

Терминология ИИ сейчас повсюду, и может быть сложно, когда все вокруг говорят на каком-то другом языке. Если вы когда-нибудь оказывались в разговоре, где кто-то упоминает «Песочницу», «RAG» или «MCP» и вы киваете на совещаниях, втайне задаваясь вопросом, что на самом деле означают эти термины, — это руководство для вас.
Технологии развиваются стремительно, но для понимания основ не требуется технического образования. Вот простое объяснение самых распространённых терминов ИИ, с которыми вы, скорее всего, столкнётесь. Они изложены простым языком и расположены так, чтобы постепенно выстраивать ваше понимание.

1. Основные концепции ИИ
Модели ИИ
Представьте модель ИИ как умную компьютерную программу, созданную для имитации человеческого мышления. Вы даёте ей ввод — например, вопрос или изображение — а она обрабатывает эту информацию и выдаёт осмысленный результат. Модели обучаются на огромном количестве примеров, распознают закономерности и постепенно улучшают свою способность понимать и отвечать.
Чтобы глубже изучить модели ИИ и узнать, как эффективно их развёртывать, ознакомьтесь с нашим Руководством по развёртыванию моделей Novita AI.
Нейронная сеть
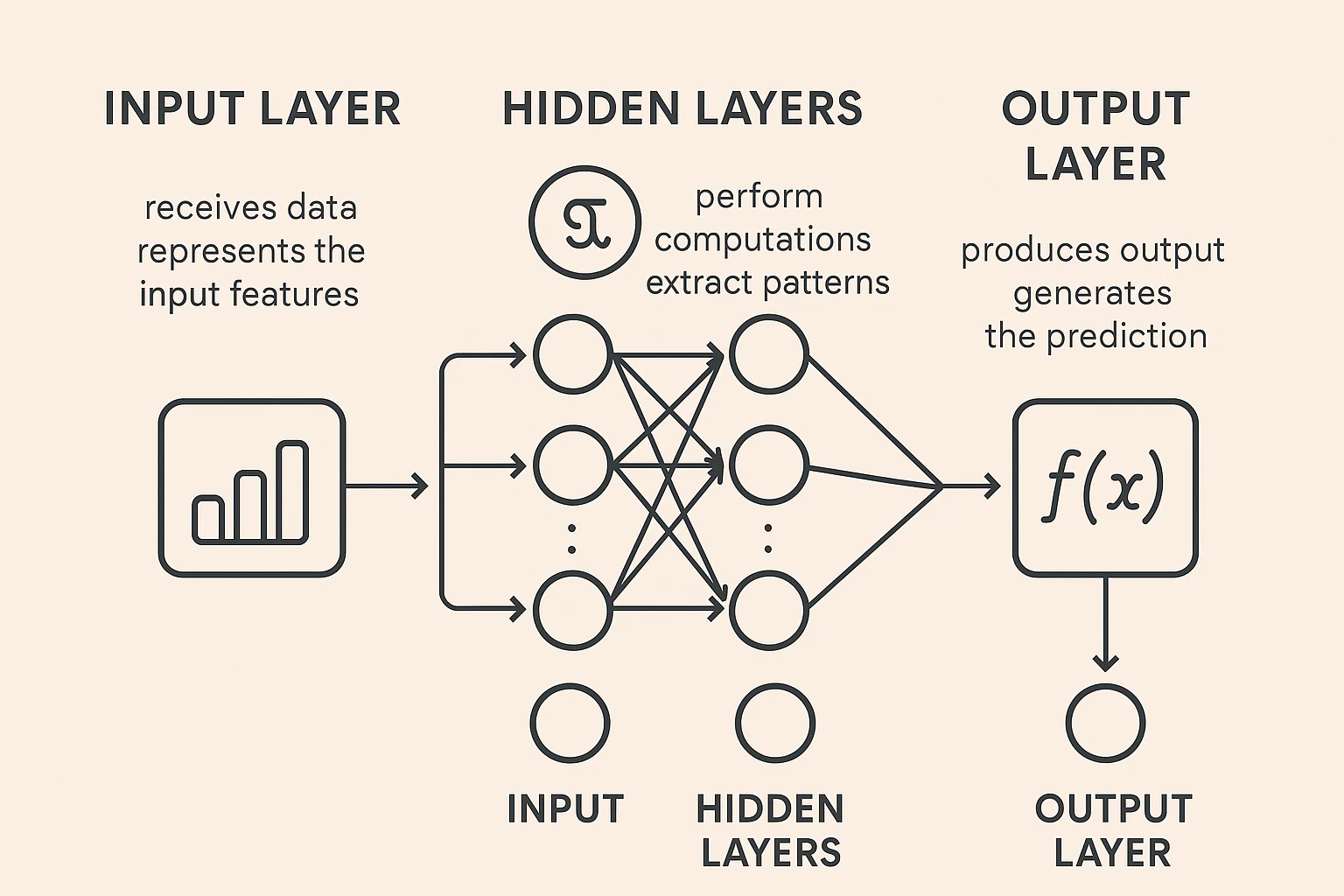
Представьте нейронную сеть как упрощённую версию работы нашего мозга. Она состоит из взаимосвязанных узлов (называемых искусственными нейронами), которые передают информацию друг другу — примерно как нейроны в нашей голове. Эти сети учатся лучше распознавать закономерности и принимать решения, регулируя веса связей между узлами — подобно тому, как мы учимся на опыте. Нейронные сети организованы в слои: входной слой получает данные, скрытые слои обрабатывают их с помощью сложных математических функций, а выходной слой выдаёт конечный результат. «Глубокое» в глубоком обучении означает сети со многими скрытыми слоями, что позволяет им изучать всё более сложные закономерности.
Архитектура трансформера
