

Qwen 3.5 Small Series (0.8B, 2B, 4B, 9B) brings vision-language AI to edge devices and production apps. Novita AI offers one-click deployment templates—just select your model size, configure resources, and start inferencing in under 10 minutes. This guide walks through the 8-step process, API testing, and use-case recommendations.
Introduction to Qwen 3.5 Small Series
Qwen 3.5 Small Series represents Alibaba Cloud’s push toward efficient, multimodal AI for real-world deployment. Released in early 2026, this family of lightweight vision-language models spans 0.8B to 9B parameters, delivering frontier-class reasoning and coding performance at a fraction of the compute cost of larger models.
Unlike monolithic LLMs that demand high-end GPUs, Qwen 3.5 Small targets edge devices, laptops, and single-GPU setups while maintaining native text, image, and video processing. The 0.8B variant runs locally on smartphones, while the 9B model handles production-grade agents and multi-step JSON extraction previously requiring larger models.
Key Features
Qwen 3.5 introduces several architectural and training innovations that set it apart from earlier small models:
- Unified Vision-Language Foundation: Early fusion training on multimodal tokens achieves performance parity with Qwen 3 dense models and surpasses the specialized Qwen 3-VL series across reasoning, coding, agent benchmarks, and visual understanding tasks.
- Efficient Hybrid Architecture: Gated Delta Networks combined with sparse Mixture-of-Experts (MoE) deliver high-throughput inference with minimal latency. This architecture choice reduces memory overhead while maintaining output quality competitive with much larger dense models.
- Scalable RL Generalization: Reinforcement learning scaled across million-agent environments with progressively complex task distributions ensures robust real-world adaptability. The models train on diverse scenarios—from simple chatbot tasks to multi-step tool use—enabling smooth transfer to production use cases.
- Global Linguistic Coverage: Expanded support to 201 languages and dialects, enabling inclusive, worldwide deployment with nuanced cultural and regional understanding. This makes Qwen 3.5 Small particularly valuable for multilingual applications in emerging markets.
- Near-Perfect Training Efficiency: Near-100% multimodal training efficiency compared to text-only training, thanks to asynchronous RL frameworks and optimized data pipelines. This means training costs scale linearly with model size rather than exponentially—a critical factor for sustainable AI development.
Performance Highlights
The Qwen 3.5 Small Series demonstrates impressive efficiency gains across the lineup. For general reasoning, instruction following, and agentic workflows, these models punch far above their weight class. Users report that Qwen 3.5 4B handles multi-step JSON extraction that previously required 9B models, making it ideal for resource-constrained production environments.
Model Comparison
| Model | Parameters | Best For | Typical Use Cases |
| Qwen3.5-0.8B | 0.8B | Edge devices, mobile apps, IoT | On-device assistants, real-time translation, voice bots |
| Qwen3.5-2B | 2B | Lightweight chatbots, embedded systems | Customer support, FAQ answering, content moderation |
| Qwen3.5-4B | 4B | Balanced performance & cost | Small-scale production, data extraction, document Q&A |
| Qwen3.5-9B | 9B | Production apps, AI agents, complex reasoning | Multi-agent systems, advanced RAG, code generation |
Why Deploy on Novita AI?
Deploying AI models traditionally involves infrastructure setup, dependency management, and GPU configuration. Novita AI eliminates these pain points:
- One-Click Templates: Pre-packaged environments for all 4 Qwen 3.5 variants—just select and deploy.
- Pre-Configured Environments: Dependencies, CUDA versions, and model weights already optimized.
- Cost-Effective GPU Options: Pay-per-use GPU instances without upfront hardware investment.
- No Infrastructure Setup: Skip the DevOps work—Novita handles orchestration, scaling, and monitoring.
Whether you’re prototyping on a 0.8B model or running a 9B agent in production, Novita AI’s templates get you live in minutes.
