

مصطلحات الذكاء الاصطناعي منتشرة في كل مكان هذه الأيام، وقد يكون الأمر مربكًا عندما يبدو أن الجميع يتحدثون بلغة مختلفة. إذا كنت يومًا في محادثة ذكر فيها أحدهم “الاختبار المعزول” (Sandbox) أو “RAG” أو “MCP” وتجد نفسك تومئ برأسك في الاجتماعات بينما تتساءل سرًا عن معنى نصف هذه المصطلحات، فهذا الدليل لك.
تتطور التكنولوجيا بسرعة، لكن فهم الأساسيات لا يتطلب خلفية تقنية. إليك تحليلًا مباشرًا لأكثر مصطلحات الذكاء الاصطناعي شيوعًا التي قد تصادفها، موضحة بلغة بسيطة ومرتبة لبناء فهمك خطوة بخطوة.

1. مفاهيم أساسية في الذكاء الاصطناعي
نماذج الذكاء الاصطناعي
فكر في نموذج الذكاء الاصطناعي كبرنامج كمبيوتر ذكي مصمم لتقليد التفكير البشري. تعطيه مدخلات - مثل سؤال أو صورة - فيقوم بمعالجة تلك المعلومات لتوليد مخرجات ذات معنى. تتعلم النماذج من خلال تحليل كميات هائلة من الأمثلة، والتعرف على الأنماط، وتحسين قدرتها تدريجيًا على الفهم والاستجابة.
للتعمق أكثر في نماذج الذكاء الاصطناعي وكيفية نشرها بكفاءة، راجع دليل نشر نماذج Novita AI.
الشبكة العصبية
فكر في الشبكة العصبية كنسخة مبسطة من كيفية عمل أدمغتنا. تتكون من عقد مترابطة (تسمى الخلايا العصبية الاصطناعية) تنقل المعلومات لبعضها البعض، شبيهة بالخلايا العصبية في رؤوسنا. تتحسن هذه الشبكات في التعرف على الأنماط واتخاذ القرارات عن طريق ضبط أوزان الاتصالات بين العقد - على غرار كيف نتعلم من التجربة. تُنظم الشبكات العصبية في طبقات: طبقة إدخال تستقبل البيانات، وطبقات مخفية تعالجها عبر دوال رياضية معقدة، وطبقة إخراج تنتج النتيجة النهائية. يشير “العميق” في التعلم العميق إلى شبكات تحتوي على طبقات مخفية عديدة، مما يسمح لها بتعلم أنماط متزايدة التعقيد.
