

La série Qwen 3.5 Small (0.8B, 2B, 4B, 9B) apporte l’IA vision-langage aux dispositifs de périphérie et aux applications de production. Novita AI propose des templates de déploiement en un clic : il vous suffit de sélectionner la taille de votre modèle, de configurer les ressources et de commencer l’inférence en moins de 10 minutes. Ce guide vous accompagne à travers les 8 étapes, le test de l’API et les recommandations d’utilisation.
Introduction à la série Qwen 3.5 Small
La série Qwen 3.5 Small représente la volonté d’Alibaba Cloud de proposer une IA multimodale efficace et prête pour le déploiement réel. Sortie début 2026, cette famille de modèles légers vision-langage couvre de 0,8B à 9B de paramètres, offrant des performances de raisonnement et de codage de pointe pour une fraction du coût de calcul des modèles plus grands.
Contrairement aux LLM monolithiques qui exigent des GPU haut de gamme, Qwen 3.5 Small cible les dispositifs de périphérie, les ordinateurs portables et les configurations à GPU unique, tout en conservant le traitement natif du texte, des images et des vidéos. La variante 0.8B fonctionne localement sur les smartphones, tandis que le modèle 9B gère des agents de qualité production et une extraction JSON multi-étapes qui nécessitaient auparavant des modèles plus grands.
Principales caractéristiques
Qwen 3.5 introduit plusieurs innovations architecturales et d’entraînement qui le distinguent des petits modèles précédents :
- Fondation vision-langage unifiée : L’entraînement par fusion précoce sur des tokens multimodaux atteint la parité de performance avec les modèles denses Qwen 3 et dépasse la série spécialisée Qwen 3-VL dans les tâches de raisonnement, de codage, de benchmarks d’agents et de compréhension visuelle.
- Architecture hybride efficace : Les Gated Delta Networks combinés à un mélange sparse d’experts (MoE) offrent une inférence à haut débit avec une latence minimale. Ce choix architectural réduit l’empreinte mémoire tout en maintenant une qualité de sortie compétitive avec des modèles denses beaucoup plus grands.
- Généralisation RL évolutive : L’apprentissage par renforcement passé à l’échelle sur des environnements de millions d’agents avec des distributions de tâches de complexité croissante garantit une adaptabilité robuste dans le monde réel. Les modèles s’entraînent sur des scénarios variés – des simples tâches de chatbot à l’utilisation d’outils multi‑étapes – permettant un transfert fluide vers des cas d’usage en production.
- Couverture linguistique mondiale : Prise en charge élargie à 201 langues et dialectes, permettant un déploiement inclusif à l’échelle mondiale avec une compréhension culturelle et régionale nuancée. Cela rend Qwen 3.5 Small particulièrement précieux pour les applications multilingues sur les marchés émergents.
- Efficacité d’entraînement quasi parfaite : Efficacité d’entraînement multimodale proche de 100 % par rapport à l’entraînement uniquement textuel, grâce à des frameworks RL asynchrones et à des pipelines de données optimisés. Cela signifie que les coûts d’entraînement évoluent linéairement avec la taille du modèle plutôt qu’exponentiellement – un facteur critique pour un développement durable de l’IA.
Points forts des performances
La série Qwen 3.5 Small démontre des gains d’efficacité impressionnants sur l’ensemble de la gamme. Pour le raisonnement général, le suivi d’instructions et les workflows agents, ces modèles pèsent bien au-dessus de leur catégorie. Les utilisateurs rapportent que Qwen 3.5 4B gère une extraction JSON multi‑étapes qui nécessitait auparavant des modèles 9B, ce qui le rend idéal pour les environnements de production aux ressources limitées.
Comparaison des modèles
| Modèle | Paramètres | Idéal pour | Cas d’usage typiques |
| Qwen3.5-0.8B | 0.8B | Dispositifs de périphérie, apps mobiles, IoT | Assistants sur l’appareil, traduction en temps réel, bots vocaux |
| Qwen3.5-2B | 2B | Chatbots légers, systèmes embarqués | Support client, FAQ, modération de contenu |
| Qwen3.5-4B | 4B | Performance et coût équilibrés | Production à petite échelle, extraction de données, Q&A documentaire |
| Qwen3.5-9B | 9B | Applications de production, agents IA, raisonnement complexe | Systèmes multi‑agents, RAG avancé, génération de code |
Pourquoi déployer sur Novita AI ?
