

Hoy, tras el lanzamiento de FlashMLA, DeepSeek ha presentado su segundo proyecto de OpenSourceWeek: DeepEP.
Como la primera biblioteca de comunicación EP de código abierto diseñada específicamente para el entrenamiento e inferencia de modelos MoE (Mixture-of-Experts), DeepEP representa un avance significativo en el campo del Parallelismo de Expertos (EP). Su objetivo es proporcionar a los modelos MoE capacidades de comunicación de baja latencia, alto ancho de banda y alto rendimiento tanto entre GPUs dentro de un nodo como entre nodos.
Según los resultados de las pruebas, DeepEP alcanza un rendimiento de ancho de banda casi máximo para la comunicación multi-GPU dentro de un nodo, mientras que también mejora significativamente la eficiencia de comunicación entre nodos.

¿Qué es EP?
Antes de profundizar en DeepEP, es importante entender primero qué es EP.
EP (Parallelismo de Expertos) es un método de computación distribuida diseñado específicamente para modelos MoE (Mixture-of-Experts), publicado originalmente por DeepSeek. MoE es una arquitectura de modelo basada en Transformer que emplea una estrategia de activación dispersa, lo que la hace más ligera durante el entrenamiento en comparación con los modelos densos tradicionales. En una red neuronal MoE, solo un subconjunto de los componentes del modelo (llamados “expertos”) se activa para procesar la entrada en un momento dado.
La importancia de EP (Parallelismo de Expertos) en la aceleración de la inferencia de grandes modelos de lenguaje radica en su capacidad para dividir eficientemente los modelos MoE. Cuando un modelo adopta la arquitectura MoE con cientos de expertos (por ejemplo, 320 expertos), EP puede asignar diferentes expertos a nodos de computación independientes, con su granularidad paralela coincidiendo directamente con el número de expertos.
En contraste, TP (Parallelismo de Tensores) se basa en dividir la computación según el mecanismo de múltiples cabezas en las capas de Atención. Por ejemplo, en una configuración típica de 32 cabezas, TP enfrenta desafíos para escalar a 64 o más GPUs porque la dimensión de división es insuficiente (32 < 64), lo que dificulta el uso completo de los recursos de hardware. EP, por otro lado, divide las computaciones a lo largo de la dimensión de los expertos.
de EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference
DP vs TP vs PP vs EP
| Método | Lógica Interna | Problema Central Resuelto |
|---|---|---|
| Parallelismo de Datos (DP) | Replicar modelos a través de dispositivos, dividir datos de entrada, sincronizar actualizaciones de gradientes. | Velocidad de entrenamiento lenta debido al gran tamaño del conjunto de datos. |
| Parallelismo de Tensores (TP) | Dividir matrices de parámetros entre dispositivos, realizar computación distribuida y agregar resultados. | Parámetros de una sola capa que exceden la capacidad de memoria del dispositivo. |
| Parallelismo de Pipeline (PP) | Particionar las capas del modelo a través de dispositivos, programar micro-lotes mediante canalización. | Memoria insuficiente para modelos con profundidad extrema. |
| Parallelismo de Expertos (EP) | Enrutar dinámicamente las entradas a subredes expertas con activación de parámetros dispersos. | Ineficiencia de memoria y computación a escala de billones de parámetros. |
Los modelos modernos a gran escala (por ejemplo, GPT-4, DeepSeek-V3) suelen integrar múltiples estrategias de paralelismo simultáneamente para maximizar la eficiencia:
- Parallelismo de Tensores (TP): Divide los parámetros de capas individuales entre dispositivos.
- Parallelismo de Pipeline (PP): Distribuye diferentes capas del modelo entre dispositivos para procesarlas en forma de pipeline.
- Parallelismo de Datos (DP): Sincroniza el entrenamiento a través de múltiples máquinas replicando el modelo y dividiendo el conjunto de datos.
- Parallelismo de Expertos (EP): Expande parámetros dispersos distribuyendo expertos entre dispositivos para modelos MoE.