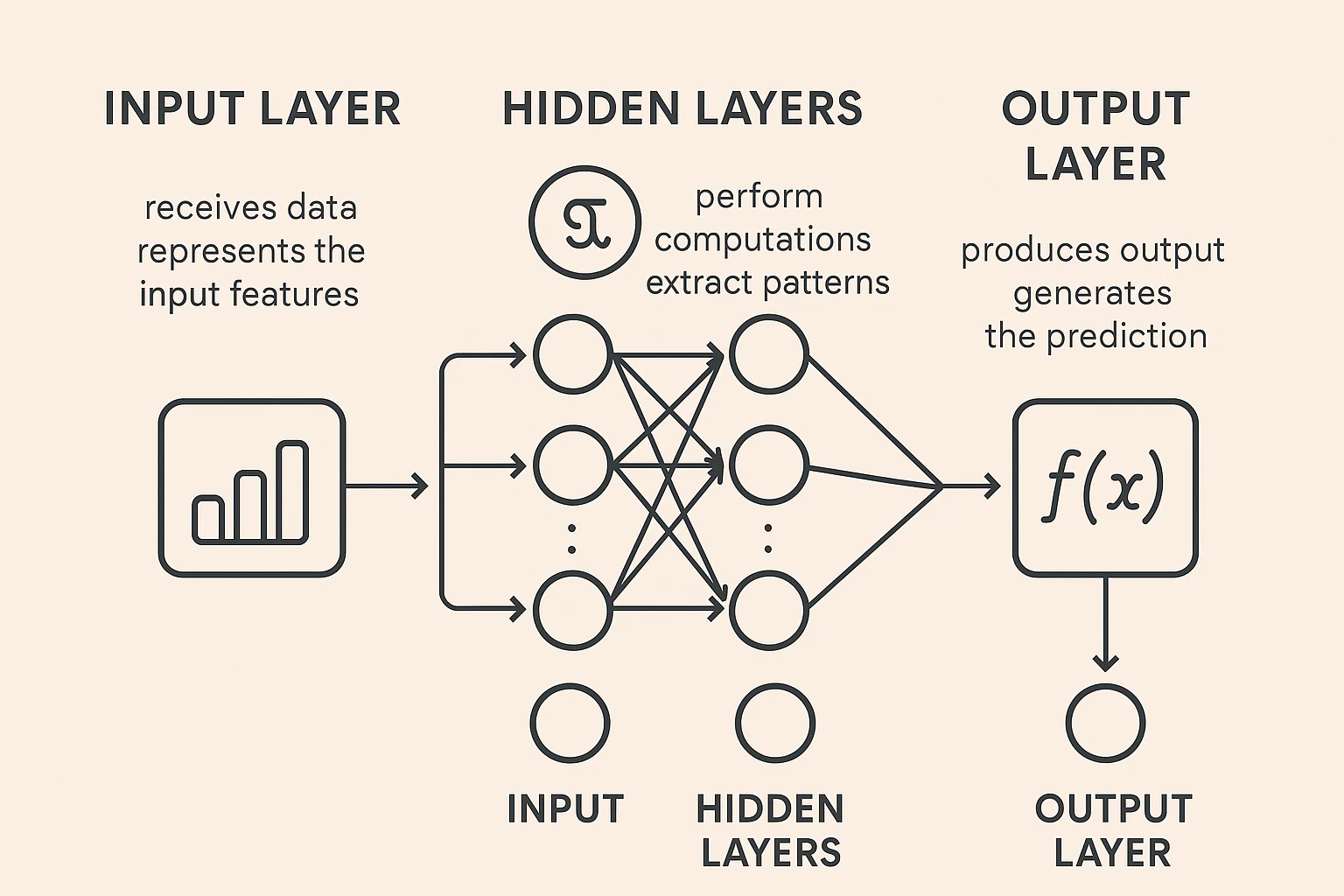
هندسة المحولات
المحول هو التقنية الرائدة التي جعلت الذكاء الاصطناعي الحديث ممكنًا. قبل عام 2017، كان على الذكاء الاصطناعي قراءة النص كلمة بكلمة، كقراءة كتاب بإصبع يتبع كل كلمة. غيرت المحولات هذا الأمر بالسماح للذكاء الاصطناعي برؤية كل الكلمات في الجملة مرة واحدة وفهم كيفية ارتباطها ببعضها البعض من خلال آلية تسمى “الانتباه”. الأمر يشبه الفرق بين قراءة كلمة واحدة في كل مرة مقابل استيعاب الجملة بأكملها فورًا. تسمح آلية الانتباه للنموذج بالتركيز على الأجزاء ذات الصلة من المدخلات عند توليد كل جزء من المخرجات، مما يجعله أكثر فعالية في فهم السياق والعلاقات في اللغة.
نموذج اللغة الكبير (LLM)
نماذج LLM هي نماذج ذكاء اصطناعي مدربة خصيصًا لفهم وتوليد اللغة البشرية. تقرأ مليارات الكلمات وتتعلم التنبؤ بما سيأتي بعد ذلك في الجملة، مما يمكنها من كتابة المقالات أو الإجابة على الأسئلة أو الدردشة بشكل طبيعي. أثناء التدريب، تحلل الأنماط في النص لفهم القواعد والسياق والمعنى. تطورت نماذج LLM الحديثة إلى نماذج متعددة الوسائط، مما يعني أنها تستطيع معالجة ليس فقط النص ولكن أيضًا الصور والصوت والمزيد - كل ذلك ضمن واجهة واحدة. على سبيل المثال، يمكن لـ GPT-4o قبول النص والصوت والصور في وقت واحد، مما يجعل التفاعلات أكثر ثراءً وتنوعًا. يشير “الكبير” إلى العدد الهائل من المعاملات (غالبًا مليارات) التي تخزن المعرفة المكتسبة للنموذج.
