

KI-Fachbegriffe sind heutzutage überall, und es kann überwältigend sein, wenn alle eine andere Sprache zu sprechen scheinen. Wenn du jemals in einem Gespräch warst, in dem jemand „Sandbox“, „RAG" oder „MCP" erwähnt hat, und du in Meetings nicken musstest, während du insgeheim darüber rätseltest, was die Hälfte dieser Begriffe eigentlich bedeuten – dann ist dieser Leitfaden genau das Richtige für dich.
Technologie entwickelt sich rasant, aber die Grundlagen zu verstehen erfordert keinen technischen Hintergrund. Hier ist eine übersichtliche Aufschlüsselung der gängigsten KI-Begriffe, die dir wahrscheinlich begegnen werden – in einfacher Sprache erklärt und so angeordnet, dass du dein Verständnis Schritt für Schritt aufbauen kannst.

1. Grundlegende KI-Konzepte
KI-Modelle
Stell dir ein KI-Modell als ein intelligentes Computerprogramm vor, das menschliches Denken nachahmen soll. Du gibst ihm eine Eingabe – eine Frage oder ein Bild – und es verarbeitet diese Informationen, um eine sinnvolle Ausgabe zu erzeugen. Modelle lernen, indem sie eine riesige Menge an Beispielen analysieren, Muster erkennen und ihre Fähigkeit, zu verstehen und zu antworten, schrittweise verbessern.
Für einen tieferen Einblick in KI-Modelle und deren effiziente Bereitstellung, schau dir unsere Novita AI Model Deployment Guide an.
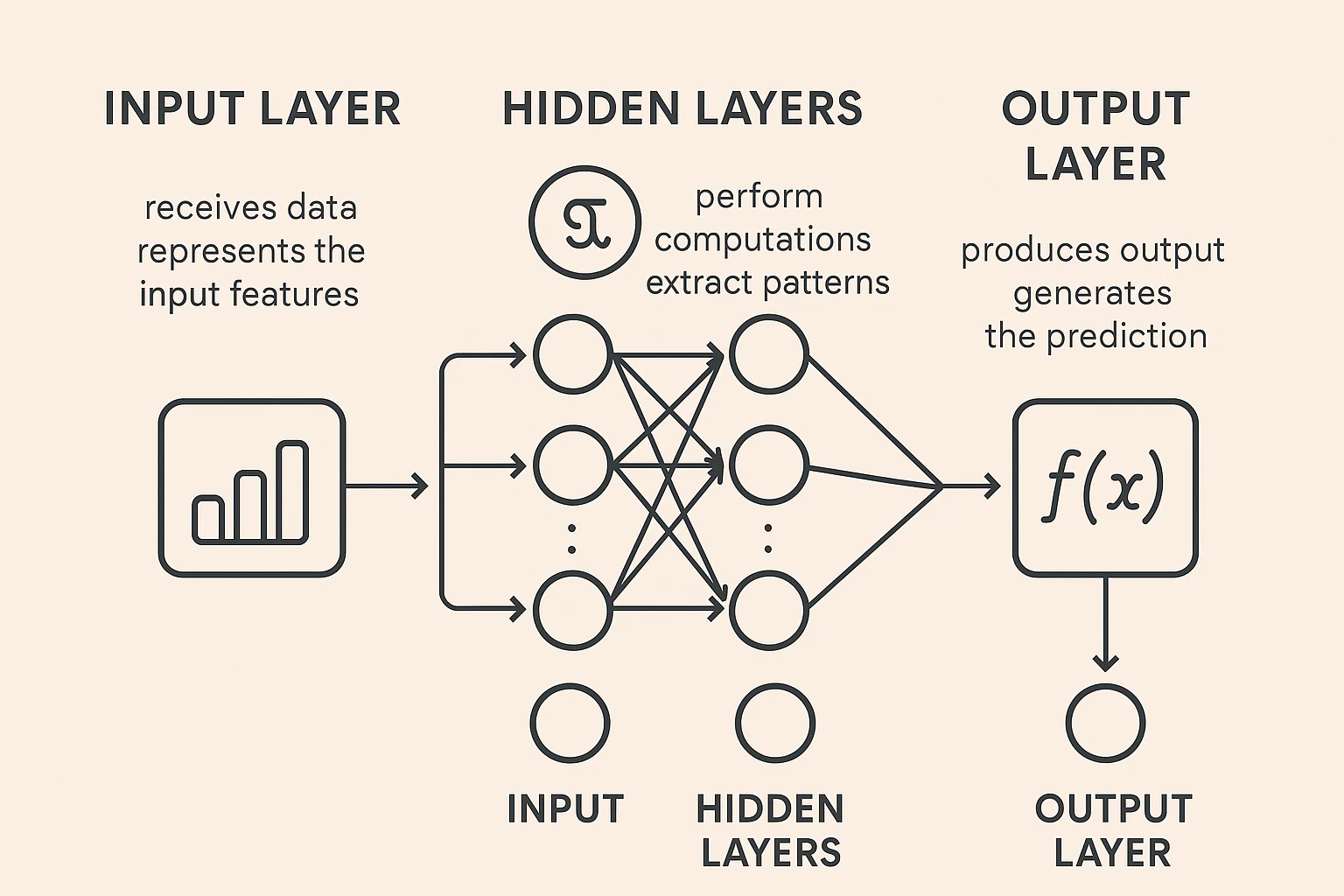
Neuronales Netzwerk
Stell dir ein neuronales Netz als eine vereinfachte Version unseres Gehirns vor. Es besteht aus miteinander verbundenen Knoten (sogenannten künstlichen Neuronen), die Informationen austauschen, ähnlich wie Neuronen in unserem Kopf. Diese Netzwerke verbessern ihre Fähigkeit, Muster zu erkennen und Entscheidungen zu treffen, indem sie die Gewichtungen der Verbindungen zwischen den Knoten anpassen – vergleichbar damit, wie wir aus Erfahrung lernen. Neuronale Netze sind in Schichten organisiert: Eine Eingabeschicht empfängt Daten, versteckte Schichten verarbeiten sie mit komplexen mathematischen Funktionen, und eine Ausgabeschicht liefert das Endergebnis. Das „tiefe“ Lernen bezieht sich auf Netze mit vielen versteckten Schichten, die es ihnen ermöglichen, immer komplexere Muster zu lernen.
