本日、FlashMLA のリリースに続き、DeepSeek は第2弾の OpenSourceWeek プロジェクトである DeepEP を公開しました。
MoE(Mixture-of-Experts)モデルの訓練と推論のために特別に設計された、初のオープンソース EP 通信ライブラリである DeepEP は、エキスパート並列(EP)の分野における重要なステップとなります。このライブラリは、ノード内およびノード間の GPU 間で、MoE モデルに低遅延・高帯域・高スループットの通信機能を提供することを目的としています。テスト結果によると、DeepEP はノード内のマルチ GPU 通信において最大帯域に近い性能を達成し、ノード間の通信効率も大幅に向上させています。

EP とは?
DeepEP の詳細に入る前に、まず EP とは何かを理解することが重要です。
EP(Expert Parallelism) は、DeepSeek が最初に発表した、MoE(Mixture-of-Experts) モデル専用の分散コンピューティング手法です。MoE は Transformer ベースのモデルアーキテクチャで、スパース活性化戦略を採用しており、従来の dense モデルに比べて訓練中により軽量です。MoE ニューラルネットワークでは、入力の処理にモデルコンポーネントの一部(「エキスパート」と呼ばれる)のみがその都度活性化されます。
大規模言語モデルの推論を高速化する上での EP(Expert Parallelism) の重要性は、MoE モデルを効率的に分割できる点にあります。モデルが数百のエキスパート(例:320 エキスパート)を備えた MoE アーキテクチャを採用する場合、EP は異なるエキスパートを独立した計算ノードに割り当てることができ、その並列粒度はエキスパート数に直接対応します。
一方、TP(Tensor Parallelism) は、Attention 層のマルチヘッド機構に基づいて計算を分割します。例えば、典型的な 32 ヘッド構成では、TP は 64 以上の GPU にスケーリングする際に課題に直面します。分割次元が不足している(32 < 64)ため、ハードウェアリソースを十分に活用することが難しくなります。EP は、エキスパートの次元に沿って計算を分割します。
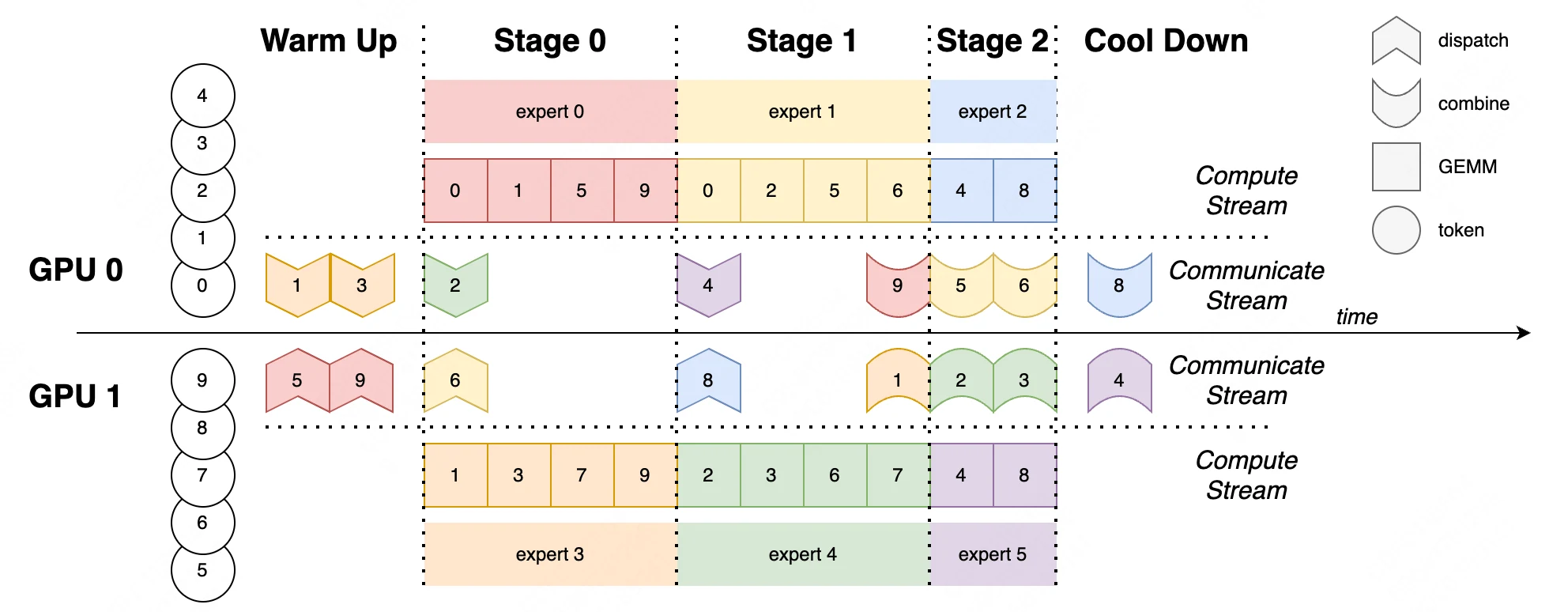
出典: EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
