

النقاط الرئيسية
استدلال FP16 لـ Qwen 2.5-7B يتطلب حوالي 17 جيجابايت VRAM، بينما يحتاج FP32 إلى أكثر من 32 جيجابايت—مما يجعل الإعدادات كاملة الدقة ممكنة فقط على وحدات معالجة رسومات مثل RTX 3090/4090 أو A100.
الكمية (8-بت أو 4-بت) تسمح بتشغيل النماذج على وحدات معالجة رسومات أصغر (مثل RTX 3060 12GB)، ولكن مع مقايضات في الدقة.
الوصول عبر API عبر Novita AI يتجنب تكاليف البنية التحتية، ويوفر استخدامًا فوريًا، واستدعاء الوظائف، وسير عمل متعدد الوكلاء باستخدام SDKs متوافقة مع OpenAI.
قم بإحالة أصدقائك إلى Novita AI وستحصلان معًا على 10 دولارات من أرصدة LLM API—حتى 500 دولار إجمالي المكافآت. لدعم مجتمع المطورين، يتوفر Qwen2.5-7B حاليًا مجانًا على Novita AI.

يتطلب تشغيل Qwen 2.5-7B اختيارًا دقيقًا لوحدة معالجة الرسومات بناءً على VRAM، والحوسبة، وعرض النطاق الترددي. للمطورين الذين لا يمتلكون أجهزة قوية، توفر واجهات برمجة التطبيقات السحابية مثل Novita AI بديلاً عمليًا وفعالًا من حيث التكلفة.
استكشاف متطلبات VRAM لـ Qwen 2.5 7B
| الدقة | VRAM التقريبية المطلوبة للاستدلال |
| FP32 | 32.26 جيجابايت |
| FP16 | 17.18 جيجابايت |
| الدقة | VRAM التقريبية المطلوبة للضبط الدقيق |
| FP16 | 92.57 جيجابايت |
ملاحظة: يتم استخدام VRAM إضافية لذاكرة التنشيط للنموذج (خاصة عند أطوال السياق الطويلة) والمخازن المؤقتة العابرة. عمليًا، يوصى باستخدام مخزن مؤقت إضافي بنسبة ~20% للاستدلال الآمن.
معايير اختيار وحدة معالجة الرسومات لـ Qwen 2.5 7B
سعة VRAM: يتطلب Qwen-7B بدقة FP16 كاملة حوالي 17 جيجابايت من VRAM. تحتاج وحدات معالجة الرسومات بسعة أقل من 17 جيجابايت (مثل 8 جيجابايت أو 12 جيجابايت) إلى الكمية (8-بت أو 4-بت) لتناسب النموذج. على سبيل المثال، يمكن لـ RTX 3060 (12 جيجابايت) التعامل مع النموذج فقط عند الكمية. تعتبر وحدة معالجة الرسومات بسعة 24 جيجابايت (مثل RTX 3090/4090) مثالية للدقة الكاملة مع النفقات العامة، مما يجعلها خيارًا شائعًا.
عرض النطاق الترددي للذاكرة: يؤثر عرض النطاق الترددي على سرعة إنشاء الرمز المميز. تتفوق وحدات معالجة الرسومات ذات الذاكرة عالية السرعة (مثل GDDR6X أو HBM2) بشكل كبير على غيرها. على سبيل المثال، يوفر RTX 4080 عرض نطاق ترددي يبلغ ~720 جيجابايت/ثانية، مما يسرع الاستدلال مقارنة بوحدات معالجة الرسومات الأقدم أو الأبطأ.
أداء الحوسبة: تستفيد نماذج المحولات من تسريع الموتر. تدعم بنيات Ampere و Ada من NVIDIA (مثل سلسلة RTX 30/40، A100، H100) FP16/INT8 عبر Tensor Cores، مما يعزز الإنتاجية. بالنسبة للكمية (INT4/INT8)، تأكد من أن بنية وحدة معالجة الرسومات ومكتبة الاستدلال توفر دعمًا فعالاً.
دعم الدقة: تحقق من أن وحدة معالجة الرسومات والمكتبات (مثل Hugging Face Transformers، bitsandbytes) تدعم الدقة المطلوبة. تفتقر البطاقات القديمة مثل سلسلة GTX 10 إلى تسريع FP16 الأصلي. يجب على مستخدمي AMD التحقق من توافق ROCm ودعم FP16 (MI200، سلسلة Radeon 7000).
قابلية التوسع متعددة وحدات معالجة الرسومات: بينما يعمل Qwen-7B على وحدة معالجة رسومات واحدة عالية الذاكرة، يمكن دمج البطاقات الأصغر باستخدام أطر تجزئة النماذج (مثل device_map في Hugging Face Accelerate). يعمل NVLink أو PCIe السريع على تحسين الأداء. تكون الإعدادات متعددة وحدات معالجة الرسومات أكثر صلة للنماذج الأكبر مثل Qwen2.5-72B.