Déployer des modèles d’IA implique traditionnellement la configuration de l’infrastructure, la gestion des dépendances et le paramétrage du GPU. Novita AI élimine ces difficultés :
- Templates en un clic : Environnements pré‑emballés pour les 4 variantes de Qwen 3.5 – il suffit de sélectionner et de déployer.
- Environnements préconfigurés : Dépendances, versions CUDA et poids du modèle déjà optimisés.
- Options GPU économiques : Instances GPU à l’utilisation sans investissement matériel initial.
- Aucune configuration d’infrastructure : Évitez le travail DevOps – Novita gère l’orchestration, la mise à l’échelle et la surveillance.
Que vous prototypiez avec un modèle 0.8B ou que vous exécutiez un agent 9B en production, les templates de Novita AI vous permettent d’être opérationnel en quelques minutes.
Trouver plus de modèles dans la bibliothèque de templates
Bibliothèque de templates
Guide de déploiement pas à pas
Le processus de déploiement est identique pour les quatre modèles Qwen 3.5. Suivez ces 8 étapes :
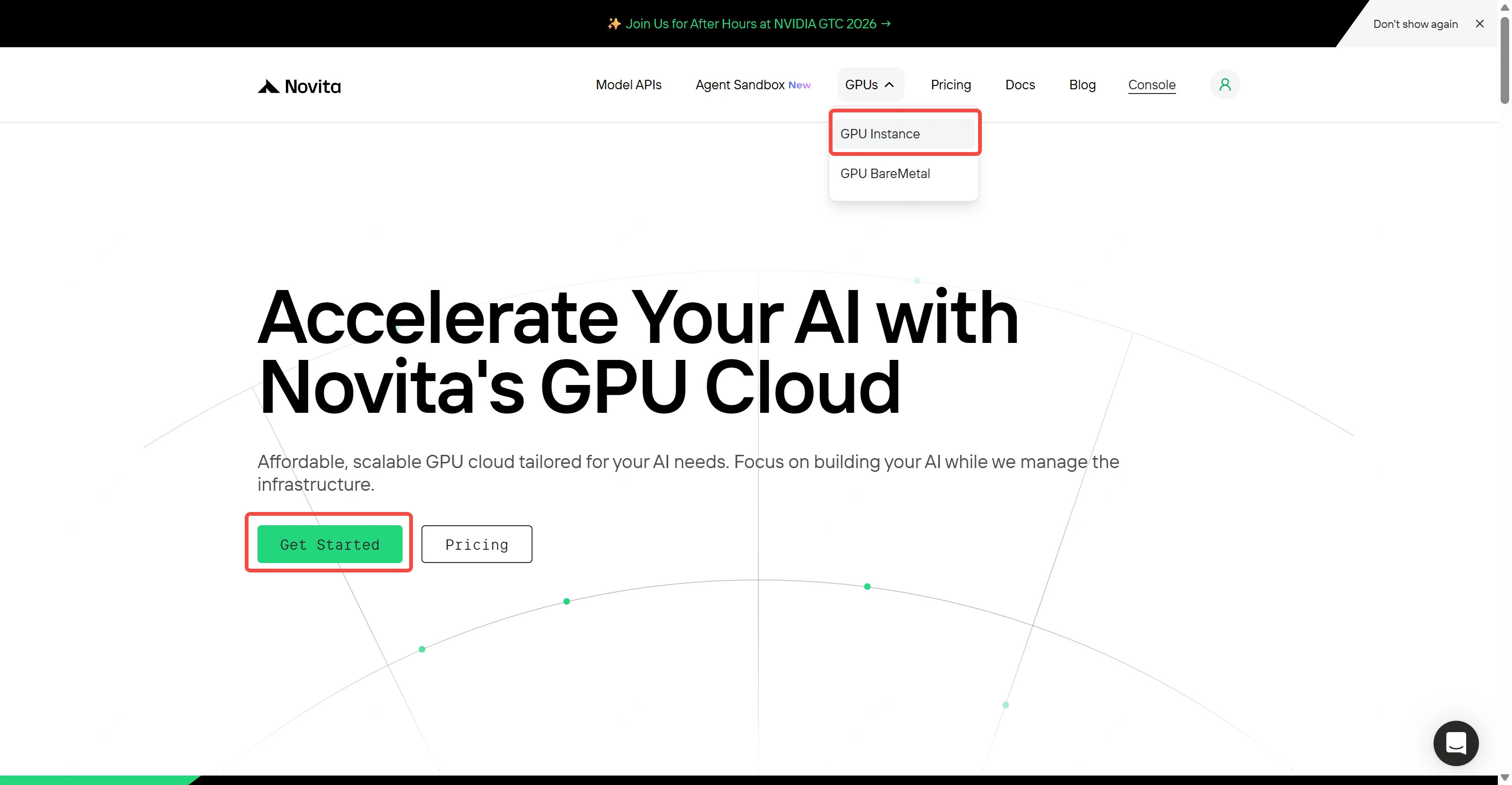
Étape 1 : Accès à la console
Naviguez vers l’interface GPU de Novita AI et cliquez sur “Get Started” pour accéder à la gestion des déploiements.
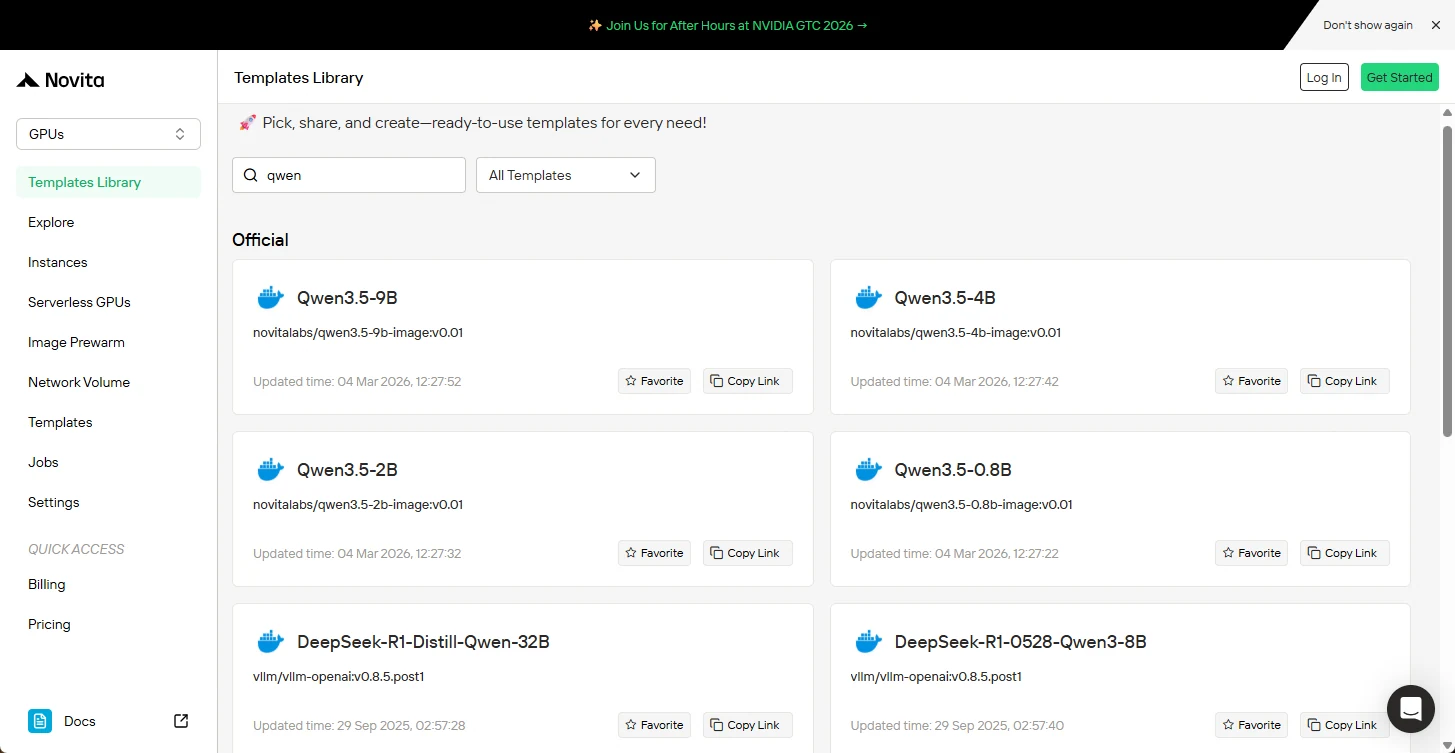
Étape 2 : Sélection du package
Dans le référentiel de templates, localisez Qwen3.5-{0.8B/2B/4B/9B} (choisissez la taille de votre modèle) et cliquez pour lancer la séquence d’installation.