DP vs TP vs PP vs EP
| **手法 ** | ** 内部ロジック ** | ** 解決する核心的問題** |
|---|---|---|
| データ並列(DP) | デバイス全体でモデルを複製し、入力データを分割し、勾配更新を同期する。 | データセットが大規模で訓練速度が遅い。 |
| テンソル並列(TP) | デバイス全体でパラメータ行列を分割し、分散計算を実行し、結果を集約する。 | 単層のパラメータがデバイスメモリ容量を超える。 |
| パイプライン並列(PP) | モデル層をデバイス全体に分割し、マイクロバッチをパイプライン処理でスケジュールする。 | モデルが極端に深い場合にメモリが不足する。 |
| エキスパート並列(EP) | 入力をエキスパートサブネットワークに動的にルーティングし、スパースパラメータ活性化を行う。 | 兆パラメータ規模でのメモリと計算の非効率性。 |
最新の大規模モデル(例:GPT-4、DeepSeek-V3)は、通常、複数の並列戦略を同時に統合して効率を最大化します。
- テンソル並列(TP): 各層のパラメータをデバイス間で分割します。
- パイプライン並列(PP): モデルの異なる層をデバイスに分散し、パイプライン方式で処理します。
- データ並列(DP): モデルを複製しデータセットを分割して、複数マシンでの訓練を同期します。
- エキスパート並列(EP): MoE モデル向けにエキスパートをデバイスに分散し、スパースパラメータを拡張します。
これらの戦略を組み合わせることで、大規模モデルは利用可能なハードウェアリソースを効果的に活用し、より大きなモデルサイズやデータセットに拡張しながら、訓練と推論の効率を維持できます。
DeepEP とは?
DeepEP は、MoE(Mixture-of-Experts) と EP(Expert Parallelism) 専用に設計された通信ライブラリであり、以下の主要な利点を提供します。
- 1. 高度に最適化された All-to-All 通信
DeepEP は効率的な All-to-All 通信カーネルを提供し、データ転送のボトルネックを大幅に削減して、分散環境でのエキスパート間の情報交換をよりスムーズにします。
- 2. ノード内/ノード間通信における NVLink と RDMA のサポート
DeepEP は NVLink と RDMA の両テクノロジーをサポートし、ノード内およびノード間での高性能通信を実現します。
-
NVLink: ノード内通信で最大 160 GB/s の帯域幅を提供。
