

Destaques Principais
Inferência FP16 para Qwen 2.5-7B requer ~17 GB de VRAM, enquanto FP32 precisa de mais de 32 GB — tornando configurações de precisão total viáveis apenas em GPUs como RTX 3090/4090 ou A100.
Quantização (8 bits ou 4 bits) permite que o modelo seja executado em GPUs menores (ex.: RTX 3060 12 GB), mas com compensações na precisão.
Acesso via API através da Novita AI evita custos de infraestrutura, oferecendo uso instantâneo, chamadas de função e fluxos de trabalho multiagente usando SDKs compatíveis com OpenAI.
Indique amigos para a Novita AI e ambos ganharão US$ 10 em créditos de API LLM — até US$ 500 em recompensas totais. Para apoiar a comunidade de desenvolvedores, o Qwen2.5-7B está atualmente disponível gratuitamente na Novita AI.

Executar o Qwen 2.5-7B requer uma seleção cuidadosa de GPU com base em VRAM, desempenho computacional e largura de banda. Para desenvolvedores sem hardware potente, APIs em nuvem como a Novita AI oferecem uma alternativa prática e econômica.
Explorando os Requisitos de VRAM do Qwen 2.5 7B
| Precisão | VRAM aproximada necessária para inferência |
| FP32 | 32,26 GB |
| FP16 | 17,18 GB |
| Precisão | VRAM aproximada necessária para ajuste fino |
| FP16 | 92,57 GB |
Nota: VRAM adicional é usada para a memória de ativação do modelo (especialmente em comprimentos de contexto longos) e buffers transitórios. Na prática, recomenda-se um buffer de ~20% de VRAM extra para inferência segura.
Critérios de Seleção de GPU para Qwen 2.5 7B
Capacidade de VRAM: O Qwen-7B em precisão total FP16 requer ~17 GB de VRAM. GPUs com <17 GB (ex.: 8 GB ou 12 GB) precisam de quantização (8 ou 4 bits) para comportar o modelo. Por exemplo, uma RTX 3060 (12 GB) só consegue executar o modelo quando quantizado. Uma GPU de 24 GB (ex.: RTX 3090/4090) é ideal para precisão total com folga, sendo uma escolha comum.
Largura de banda da memória: A largura de banda afeta a velocidade de geração de tokens. GPUs com memória de alta velocidade (ex.: GDDR6X ou HBM2) superam significativamente outras. Por exemplo, uma RTX 4080 oferece ~720 GB/s de largura de banda, acelerando a inferência em comparação com GPUs mais antigas ou com memória mais lenta.
Desempenho computacional: Modelos Transformer se beneficiam da aceleração por tensores. As arquiteturas Ampere e Ada da NVIDIA (ex.: séries RTX 30/40, A100, H100) suportam FP16/INT8 via Tensor Cores, aumentando a taxa de transferência. Para quantização (INT4/INT8), certifique-se de que sua arquitetura de GPU e biblioteca de inferência ofereçam suporte eficiente.
Suporte a precisão: Verifique se sua GPU e bibliotecas (ex.: Hugging Face Transformers, bitsandbytes) suportam a precisão desejada. Placas mais antigas, como a série GTX 10, não possuem aceleração nativa para FP16. Usuários AMD devem verificar a compatibilidade com ROCm e suporte a FP16 (MI200, série Radeon 7000).
Escalabilidade multi-GPU: Embora o Qwen-7B seja executado em uma única GPU com muita memória, placas menores podem ser combinadas usando frameworks de divisão de modelo (ex.: device_map no Hugging Face Accelerate). NVLink ou PCIe rápido melhoram o desempenho. Configurações multi-GPU são mais relevantes para modelos maiores, como Qwen2.5-72B.
GPUs Recomendadas para Qwen 2.5 7B
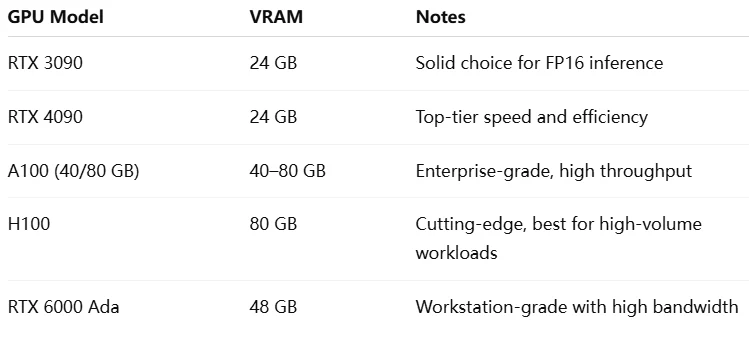
Nota: Certifique-se de que a GPU suporta FP16, INT8 ou INT4 por meio de bibliotecas como bitsandbytes, transformers ou AutoGPTQ. Para melhor desempenho, combine GPUs com alta largura de banda de memória (GDDR6X ou HBM2+). Se você usar várias GPUs pequenas, considere a divisão de modelo com frameworks como o device_map do Hugging Face.
Desafios de Implantação em Servidores GPU Domésticos
Executar um modelo como Qwen 2.5-7B em um servidor doméstico (ou em um pequeno servidor de escritório) apresenta desafios práticos que vão além de apenas fazer o modelo funcionar. GPUs de alto desempenho e servidores sempre ligados exigem consideração cuidadosa da infraestrutura de energia, resfriamento, ruído e rede:
Fonte de Alimentação
- GPUs de alto desempenho consomem 250–450 W; recomenda-se uma PSU de 850 W–1000 W ou mais.