Find More Templates in Template Library
Template Library
Step-by-Step Deployment Guide
The deployment process is identical for all four Qwen 3.5 models. Follow these 8 steps:
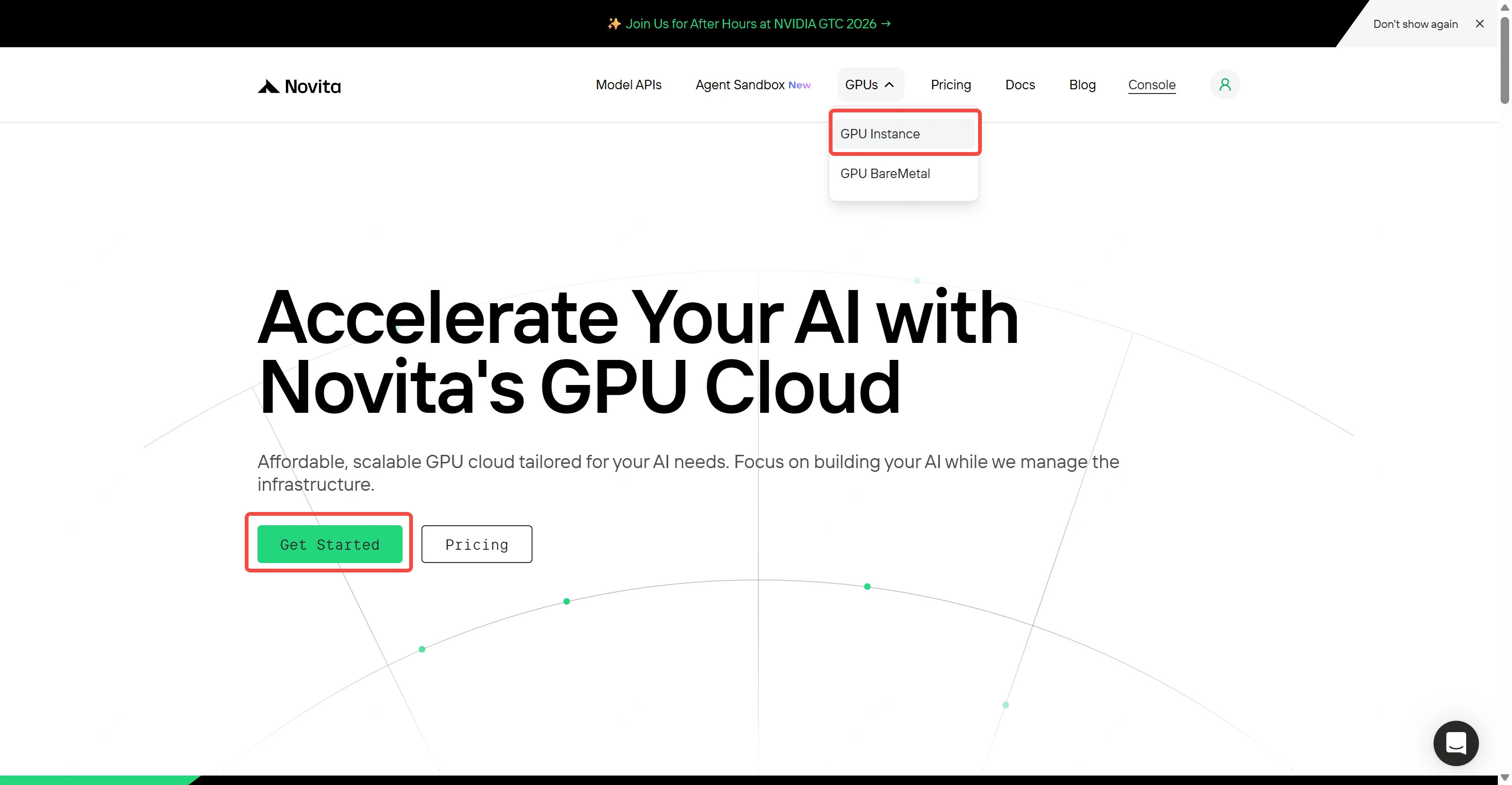
Step 1: Console Entry
Navigate to Novita AI’s GPU interface and click “Get Started” to access deployment management.