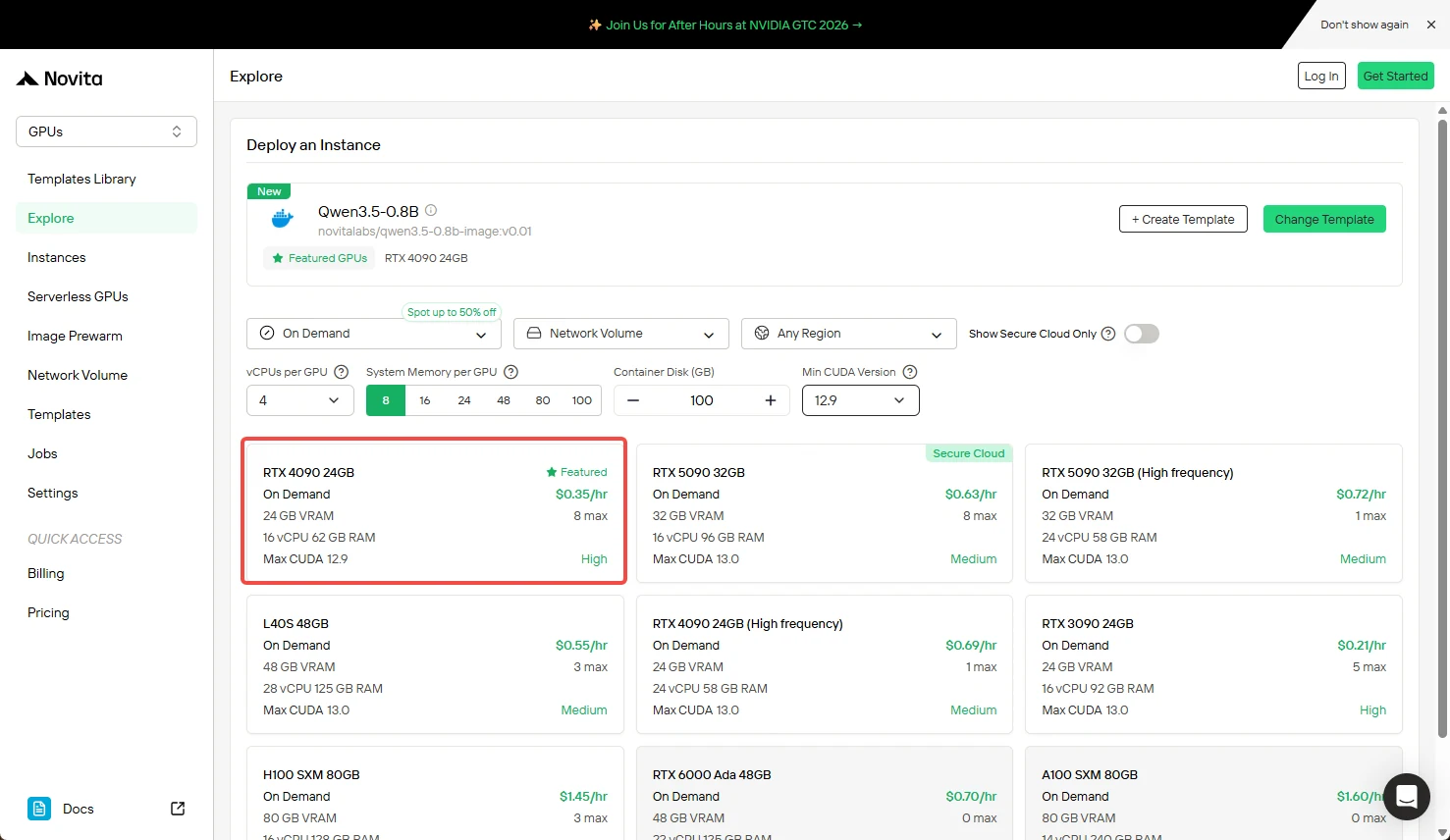
Étape 3 : Configuration de l’infrastructure
Configurez les paramètres de calcul :
- Allocation mémoire (RAM)
- Besoins de stockage (espace disque pour les poids du modèle)
- Paramètres réseau (règles de pare-feu, ports)
Une fois configuré, cliquez sur “Deploy” pour continuer.
Étape 4 : Vérification et création
