

주요 요점
Qwen 2.5-7B의 FP16 추론 에는 약 17GB VRAM이 필요하며, FP32는 32GB 이상이 필요합니다. 따라서 RTX 3090/4090 또는 A100과 같은 GPU에서만 전체 정밀도 설정이 가능합니다.
양자화(8비트 또는 4비트) 를 사용하면 더 작은 GPU(예: RTX 3060 12GB) 에서도 모델을 실행할 수 있지만, 정밀도 측면에서 절충이 필요합니다.
Novita AI를 통한 API 접근 은 인프라 비용을 없애고, OpenAI 호환 SDK를 사용한 즉시 사용, 함수 호출, 멀티에이전트 워크플로를 제공합니다.
친구에게 Novita AI를 추천하면 두 분 모두 LLM API 크레딧으로 $10를 받게 됩니다. 최대 총 $500까지 적립 가능합니다. 개발자 커뮤니티를 지원하기 위해 Qwen2.5-7B는 현재 Novita AI에서 무료로 제공됩니다.

Qwen 2.5-7B를 실행하려면 VRAM, 컴퓨팅 성능, 대역폭을 고려한 신중한 GPU 선택이 필요합니다. 강력한 하드웨어가 없는 개발자에게는 Novita AI와 같은 클라우드 API가 실용적이고 비용 효율적인 대안입니다.
Qwen 2.5 7B VRAM 요구 사항 살펴보기
| **정밀도 ** | ** 추론에 필요한 대략적인 VRAM** |
| FP32 | 32.26GB |
| FP16 | 17.18GB |
| **정밀도 ** | ** 미세 조정에 필요한 대략적인 VRAM** |
| FP16 | 92.57GB |
참고: 추가 VRAM은 모델의 활성화 메모리(특히 긴 컨텍스트 길이에서) 와 일시적 버퍼에 사용됩니다. 실제로는 안전한 추론을 위해 약 20%의 여유 VRAM을 추가로 확보하는 것이 좋습니다.
Qwen 2.5 7B를 위한 GPU 선택 기준
VRAM 용량: Qwen-7B는 전체 FP16 정밀도에서 약 17GB의 VRAM이 필요합니다. 17GB 미만의 GPU(예: 8GB 또는 12GB) 는 모델을 수용하기 위해 양자화(8비트 또는 4비트) 가 필요합니다. 예를 들어 RTX 3060(12GB) 은 양자화된 경우에만 모델을 처리할 수 있습니다. 24GB GPU(예: RTX 3090/4090) 는 오버헤드를 포함한 전체 정밀도에 이상적이므로 일반적인 선택입니다.
메모리 대역폭: 대역폭은 토큰 생성 속도에 영향을 줍니다. 고속 메모리(GDDR6X 또는 HBM2 등) 를 갖춘 GPU는 다른 GPU보다 성능이 훨씬 뛰어납니다. 예를 들어 RTX 4080은 약 720GB/s의 대역폭을 제공하여 이전 세대나 느린 메모리 GPU보다 추론 속도를 높입니다.
컴퓨팅 성능: 트랜스포머 모델은 텐서 가속의 혜택을 받습니다. NVIDIA의 Ampere 및 Ada 아키텍처(예: RTX 30/40 시리즈, A100, H100) 는 Tensor Cores를 통해 FP16/INT8을 지원하여 처리량을 높입니다. 양자화(INT4/INT8) 의 경우 GPU 아키텍처와 추론 라이브러리가 효율적인 지원을 제공하는지 확인하세요.
정밀도 지원: GPU와 라이브러리(예: Hugging Face Transformers, bitsandbytes) 가 원하는 정밀도를 지원하는지 확인하세요. GTX 10 시리즈와 같은 구형 카드는 기본 FP16 가속을 지원하지 않습니다. AMD 사용자는 ROCm 호환성 및 FP16 지원(MI200, Radeon 7000 시리즈) 을 확인해야 합니다.