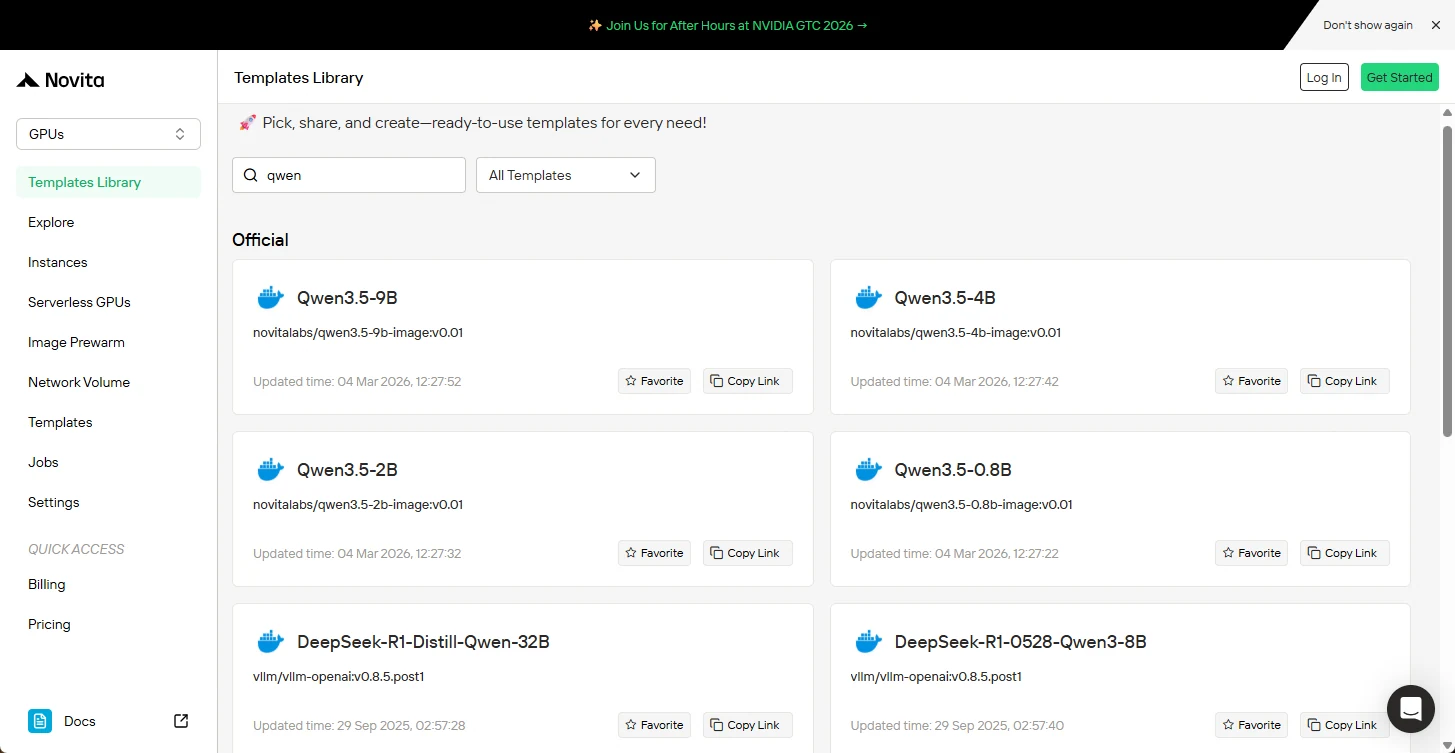
Step 2: Package Selection
In the template repository, locate Qwen3.5-{0.8B/2B/4B/9B} (choose your desired model size) and click to begin the installation sequence.
