继 FlashMLA 发布之后,DeepSeek 今天推出了第二个 OpenSourceWeek 项目——DeepEP。
作为首个专为 MoE(混合专家)模型训练和推理设计的开源 EP 通信库,DeepEP 标志着专家并行(EP)领域迈出了重要一步。它旨在为 MoE 模型提供节点内和节点间 GPU 之间的低延迟、高带宽、高吞吐量通信能力。根据测试结果,DeepEP 在节点内多 GPU 通信中实现了接近最大带宽的性能,同时显著提升了节点间通信效率。

什么是 EP?
在深入了解 DeepEP 之前,有必要先了解 EP 是什么。
EP(Expert Parallelism,专家并行) 是一种专为 MoE(混合专家) 模型设计的分布式计算方法,最初由 DeepSeek 提出。MoE 是一种基于 Transformer 的模型架构,采用稀疏激活策略,使其在训练时相比传统密集模型更为轻量。在 MoE 神经网络中,任何时候只有一部分模型组件(称为“专家”)被激活来处理输入。
EP(专家并行) 在加速大型语言模型推理中的重要性在于,它能高效地划分 MoE 模型。当模型采用包含数百个专家(例如 320 个专家)的 MoE 架构时,EP 可以将不同的专家分配给独立的计算节点,其并行粒度直接与专家数量匹配。
相比之下,TP(张量并行) 依赖于基于注意力层多头机制的分割计算。例如,在典型的 32 头配置中,TP 在扩展到 64 个或更多 GPU 时面临挑战,因为分割维度不足(32 < 64),难以充分利用硬件资源。而 EP 则沿着专家维度划分计算。
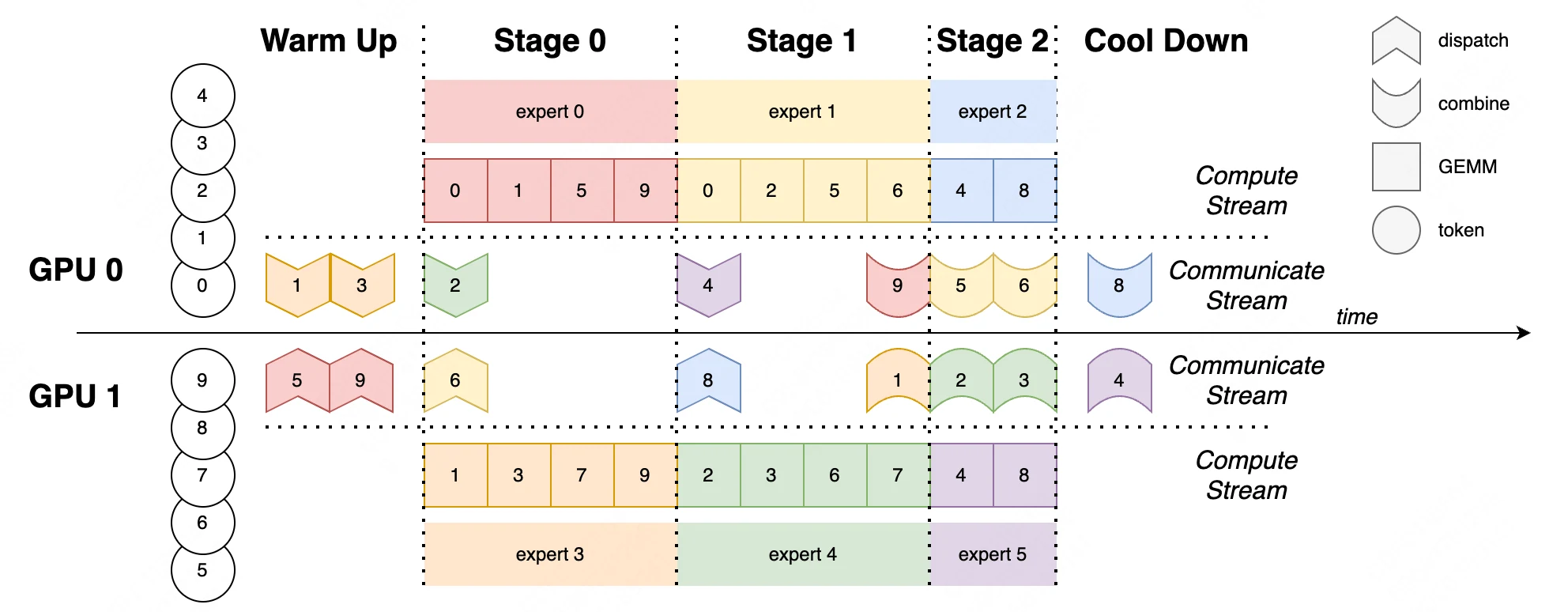
来自 EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
DP vs TP vs PP vs EP
| **方法 ** | ** 内在逻辑 ** | ** 解决的核心问题** |
|---|---|---|
| 数据并行 (DP) | 跨设备复制模型,分割输入数据,同步梯度更新 | 数据集过大导致训练速度慢 |
| 张量并行 (TP) | 跨设备分割参数矩阵,进行分布式计算,聚合结果 | 单层参数超出设备内存容量 |
| 流水线并行 (PP) | 跨设备划分模型层,通过流水线调度微批次 | 模型层数过深导致内存不足 |
| 专家并行 (EP) | 动态路由输入到专家子网络,稀疏激活参数 | 万亿参数规模下的内存和计算效率瓶颈 |
现代大规模模型(如 GPT-4、DeepSeek-V3)通常同时集成多种并行策略以最大化效率:
- 张量并行 (TP): 将单层参数分割到多个设备。
- 流水线并行 (PP): 将模型的不同层分布到设备上,以流水线方式处理。
- 数据并行 (DP): 通过复制模型并分割数据集,在多个机器间同步训练。
- 专家并行 (EP): 通过将专家分布到设备上,扩展 MoE 模型的稀疏参数。
通过组合这些策略,大模型能够有效利用可用硬件资源,扩展到更大的模型规模和数据集,同时保持训练和推理效率。
什么是 DeepEP?