وحدات معالجة الرسومات الموصى بها لـ Qwen 2.5 7B
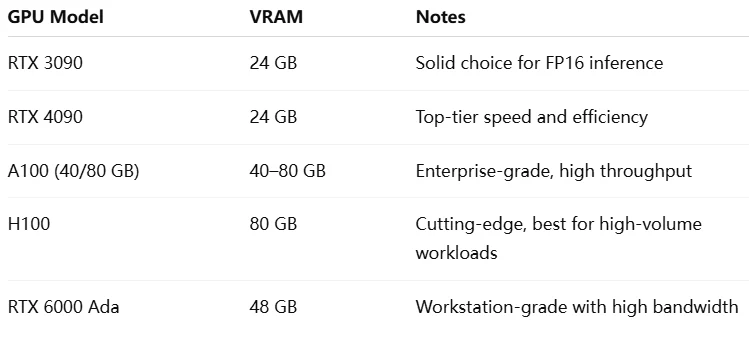
ملاحظة: تأكد من أن وحدة معالجة الرسومات تدعم FP16 أو INT8 أو INT4 عبر مكتبات مثل bitsandbytes، transformers، أو AutoGPTQ. للحصول على أفضل أداء، اقرن وحدات معالجة الرسومات بعرض نطاق ترددي عالي للذاكرة (GDDR6X أو HBM2+). إذا كنت تستخدم وحدات معالجة رسومات متعددة صغيرة، ففكر في تجزئة النموذج باستخدام أطر مثل device_map من Hugging Face.
تحديات النشر على خوادم GPU منزلية
يؤدي تشغيل نموذج مثل Qwen 2.5-7B على خادم منزلي (أو خادم مكتب صغير) إلى تقديم تحديات عملية تتجاوز مجرد تشغيل النموذج. تتطلب وحدات معالجة الرسومات عالية الأداء والخوادم التي تعمل دائمًا دراسة متأنية للبنية التحتية للطاقة والتبريد والضوضاء والشبكة:
إمداد الطاقة
- تستهلك وحدات معالجة الرسومات عالية الأداء 250-450 واط؛ يوصى باستخدام مزود طاقة بقدرة 850 واط-1000 واط+.
- قد يكون للمنازل القديمة حدود في الدوائر—فكر في استخدام دائرة مخصصة.
- يزيد الاستخدام المستمر 24/7 من تكاليف الكهرباء؛ يُنصح باستخدام UPS لانقطاعات التيار.
التبريد والحرارة
- تولد وحدات معالجة الرسومات تحت الحمل حرارة كبيرة—تأكد من تدفق هواء جيد أو تبريد خارجي.
- تعتبر وحدات معالجة الرسومات من نوع blower-style أفضل لإعدادات متعددة وحدات معالجة الرسومات لطرد الحرارة خارج العلبة.
- تجنب تشغيل الخوادم في مسافات غير مهواة مثل الخزانات أو المرائب.
الضوضاء
- يمكن أن تصل مروحة وحدة معالجة الرسومات والعلبة إلى 40-50 ديسيبل—وهو أمر مزعج في مناطق المعيشة.
- استخدم علب عازلة للصوت، أو تبريد مائي، أو مراوح هادئة (مثل Noctua) لتقليل الضوضاء.
المساحة الفعلية
- تتطلب وحدات معالجة الرسومات الكبيرة مثل RTX 4090 أبراج ATX كاملة الحجم.
- تحتاج بطاقات مراكز البيانات (مثل وحدات SXM) إلى هيكل متخصص—وهي غير مناسبة للمنزل.
الشبكة
- يتطلب الوصول الخارجي عرض نطاق ترددي ثابت للرفع (يوصى بـ 10 ميجابت/ثانية+).
- تجنب قيود مزود خدمة الإنترنت: قم بإعداد إعادة توجيه المنفذ، أو DDNS، أو الدفع مقابل عنوان IP ثابت.
- استخدم VPN أو SSH لتأمين نقاط النهاية؛ لا تعرض واجهات برمجة التطبيقات غير الآمنة أبدًا.
الموثوقية والصيانة
- توقع انقطاعات في الطاقة أو الشبكة أو الأجهزة—كن مستعدًا بخطط إعادة التشغيل/الاسترداد.
- راقب صحة وحدة معالجة الرسومات (على سبيل المثال باستخدام
nvidia-smi)، ونظف الغبار، وتحقق من حالة المروحة بانتظام.
السلامة
- تأكد من عدم تحميل الأسلاك الكهربائية بشكل زائد وأن الحرارة يتم تفريغها بأمان.
- كن على دراية بمخاطر الحرائق وعدم الراحة في المساحات المشتركة بسبب الحرارة/الضوضاء.