Vérifiez les détails de votre configuration et le résumé des coûts. Lorsque vous êtes satisfait, cliquez sur “Deploy” pour lancer le processus de création.
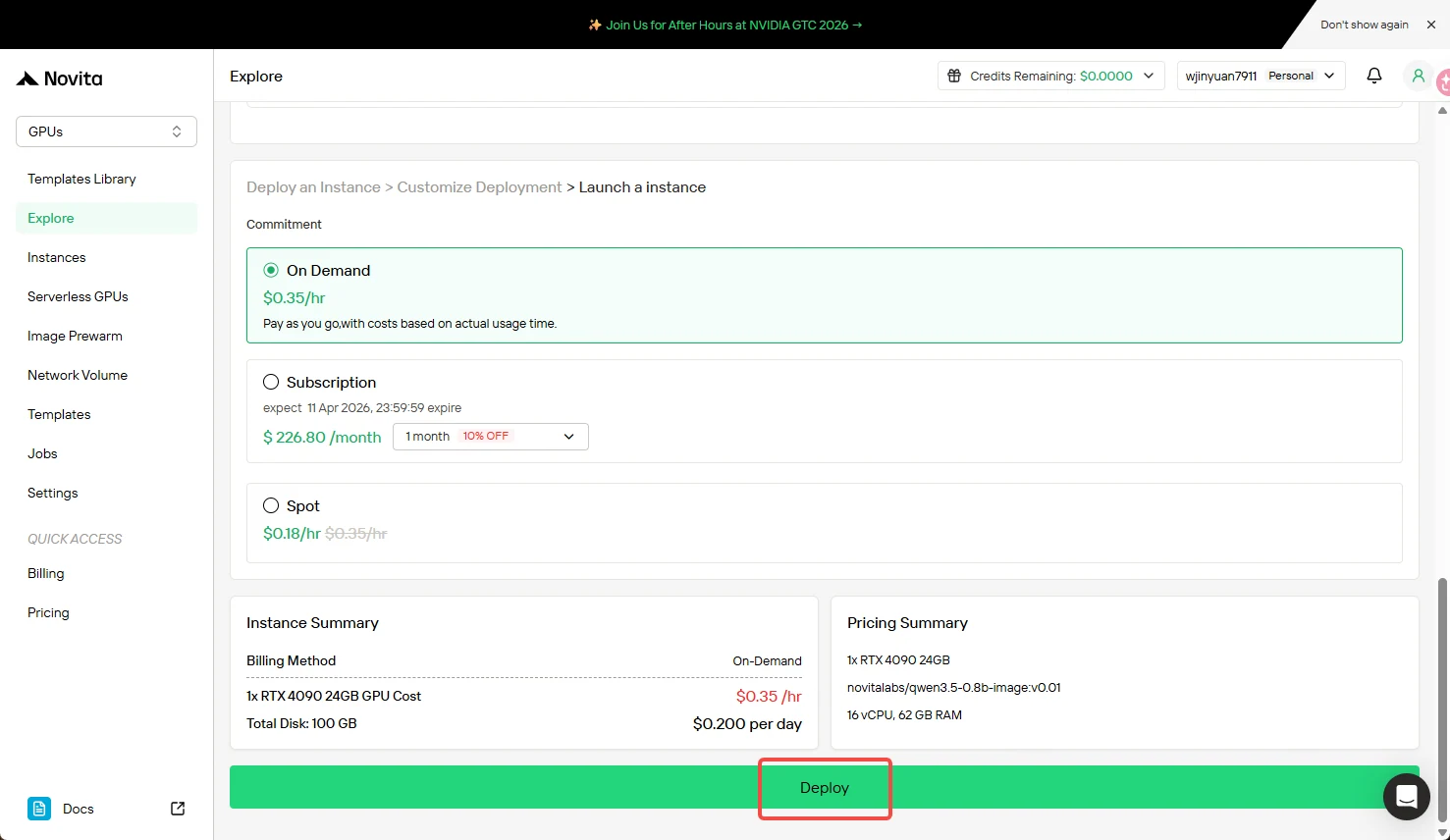
Étape 5 : Attente de la création
Après avoir initié le déploiement, le système vous redirige automatiquement vers la page de gestion des instances. Votre instance sera