

Wichtige Eckpunkte
FP16-Inferenz für Qwen 2.5-7B benötigt ~17 GB VRAM, während FP32 über 32 GB erfordert – Volldezimalsetups sind daher nur auf GPUs wie der RTX 3090/4090 oder A100 praktikabel.
Quantisierung (8-Bit oder 4-Bit) ermöglicht den Betrieb des Modells auf kleineren GPUs (z. B. RTX 3060 12GB), jedoch mit Abstrichen bei der Genauigkeit.
API-Zugriff über Novita AI vermeidet Infrastrukturkosten und bietet sofortige Nutzung, Funktionsaufrufe und Multi-Agent-Workflows mit OpenAI-kompatiblen SDKs.
Empfehlen Sie Novita AI Freunden und Sie erhalten beide $10 in LLM-API-Guthaben – bis zu $500 an Gesamtbelohnungen. Um die Entwickler-Community zu unterstützen, ist Qwen2.5-7B derzeit kostenlos auf Novita AI verfügbar.

Das Ausführen von Qwen 2.5-7B erfordert eine sorgfältige GPU-Auswahl basierend auf VRAM, Rechenleistung und Bandbreite. Für Entwickler ohne leistungsstarke Hardware stellen Cloud-APIs wie Novita AI eine praktische, kosteneffektive Alternative dar.
VRAM-Anforderungen von Qwen 2.5 7B im Detail
| Präzision | Ungefährer VRAM-Bedarf für Inferenz |
| FP32 | 32,26 GB |
| FP16 | 17,18 GB |
| Präzision | Ungefährer VRAM-Bedarf für Feintuning |
| FP16 | 92,57 GB |
Hinweis: Zusätzlicher VRAM wird für den Aktivierungsspeicher des Modells (insbesondere bei langen Kontextlängen) und temporäre Puffer verwendet. In der Praxis wird ein Puffer von etwa 20 % zusätzlichem VRAM für eine sichere Inferenz empfohlen.
GPU-Auswahlkriterien für Qwen 2.5 7B
VRAM-Kapazität: Qwen-7B in voller FP16-Präzision benötigt ~17 GB VRAM. GPUs mit weniger als 17 GB (z. B. 8 GB oder 12 GB) erfordern eine Quantisierung (8-Bit oder 4-Bit), um das Modell aufnehmen zu können. Zum Beispiel kann eine RTX 3060 (12 GB) das Modell nur quantisiert verarbeiten. Eine 24-GB-GPU (z. B. RTX 3090/4090) ist ideal für volle Präzision mit Overhead und daher eine häufige Wahl.
Speicherbandbreite: Die Bandbreite beeinflusst die Token-Generierungsgeschwindigkeit. GPUs mit schnellem Speicher (z. B. GDDR6X oder HBM2) übertreffen andere deutlich. Beispielsweise bietet eine RTX 4080 etwa 720 GB/s Bandbreite, was die Inferenz im Vergleich zu älteren oder langsameren GPUs beschleunigt.
Rechenleistung: Transformer-Modelle profitieren von Tensor-Beschleunigung. NVIDIAs Ampere- und Ada-Architekturen (z. B. RTX 30/40-Serie, A100, H100) unterstützen FP16/INT8 über Tensor Cores und steigern den Durchsatz. Stellen Sie bei Quantisierung (INT4/INT8) sicher, dass Ihre GPU-Architektur und die Inferenzbibliothek effiziente Unterstützung bieten.
Präzisionsunterstützung: Prüfen Sie, ob Ihre GPU und Bibliotheken (z. B. Hugging Face Transformers, bitsandbytes) die gewünschte Präzision unterstützen. Ältere Karten wie die GTX 10-Serie haben keine native FP16-Beschleunigung. AMD-Anwender sollten die ROCm-Kompatibilität und FP16-Unterstützung (MI200, Radeon 7000-Serie) prüfen.
Multi-GPU-Skalierbarkeit: Obwohl Qwen-7B auf einer einzelnen GPU mit viel Speicher läuft, können kleinere Karten mit Modell-Sharding-Frameworks (z. B. device_map in Hugging Face Accelerate) kombiniert werden. NVLink oder schnelles PCIe verbessert die Leistung. Multi-GPU-Setups sind eher für größere Modelle wie Qwen2.5-72B relevant.