الذكاء الاصطناعي العام (AGI)
الذكاء الاصطناعي العام هو الكأس المقدسة للذكاء الاصطناعي - نظام سيكون ذكيًا مثل البشر في جميع المجالات، وليس فقط في مهام محددة. بينما يتفوق الذكاء الاصطناعي الحالي في أشياء معينة مثل الكتابة أو التعرف على الصور، فإن الذكاء الاصطناعي العام سيكون مماثلاً للذكاء البشري في الإبداع والاستدلال والتعلم وحل المشكلات عبر أي مجال. علميًا، يتطلب تحقيق الذكاء الاصطناعي العام حل تحديات أساسية بما في ذلك التعلم بالنقل (تطبيق المعرفة عبر المجالات)، والتعلم من أمثلة قليلة، والاستدلال السببي، وتطوير خوارزميات تعلم أكثر كفاءة. تعتبر أنظمة الذكاء الاصطناعي الحالية “ضيقة” لأنها تتفوق في مهام محددة لكنها تفتقر إلى الذكاء العام والقدرة على التكيف التي تميز الإدراك البشري.
مواءمة الذكاء الاصطناعي
مواءمة الذكاء الاصطناعي تعني التأكد من أن أنظمة الذكاء الاصطناعي تريد نفس الأشياء التي يريدها البشر وتتصرف بطرق تساعدنا بدلاً من أن تضرنا. مع ازدياد قوة الذكاء الاصطناعي، يصبح ضمان مشاركته لقيمنا وأهدافنا أمرًا بالغ الأهمية. فكر في الأمر على أنه التأكد من أن الذكاء الاصطناعي في فريقنا. يتضمن ذلك تحديات تقنية مثل تعلم القيم (تعليم الذكاء الاصطناعي فهم التفضيلات البشرية)، والمتانة (ضمان تصرف الذكاء الاصطناعي بشكل صحيح في المواقف الجديدة)، وقابلية التفسير (فهم لماذا يتخذ الذكاء الاصطناعي قرارات معينة). يتناول بحث المواءمة أيضًا أسئلة فلسفية حول قيم من يجب المواءمة معها وكيفية التعامل مع التفضيلات البشرية المتضاربة.
2. البيانات والتدريب
بيانات التدريب
بيانات التدريب هي ببساطة كل المعلومات المستخدمة لتعليم نموذج الذكاء الاصطناعي - فكر فيها ككتب النموذج الدراسية. بالنسبة لنماذج اللغة، يشمل ذلك ملايين الكتب والمواقع الإلكترونية والمقالات الإخبارية والمحتوى المكتوب الآخر. كلما كانت هذه “المواد القرائية” أكثر تنوعًا وجودة، أصبح الذكاء الاصطناعي أفضل في التعامل مع المواضيع والمواقف المختلفة. جودة البيانات أمر بالغ الأهمية: بيانات التدريب المتحيزة أو غير الصحيحة تؤدي إلى مخرجات ذكاء اصطناعي متحيزة أو غير صحيحة. تتضمن عملية التدريب عرض أمثلة لا حصر لها على النموذج حتى يتعلم الأنماط والعلاقات الإحصائية داخل البيانات.
التدريب المسبق
التدريب المسبق يشبه ذهاب الذكاء الاصطناعي إلى المدرسة الابتدائية - حيث تتعلم النماذج الأساسيات. خلال هذه المرحلة، يقرأ الذكاء الاصطناعي كميات هائلة من النص ويتعلم أنماطًا أساسية حول اللغة وحقائق عن العالم وكيفية التفكير. إنه في الأساس التعليم العام للذكاء الاصطناعي قبل أن يتخصص في شيء محدد. يستخدم التدريب المسبق التعلم غير الخاضع للإشراف، مما يعني أن النموذج يتعلم الأنماط دون تسميات أو إجابات صريحة. هذه المرحلة مكلفة حسابيًا، وغالبًا ما تتطلب أسابيع أو أشهر على مجموعات حاسوبية قوية، لكنها تنشئ أساسًا من المعرفة العامة يمكن تطبيقه على العديد من المهام المختلفة.
الضبط الدقيق
الضبط الدقيق يشبه التدريب المتخصص بعد التخرج. بمجرد حصول الذكاء الاصطناعي على تعليمه العام من خلال التدريب المسبق، يمكن تدريبه بشكل أكبر على أنواع محددة من المحتوى أو المهام. على سبيل المثال، يمكن ضبط ذكاء اصطناعي عام بدقة على المجلات الطبية ليصبح أفضل في الأسئلة الصحية، أو تدريبه على محادثات خدمة العملاء لتبني نغمة وأسلوب معينين للشركة. تتطلب هذه العملية بيانات وموارد حاسوبية أقل بكثير من التدريب المسبق لأن النموذج يفهم بالفعل أساسيات اللغة. يضبط الضبط الدقيق معاملات النموذج لتحسين الأداء لمجالات أو تطبيقات محددة مع الحفاظ على القدرات العامة.