Al combinar estas estrategias, los modelos grandes pueden utilizar eficazmente los recursos de hardware disponibles, escalando a tamaños de modelo y conjuntos de datos más grandes mientras mantienen la eficiencia de entrenamiento e inferencia.
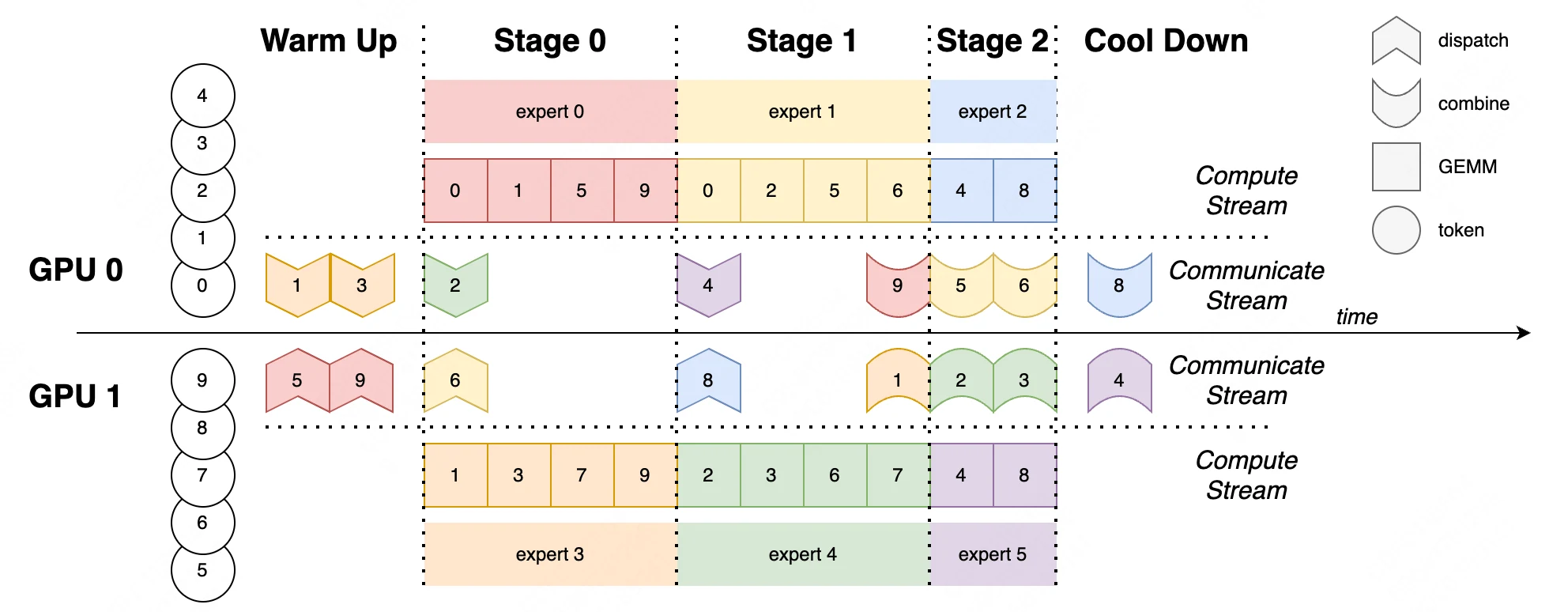
¿Qué es DeepEP?
DeepEP es una biblioteca de comunicación diseñada específicamente para MoE (Mixture-of-Experts) y EP (Parallelismo de Expertos), que ofrece las siguientes ventajas principales:
- 1. Comunicación All-to-All Altamente Optimizada
DeepEP proporciona un núcleo de comunicación All-to-All eficiente que reduce significativamente los cuellos de botella en la transferencia de datos, asegurando un intercambio de información más fluido entre expertos en entornos distribuidos.