Empfohlene GPUs für Qwen 2.5 7B
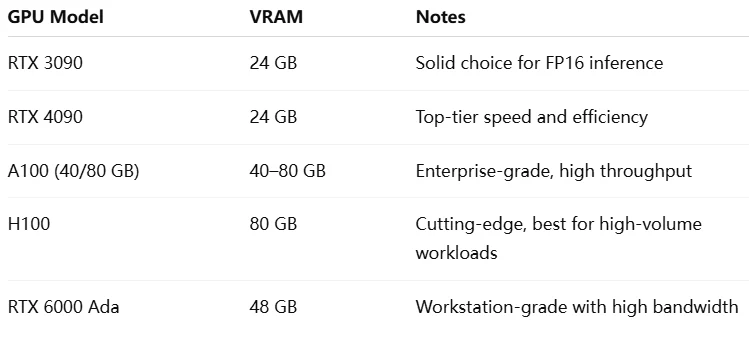
Hinweis: Stellen Sie sicher, dass die GPU FP16, INT8 oder INT4 über Bibliotheken wie bitsandbytes, transformers oder AutoGPTQ unterstützt. Für beste Leistung kombinieren Sie GPUs mit hoher Speicherbandbreite (GDDR6X oder HBM2+). Wenn Sie mehrere kleine GPUs verwenden, ziehen Sie Modell-Sharding mit Frameworks wie Hugging Faces device_map in Betracht.
Herausforderungen beim Einsatz auf eigenen GPU-Servern
Der Betrieb eines Modells wie Qwen 2.5-7B auf einem eigenen Server (oder einem kleinen Büroserver) bringt praktische Herausforderungen mit sich, die über das reine Ausführen des Modells hinausgehen. Hochwertige GPUs und ständig laufende Server erfordern sorgfältige Überlegungen zu Stromversorgung, Kühlung, Lärm und Netzwerk-Infrastruktur:
Stromversorgung
- Hochwertige GPUs verbrauchen 250–450 W; ein Netzteil mit 850 W–1000 W+ wird empfohlen.
- Ältere Häuser haben möglicherweise Stromkreisbeschränkungen – erwägen Sie einen eigenen Stromkreis.
- Kontinuierlicher 24/7-Betrieb erhöht die Stromkosten; eine USV wird bei Ausfällen empfohlen.
Kühlung & Wärme
- GPUs unter Last erzeugen erhebliche Wärme – sorgen Sie für gute Luftzirkulation oder externe Kühlung.
- Radiallüfter-GPUs sind für Multi-GPU-Setups besser geeignet, um die Wärme aus dem Gehäuse zu leiten.
- Vermeiden Sie den Betrieb in unbelüfteten Räumen wie Abstellräumen oder Garagen.
Lärm
- GPU- und Gehäuselüfter können 40–50 dB erreichen – laut in Wohnbereichen.
- Verwenden Sie schalldämmende Gehäuse, Wasserkühlung oder leise Lüfter (z. B. Noctua), um den Lärm zu reduzieren.
Physikalischer Platz
- Große GPUs wie die RTX 4090 benötigen ATX-Tower in voller Größe.
- Rechenzentrumskarten (z. B. SXM-Module) benötigen spezielle Gehäuse – nicht hausfreundlich.
Netzwerk
- Externer Zugriff erfordert stabile Upload-Bandbreite (10 Mbit/s+ empfohlen).
- Vermeiden Sie ISP-Einschränkungen: Richten Sie Portweiterleitung, DDNS ein oder zahlen Sie für eine statische IP.
- Verwenden Sie VPN oder SSH, um Endpunkte zu sichern; setzen Sie niemals ungesicherte APIs frei.
Zuverlässigkeit & Wartung
- Rechnen Sie mit Strom-, Netzwerk- oder Hardwareunterbrechungen – haben Sie Pläne für Neustarts/Wiederherstellung.
- Überwachen Sie die GPU-Gesundheit (z. B. mit
nvidia-smi), reinigen Sie Staub und prüfen Sie regelmäßig den Lüfterstatus.