DeepEP 是一个专为 MoE(混合专家) 和 EP(专家并行) 设计的通信库,具有以下核心优势:
-
1. 高度优化的 All-to-All 通信
DeepEP 提供高效的 All-to-All 通信内核,显著减少数据传输瓶颈,确保分布式环境中专家间的信息交换更加流畅。
-
2. 支持节点内/节点间通信的 NVLink 和 RDMA
DeepEP 同时支持 NVLink 和 RDMA 技术,实现节点内和节点间的高性能通信:
- NVLink: 为节点内通信提供高达 160 GB/s 的带宽。
- RDMA: 实现低延迟的节点间数据传输,满足大规模分布式训练需求。
-
3. 高吞吐量计算核心
针对训练和推理 prefill 阶段,DeepEP 提供高吞吐量计算核心,确保大规模数据的高效处理。
-
4. 低延迟计算核心
DeepEP 提供基于 RDMA/Infiniband 的低延迟计算核心,可最小化推理延迟,特别适用于对延迟敏感的推理解码阶段。
-
5. 原生支持 FP8 数据分发
DeepEP 原生支持 FP8 数据分发,在保持精度的同时减少数据传输量,进一步提升通信效率。
-
6. 灵活的 GPU 资源控制
DeepEP 具备灵活的 GPU 资源调度机制,允许计算与通信高效重叠,最大限度减少资源浪费并提升整体性能。
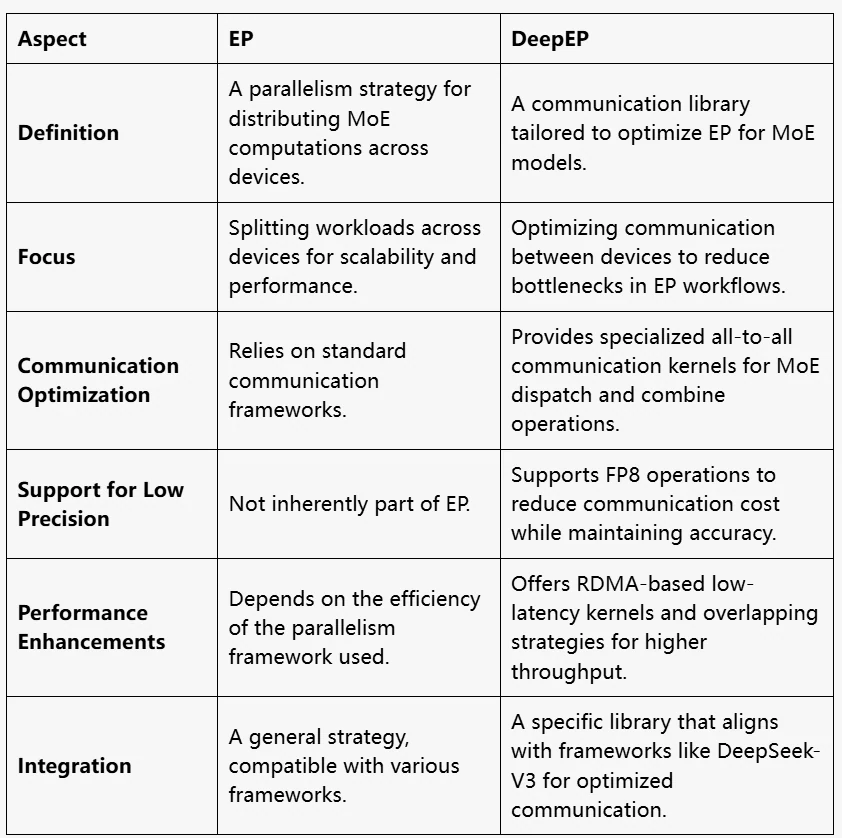
EP vs DeepEP
本质上,EP 定义了“做什么”(如何划分专家和分配工作负载),而 DeepEP 提供了“怎么做”(高效的通信机制,使 EP 更快、更具可扩展性)。
DeepEP 性能
DeepEP 在节点内和节点间通信中均表现出卓越性能,尤其是在结合 NVLink 和 RDMA 的混合架构中。以下是两个典型场景下的性能结果:
常规内核性能(NVLink 和 RDMA 转发)
-
测试环境:
- GPU: H800(NVLink,最大带宽约 160 GB/s)
- 网络: CX7 InfiniBand 400 Gb/s RDMA NIC(最大带宽约 50 GB/s)
- 配置: DeepSeek-V3/R1 预训练设置(批次大小:4096 token,隐藏层大小:7168,top-4 层,top-8 专家,FP8 分发,BF16 聚合)