- Casas mais antigas podem ter limites de circuito — considere um circuito dedicado.
- O uso contínuo 24/7 aumenta os custos de eletricidade; um UPS é recomendado para quedas de energia.
Resfriamento e Calor
- GPUs sob carga geram calor significativo — garanta boa ventilação ou resfriamento externo.
- GPUs com cooler do tipo blower são melhores para configurações multi-GPU, pois expelem o calor para fora do gabinete.
- Evite executar servidores em espaços não ventilados, como armários ou garagens.
Ruído
- As ventoinhas da GPU e do gabinete podem atingir 40–50 dB — barulhento em áreas residenciais.
- Use gabinetes com isolamento acústico, resfriamento a água ou ventoinhas silenciosas (ex.: Noctua) para reduzir o ruído.
Espaço Físico
- GPUs grandes, como a RTX 4090, exigem torres ATX de tamanho completo.
- Placas de datacenter (ex.: módulos SXM) precisam de gabinetes especializados — não são adequadas para uso doméstico.
Rede
- O acesso externo exige largura de banda de upload estável (recomenda-se 10 Mbps ou mais).
- Evite limitações da ISP: configure redirecionamento de porta, DDNS ou pague por um IP estático.
- Use VPN ou SSH para proteger endpoints; nunca exponha APIs não seguras.
Confiabilidade e Manutenção
- Espere interrupções de energia, rede ou hardware — tenha planos de reinicialização/recuperação.
- Monitore a saúde da GPU (ex.: com
nvidia-smi), limpe a poeira e verifique o status das ventoinhas regularmente.
Segurança
- Certifique-se de que a fiação elétrica não esteja sobrecarregada e que o calor seja ventilado com segurança.
- Esteja ciente do risco de incêndio e do desconforto em espaços compartilhados devido ao calor/ruído.
Escolha Mais Econômica: API
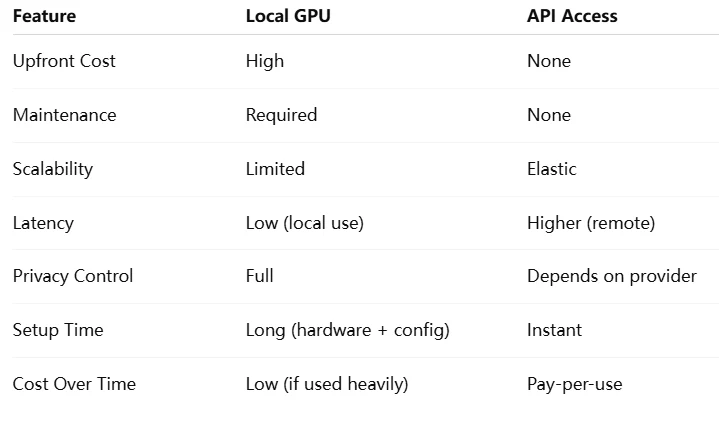
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer nuvem de GPU acessível e confiável para construir e escalar.
Você pode iniciar seu teste gratuito para explorar as capacidades do modelo selecionado. Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com a LLM da Novita AI. Este é um exemplo de uso da API de chat completions para usuários Python.
Experimente o Qwen 2.5 7B Demo Agora!
Integração Direta com a API
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="<SUA Chave de API Novita AI>",
)
model = "qwen/qwen2.5-7B-Instruct"
stream = True # or False
max_tokens = 2048
system_content = """Seja um assistente útil"""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Olá!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Fluxos de Trabalho Multiagente com o SDK de Agentes OpenAI
Construa sistemas multiagente avançados integrando a Novita AI ao OpenAI Agents SDK:
- Plug-and-play: Use as LLMs da Novita AI em qualquer fluxo de trabalho do OpenAI Agents.
- Suporte a transferências, roteamento e uso de ferramentas: Crie agentes que podem delegar, triar ou executar funções, tudo alimentado pelos modelos da Novita AI.
- Integração Python: Basta apontar o SDK para o endpoint da Novita (
https://api.novita.ai/v3/openai) e usar sua chave de API.
Em Plataformas de Terceiros
- Hugging Face: Use o Qwen 3 em Spaces, pipelines ou com a biblioteca Transformers através dos endpoints da Novita AI.
- Frameworks de Agentes e Orquestração: Conecte facilmente a Novita AI a plataformas parceiras como Continue, AnythingLLM, LangChain, Dify e Langflow através de conectores oficiais e guias de integração passo a passo.
- API Compatível com OpenAI: Desfrute de migração e integração sem complicações com ferramentas como Cline e Cursor, projetadas para o padrão da API OpenAI.
Em resumo, seja otimizando sua pilha local de GPU ou colocando em funcionamento IA escalável via APIs em nuvem, entender as necessidades de VRAM do Qwen 2.5-7B é o primeiro passo para executá-lo de forma eficiente e acessível.
Perguntas Frequentes
Como posso executar o Qwen2.5-7B localmente?
Use uma GPU com pelo menos 24 GB de VRAM (ex.: RTX 4090). Instale o Hugging Face Transformers e carregue o modelo em FP16.
Como o acesso via API se compara à implantação local?
O uso da API evita investimento em hardware, suporta escalonamento fácil e é ideal para prototipagem rápida ou ambientes de produção.
Como acessar o Qwen2.5-7B via API?
A Novita AI oferece endpoints compatíveis com OpenAI. Basta importar o SDK, configurar sua chave de API e começar a gerar com algumas linhas de Python.
A Novita AI é a plataforma completa em nuvem que impulsiona suas ambições de IA. APIs integradas, sem servidor, instância de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