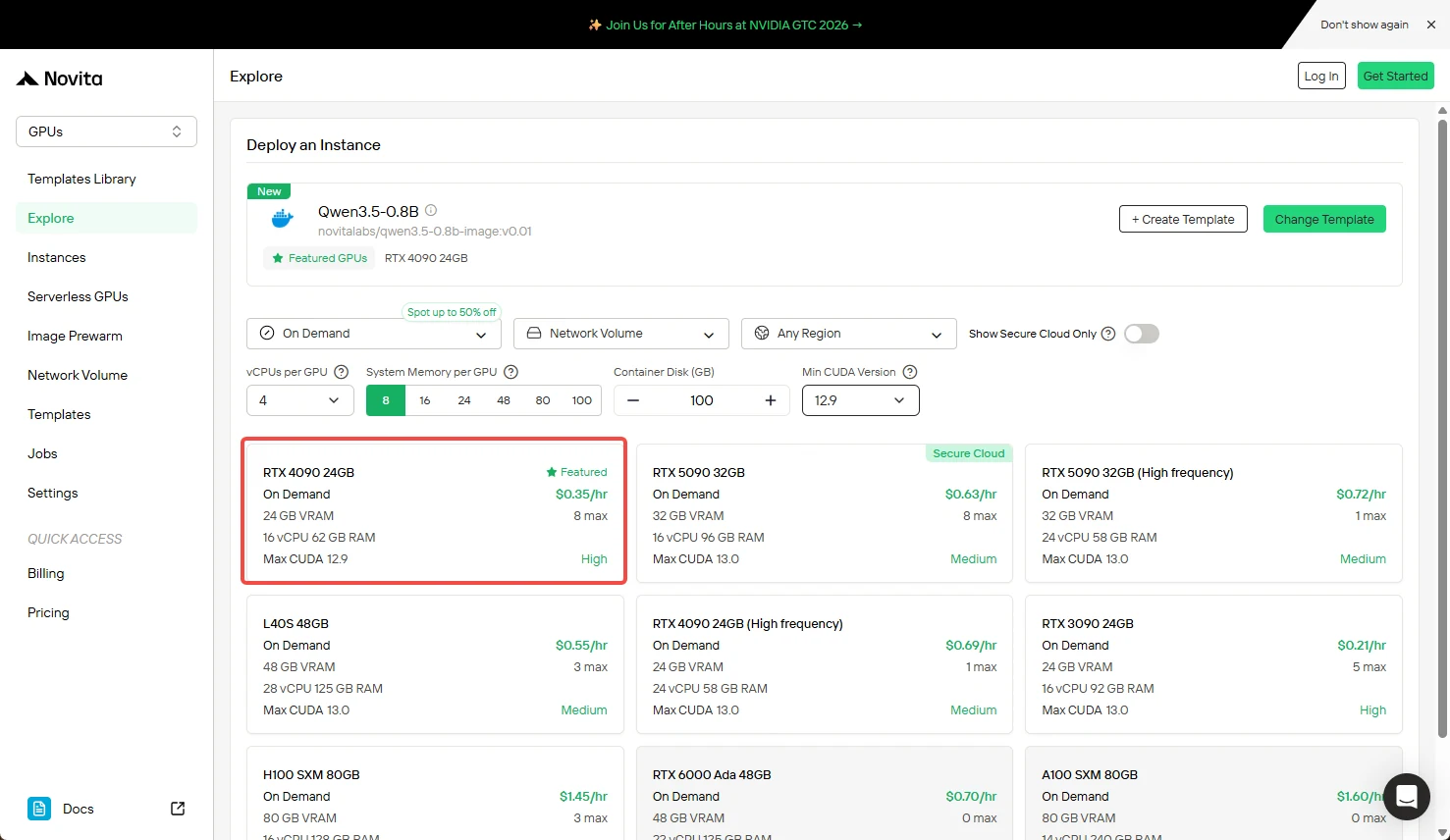
Step 3: Infrastructure Setup
Configure computing parameters:
- Memory allocation (RAM)
- Storage requirements (disk space for model weights)
- Network settings (firewall rules, ports)
Once configured, click “Deploy” to proceed.
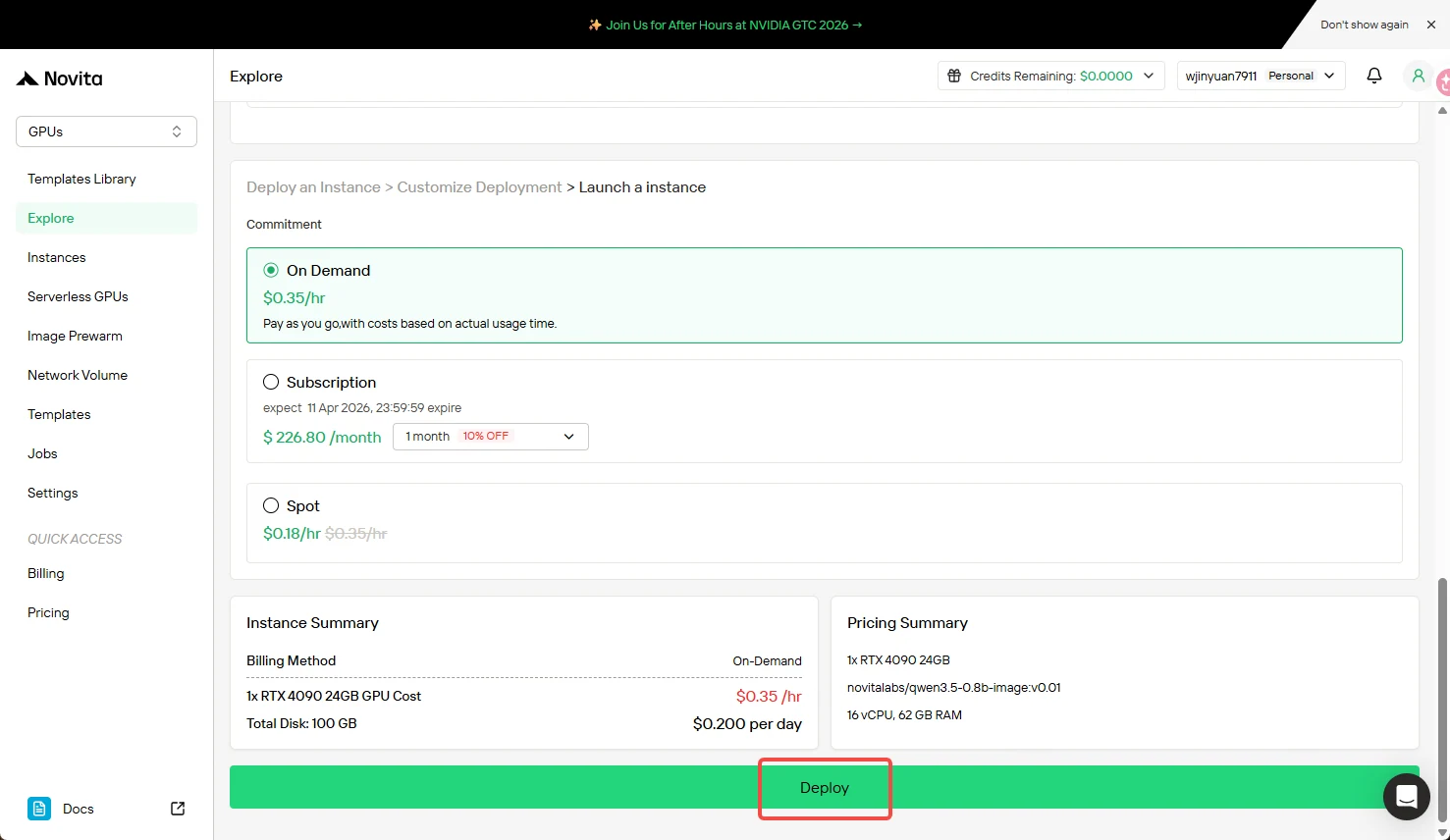
Step 4: Review and Create
Double-check your configuration details and cost summary. When satisfied, click “Deploy” to initiate the creation process.
Step 5: Wait for Creation
After initiating deployment, the system automatically redirects you to the instance management page. Your instance will be created in the background—no manual intervention needed.
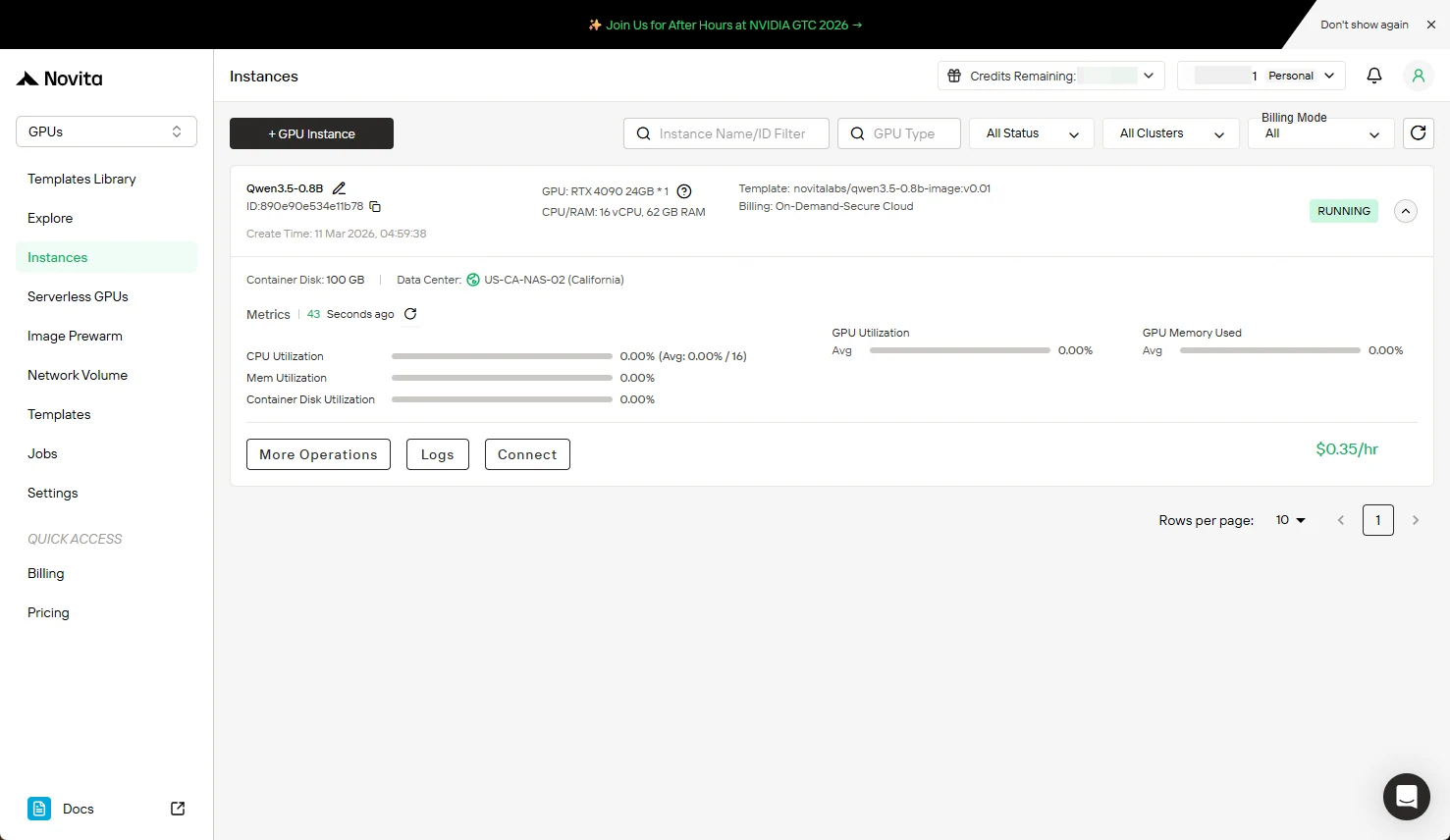
Step 6: Monitor Download Progress