-
RDMA: ノード間データ転送の低遅延を実現し、大規模分散訓練の要求に応えます。
-
3. 高スループット計算コア
訓練および推論のプリフィル段階向けに、DeepEP は高スループットの計算コアを提供し、大規模データの効率的な処理を保証します。
- 4. 低遅延計算コア
DeepEP は RDMA/Infiniband ベースの低遅延計算コアを提供し、推論レイテンシを最小化します。これは推論デコード段階のレイテンシに敏感なアプリケーションで特に有益です。
- 5. FP8 データ配信のネイティブサポート
DeepEP は FP8 データ配信をネイティブサポートし、精度を維持しながらデータ転送量を削減し、通信効率をさらに向上させます。
- 6. 柔軟な GPU リソース制御
DeepEP は柔軟な GPU リソーススケジューリングメカニズムを備え、計算と通信の効率的なオーバーラップを可能にします。これによりリソースの無駄を最小限に抑え、全体的なパフォーマンスを向上させます。
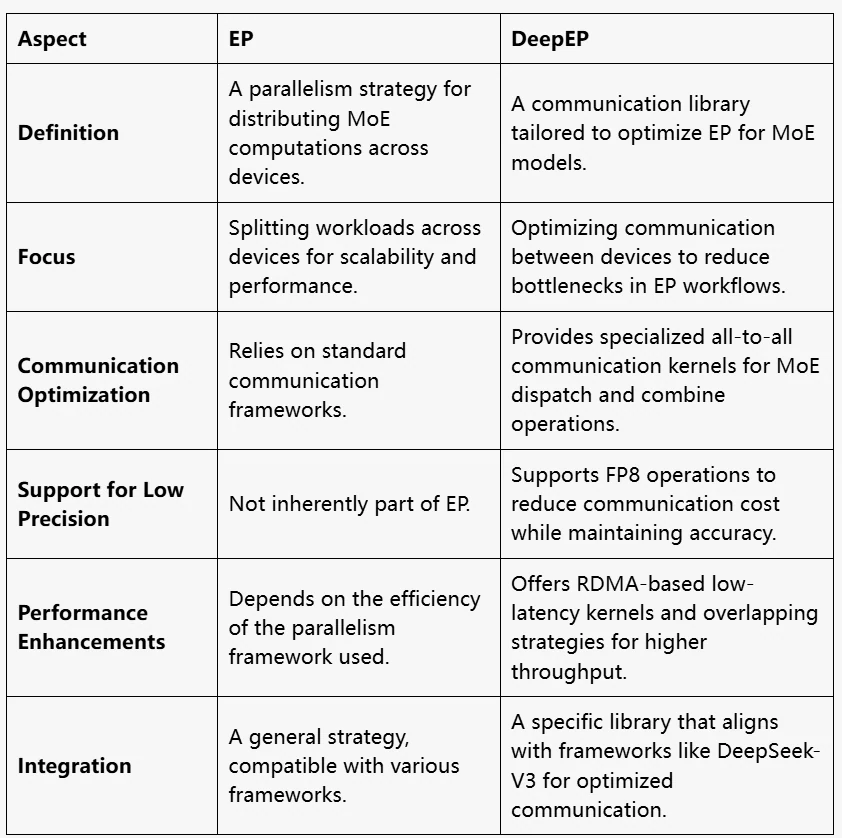
EP vs DeepEP
本質的に、EP は「何をするか」(エキスパートをどのように分割し、ワークロードを分配するか)を定義し、DeepEP は「どのように行うか」(EP をより高速でスケーラブルにする効率的な通信メカニズム)を提供します。
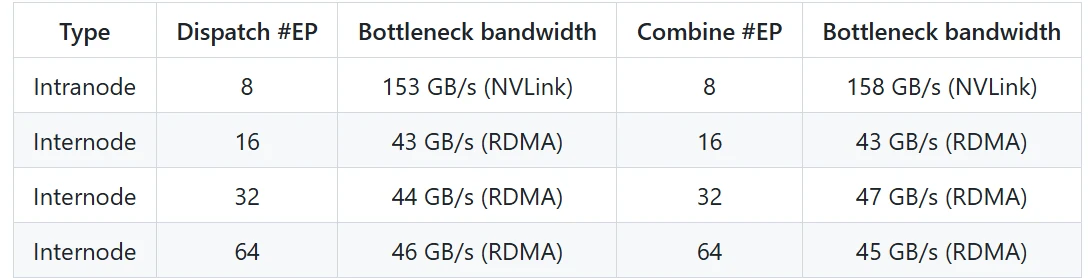
DeepEP の性能
DeepEP は、ノード内およびノード間の両方の通信、特に NVLink と RDMA を組み合わせたハイブリッドアーキテクチャで卓越した性能を発揮します。以下は、2 つの代表的なシナリオにおける性能結果です。
通常カーネル性能(NVLink および RDMA 転送)
- テスト環境:
- GPU: H800(NVLink、最大帯域幅約 160 GB/s)
- ネットワーク: CX7 InfiniBand 400 Gb/s RDMA NIC(最大帯域幅約 50 GB/s)
- 構成: DeepSeek-V3/R1 プレトレーニング設定(バッチサイズ 4096 トークン、隠れサイズ 7168、top-4 層、top-8 エキスパート、FP8 配信、BF16 集約)
- 性能結果:
- ノード内通信では NVLink の最大帯域(160 GB/s)に近い帯域幅を達成し、非常に高いデータ転送効率を示します。