التعلم التعزيزي من التغذية الراجعة البشرية (RLHF)
RLHF يشبه وجود معلمين بشريين يصححون واجبات الذكاء الاصطناعي ويخبرونه ما الذي يجعل الإجابة جيدة. يقوم البشر بتقييم استجابات الذكاء الاصطناعي المختلفة، ويتعلم النموذج إنتاج مخرجات يجدها الناس مفيدة ودقيقة ومناسبة. هذه العملية حاسمة لجعل أنظمة الذكاء الاصطناعي تتصرف بالطريقة التي نريدها. يتضمن RLHF عادةً ثلاث خطوات: تدريب نموذج مكافأة بناءً على التفضيلات البشرية، واستخدام التعلم التعزيزي لتحسين سلوك الذكاء الاصطناعي وفقًا لنموذج المكافأة هذا، والتحسين التكراري من خلال المزيد من التغذية الراجعة البشرية. تساعد هذه التقنية في مواءمة سلوك الذكاء الاصطناعي مع القيم البشرية وتقليل المخرجات الضارة أو غير المرغوب فيها.
3. آليات الإدخال والإخراج
الرمز (Token)
الرمز هو بشكل أساسي كيفية “عد” الذكاء الاصطناعي للنص - تقريبًا رمز واحد لكل كلمة، على الرغم من أنه يمكن أن يكون أجزاء من الكلمات أو علامات ترقيم أو حتى مسافات. نماذج الذكاء الاصطناعي لها حدود على عدد الرموز التي يمكنها معالجتها في وقت واحد (تسمى نافذة السياق)، ولهذا السبب في بعض الأحيان لا تستطيع معالجة المستندات الطويلة جدًا أو تذكر كل شيء من محادثة طويلة. تتطلب اللغات وأنظمة الكتابة المختلفة استراتيجيات تجزئة مختلفة. فهم الرموز مهم لأن نماذج الذكاء الاصطناعي تعالج النص بشكل تسلسلي كرموز، ويحدد حد الرمز كلاً من طول الإدخال ومدى الذاكرة أثناء المحادثات.
الاستدلال (Inference)
الاستدلال هو ببساطة اللحظة التي يقوم فيها الذكاء الاصطناعي بعمله - أخذ مدخلاتك وإنتاج مخرجات. عندما تكتب سؤالاً في ChatGPT وتحصل على إجابة، فهذا هو الاستدلال. إنه يختلف عن التدريب، حيث يتعلم الذكاء الاصطناعي من البيانات. أثناء الاستدلال، يستخدم النموذج معاملاته المكتسبة لمعالجة المدخلات الجديدة وتوليد الاستجابات. هذه العملية أسرع بكثير وأقل استهلاكًا للموارد من التدريب، ولكنها لا تزال تتطلب قوة حاسوبية كبيرة للنماذج الكبيرة. تعتمد جودة الاستدلال على كل من تدريب النموذج ومدى تطابق المدخلات مع الأنماط التي رآها النموذج من قبل.
هندسة الاستفسار (Prompt Engineering)
هندسة الاستفسار هي فن وعلم طرح السؤال الصحيح على الذكاء الاصطناعي بالطريقة الصحيحة. مثلما أن طرح سؤال واضح ومحدد على شخص ما يعطيك إجابة أفضل من سؤال غامض، فإن صياغة استفسارات جيدة يمكن أن تحسن بشكل كبير ما تحصل عليه من الذكاء الاصطناعي. غالبًا ما تتضمن الاستفسارات الفعالة تعليمات واضحة، وسياقًا ذا صلة، وأمثلة على تنسيق الإخراج المطلوب، وقيودًا أو متطلبات محددة. تشمل التقنيات المتقدمة استفسار سلسلة الأفكار (طلب إظهار المنطق من الذكاء الاصطناعي)، والتعلم بعدة أمثلة قليلة (توفير أمثلة)، وتسلسل الاستفسارات (تقسيم المهام المعقدة إلى خطوات). الهدف هو توصيل النية بوضوح مع الاستفادة المثلى من قدرات النموذج.