Transformer-Architektur
Der Transformer ist die bahnbrechende Technologie, die die heutige intelligente KI möglich gemacht hat. Vor 2017 musste KI Text Wort für Wort lesen, wie das Lesen eines Buches, bei dem man jedem Wort mit dem Finger folgt. Transformer haben das geändert, indem sie der KI erlauben, alle Wörter eines Satzes gleichzeitig zu sehen und zu verstehen, wie sie durch einen Mechanismus namens „Attention“ (Aufmerksamkeit) zusammenhängen. Das ist der Unterschied zwischen dem Lesen eines Wortes nach dem anderen und dem sofortigen Erfassen des gesamten Satzes. Der Attention-Mechanismus ermöglicht es dem Modell, bei der Erzeugung jedes Ausgabeteils relevante Teile der Eingabe zu fokussieren, was die Verarbeitung von Kontext und Beziehungen in der Sprache wesentlich effektiver macht.
Großes Sprachmodell (Large Language Model, LLM)
LLMs sind KI-Modelle, die speziell dafür trainiert werden, menschliche Sprache zu verstehen und zu erzeugen. Sie lesen Milliarden von Wörtern und lernen, vorherzusagen, was als Nächstes in einem Satz kommt, was ihnen ermöglicht, Aufsätze zu schreiben, Fragen zu beantworten oder natürlich zu chatten. Während des Trainings analysieren sie Muster in Texten, um Grammatik, Kontext und Bedeutung zu verstehen. Moderne LLMs haben sich zu multimodalen Modellen entwickelt, die nicht nur Text, sondern auch Bilder, Audio und mehr verarbeiten können – alles in einer Oberfläche. GPT-4o kann beispielsweise gleichzeitig Text, Sprache und Bilder akzeptieren, was die Interaktionen reichhaltiger und vielseitiger macht. Das „Large“ bezieht sich auf die enorme Anzahl von Parametern (oft Milliarden), die das gelernte Wissen des Modells speichern.