-
性能结果:
- 节点内通信带宽接近 NVLink 最大值(160 GB/s),展示出极高的数据传输效率。
- 节点间通信在 RDMA 下保持稳定带宽,满足大规模分布式训练的要求。
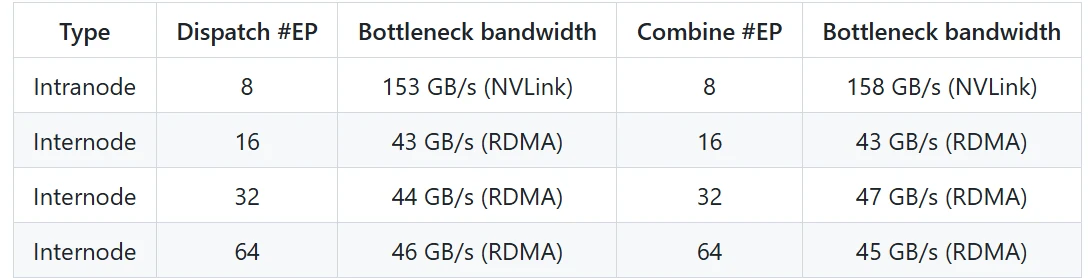
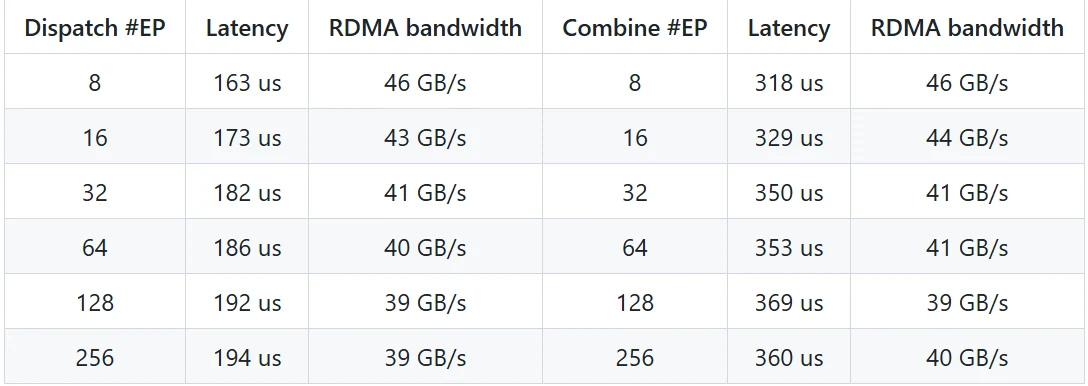
低延迟内核性能(纯 RDMA)
-
测试环境:
- GPU: H800
- 网络: CX7 InfiniBand 400 Gb/s RDMA NIC(最大带宽约 50 GB/s)
- 配置: 典型的 DeepSeek-V3/R1 生产设置(批次大小:128 token,隐藏层大小:7168,top-8 专家,FP8 分发,BF16 聚合)
-
性能结果:
- 低延迟内核在纯 RDMA 模式下实现微秒级延迟,适用于对延迟敏感的推理解码任务。
- 即使在高度并行(#EP=256)下,RDMA 带宽仍保持稳定,确保高效的数据传输。
DeepEP 应用场景
DeepEP 适用于各种 MoE 模型训练和推理场景,尤其是在大规模分布式训练中。主要应用场景包括:
-
MoE 模型训练
- DeepEP 的高吞吐量计算核心和高效的 All-to-All 通信机制显著加速训练过程,特别是在多节点、多 GPU 环境中。
-
推理 Prefill 阶段
- 在推理 prefill 阶段,DeepEP 的高吞吐量计算核心高效处理大量数据,确保高效推理流水线。
-
推理解码阶段
- 在解码阶段,DeepEP 的低延迟计算核心最小化推理延迟,非常适合实时应用。
结论
根据评估结果,DeepGEMM 在多个 GPU(包括 H100、H200 和 H800)上展现出显著的性能优化能力,凸显了其出色的通用性。
对于运行在 Hopper 架构上的 MoE 系列模型(如 DeepSeek V3 和 R1),通过将优化集成到推理框架的 MoE 模块中,并用 DeepGEMM 实现替换原始的 CUTLASS 版本的分组 GEMM,模型推理预计可实现约 1.2 倍的加速,显著提升整体性能。
Novita AI 是一个 AI 云平台,为开发者提供简单 API 轻松部署 AI 模型,同时提供价格实惠且可靠的 GPU 云用于构建和扩展。