- 2. Soporte para NVLink y RDMA en Comunicación Intra-Nodo e Inter-Nodo
DeepEP soporta tanto tecnologías NVLink como RDMA, permitiendo comunicación de alto rendimiento dentro de los nodos y entre nodos:
-
NVLink: Ofrece un ancho de banda de hasta 160 GB/s para comunicación dentro del nodo.
-
RDMA: Permite transferencias de datos de baja latencia entre nodos, satisfaciendo las demandas de entrenamiento distribuido a gran escala.
-
3. Núcleo de Cómputo de Alto Rendimiento
Para las etapas de entrenamiento y prefill de inferencia, DeepEP proporciona un núcleo de cómputo de alto rendimiento, asegurando un procesamiento eficiente de datos a gran escala.
- 4. Núcleo de Cómputo de Baja Latencia
DeepEP ofrece un núcleo de cómputo de baja latencia basado en RDMA/Infiniband, que minimiza la latencia de inferencia. Esto es especialmente beneficioso para aplicaciones sensibles a la latencia durante la etapa de decodificación de inferencia.
- 5. Soporte Nativo para Distribución de Datos FP8
DeepEP soporta de forma nativa la distribución de datos FP8, reduciendo el volumen de datos transferidos mientras mantiene la precisión, mejorando aún más la eficiencia de comunicación.
- 6. Control Flexible de Recursos de GPU
DeepEP cuenta con un mecanismo flexible de programación de recursos de GPU, permitiendo una superposición eficiente de cómputo y comunicación. Esto minimiza el desperdicio de recursos y mejora el rendimiento general.
EP vs DeepEP
En esencia, EP define el “qué” (cómo dividir expertos y distribuir cargas de trabajo), mientras que DeepEP proporciona el “cómo” (mecanismos de comunicación eficientes para hacer que EP sea más rápido y escalable).
Rendimiento de DeepEP
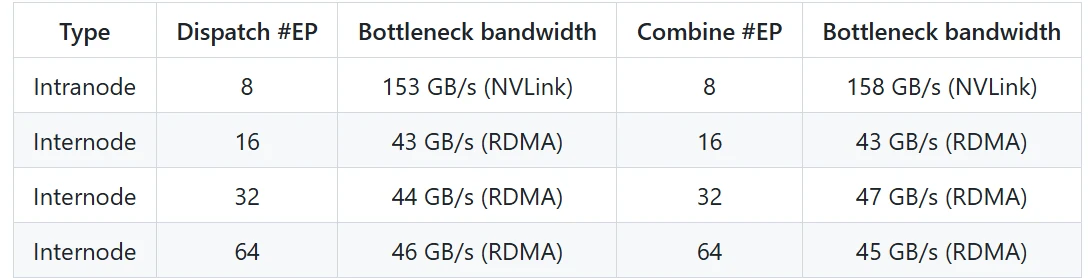
DeepEP muestra un rendimiento excepcional tanto en comunicación intra-nodo como inter-nodo, particularmente en arquitecturas híbridas que combinan NVLink y RDMA. A continuación se presentan los resultados de rendimiento en dos escenarios típicos:
Rendimiento del Núcleo Regular (Reenvío NVLink y RDMA)
-
Entorno de Prueba:
- GPU: H800 (NVLink con ancho de banda máximo de ~160 GB/s)
- Red: CX7 InfiniBand 400 Gb/s RDMA NIC (ancho de banda máximo ~50 GB/s)
- Configuración: Configuración de preentrenamiento de DeepSeek-V3/R1 (tamaño de lote: 4096 tokens, tamaño oculto: 7168, top-4 capas, top-8 expertos, distribución FP8 y agregación BF16)
-
Resultados de Rendimiento:
- La comunicación intra-nodo alcanza un ancho de banda cercano al máximo de NVLink (160 GB/s), demostrando una eficiencia de transferencia de datos extremadamente alta.
- La comunicación inter-nodo mantiene un ancho de banda estable bajo RDMA, cumpliendo con los requisitos para entrenamiento distribuido a gran escala.