Sicherheit
- Stellen Sie sicher, dass die elektrische Verkabelung nicht überlastet ist und Wärme sicher abgeführt wird.
- Beachten Sie Brandrisiken und mögliche Unannehmlichkeiten in gemeinsam genutzten Räumen durch Hitze/Lärm.
Kostengünstigere Wahl: API
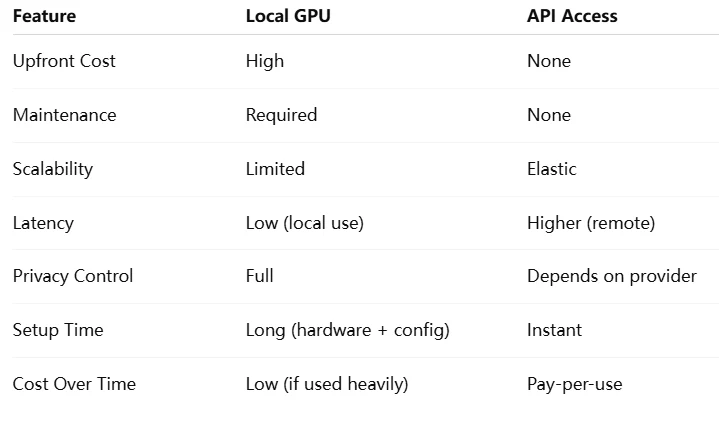
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für Aufbau und Skalierung bietet.
Sie können eine kostenlose Testversion starten, um die Fähigkeiten des ausgewählten Modells zu erkunden. Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
Testen Sie jetzt Qwen 2.5 7B Demo!
Direkte API-Integration
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<IHR Novita AI API-Schlüssel>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # oder False
max_tokens = 2048
system_content = """Seien Sie ein hilfreicher Assistent"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hallo!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Multi-Agent-Workflows mit dem OpenAI Agents SDK
Erstellen Sie fortschrittliche Multi-Agent-Systeme, indem Sie Novita AI mit dem OpenAI Agents SDK integrieren:
- Plug-and-Play: Verwenden Sie Novita AIs LLMs in jedem OpenAI Agents-Workflow.
- Unterstützt Übergaben, Routing und Werkzeugnutzung: Entwerfen Sie Agenten, die delegieren, priorisieren oder Funktionen ausführen können – alles unterstützt von Novita AIs Modellen.
- Python-Integration: Richten Sie das SDK einfach auf Novitas Endpunkt (
https://api.novita.ai/v3/openai) und verwenden Sie Ihren API-Schlüssel.
Auf Plattformen Dritter
- Hugging Face: Verwenden Sie Qwen 3 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte.
- Agenten- & Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM, LangChain, Dify und Langflow über offizielle Konnektoren und Schritt-für-Schritt-Integrationsleitfäden.
- OpenAI-kompatible API: Genießen Sie eine reibungslose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard ausgelegt sind.
Kurz gesagt: Egal, ob Sie Ihren lokalen GPU-Stack optimieren oder skalierbare KI über Cloud-APIs betreiben – das Verständnis der VRAM-Anforderungen von Qwen 2.5-7B ist der erste Schritt, um es effizient und kostengünstig auszuführen.
Häufig gestellte Fragen
Wie kann ich Qwen2.5-7B lokal ausführen?
Verwenden Sie eine GPU mit mindestens 24 GB VRAM (z. B. RTX 4090). Installieren Sie Hugging Face Transformers und laden Sie das Modell in FP16.
Wie schneidet der API-Zugriff im Vergleich zur lokalen Bereitstellung ab?
Die API-Nutzung vermeidet Hardware-Investitionen, unterstützt einfache Skalierung und ist ideal für schnelles Prototyping oder Produktionsumgebungen.
Wie greife ich über die API auf Qwen2.5-7B zu?
Novita AI bietet OpenAI-kompatible Endpunkte. Importieren Sie einfach das SDK, setzen Sie Ihren API-Schlüssel und beginnen Sie mit der Generierung mit wenigen Zeilen Python.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen fördert. Integrierte APIs, serverlos, GPU-Instanzen – die kosteneffizienten Tools, die Sie brauchen. Infrastruktur eliminieren, kostenlos starten und Ihre KI-Vision verwirklichen.



