

La terminologie de l’IA est omniprésente de nos jours, et il peut être difficile de suivre quand tout le monde semble parler une langue différente. Si vous avez déjà été dans une conversation où quelqu’un mentionne « Sandbox », « RAG » ou « MCP » et que vous vous surprenez à acquiescer en réunion tout en vous demandant secrètement ce que signifient réellement ces termes, ce guide est fait pour vous.
La technologie évolue rapidement, mais comprendre les bases ne nécessite pas de formation technique. Voici une explication simple des termes d’IA les plus courants que vous êtes susceptible de rencontrer, organisée pour construire votre compréhension étape par étape.

1. Concepts fondamentaux de l’IA
Modèles d’IA
Considérez un modèle d’IA comme un programme informatique intelligent conçu pour imiter la pensée humaine. Vous lui fournissez une entrée – comme une question ou une image – et il traite cette information pour générer une sortie pertinente. Les modèles apprennent en analysant de vastes quantités d’exemples, en reconnaissant des schémas et en améliorant progressivement leur capacité à comprendre et à répondre.
Pour une plongée plus approfondie dans les modèles d’IA et la manière de les déployer efficacement, consultez notre Guide de déploiement de modèles Novita AI.
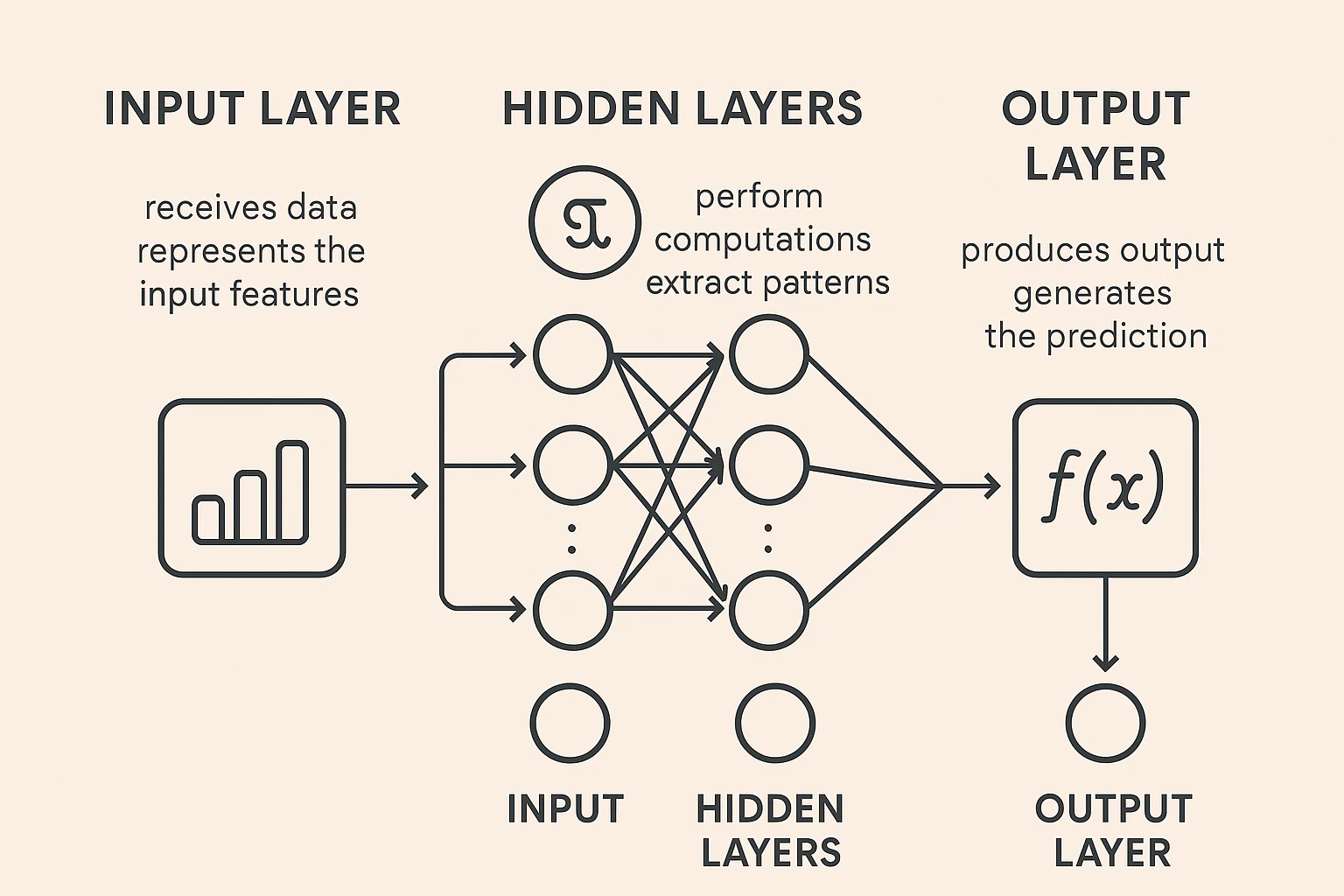
Réseau de neurones
Imaginez un réseau de neurones comme une version simplifiée du fonctionnement de notre cerveau. Il est composé de nœuds interconnectés (appelés neurones artificiels) qui se transmettent des informations, un peu comme les neurones dans notre tête. Ces réseaux s’améliorent dans la reconnaissance de schémas et la prise de décision en ajustant les poids des connexions entre les nœuds – un peu comme nous apprenons de l’expérience. Les réseaux de neurones sont organisés en couches : une couche d’entrée reçoit les données, des couches cachées les traitent via des fonctions mathématiques complexes, et une couche de sortie produit le résultat final. Le « profond » dans l’apprentissage profond fait référence aux réseaux avec de nombreuses couches cachées, leur permettant d’apprendre des schémas de plus en plus complexes.
Architecture Transformer