Трансформер — это прорывная технология, которая сделала возможным современный умный ИИ. До 2017 года ИИ должен был читать текст слово за словом, как книгу, водя пальцем по каждому слову. Трансформеры изменили это, позволив ИИ видеть все слова в предложении одновременно и понимать, как они связаны друг с другом, с помощью механизма «внимания». Это как разница между чтением по одному слову и мгновенным восприятием всего предложения. Механизм внимания позволяет модели сосредотачиваться на релевантных частях входа при генерации каждой части выхода, что делает её гораздо эффективнее в понимании контекста и связей в языке.
Большая языковая модель (LLM)
LLM — это модели ИИ, обученные специально понимать и генерировать человеческий язык. Они читают миллиарды слов и учатся предсказывать, что идёт дальше в предложении, что позволяет им писать эссе, отвечать на вопросы или естественно общаться. Во время обучения они анализируют закономерности в тексте, чтобы понять грамматику, контекст и значение. Современные LLM эволюционировали в мультимодальные модели, то есть могут обрабатывать не только текст, но и изображения, аудио и многое другое — всё в одном интерфейсе. Например, GPT-4o может одновременно принимать текст, голос и изображения, делая взаимодействие более богатым и универсальным. «Большая» относится к огромному числу параметров (часто миллиардам), в которых хранятся изученные знания модели.
Общий искусственный интеллект (AGI)
AGI — это святой Грааль ИИ: система, которая была бы так же умна, как человек, во всех областях, а не только в конкретных задачах. В то время как сегодняшний ИИ превосходно справляется с конкретными вещами, такими как написание текстов или распознавание изображений, AGI сравнялся бы с человеческим интеллектом в творчестве, рассуждении, обучении и решении проблем в любой области. С научной точки зрения, достижение AGI требует решения фундаментальных задач, включая обучение с переносом (применение знаний в разных областях), обучение по малому количеству примеров, причинно-следственное мышление и разработку более эффективных алгоритмов обучения. Современные системы ИИ считаются «узкими», потому что они превосходны в конкретных задачах, но им не хватает общего интеллекта и адаптивности, характерных для человеческого познания.