Künstliche Allgemeine Intelligenz (AGI)
AGI ist der heilige Gral der KI – ein System, das in allen Bereichen so intelligent wie der Mensch wäre, nicht nur bei bestimmten Aufgaben. Während die heutige KI bei bestimmten Dingen wie Schreiben oder Bilderkennung herausragend ist, würde AGI die menschliche Intelligenz in Kreativität, logischem Denken, Lernen und Problemlösung in jedem Bereich erreichen. Wissenschaftlich betrachtet erfordert die Erreichung von AGI die Lösung grundlegender Herausforderungen, darunter Transferlernen (Wissen auf verschiedene Bereiche anwenden), Few-Shot-Lernen (aus minimalen Beispielen lernen), kausales Denken und die Entwicklung effizienterer Lernalgorithmen. Aktuelle KI-Systeme gelten als „schwach“, weil sie bei bestimmten Aufgaben hervorragend sind, aber nicht über die allgemeine Intelligenz und Anpassungsfähigkeit verfügen, die das menschliche Denken auszeichnet.
KI-Alignment
KI-Alignment bedeutet, sicherzustellen, dass KI-Systeme das Gleiche wollen wie Menschen und sich so verhalten, dass sie uns helfen statt schaden. Da KI immer leistungsfähiger wird, wird es immer wichtiger, dass sie unsere Werte und Ziele teilt. Stell es dir so vor, dass die KI in unserem Team ist. Dies umfasst technische Herausforderungen wie Werte lernen (der KI beibringen, menschliche Präferenzen zu verstehen), Robustheit (sicherstellen, dass sich die KI in neuen Situationen korrekt verhält) und Interpretierbarkeit (verstehen, warum die KI bestimmte Entscheidungen trifft). Die Alignment-Forschung befasst sich auch mit philosophischen Fragen, z. B. mit wessen Werten wir uns ausrichten sollen und wie mit widersprüchlichen menschlichen Präferenzen umzugehen ist.
2. Daten und Training
Trainingsdaten
Trainingsdaten sind einfach alle Informationen, die verwendet werden, um einem KI-Modell etwas beizubringen – stell sie dir als die Lehrbücher der KI vor. Bei Sprachmodellen umfassen sie Millionen von Büchern, Websites, Nachrichtenartikeln und anderen schriftlichen Inhalten. Je vielfältiger und qualitativ hochwertiger dieses „Lesematerial“ ist, desto besser wird die KI darin, verschiedene Themen und Situationen zu bewältigen. Die Datenqualität ist entscheidend: Verzerrte oder fehlerhafte Trainingsdaten führen zu verzerrten oder fehlerhaften KI-Outputs. Der Trainingsprozess besteht darin, dem Modell zahllose Beispiele zu zeigen, damit es statistische Muster und Beziehungen in den Daten lernen kann.
Pre-Training (Vortraining)
Pre-Training ist wie der Besuch der Grundschule für die KI – hier lernen die Modelle die Grundlagen. In dieser Phase liest die KI riesige Textmengen und lernt grundlegende Muster der Sprache, Fakten über die Welt und wie man logisch denkt. Es ist im Wesentlichen die allgemeine Bildung der KI, bevor sie sich auf etwas Spezifisches spezialisiert. Pre-Training verwendet unüberwachtes Lernen, d. h., das Modell lernt Muster ohne explizite Labels oder Antworten. Diese Phase ist rechenintensiv und erfordert oft Wochen oder Monate auf leistungsstarken Rechenclustern, schafft aber eine Grundlage allgemeinen Wissens, das auf viele verschiedene Aufgaben angewendet werden kann.