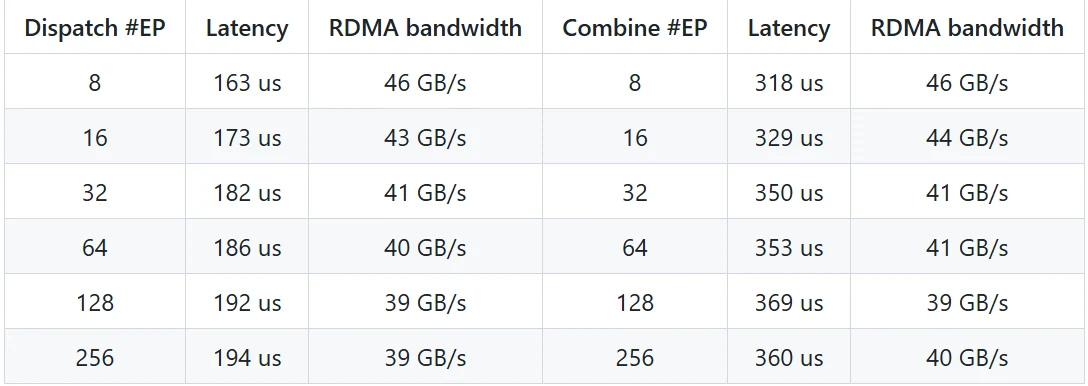
Rendimiento del Núcleo de Baja Latencia (RDMA Puro)
-
Entorno de Prueba:
- GPU: H800
- Red: CX7 InfiniBand 400 Gb/s RDMA NIC (ancho de banda máximo ~50 GB/s)
- Configuración: Configuración típica de producción de DeepSeek-V3/R1 (tamaño de lote: 128 tokens, tamaño oculto: 7168, top-8 expertos, distribución FP8 y agregación BF16)
-
Resultados de Rendimiento:
- El núcleo de baja latencia logra latencia a nivel de microsegundos en modo RDMA puro, lo que lo hace adecuado para tareas de decodificación de inferencia sensibles a la latencia.
- Incluso con alto paralelismo (#EP=256), el ancho de banda de RDMA se mantiene estable, asegurando una transferencia de datos eficiente.
Escenarios de Aplicación de DeepEP
DeepEP es adecuado para varios escenarios de entrenamiento e inferencia de modelos MoE, particularmente en entrenamiento distribuido a gran escala. Los escenarios clave de aplicación incluyen:
-
Entrenamiento de Modelos MoE
- El núcleo de cómputo de alto rendimiento y el mecanismo de comunicación All-to-All eficiente de DeepEP aceleran significativamente el proceso de entrenamiento, especialmente en entornos multi-nodo y multi-GPU.
-
Etapa de Prefill de Inferencia
- Durante la etapa de prefill de inferencia, el núcleo de cómputo de alto rendimiento de DeepEP procesa eficientemente grandes cantidades de datos, asegurando un pipeline de inferencia altamente eficiente.
-
Etapa de Decodificación de Inferencia
- Para la etapa de decodificación, el núcleo de cómputo de baja latencia de DeepEP minimiza los retrasos de inferencia, lo que lo hace ideal para aplicaciones en tiempo real.
Conclusión
Según los resultados de evaluación, DeepGEMM ha demostrado una capacidad de optimización de rendimiento significativa en múltiples GPUs, incluyendo H100, H200 y H800, destacando su excelente versatilidad.
Para modelos de la serie MoE que se ejecutan en la arquitectura Hopper (como DeepSeek V3 y R1), al integrar optimizaciones en el módulo MoE del marco de inferencia y reemplazar los grouped GEMMs originales de la versión CUTLASS con la implementación de DeepGEMM, se espera que la inferencia del modelo logre una aceleración de aproximadamente 1.2x, mejorando significativamente el rendimiento general.
Novita AI es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA utilizando nuestra API simple, además de proporcionar la GPU en la nube asequible y confiable para construir y escalar.
¡Obtén $20 de crédito y prueba DeepSeek ahora!