Track the model image download in real-time. Your instance status will change from “Pulling” to “Running” once deployment completes. Click the arrow icon next to your instance name for detailed progress.
Step 7: Verify Instance Status
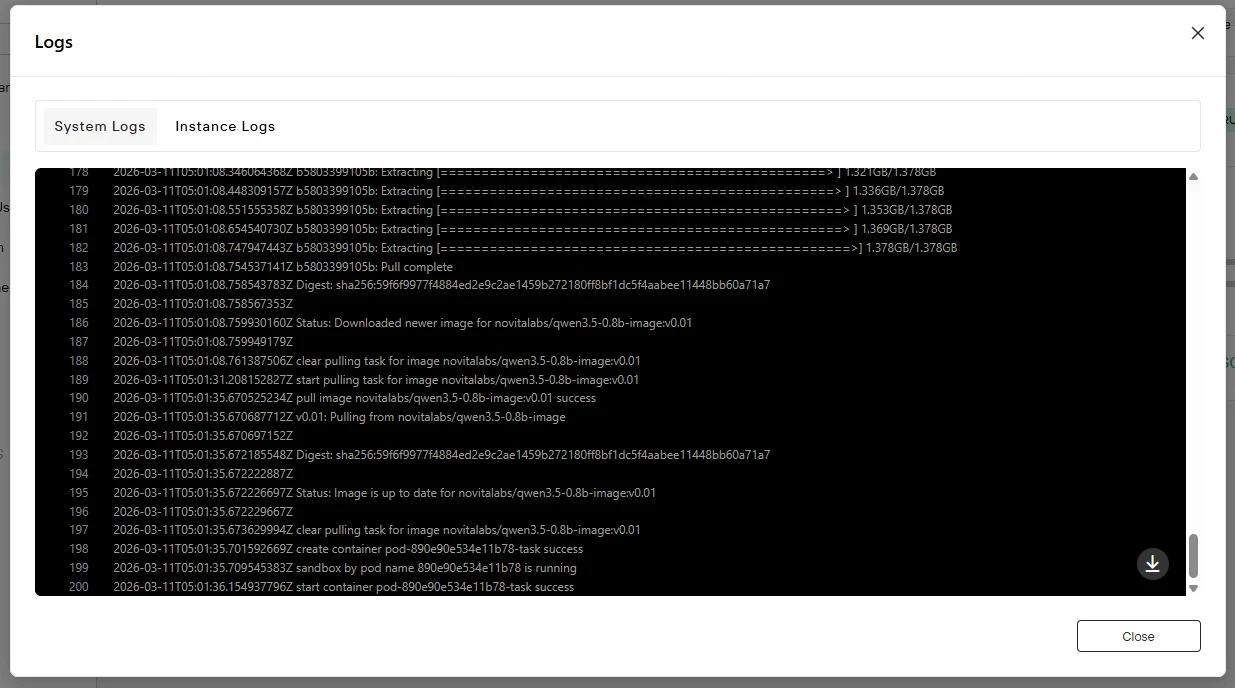
Click the “Logs” button to view instance logs and confirm that the inference service has started properly. Look for startup messages indicating successful model loading.
Step 8: Environmental Access
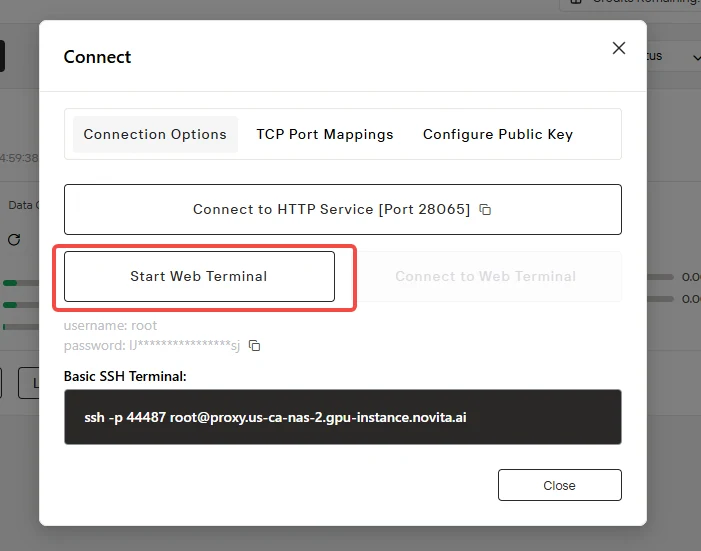
Launch the development space through the “Connect” interface, then initialize “Start Web Terminal” to access your deployment environment.
Testing Your Deployment