créée en arrière‑plan – aucune intervention manuelle n’est nécessaire.
Étape 6 : Suivi de la progression du téléchargement
Suivez en temps réel le téléchargement de l’image du modèle. Le statut de votre instance passe de “Pulling” à “Running” une fois le déploiement terminé. Cliquez sur l’icône en forme de flèche à côté du nom de votre instance pour obtenir le détail de la progression.
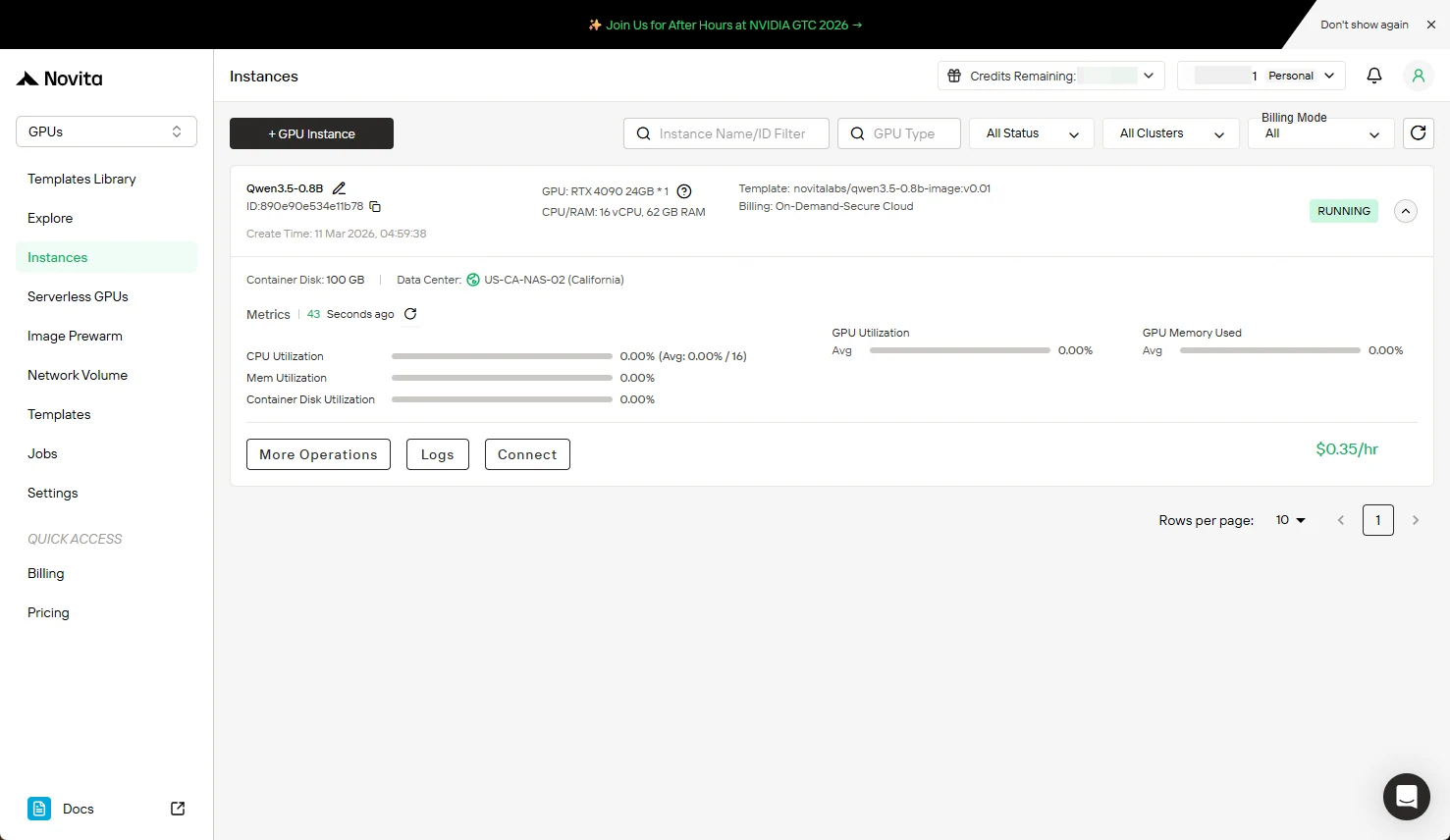
Étape 7 : Vérification du statut de l’instance
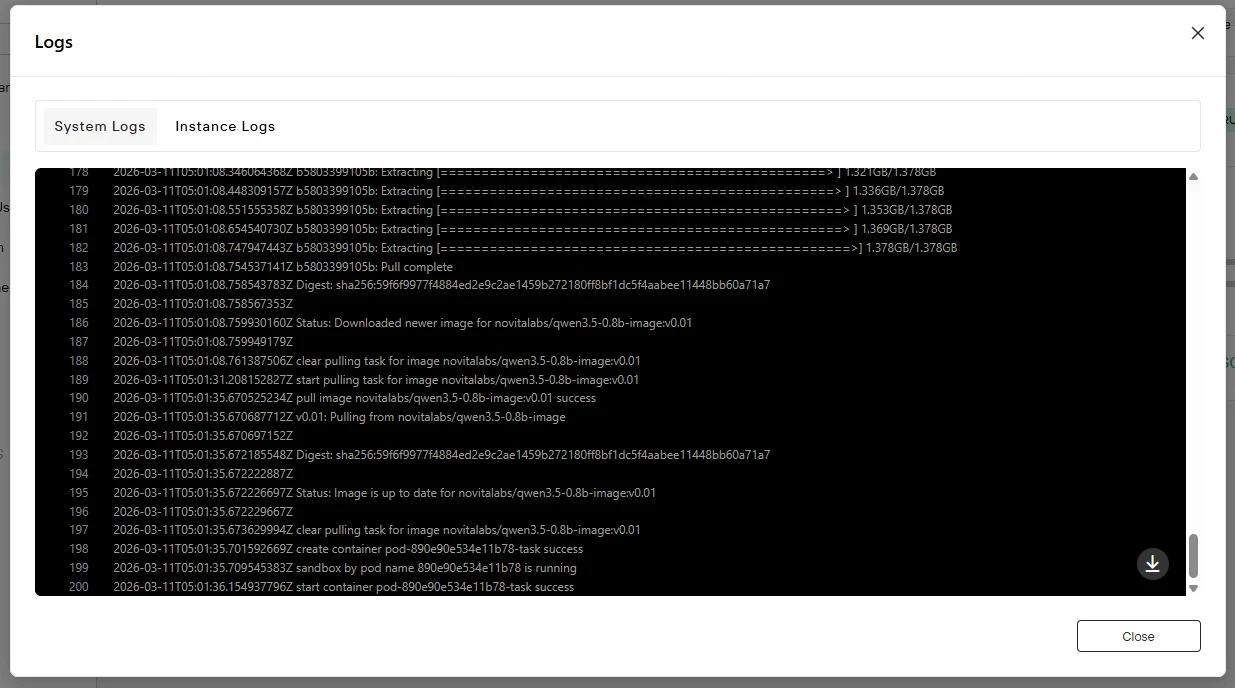
Cliquez sur le bouton “Logs” pour consulter les logs de l’instance et confirmer que le service d’inférence a bien démarré. Recherchez les messages de démarrage indiquant un chargement réussi du modèle.