멀티 GPU 확장성: Qwen-7B는 단일 고메모리 GPU에서 실행되지만, 모델 샤딩 프레임워크(예: Hugging Face Accelerate의 device_map) 를 사용하여 더 작은 카드를 결합할 수 있습니다. NVLink 또는 고속 PCIe가 성능을 향상시킵니다. 멀티 GPU 설정은 Qwen2.5-72B와 같은 더 큰 모델에 더 적합합니다.
Qwen 2.5 7B에 권장되는 GPU
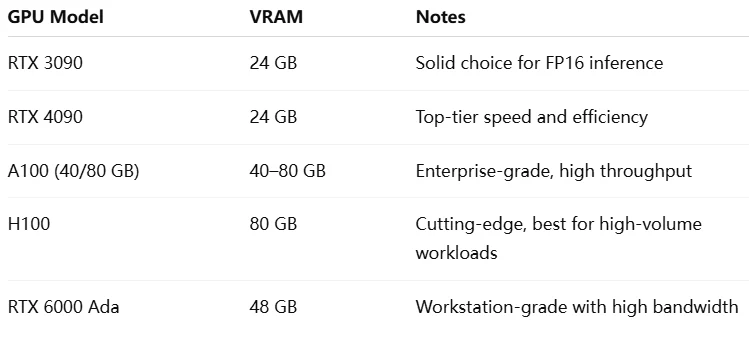
*참고: GPU가 bitsandbytes, transformers 또는 AutoGPTQ 와 같은 라이브러리를 통해 FP16, INT8 또는 INT4를 지원하는지 확인하세요. **최상의 성능 ** 을 위해 높은 *메모리 대역폭 (GDDR6X 또는 HBM2+) 을 갖춘 GPU를 페어링하세요. ** 여러 개의 소형 GPU를 사용하는 경우 Hugging Face의 device_map과 같은 프레임워크로 모델 샤딩을 고려하세요.
홈 GPU 서버에서의 배포 과제
홈 서버(또는 소규모 사무실 서버) 에서 Qwen 2.5-7B와 같은 모델을 실행하면 모델을 실행하는 것 이상의 실질적인 문제가 발생합니다. 고성능 GPU와 상시 가동 서버는 전력, 냉각, 소음, 네트워크 인프라에 대한 신중한 고려가 필요합니다.
전원 공급
- 고성능 GPU는 250~450W를 소비합니다. 850W~1000W+ PSU를 권장합니다.
- 오래된 주택은 회로 제한이 있을 수 있으므로 전용 회로를 고려하세요.
- 연중무휴 24시간 사용은 전기 요금을 증가시킵니다. 정전 시 UPS를 권장합니다.
냉각 및 발열
- 부하가 걸린 GPU는 상당한 열을 발생시킵니다. 좋은 공기 흐름 또는 외부 냉각을 보장하세요.
- 블로워 스타일 GPU는 멀티 GPU 설정에서 열을 케이스 외부로 배출하는 데 더 좋습니다.
- 서버를 다용도실이나 차고와 같은 환기가 되지 않는 공간에서 실행하지 마세요.
소음
- GPU 및 케이스 팬은 40~50dB에 도달할 수 있어 거실에서 시끄러울 수 있습니다.
- 방음 케이스, 수냉식 또는 조용한 팬(예: Noctua) 을 사용하여 소음을 줄이세요.
공간
- RTX 4090과 같은 대형 GPU는 풀사이즈 ATX 타워가 필요합니다.
- 데이터 센터 카드(예: SXM 모듈) 는 특수 섀시가 필요하므로 가정용으로 적합하지 않습니다.
네트워크
- 외부 접근에는 안정적인 업로드 대역폭(10Mbps 이상 권장) 이 필요합니다.
- ISP 제한을 피하려면 포트 포워딩, DDNS 설정 또는 고정 IP 비용을 지불하세요.
- 엔드포인트를 보호하려면 VPN 또는 SSH를 사용하고, 보안되지 않은 API를 노출하지 마세요.
신뢰성 및 유지보수
- 전원, 네트워크 또는 하드웨어 중단이 예상되므로 재시작/복구 계획을 세우세요.
nvidia-smi등으로 GPU 상태를 모니터링하고, 먼지를 청소하며, 팬 상태를 정기적으로 확인하세요.