Выравнивание ИИ
Выравнивание ИИ заключается в том, чтобы системы ИИ хотели того же, что и люди, и вели себя так, чтобы помогать, а не вредить нам. По мере того как ИИ становится мощнее, обеспечение соответствия нашим ценностям и целям становится всё более важным. Думайте об этом как о том, чтобы убедиться, что ИИ на нашей стороне. Это включает технические задачи, такие как обучение ценностям (обучение ИИ пониманию человеческих предпочтений), надёжность (обеспечение правильного поведения ИИ в новых ситуациях) и интерпретируемость (понимание причин, по которым ИИ принимает те или иные решения). Исследования выравнивания также затрагивают философские вопросы о том, с чьими ценностями выравниваться и как обрабатывать конфликтующие человеческие предпочтения.
2. Данные и обучение
Обучающие данные
Обучающие данные — это просто вся информация, используемая для обучения модели ИИ. Представьте их как учебники для ИИ. Для языковых моделей это миллионы книг, веб-сайтов, новостных статей и других письменных материалов. Чем разнообразнее и качественнее этот «учебный материал», тем лучше ИИ справляется с разными темами и ситуациями. Качество данных критически важно: предвзятые или неверные обучающие данные приводят к предвзятым или неверным результатам ИИ. Процесс обучения включает показ модели бесчисленного количества примеров, чтобы она могла изучить статистические закономерности и взаимосвязи в данных.
Предварительное обучение
Предварительное обучение — это как школа для ИИ: на этом этапе модели изучают основы. Во время этой фазы ИИ читает огромные объёмы текста и усваивает фундаментальные закономерности языка, факты о мире и способы рассуждения. Это, по сути, общее образование ИИ до того, как он специализируется на чём-то конкретном. Предварительное обучение использует обучение без учителя, то есть модель учится на закономерностях без явных меток или ответов. Этот этап требует больших вычислительных затрат, часто занимает недели или месяцы на мощных кластерах компьютеров, но создаёт основу общих знаний, которые можно применять для множества разных задач.
Тонкая настройка
Тонкая настройка — это как специализированное обучение после выпуска. После того как ИИ получил общее образование через предварительное обучение, его можно дополнительно обучать на конкретных типах контента или задач. Например, общий ИИ можно тонко настроить на медицинских журналах, чтобы он лучше отвечал на вопросы о здравоохранении, или обучить на диалогах службы поддержки, чтобы он перенял определённый тон и стиль компании. Этот процесс требует гораздо меньше данных и вычислительных ресурсов, чем предварительное обучение, потому что модель уже понимает основы языка. Тонкая настройка корректирует параметры модели для оптимизации производительности в конкретных областях или приложениях, сохраняя при этом общие способности.
Обучение с подкреплением на основе человеческой обратной связи (RLHF)
RLHF — это как если бы учителя-люди оценивали домашнюю работу ИИ и говорили, что делает ответ хорошим. Люди оценивают разные ответы ИИ, и модель учится выдавать результаты, которые люди считают полезными, точными и уместными. Этот процесс критически важен для создания систем ИИ, которые ведут себя так, как мы хотим. RLHF обычно включает три шага: обучение модели вознаграждения на основе человеческих предпочтений, использование обучения с подкреплением для оптимизации поведения ИИ в соответствии с этой моделью вознаграждения и итеративное улучшение с помощью дополнительной обратной связи. Этот метод помогает согласовать поведение ИИ с человеческими ценностями и уменьшает количество вредных или нежелательных ответов.
3. Механизмы ввода и вывода
Токен
Токен — это то, как ИИ «считает» текст: примерно один токен на слово, хотя это могут быть части слов, знаки препинания или даже пробелы. Модели ИИ имеют ограничения на количество токенов, которые они могут обработать за раз (так называемое окно контекста), поэтому иногда они не могут обработать очень длинные документы или запомнить всё из длительного разговора. Разные языки и системы письма требуют разных стратегий токенизации. Понимание токенов важно, потому что модели ИИ обрабатывают текст последовательно как токены, и ограничение токенов определяет как длину ввода, так и объём памяти при разговоре.