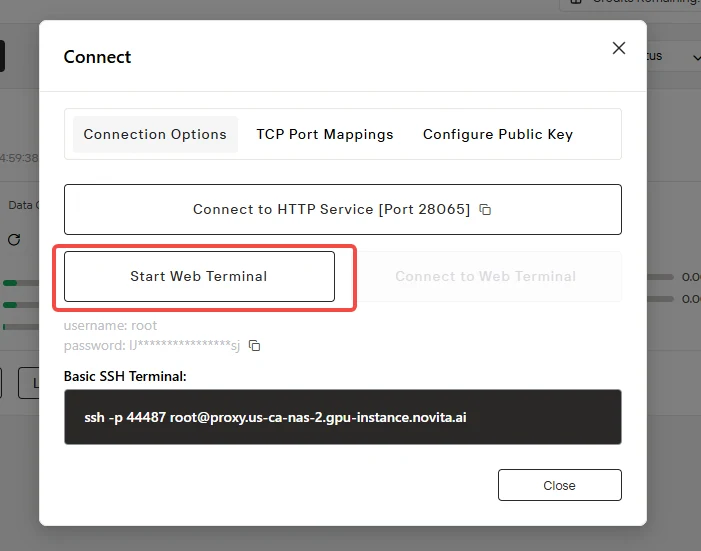
Étape 8 : Accès à l’environnement
Lancez l’espace de développement via l’interface “Connect”, puis initialisez “Start Web Terminal” pour accéder à votre environnement de déploiement.
Tester votre déploiement
Une fois votre instance en cours d’exécution, testez-la via le point de terminaison API compatible OpenAI. Voici un exemple cURL pour Qwen3.5-0.8B :
curl -sS http://127.0.0.1:28065/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3.5-0.8b",
"messages": [
{
"role": "system",
"content": "you are a helpful assitant."
},
{
"role": "user",
"content": "hello"
}
],
"max_tokens": 1300,
"stream": false
}'
{"id":"f4ff10a1836444f9b17593fcd6b40267","object":"chat.completion","created":1772593690,"model":"qwen3.5-0.8b","choices":[{"index":0,"message":{"role":"assistant","content":null,"reasoning_content":"Hello! How can I help you today?","tool_calls":null},"logprobs":null,"finish_reason":"stop","matched_stop":248046}],"usage":{"prompt_tokens":25,"total_tokens":35,"completion_tokens":10,"prompt_tokens_details":null,"reasoning_tokens":0},"metadata":{"weight_version":"default"}}
Conclusion
La série Qwen 3.5 Small démocratise l’accès à une IA vision-langage puissante, et Novita AI rend le déploiement sans effort. Avec des templates pré‑construits, des environnements optimisés pour GPU et une API compatible OpenAI, vous pouvez passer de zéro à une inférence prête pour la production en moins de 10 minutes – aucune expertise en infrastructure n’est requise.
Que vous construisiez des applications légères de périphérie avec le modèle 0.8B ou que vous déployiez des agents IA sophistiqués avec la variante 9B, la plateforme Novita AI s’adapte à vos besoins. Prêt à commencer ? Rendez-vous sur la bibliothèque de templates de Novita AI et déployez votre premier modèle Qwen 3.5 dès aujourd’hui.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.