- ノード間通信では RDMA のもとで安定した帯域幅を維持し、大規模分散訓練の要件を満たします。
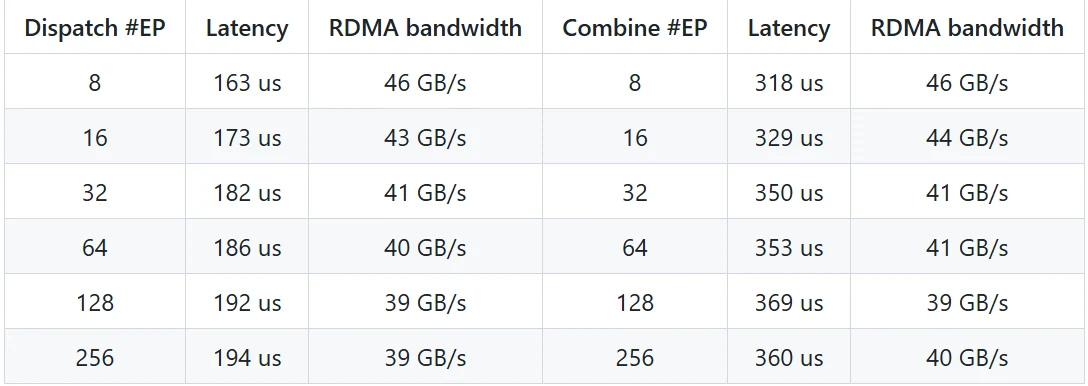
低遅延カーネル性能(Pure RDMA)
- テスト環境:
- GPU: H800
- ネットワーク: CX7 InfiniBand 400 Gb/s RDMA NIC(最大帯域幅約 50 GB/s)
- 構成: 典型的な DeepSeek-V3/R1 プロダクション設定(バッチサイズ 128 トークン、隠れサイズ 7168、top-8 エキスパート、FP8 配信、BF16 集約)
- 性能結果:
- 低遅延カーネルは Pure RDMA モードでマイクロ秒レベルのレイテンシを達成し、レイテンシに敏感な推論デコードタスクに適しています。
- 高い並列度(#EP=256)でも RDMA 帯域幅は安定しており、効率的なデータ転送を保証します。
DeepEP の適用シナリオ
DeepEP は、さまざまな MoE モデルの訓練および推論シナリオ、特に大規模分散訓練に適しています。主な適用シナリオは次のとおりです。
- MoE モデル訓練
- DeepEP の高スループット計算コアと効率的な All-to-All 通信メカニズムは、特にマルチノード・マルチ GPU 環境での訓練プロセスを大幅に高速化します。
- 推論プリフィル段階
- 推論プリフィル段階では、DeepEP の高スループット計算コアが大量のデータを効率的に処理し、高効率な推論パイプラインを保証します。
- 推論デコード段階
- デコード段階では、DeepEP の低遅延計算コアが推論遅延を最小限に抑え、リアルタイムアプリケーションに最適です。
結論
評価結果によると、DeepGEMM は H100、H200、H800 を含む複数の GPU で顕著な性能最適化能力を示し、優れた汎用性を強調しています。
Hopper アーキテクチャ上で動作する MoE シリーズモデル(DeepSeek V3 や R1 など)では、推論フレームワークの MoE モジュールに最適化を統合し、元の CUTLASS 版 grouped GEMM を DeepGEMM 実装に置き換えることで、モデル推論は約 1.2 倍の高速化が期待され、全体的なパフォーマンスが大幅に向上します。
Novita AI は AI クラウドプラットフォームで、シンプルな API を使用して AI モデルを簡単にデプロイできる機能を開発者に提供するとともに、手頃で信頼性の高い GPU クラウドをビルドおよびスケーリングに提供します。