Инференс
Инференс — это просто момент, когда ИИ выполняет свою работу: принимает ваш ввод и выдаёт результат. Когда вы печатаете вопрос в ChatGPT и получаете ответ, это и есть инференс. Он отличается от обучения, когда ИИ учится на данных. Во время инференса модель использует свои изученные параметры для обработки новых вводов и генерации ответов. Этот процесс намного быстрее и требует меньше ресурсов, чем обучение, но всё ещё требует значительных вычислительных мощностей для больших моделей. Качество инференса зависит как от обучения модели, так и от того, насколько хорошо ввод соответствует закономерностям, которые модель видела раньше.
Промпт-инжиниринг
Промпт-инжиниринг — это искусство и наука задавать ИИ правильный вопрос правильным способом. Точно так же, как чёткий конкретный вопрос к человеку даёт лучший ответ, чем расплывчатый, грамотно составленные промпты могут значительно улучшить то, что вы получаете от ИИ. Эффективные промпты часто включают чёткие инструкции, релевантный контекст, примеры желаемого формата вывода и конкретные ограничения или требования. Продвинутые техники включают промптинг с цепочкой рассуждений (попросить ИИ показать свои рассуждения), обучение на нескольких примерах (few-shot learning) и объединение промптов в цепочки (разбиение сложных задач на шаги). Цель — чётко передать намерение, оптимально используя возможности модели.
Галлюцинация
Когда ИИ «галлюцинирует», он выдумывает то, что звучит убедительно, но не является правдой. Это происходит, когда ИИ пытается заполнить пробелы в своих знаниях или когда его спрашивают о чём-то, чего он на самом деле не понимает. Это как если бы кто-то уверенно давал вам указания в место, где никогда не был, — уверенность не делает указания верными. Галлюцинации возникают потому, что языковые модели обучены генерировать правдоподобно звучащий текст, а не обязательно точную информацию. Они могут выдумывать факты, цитаты или детали, сохраняя уверенный тон. Понимание этого ограничения крайне важно для ответственного использования ИИ, и такие техники, как проверка фактов и верификация источников, остаются важными.

4. Инструменты ИИ и продвинутые приложения
Интерфейс прикладного программирования (API)
API — это как официант в ресторане: он принимает ваш заказ (запрос) на кухню (система ИИ) и приносит еду (ответ). В мире ИИ API позволяют разным программам общаться с моделями ИИ, не создавая ИИ с нуля. Компании могут подключаться к существующим сервисам ИИ через API. API определяют конкретный формат запросов и ответов, включая такие параметры, как максимальная длина вывода, уровень креативности (температура) и формат ответа. Они обрабатывают аутентификацию, ограничение частоты запросов и управление ошибками, что упрощает разработчикам интеграцию возможностей ИИ в приложения, веб-сайты или сервисы без необходимости глубоких знаний в области ИИ.
Мультимодальный ИИ
Мультимодальный ИИ может работать с разными типами контента одновременно — текстом, изображениями, голосом и видео. Это как разговор с человеком, который одновременно видит, что вы ему показываете, слышит, что вы говорите, и читает написанное. Это делает взаимодействие с ИИ гораздо более естественным и похожим на человеческое. Мультимодальные модели используют разные архитектуры нейронных сетей для разных типов ввода (трансформеры для зрения для изображений, аудиокодеры для звука), но объединяют их в единое представление. Это позволяет ИИ понимать связи между разными модальностями, например, описывать происходящее на видео или отвечать на вопросы об изображениях.