Le transformer est la technologie révolutionnaire qui a rendu possible l’IA intelligente d’aujourd’hui. Avant 2017, l’IA devait lire le texte mot par mot, comme lire un livre en suivant chaque mot du doigt. Les transformers ont changé cela en permettant à l’IA de voir tous les mots d’une phrase en même temps et de comprendre comment ils sont liés grâce à un mécanisme appelé « attention ». C’est comme la différence entre lire un mot à la fois et saisir instantanément toute la phrase. Le mécanisme d’attention permet au modèle de se concentrer sur les parties pertinentes de l’entrée lors de la génération de chaque partie de la sortie, ce qui le rend beaucoup plus efficace pour comprendre le contexte et les relations dans le langage.
Grand modèle de langage (LLM)
Les LLM sont des modèles d’IA spécifiquement entraînés pour comprendre et générer le langage humain. Ils lisent des milliards de mots et apprennent à prédire ce qui vient ensuite dans une phrase, ce qui leur permet d’écrire des essais, de répondre à des questions ou de discuter naturellement. Pendant l’entraînement, ils analysent des schémas dans le texte pour comprendre la grammaire, le contexte et la signification. Les LLM modernes ont évolué vers des modèles multimodaux, ce qui signifie qu’ils peuvent traiter non seulement du texte mais aussi des images, de l’audio, etc., le tout dans une seule interface. Par exemple, GPT-4o peut accepter simultanément du texte, de la voix et des images, rendant les interactions plus riches et plus polyvalentes. Le terme « grand » fait référence au nombre énorme de paramètres (souvent des milliards) qui stockent les connaissances apprises par le modèle.
Intelligence générale artificielle (AGI)
L’AGI est le Saint Graal de l’IA – un système qui serait aussi intelligent que les humains dans tous les domaines, et pas seulement pour des tâches spécifiques. Alors que l’IA d’aujourd’hui excelle dans des choses particulières comme l’écriture ou la reconnaissance d’images, l’AGI égalerait l’intelligence humaine en créativité, raisonnement, apprentissage et résolution de problèmes dans n’importe quel domaine. Scientifiquement, atteindre l’AGI nécessite de résoudre des défis fondamentaux tels que l’apprentissage par transfert (appliquer des connaissances d’un domaine à un autre), l’apprentissage en quelques exemples (apprendre à partir de très peu d’exemples), le raisonnement causal et le développement d’algorithmes d’apprentissage plus efficaces. Les systèmes d’IA actuels sont considérés comme « étroits » car ils excellent dans des tâches spécifiques mais manquent de l’intelligence générale et de l’adaptabilité qui caractérisent la cognition humaine.