الهلوسة (Hallucination)
عندما “يهلوس” الذكاء الاصطناعي، فإنه يختلق أشياء تبدو مقنعة لكنها غير حقيقية. يحدث هذا عندما يحاول الذكاء الاصطناعي سد الفجوات في معرفته أو يُسأل عن شيء لا يفهمه حقًا. إنه مثل عندما يعطيك شخص بثقة توجيهات إلى مكان لم يسبق له زيارته - الثقة لا تجعل التوجيهات صحيحة. تحدث الهلوسة لأن نماذج اللغة تُدرَّب على توليد نصوص تبدو معقولة، وليس بالضرورة معلومات دقيقة. يمكنها اختلاق الحقائق أو الاستشهادات أو التفاصيل مع الحفاظ على نبرة واثقة. فهم هذا القيد أمر بالغ الأهمية للاستخدام المسؤول للذكاء الاصطناعي، ولا تزال تقنيات مثل التحقق من الحقائق والتحقق من المصادر مهمة.

4. أدوات الذكاء الاصطناعي والتطبيقات المتقدمة
واجهة برمجة التطبيقات (API)
واجهة برمجة التطبيقات تشبه النادل في المطعم - يأخذ طلبك (الاستفسار) إلى المطبخ (نظام الذكاء الاصطناعي) ويعيد طعامك (الاستجابة). في عالم الذكاء الاصطناعي، تسمح واجهات API لبرامج مختلفة بالتحدث مع نماذج الذكاء الاصطناعي دون الحاجة إلى بناء النموذج من الصفر. يمكن للشركات الاتصال بخدمات الذكاء الاصطناعي الحالية من خلال واجهات API. تحدد واجهات API التنسيق المحدد للطلبات والاستجابات، بما في ذلك معاملات مثل الحد الأقصى لطول الإخراج، ومستوى الإبداع (درجة الحرارة)، وتنسيق الاستجابة. تتعامل مع المصادقة وتحديد المعدل وإدارة الأخطاء، مما يسهل على المطورين دمج قدرات الذكاء الاصطناعي في التطبيقات أو المواقع الإلكترونية أو الخدمات دون الحاجة إلى خبرة عميقة في الذكاء الاصطناعي.
الذكاء الاصطناعي متعدد الوسائط (Multimodal AI)
يمكن للذكاء الاصطناعي متعدد الوسائط التعامل مع أنواع مختلفة من المحتوى في وقت واحد - النص والصور والصوت والفيديو. إنه مثل التحدث مع شخص يمكنه رؤية ما تظهره له، وسماع ما تقوله، وقراءة ما كتبته، كل ذلك في وقت واحد. هذا يجعل تفاعلات الذكاء الاصطناعي تبدو أكثر طبيعية وشبه بشرية. تستخدم النماذج متعددة الوسائط بنى شبكات عصبية مختلفة لأنواع المدخلات المختلفة (محولات الرؤية للصور، ومشفِّرات الصوت للصوت) ولكنها تجمعها في فضاء تمثيل موحد. يسمح هذا للذكاء الاصطناعي بفهم العلاقات بين الوسائط المختلفة، مثل وصف ما يحدث في فيديو أو الإجابة على أسئلة حول الصور.
التوليد المعزز بالاسترجاع (RAG)
RAG يشبه إعطاء الذكاء الاصطناعي إمكانية الوصول إلى مكتبة حديثة أثناء إجابته على أسئلتك. بدلاً من استخدام ما تعلمه أثناء التدريب فقط، يمكن لأنظمة RAG البحث في قواعد البيانات والوثائق المحدثة للعثور على المعلومات ذات الصلة قبل صياغة الرد. هذا يساعد في ضمان أن الإجابات دقيقة وحديثة. يعمل RAG في خطوتين: أولاً، يبحث نظام استرجاع عن المستندات أو المعلومات ذات الصلة بناءً على الاستفسار، ثم يولد نموذج اللغة ردًا باستخدام كل من معرفته التدريبية والمعلومات المسترجعة. يقلل هذا النهج من الهلوسة، ويتيح الوصول إلى المعلومات الحالية، ويسمح للذكاء الاصطناعي بالعمل مع قواعد المعرفة الخاصة أو المتخصصة.