Fine-Tuning (Feinabstimmung)
Fine-Tuning ist wie eine Spezialausbildung nach dem Abschluss. Sobald eine KI ihre allgemeine Ausbildung durch Pre-Training erhalten hat, kann sie weiter auf bestimmte Inhalte oder Aufgaben trainiert werden. Beispielsweise könnte eine allgemeine KI auf medizinischen Fachzeitschriften feinabgestimmt werden, um besser bei Gesundheitsfragen zu sein, oder auf Kundendienstgesprächen, um den spezifischen Ton und Stil eines Unternehmens anzunehmen. Dieser Prozess erfordert viel weniger Daten und Rechenressourcen als Pre-Training, weil das Modell bereits die Grundlagen der Sprache versteht. Fine-Tuning passt die Parameter des Modells an, um die Leistung für bestimmte Bereiche oder Anwendungen zu optimieren, während die allgemeinen Fähigkeiten erhalten bleiben.
Verstärkendes Lernen aus menschlichem Feedback (Reinforcement Learning from Human Feedback, RLHF)
RLHF ist, als ob menschliche Lehrer die Hausaufgaben der KI benoten und ihr sagen, was eine gute Antwort ausmacht. Menschen bewerten verschiedene KI-Antworten, und das Modell lernt, Ergebnisse zu produzieren, die Menschen als hilfreich, genau und angemessen empfinden. Dieser Prozess ist entscheidend, damit KI-Systeme sich so verhalten, wie wir es wünschen. RLHF umfasst typischerweise drei Schritte: Trainieren eines Belohnungsmodells basierend auf menschlichen Präferenzen, Anwendung von verstärkendem Lernen zur Optimierung des KI-Verhaltens gemäß diesem Belohnungsmodell und iterative Verbesserung durch weiteres menschliches Feedback. Diese Technik hilft, das KI-Verhalten mit menschlichen Werten in Einklang zu bringen und schädliche oder unerwünschte Ergebnisse zu reduzieren.
3. Eingabe- und Ausgabemechanismen
Token
Ein Token ist im Grunde die Art und Weise, wie KI Text „zählt“ – ungefähr ein Token pro Wort, obwohl es Wortteile, Satzzeichen oder sogar Leerzeichen sein können. KI-Modelle haben Grenzen, wie viele Token sie auf einmal verarbeiten können (das sogenannte Kontextfenster), weshalb sie manchmal sehr lange Dokumente nicht verarbeiten oder sich nicht an alles aus einem langen Gespräch erinnern können. Unterschiedliche Sprachen und Schriftsysteme erfordern unterschiedliche Tokenisierungsstrategien. Das Verständnis von Token ist wichtig, weil KI-Modelle Text sequenziell als Token verarbeiten und das Token-Limit sowohl die Eingabelänge als auch die Gedächtnisspanne während Gesprächen bestimmt.
Inferenz
Inferenz ist einfach der Moment, in dem KI ihre Arbeit macht – deine Eingabe nimmt und eine Ausgabe produziert. Wenn du eine Frage in ChatGPT tippst und eine Antwort erhältst, ist das Inferenz. Es unterscheidet sich vom Training, bei dem die KI aus Daten lernt. Während der Inferenz verwendet das Modell seine erlernten Parameter, um neue Eingaben zu verarbeiten und Antworten zu generieren. Dieser Prozess ist viel schneller und weniger ressourcenintensiv als das Training, erfordert aber dennoch erhebliche Rechenleistung für große Modelle. Die Qualität der Inferenz hängt sowohl vom Training des Modells als auch davon ab, wie gut die Eingabe mit den Mustern übereinstimmt, die das Modell zuvor gesehen hat.
Prompt Engineering
Prompt Engineering ist die Kunst und Wissenschaft, der KI die richtige Frage auf die richtige Weise zu stellen. So wie eine klare, spezifische Frage an einen Menschen eine bessere Antwort ergibt als eine vage, kann die Formulierung guter Prompts das, was du von der KI bekommst, drastisch verbessern. Effektive Prompts enthalten oft klare Anweisungen, relevanten Kontext, Beispiele des gewünschten Ausgabeformats sowie spezifische Einschränkungen oder Anforderungen. Fortgeschrittene Techniken umfassen Chain-of-Thought-Prompting (die KI bitten, ihre Überlegungen darzulegen), Few-Shot-Learning (Beispiele geben) und Prompt-Chaining (Aufgaben in Schritte zerlegen). Ziel ist es, die Absicht klar zu kommunizieren und gleichzeitig die Fähigkeiten des Modells optimal zu nutzen.