Alignement de l’IA
L’alignement de l’IA consiste à s’assurer que les systèmes d’IA veulent les mêmes choses que les humains et se comportent de manière à nous aider plutôt qu’à nous nuire. À mesure que l’IA devient plus puissante, il est de plus en plus important de garantir qu’elle partage nos valeurs et nos objectifs. Pensez-y comme à s’assurer que l’IA est de notre côté. Cela implique des défis techniques comme l’apprentissage des valeurs (enseigner à l’IA à comprendre les préférences humaines), la robustesse (s’assurer que l’IA se comporte correctement dans de nouvelles situations) et l’interprétabilité (comprendre pourquoi l’IA prend certaines décisions). La recherche sur l’alignement aborde également des questions philosophiques sur les valeurs à aligner et comment gérer des préférences humaines conflictuelles.
2. Données et entraînement
Données d’entraînement
Les données d’entraînement sont simplement toutes les informations utilisées pour enseigner un modèle d’IA – considérez-les comme les manuels de l’IA. Pour les modèles de langage, cela inclut des millions de livres, sites web, articles de presse et autres contenus écrits. Plus ce « matériel de lecture » est diversifié et de haute qualité, meilleure est l’IA pour traiter différents sujets et situations. La qualité des données est cruciale : des données d’entraînement biaisées ou incorrectes conduisent à des résultats d’IA biaisés ou incorrects. Le processus d’entraînement implique de montrer au modèle d’innombrables exemples afin qu’il puisse apprendre des schémas statistiques et des relations dans les données.
Pré-entraînement
Le pré-entraînement, c’est comme si l’IA allait à l’école primaire – c’est là que les modèles apprennent les bases. Pendant cette phase, l’IA lit d’énormes quantités de texte et apprend des schémas fondamentaux sur le langage, des faits sur le monde et comment raisonner. C’est essentiellement l’éducation générale de l’IA avant qu’elle ne se spécialise dans quelque chose de spécifique. Le pré-entraînement utilise l’apprentissage non supervisé, ce qui signifie que le modèle apprend des schémas sans étiquettes ou réponses explicites. Cette phase est coûteuse en calcul, nécessitant souvent des semaines ou des mois sur des clusters d’ordinateurs puissants, mais elle crée une base de connaissances générales qui peut être appliquée à de nombreuses tâches différentes.
Ajustement fin (fine-tuning)
L’ajustement fin (fine-tuning) est comme une formation spécialisée après l’obtention du diplôme. Une fois qu’une IA a reçu son éducation générale via le pré-entraînement, elle peut être entraînée davantage sur des types spécifiques de contenu ou de tâches. Par exemple, une IA générale peut être ajustée sur des revues médicales pour devenir meilleure pour les questions de santé, ou entraînée sur des conversations de service client pour adopter le ton et le style particuliers d’une entreprise. Ce processus nécessite beaucoup moins de données et de ressources informatiques que le pré-entraînement car le modèle comprend déjà les fondamentaux du langage. L’ajustement fin ajuste les paramètres du modèle pour optimiser les performances dans des domaines ou applications spécifiques tout en préservant les capacités générales.
Apprentissage par renforcement à partir du feedback humain (RLHF)
Le RLHF, c’est comme avoir des enseignants humains qui notent les devoirs de l’IA et lui disent ce qui fait une bonne réponse. Les humains évaluent différentes réponses de l’IA, et le modèle apprend à produire des résultats que les gens trouvent utiles, précis et appropriés. Ce processus est crucial pour créer des systèmes d’IA qui se comportent comme nous le souhaitons. Le RLHF comporte généralement trois étapes : l’entraînement d’un modèle de récompense basé sur les préférences humaines, l’utilisation de l’apprentissage par renforcement pour optimiser le comportement de l’IA en fonction de ce modèle de récompense, et l’amélioration itérative via davantage de feedback humain. Cette technique aide à aligner le comportement de l’IA sur les valeurs humaines et réduit les résultats nuisibles ou indésirables.
3. Mécanismes d’entrée et de sortie
Token
Un token est fondamentalement la façon dont l’IA « compte » le texte – environ un token par mot, même s’il peut s’agir de parties de mots, de ponctuation ou même d’espaces. Les modèles d’IA ont des limites sur le nombre de tokens qu’ils peuvent traiter à la fois (appelée la fenêtre de contexte), ce qui explique pourquoi ils ne peuvent parfois pas traiter de très longs documents ou se souvenir de tout d’une longue conversation. Différentes langues et systèmes d’écriture nécessitent différentes stratégies de tokenisation. Comprendre les tokens est important car les modèles d’IA traitent le texte séquentiellement sous forme de tokens, et la limite de tokens détermine à la fois la longueur d’entrée et la portée de la mémoire lors des conversations.