안전
- 전기 배선이 과부하되지 않고 열이 안전하게 배출되는지 확인하세요.
- 화재 위험과 열/소음으로 인한 공유 공간 불편을 인지하세요.
더 비용 효율적인 선택: API
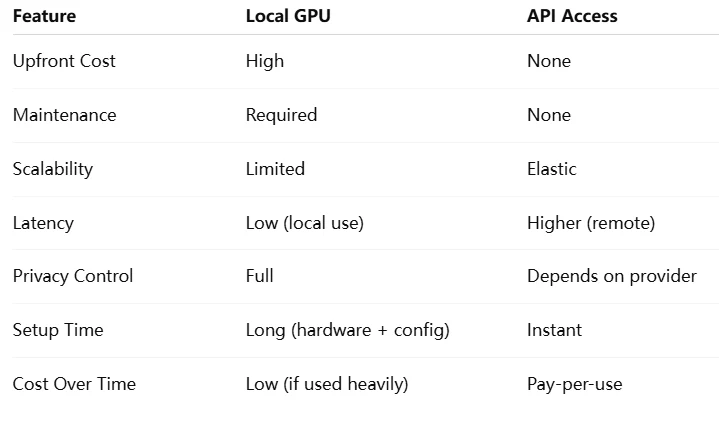
Novita AI는 개발자가 간단한 API를 통해 AI 모델을 쉽게 배포할 수 있도록 하면서, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공하는 AI 클라우드 플랫폼입니다.
무료 체험판을 시작하여 선택한 모델의 기능을 살펴보세요. 설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
직접 API 통합
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
OpenAI Agents SDK를 사용한 멀티에이전트 워크플로
Novita AI를 OpenAI Agents SDK와 통합하여 고급 멀티에이전트 시스템을 구축하세요:
- 플러그 앤 플레이: Novita AI의 LLM을 모든 OpenAI Agents 워크플로에서 사용하세요.
- 핸드오프, 라우팅, 도구 사용 지원: 위임, 분류 또는 함수 실행이 가능한 에이전트를 설계하세요. 모두 Novita AI의 모델로 구동됩니다.
- Python 통합: SDK를 Novita의 엔드포인트(
https://api.novita.ai/v3/openai) 로 지정하고 API 키를 사용하기만 하면 됩니다.
타사 플랫폼에서
- Hugging Face: Novita AI 엔드포인트를 통해 Spaces, 파이프라인 또는 Transformers 라이브러리에서 Qwen 3를 사용하세요.
- 에이전트 및 오케스트레이션 프레임워크: 공식 커넥터와 단계별 통합 가이드를 통해 Novita AI를 Continue, AnythingLLM, LangChain, Dify, Langflow와 같은 파트너 플랫폼에 쉽게 연결하세요.
- OpenAI 호환 API: Cline 및 Cursor와 같은 OpenAI API 표준에 맞춰 설계된 도구와 함께 번거로움 없이 마이그레이션 및 통합을 즐기세요.
요약하자면, 로컬 GPU 스택을 최적화하든 클라우드 API를 통해 확장 가능한 AI를 구축하든, Qwen 2.5-7B의 VRAM 요구 사항을 이해하는 것이 효율적이고 경제적으로 실행하는 첫걸음입니다.
자주 묻는 질문
Qwen2.5-7B를 로컬에서 실행하려면 어떻게 해야 하나요?
최소 24GB VRAM(예: RTX 4090) 의 GPU를 사용하세요. Hugging Face Transformers를 설치하고 FP16으로 모델을 로드하세요.
API 접근과 로컬 배포를 비교하면 어떤가요?
API 사용은 하드웨어 투자를 피하고, 쉬운 확장을 지원하며, 빠른 프로토타이핑이나 프로덕션 환경에 이상적입니다.
API를 통해 Qwen2.5-7B에 어떻게 접근하나요?
Novita AI는 OpenAI 호환 엔드포인트를 제공합니다. SDK를 가져오고, API 키를 설정한 후 몇 줄의 Python 코드로 생성을 시작하세요.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구를 제공합니다. 인프라를 없애고, 무료로 시작하여 AI 비전을 현실로 만드세요.