Halluzination
Wenn KI „halluziniert“, erfindet sie Dinge, die überzeugend klingen, aber nicht wahr sind. Das passiert, wenn die KI versucht, Wissenslücken zu füllen oder nach etwas gefragt wird, das sie nicht wirklich versteht. Es ist, als ob dir jemand selbstbewusst den Weg zu einem Ort beschreibt, an dem er noch nie war – das Selbstbewusstsein macht die Wegbeschreibung nicht richtig. Halluzinationen treten auf, weil Sprachmodelle darauf trainiert sind, plausibel klingende Texte zu generieren, nicht unbedingt korrekte Informationen. Sie können Fakten, Zitate oder Details erfinden, während sie einen selbstbewussten Ton beibehalten. Das Verständnis dieser Einschränkung ist für einen verantwortungsvollen KI-Einsatz entscheidend, und Techniken wie Faktenprüfung und Quellenverifikation bleiben wichtig.

4. KI-Werkzeuge und fortgeschrittene Anwendungen
Anwendungsprogrammierschnittstelle (Application Programming Interface, API)
Eine API ist wie ein Kellner in einem Restaurant – sie nimmt deine Bestellung (Anfrage) entgegen, gibt sie an die Küche (KI-System) und bringt dein Essen (Antwort) zurück. In der KI-Welt ermöglichen APIs verschiedenen Softwareprogrammen, mit KI-Modellen zu kommunizieren, ohne die KI von Grund auf neu bauen zu müssen. Unternehmen können sich über APIs an bestehende KI-Dienste anschließen. APIs definieren das spezifische Format für Anfragen und Antworten, einschließlich Parametern wie maximale Ausgabelänge, Kreativitätsstufe (Temperatur) und Antwortformat. Sie kümmern sich um Authentifizierung, Ratenbegrenzung und Fehlerverwaltung, sodass Entwickler KI-Funktionen einfach in Anwendungen, Websites oder Dienste integrieren können, ohne tiefgehende KI-Kenntnisse zu benötigen.
Multimodale KI
Multimodale KI kann verschiedene Arten von Inhalten gleichzeitig verarbeiten – Text, Bilder, Sprache und Video. Es ist, als würde man sich mit jemandem unterhalten, der sehen kann, was man ihm zeigt, hören, was man sagt, und lesen, was man geschrieben hat – alles gleichzeitig. Dadurch fühlen sich KI-Interaktionen viel natürlicher und menschlicher an. Multimodale Modelle verwenden unterschiedliche neuronale Netzarchitekturen für verschiedene Eingabearten (Vision Transformer für Bilder, Audiocodierer für Töne), kombinieren diese aber in einem einheitlichen Darstellungsraum. Dadurch kann die KI Beziehungen zwischen verschiedenen Modalitäten verstehen, wie das Beschreiben dessen, was in einem Video passiert, oder das Beantworten von Fragen zu Bildern.
Retrieval-Augmented Generation (RAG)
RAG ist, als ob die KI während der Beantwortung deiner Fragen Zugriff auf eine aktuelle Bibliothek hätte. Anstatt nur das zu verwenden, was sie während des Trainings gelernt hat, können RAG-Systeme aktuelle Datenbanken und Dokumente durchsuchen, um relevante Informationen zu finden, bevor sie eine Antwort formulieren. Das hilft, sicherzustellen, dass Antworten genau und aktuell sind. RAG funktioniert in zwei Schritten: Zuerst sucht ein Retrieval-System nach relevanten Dokumenten oder Informationen basierend auf der Anfrage, dann generiert das Sprachmodell eine Antwort unter Verwendung sowohl seines Trainingswissens als auch der abgerufenen Informationen. Dieser Ansatz reduziert Halluzinationen, ermöglicht den Zugriff auf aktuelle Informationen und erlaubt der KI, mit proprietären oder spezialisierten Wissensbasen zu arbeiten.