Inférence
L’inférence est simplement le moment où l’IA fait son travail – elle prend votre entrée et produit une sortie. Lorsque vous tapez une question dans ChatGPT et obtenez une réponse, c’est l’inférence qui se produit. C’est différent de l’entraînement, qui est le moment où l’IA apprend à partir des données. Pendant l’inférence, le modèle utilise ses paramètres appris pour traiter de nouvelles entrées et générer des réponses. Ce processus est beaucoup plus rapide et moins gourmand en ressources que l’entraînement, mais nécessite tout de même une puissance de calcul significative pour les grands modèles. La qualité de l’inférence dépend à la fois de l’entraînement du modèle et de la manière dont l’entrée correspond aux schémas que le modèle a déjà vus.
Ingénierie des prompts
L’ingénierie des prompts est l’art et la science de poser la bonne question à l’IA de la bonne manière. Tout comme poser à une personne une question claire et spécifique donne une meilleure réponse qu’une question vague, élaborer de bons prompts peut améliorer considérablement ce que vous obtenez de l’IA. Les prompts efficaces incluent souvent des instructions claires, un contexte pertinent, des exemples du format de sortie souhaité et des contraintes ou exigences spécifiques. Les techniques avancées incluent le prompting en chaîne de pensée (demander à l’IA de montrer son raisonnement), l’apprentissage en quelques exemples (fournir des exemples) et l’enchaînement de prompts (diviser les tâches complexes en étapes). L’objectif est de communiquer clairement l’intention tout en exploitant de manière optimale les capacités du modèle.
Hallucination
Quand l’IA « hallucine », elle invente des choses qui semblent convaincantes mais qui ne sont pas vraies. Cela se produit lorsque l’IA essaie de combler des lacunes dans ses connaissances ou qu’on lui demande quelque chose qu’elle ne comprend pas vraiment. C’est comme quand quelqu’un vous donne avec assurance des indications pour un endroit où il n’est jamais allé – l’assurance ne rend pas les indications correctes. Les hallucinations surviennent parce que les modèles de langage sont entraînés à générer du texte plausible, pas nécessairement des informations précises. Ils peuvent fabriquer des faits, des citations ou des détails tout en conservant un ton confiant. Comprendre cette limitation est crucial pour une utilisation responsable de l’IA, et des techniques comme la vérification des faits et la validation des sources restent importantes.

4. Outils d’IA et applications avancées
Interface de programmation d’application (API)
Une API est comme un serveur dans un restaurant – elle prend votre commande (requête) vers la cuisine (système d’IA) et vous rapporte votre plat (réponse). Dans le monde de l’IA, les API permettent à différents programmes logiciels de dialoguer avec des modèles d’IA sans avoir à construire l’IA à partir de zéro. Les entreprises peuvent se connecter à des services d’IA existants via des API. Les API définissent le format spécifique des requêtes et des réponses, y compris des paramètres comme la longueur maximale de sortie, le niveau de créativité (température) et le format de réponse. Elles gèrent l’authentification, la limitation de débit et la gestion des erreurs, ce qui permet aux développeurs d’intégrer facilement des capacités d’IA dans des applications, sites web ou services sans avoir besoin d’une expertise approfondie en IA.
IA multimodale
L’IA multimodale peut gérer différents types de contenu en même temps – texte, images, voix et vidéo. C’est comme avoir une conversation avec quelqu’un qui peut voir ce que vous lui montrez, entendre ce que vous dites et lire ce que vous avez écrit, le tout simultanément. Cela rend les interactions avec l’IA beaucoup plus naturelles et humaines. Les modèles multimodaux utilisent différentes architectures de réseaux de neurones pour différents types d’entrée (transformers de vision pour les images, encodeurs audio pour le son) mais les combinent dans un espace de représentation unifié. Cela permet à l’IA de comprendre les relations entre différentes modalités, comme décrire ce qui se passe dans une vidéo ou répondre à des questions sur des images.