Once your instance is running, test it via the OpenAI-compatible API endpoint. Here’s a cURL example for each Qwen3.5-0.8B:
curl -sS http://127.0.0.1:28065/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5-0.8b",
"messages": [
{
"role": "system",
"content": "you are a helpful assitant."
},
{
"role": "user",
"content": "hello"
}
],
"max_tokens": 1300,
"stream": false
}'
{"id":"f4ff10a1836444f9b17593fcd6b40267","object":"chat.completion","created":1772593690,"model":"qwen3.5-0.8b","choices":[{"index":0,"message":{"role":"assistant","content":null,"reasoning_content":"Hello! How can I help you today?","tool_calls":null},"logprobs":null,"finish_reason":"stop","matched_stop":248046}],"usage":{"prompt_tokens":25,"total_tokens":35,"completion_tokens":10,"prompt_tokens_details":null,"reasoning_tokens":0},"metadata":{"weight_version":"default"}}Conclusion
Qwen 3.5 Small Series democratizes access to powerful vision-language AI, and Novita AI makes deployment effortless. With pre-built templates, GPU-optimized environments, and an OpenAI-compatible API, you can go from zero to production-ready inference in under 10 minutes—no infrastructure expertise required.
Whether you’re building lightweight edge applications with the 0.8B model or deploying sophisticated AI agents with the 9B variant, Novita AI’s platform scales with your needs. Ready to get started? Head to Novita AI’s Template Library and deploy your first Qwen 3.5 model today.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.