Dieser Artikel hilft dir, mehr zu erfahren: What is RAG: A Comprehensive Introduction to Retrieval Augmented Generation
Sandbox
Eine Sandbox ist wie ein sicherer Spielbereich für KI – eine isolierte Umgebung, in der KI Code ausführen, auf Werkzeuge zugreifen oder experimentieren kann, ohne Risiko für deine Hauptsysteme. Es ist, wie ein Kind in einem abgesperrten Bereich spielen zu lassen, in dem es nichts Wichtiges kaputt machen kann. Sandboxes nutzen Containerisierung, virtuelle Maschinen oder andere Isolationstechnologien, um kontrollierte Umgebungen mit eingeschränktem Zugriff auf Systemressourcen, Netzwerkverbindungen und sensible Daten zu schaffen. Dadurch können KI-Agenten Code ausführen, mit APIs interagieren oder Lösungen testen, während potenzielle Sicherheitsverletzungen, Datenkorruption oder Systemschäden verhindert werden.
Dies ist ein ziemlich komplexes Konzept. Wenn du mehr erfahren möchtest, haben wir einen großartigen Artikel, der tiefer eintaucht: How Agent Sandboxes Power Secure, Scalable AI Innovation.
LLM-Dedicated-Endpoint
Ein LLM-Dedicated-Endpoint ist wie eine direkte Telefonleitung zu einem bestimmten KI-Modell, optimiert für deine speziellen Bedürfnisse. Anstatt Ressourcen mit allen anderen zu teilen, erhältst du eine dedizierte Verbindung, die für deinen spezifischen Anwendungsfall angepasst werden kann. Dies umfasst die Einrichtung isolierter Rechenressourcen (GPUs, Speicher, Bandbreite) mit benutzerdefinierten Konfigurationen wie Antwortgeschwindigkeit, Ausgabestil, Sicherheitsfiltern und Leistungsgarantien. Dedizierte Endpunkte bieten konsistente Latenz, höheren Durchsatz und die Möglichkeit, Modelle speziell für deine Anwendungen zu optimieren, während Datenschutz und Sicherheitsanforderungen von Unternehmen erfüllt werden.
Dieser Artikel hilft dir, mehr zu erfahren: LLM Dedicated Endpoint on Novita AI: Custom Models, Usage-Based Pricing, and DevOps-Free Scaling.
Model Context Protocol (MCP)
MCP ist ein aufkommender Standard, der es KI-Modellen ermöglicht, auf einheitliche Weise mit externen Werkzeugen und Diensten zu interagieren. Anstatt nur Text zu erzeugen, kann KI jetzt deine Meetings planen, deinen Kalender aktualisieren oder Informationen aus deinen Datenbanken abrufen. Aus technischer Sicht schafft MCP ein standardisiertes Kommunikationsprotokoll, das es der KI ermöglicht, sicher mit verschiedenen Softwaresystemen über definierte Schnittstellen und Berechtigungen zu interagieren. Dies verwandelt KI von einem passiven Antwortgeber in einen aktiven Assistenten, der echte Aktionen ausführen kann, während die Sicherheit durch kontrollierte Zugriffsmuster und Prüfpfade gewahrt bleibt.
Hier ist ein Artikel, der dir hilft, mehr zu erfahren: What is MCP? A Developer’s Guide to Model Context Protocol.
Künstliche Intelligenz ist ein sich schnell entwickelndes Feld, das grundlegende Konzepte, fortschrittliche Werkzeuge und ethische Überlegungen vereint, um leistungsstarke Systeme zu schaffen, die Branchen transformieren können. Da KI weiter voranschreitet, ist es entscheidend, über ihre Konzepte und Anwendungen informiert zu bleiben, um ihr volles Potenzial auszuschöpfen. Der Übergang zur praktischen Arbeit ist auch eine großartige Möglichkeit, mit den neuesten Entwicklungen Schritt zu halten und praktische Erfahrung zu sammeln.
Für eine begrenzte Zeit können neue Benutzer $10 in kostenlosen Credits erhalten, um die LLM-API auf Novita AI zu erkunden und damit zu entwickeln. Verpasse nicht diese Gelegenheit, in die Welt der KI einzutauchen und deine Ideen zum Leben zu erwecken!
Über Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.