Génération augmentée par récupération (RAG)
Le RAG, c’est comme donner à l’IA accès à une bibliothèque à jour tout en répondant à vos questions. Au lieu d’utiliser uniquement ce qu’elle a appris pendant l’entraînement, les systèmes RAG peuvent rechercher dans des bases de données et des documents à jour pour trouver des informations pertinentes avant d’élaborer une réponse. Cela permet de garantir que les réponses sont précises et actuelles. Le RAG fonctionne en deux étapes : d’abord, un système de récupération recherche les documents ou informations pertinents en fonction de la requête, puis le modèle de langage génère une réponse en utilisant à la fois ses connaissances d’entraînement et les informations récupérées. Cette approche réduit les hallucinations, permet l’accès à des informations actualisées et permet à l’IA de travailler avec des bases de connaissances propriétaires ou spécialisées.
Cet article vous permet d’en apprendre davantage : Qu’est-ce que le RAG : une introduction complète à la génération augmentée par récupération
Sandbox
Un sandbox (bac à sable) est comme un parc sécurisé pour l’IA – un environnement isolé et sûr où l’IA peut exécuter du code, accéder à des outils ou expérimenter sans aucun risque pour vos systèmes principaux. C’est comme laisser un enfant jouer dans une zone clôturée où il ne peut rien casser d’important. Les sandbox utilisent la conteneurisation, les machines virtuelles ou d’autres technologies d’isolation pour créer des environnements contrôlés avec un accès limité aux ressources système, aux connexions réseau et aux données sensibles. Cela permet aux agents d’IA d’exécuter du code, d’interagir avec des API ou de tester des solutions tout en empêchant les violations de sécurité potentielles, la corruption de données ou les dommages système.
C’est un concept assez complexe ; si vous souhaitez explorer davantage, voici un excellent article de notre part pour approfondir le sujet : Comment les sandbox d’agents permettent une innovation IA sécurisée et évolutive.
Endpoint dédié LLM
Un endpoint dédié LLM, c’est comme avoir une ligne téléphonique directe vers un modèle d’IA spécifique, optimisé pour vos besoins particuliers. Au lieu de partager les ressources avec tout le monde, vous bénéficiez d’une connexion dédiée qui peut être personnalisée pour votre cas d’utilisation spécifique. Cela implique la mise en place de ressources de calcul isolées (GPU, mémoire, bande passante) avec des configurations personnalisées comme la vitesse de réponse, le style de sortie, les filtres de sécurité et les garanties de performance. Les endpoints dédiés offrent une latence constante, un débit plus élevé et la possibilité d’ajuster finement les modèles spécifiquement pour vos applications tout en garantissant la confidentialité des données et en répondant aux exigences de sécurité des entreprises.
Cet article vous permet d’en apprendre davantage : Endpoint dédié LLM sur Novita AI : modèles personnalisés, facturation à l’usage et mise à l’échelle sans DevOps.
Protocole de contexte de modèle (MCP)
Le MCP est un standard émergent qui permet aux modèles d’IA de se connecter à des outils et services externes de manière cohérente. Au lieu de simplement générer du texte, l’IA peut désormais planifier vos réunions, mettre à jour votre calendrier ou extraire des informations de vos bases de données. D’un point de vue technique, le MCP crée un protocole de communication standardisé qui permet à l’IA d’interagir en toute sécurité avec différents systèmes logiciels via des interfaces et des permissions définies. Cela transforme l’IA d’un répondeur passif en un assistant actif capable d’effectuer des actions réelles tout en maintenant la sécurité grâce à des modèles d’accès contrôlés et des pistes d’audit.
Voici un article qui vous permet d’en apprendre davantage : Qu’est-ce que le MCP ? Guide du développeur sur le protocole de contexte de modèle .
L’intelligence artificielle est un domaine en évolution rapide qui combine des concepts fondamentaux, des outils avancés et des considérations éthiques pour créer des systèmes puissants capables de transformer les industries. Alors que l’IA continue de progresser, rester informé de ses concepts et de ses applications est essentiel pour libérer tout son potentiel. Passer à la pratique est également un excellent moyen de rester à jour avec les derniers développements et d’acquérir une expérience pratique.
Pour une durée limitée, les nouveaux utilisateurs peuvent obtenir 10 $ de crédits gratuits pour explorer et construire avec l’API LLM sur Novita AI. Ne manquez pas cette opportunité de plonger dans le monde de l’IA et de donner vie à vos idées !
À propos de Novita AI
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour construire et passer à l’échelle.