يساعدك هذا المقال في معرفة المزيد: ما هو RAG: مقدمة شاملة للتوليد المعزز بالاسترجاع
الاختبار المعزول (Sandbox)
الاختبار المعزول يشبه حقل لعب آمن للذكاء الاصطناعي - بيئة معزولة وآمنة حيث يمكن للذكاء الاصطناعي تشغيل الأكواد أو الوصول إلى الأدوات أو التجربة دون أي خطر على أنظمتك الرئيسية. إنه مثل السماح لطفل باللعب في منطقة مسيجة حيث لا يمكنه كسر أي شيء مهم. تستخدم الاختبارات المعزولة تقنيات العزل الحاسوبي مثل الحاويات (Containerization) أو الآلات الافتراضية لإنشاء بيئات محكومة مع وصول محدود إلى موارد النظام واتصالات الشبكة والبيانات الحساسة. يسمح هذا لوكلاء الذكاء الاصطناعي بتنفيذ الأكواد أو التفاعل مع واجهات API أو اختبار الحلول مع منع الاختراقات الأمنية المحتملة أو تلف البيانات أو تلف النظام.
هذا مفهوم معقد إلى حد ما، إذا كنت ترغب في استكشاف المزيد، إليك مقال رائع منا للتعمق فيه:كيف تعمل الاختبارات المعزولة للوكلاء على تمكين ابتكار الذكاء الاصطناعي الآمن والقابل للتوسع.
نقطة نهاية مخصصة لـ LLM
نقطة النهاية المخصصة لـ LLM تشبه وجود خط هاتف مباشر لنموذج ذكاء اصطناعي محدد، محسّن لاحتياجاتك الخاصة. بدلاً من مشاركة الموارد مع الجميع، تحصل على اتصال مخصص يمكن تخصيصه لحالة الاستخدام الخاصة بك. يتضمن ذلك إعداد موارد حاسوبية معزولة (وحدات معالجة رسومية GPU، ذاكرة، نطاق ترددي) مع تكوينات مخصصة مثل سرعة الاستجابة، ونمط الإخراج، ومرشحات الأمان، وضمانات الأداء. توفر نقاط النهاية المخصصة زمن وصول ثابتًا، وإنتاجية أعلى، والقدرة على ضبط النماذج بدقة خصيصًا لتطبيقاتك مع ضمان خصوصية البيانات وتلبية متطلبات الأمان المؤسسية.
يساعدك هذا المقال في معرفة المزيد: نقطة نهاية مخصصة لـ LLM على Novita AI: نماذج مخصصة، تسعير حسب الاستخدام، وتوسع بدون DevOps.
بروتوكول سياق النموذج (MCP)
MCP هو معيار ناشئ يسمح لنماذج الذكاء الاصطناعي بالاتصال بالأدوات والخدمات الخارجية بطريقة متسقة. بدلاً من مجرد توليد النص، يمكن للذكاء الاصطناعي الآن جدولة اجتماعاتك، أو تحديث تقويمك، أو سحب المعلومات من قواعد بياناتك. من الناحية التقنية، ينشئ MCP بروتوكول اتصال معياريًا يسمح للذكاء الاصطناعي بالتفاعل بأمان مع أنظمة برمجية مختلفة من خلال واجهات وأذونات محددة. يحول هذا الذكاء الاصطناعي من مستجيب سلبي إلى مساعد نشط يمكنه اتخاذ إجراءات حقيقية مع الحفاظ على الأمان من خلال أنماط الوصول الخاضعة للرقابة وسجلات التدقيق.
إليك مقال يساعدك في معرفة المزيد:ما هو MCP؟ دليل المطور لبروتوكول سياق النموذج .
الذكاء الاصطناعي هو مجال سريع التطور يجمع بين المفاهيم الأساسية والأدوات المتقدمة والاعتبارات الأخلاقية لإنشاء أنظمة قادرة على تحويل الصناعات. مع استمرار تقدم الذكاء الاصطناعي، يعد البقاء على اطلاع بمفاهيمه وتطبيقاته أمرًا أساسيًا لفتح إمكاناته الكاملة. الانتقال إلى الممارسة العملية هو أيضًا طريقة رائعة للبقاء على اطلاع بأحدث التطورات واكتساب خبرة عملية.
لفترة محدودة، يمكن للمستخدمين الجدد الحصول على 10 دولارات كرصيد مجاني لاستكشاف وبناء تطبيقات باستخدام واجهة برمجة تطبيقات LLM على Novita AI. لا تفوت هذه الفرصة للغوص في عالم الذكاء الاصطناعي وإضفاء الحياة على أفكارك!
حول Novita AI
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة تطبيقات بسيطة، مع توفير سحابة GPU ميسورة التكلفة وموثوقة للبناء.