Генерация с дополненной выборкой (RAG)
RAG — это как предоставить ИИ доступ к актуальной библиотеке, пока он отвечает на ваши вопросы. Вместо того чтобы использовать только то, что он выучил во время обучения, системы RAG могут искать в актуальных базах данных и документах релевантную информацию перед формированием ответа. Это помогает гарантировать точность и актуальность ответов. RAG работает в два этапа: сначала система поиска находит релевантные документы или информацию на основе запроса, затем языковая модель генерирует ответ, используя как свои знания, полученные при обучении, так и найденную информацию. Такой подход уменьшает количество галлюцинаций, обеспечивает доступ к актуальной информации и позволяет ИИ работать с проприетарными или специализированными базами знаний.
Эта статья поможет узнать больше: Что такое RAG: Полное введение в Retrieval Augmented Generation
Песочница
Песочница — это как безопасный манеж для ИИ: изолированная среда, где ИИ может запускать код, работать с инструментами или экспериментировать без какого-либо риска для ваших основных систем. Это как позволить ребёнку играть в огороженной зоне, где он не может ничего сломать. Песочницы используют контейнеризацию, виртуальные машины или другие технологии изоляции для создания контролируемых сред с ограниченным доступом к системным ресурсам, сетевым подключениям и конфиденциальным данным. Это позволяет агентам ИИ выполнять код, взаимодействовать с API или тестировать решения, предотвращая потенциальные нарушения безопасности, повреждение данных или сбои системы.
Это довольно сложное понятие; если хотите узнать больше, вот отличная статья от нас, в которой мы глубоко погружаемся в эту тему: Как песочницы агентов обеспечивают безопасные и масштабируемые инновации ИИ.
Выделенная конечная точка LLM
Выделенная конечная точка LLM — это как прямая телефонная линия к конкретной модели ИИ, оптимизированная для ваших нужд. Вместо того чтобы делить ресурсы со всеми остальными, вы получаете выделенное соединение, которое можно настроить для вашего конкретного случая использования. Это включает настройку изолированных вычислительных ресурсов (GPU, память, пропускная способность) с пользовательскими конфигурациями, такими как скорость ответа, стиль вывода, фильтры безопасности и гарантии производительности. Выделенные конечные точки обеспечивают стабильную задержку, более высокую пропускную способность и возможность точной настройки моделей специально для ваших приложений, гарантируя при этом конфиденциальность данных и соответствие корпоративным требованиям безопасности.
Эта статья поможет узнать больше: Выделенная конечная точка LLM на Novita AI: пользовательские модели, ценообразование на основе использования и масштабирование без DevOps.
Протокол контекста модели (MCP)
MCP — это новый стандарт, который позволяет моделям ИИ подключаться к внешним инструментам и сервисам единообразным способом. Вместо того чтобы просто генерировать текст, ИИ теперь может планировать ваши встречи, обновлять календарь или извлекать информацию из ваших баз данных. С технической точки зрения, MCP создаёт стандартизированный коммуникационный протокол, который позволяет ИИ безопасно взаимодействовать с различными программными системами через определённые интерфейсы и разрешения. Это превращает ИИ из пассивного ответчика в активного помощника, который может выполнять реальные действия, сохраняя безопасность через контролируемые схемы доступа и журналы аудита.
Вот статья, которая поможет узнать больше: Что такое MCP? Руководство разработчика по протоколу контекста модели.
Искусственный интеллект — это быстро развивающаяся область, объединяющая фундаментальные концепции, продвинутые инструменты и этические соображения для создания мощных систем, способных преобразовывать отрасли. По мере развития ИИ важно оставаться в курсе его концепций и приложений, чтобы полностью раскрыть его потенциал. Переход к практическому применению — отличный способ оставаться на связи с последними разработками и получить практический опыт.
На ограниченное время новые пользователи могут получить $10 бесплатных кредитов, чтобы исследовать и создавать с помощью LLM API на Novita AI. Не упустите возможность погрузиться в мир ИИ и воплотить свои идеи в жизнь!
О Novita AI
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развёртывания моделей ИИ с помощью нашего простого API, а также предоставляет доступное и надёжное GPU-облако для создания и масштабирования.