خيار أكثر فعالية من حيث التكلفة: API
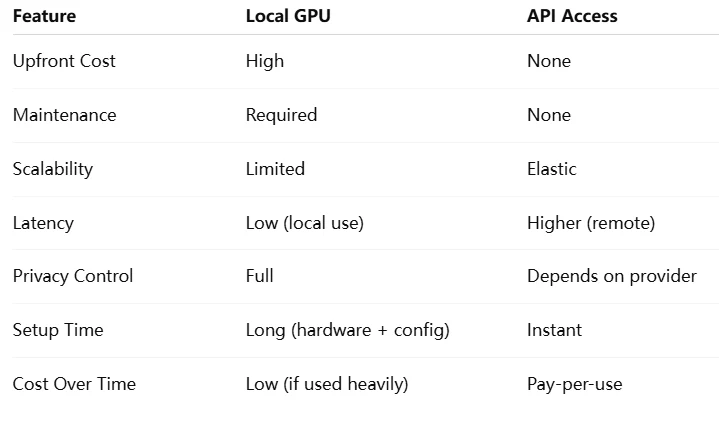
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API بسيط، مع توفير سحابة GPU موثوقة وبأسعار معقولة للبناء والتوسع.
يمكنك بدء النسخة التجريبية المجانية لاستكشاف قدرات النموذج المحدد. بعد التثبيت، قم باستيراد المكتبات اللازمة إلى بيئة التطوير الخاصة بك. قم بتهيئة API باستخدام مفتاح API الخاص بك لبدء التفاعل مع LLM من Novita AI. هذا مثال على استخدام chat completions API لمستخدمي Python.
التكامل المباشر مع API
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<YOUR Novita AI API Key>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Be a helpful assistant"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
سير عمل متعدد الوكلاء مع OpenAI Agents SDK
قم ببناء أنظمة متقدمة متعددة الوكلاء من خلال دمج Novita AI مع OpenAI Agents SDK:
- التوصيل والتشغيل: استخدم LLMs من Novita AI في أي سير عمل OpenAI Agents.
- يدعم التسليم والتوجيه واستخدام الأدوات: صمم وكلاء يمكنهم التفويض أو الفرز أو تشغيل الوظائف، وكلها مدعومة بنماذج Novita AI.
- التكامل مع Python: ما عليك سوى توجيه SDK إلى نقطة نهاية Novita (
https://api.novita.ai/v3/openai) واستخدام مفتاح API الخاص بك.
على منصات الطرف الثالث
- Hugging Face: استخدم Qwen 3 في Spaces، أو pipelines، أو مع مكتبة Transformers عبر نقاط نهاية Novita AI.
- أطر العملاء والتنسيق: قم بتوصيل Novita AI بسهولة مع منصات شريكة مثل Continue، AnythingLLM، LangChain، Dify و Langflow من خلال موصلات رسمية وأدلة تكامل خطوة بخطوة.
- API متوافق مع OpenAI: استمتع بالترحيل والتكامل الخالي من المتاعب مع أدوات مثل Cline و Cursor، المصممة لمعيار API OpenAI.
باختصار، سواء كنت تعمل على تحسين مجموعة GPU المحلية الخاصة بك أو تدير ذكاء اصطناعي قابل للتطوير عبر واجهات برمجة التطبيقات السحابية، فإن فهم احتياجات VRAM لـ Qwen 2.5-7B هو الخطوة الأولى لتشغيله بكفاءة وبتكلفة معقولة.
الأسئلة المتكررة
كيف يمكنني تشغيل Qwen2.5-7B محليًا؟
استخدم وحدة معالجة رسومات بسعة VRAM لا تقل عن 24 جيجابايت (مثل RTX 4090). قم بتثبيت Hugging Face Transformers وقم بتحميل النموذج بدقة FP16.
كيف يقارن الوصول عبر API بالنشر المحلي؟
يتجنب استخدام API الاستثمار في الأجهزة، ويدعم التوسع السهل، وهو مثالي للنماذج الأولية السريعة أو بيئات الإنتاج.
كيف يمكن الوصول إلى Qwen2.5-7B عبر API؟
تقدم Novita AI نقاط نهاية متوافقة مع OpenAI. ما عليك سوى استيراد SDK، وتعيين مفتاح API الخاص بك، وابدأ في التوليد ببضعة أسطر من Python.
Novita AI هي المنصة السحابية الشاملة التي تمكن طموحاتك في الذكاء الاصطناعي. APIs متكاملة، بدون خادم، مثيل GPU—الأدوات الفعالة من حيث التكلفة التي تحتاجها. تخلص من البنية التحتية، ابدأ مجانًا، واجعل رؤيتك للذكاء الاصطناعي حقيقة.



