

PaddleOCR-VL ist jetzt auf der Novita AI-Plattform verfügbar und bietet state-of-the-art mehrsprachige Dokumentenanalysefunktionen durch ein ultra-kompaktes 0.9B Vision-Language-Modell. Diese innovative Lösung integriert einen dynamischen Bildencoder im NaViT-Stil mit variabler Auflösung mit dem Sprachmodell ERNIE-4.5-0.3B, um eine genaue Elementerkennung in 109 Sprachen zu ermöglichen.
PaddleOCR-VL-0.9B ist ein kompaktes, aber leistungsstarkes Vision-Language-Modell, das sich durch die Erkennung komplexer Elemente wie Text, Tabellen, Formeln und Diagramme auszeichnet, bei gleichzeitig minimalem Ressourcenverbrauch. Durch umfassende Auswertungen an weit verbreiteten öffentlichen Benchmarks und internen Benchmarks erreicht PaddleOCR-VL SOTA-Leistung sowohl bei der seitenweisen Dokumentenanalyse als auch bei der elementweisen Erkennung.
Es übertrifft bestehende Lösungen deutlich, zeigt eine starke Wettbewerbsfähigkeit gegenüber erstklassigen VLMs und bietet schnelle Inferenzgeschwindigkeiten, die für den praktischen Einsatz in realen Szenarien geeignet sind.
Probieren Sie PaddleOCR jetzt aus
Was ist PaddleOCR-VL?
PaddleOCR-VL ist ein state-of-the-art und ressourceneffizientes Modell, das speziell für die Dokumentenanalyse entwickelt wurde. Seine Kernkomponente ist PaddleOCR-VL-0.9B, ein kompaktes, aber leistungsstarkes Vision-Language-Modell, das einen dynamischen Bildencoder im NaViT-Stil mit variabler Auflösung mit dem Sprachmodell ERNIE-4.5-0.3B integriert, um eine genaue Elementerkennung zu ermöglichen.
Dieses innovative Modell unterstützt effizient 109 Sprachen und zeichnet sich durch die Erkennung komplexer Elemente wie Text, Tabellen, Formeln und Diagramme aus, bei gleichzeitig minimalem Ressourcenverbrauch. Durch umfassende Auswertungen an weit verbreiteten öffentlichen Benchmarks und internen Benchmarks erreicht PaddleOCR-VL SOTA-Leistung sowohl bei der seitenweisen Dokumentenanalyse als auch bei der elementweisen Erkennung.
Das Modell übertrifft bestehende Lösungen deutlich, zeigt eine starke Wettbewerbsfähigkeit gegenüber erstklassigen VLMs und bietet schnelle Inferenzgeschwindigkeiten. Diese Stärken machen es besonders gut für den praktischen Einsatz in realen Szenarien geeignet.
Kernfunktionen
Kompakte, aber leistungsstarke VLM-Architektur
PaddleOCR-VL ist ein neuartiges Vision-Language-Modell, das speziell für ressourceneffiziente Inferenz entwickelt wurde und eine herausragende Leistung bei der Elementerkennung erzielt. Durch die Integration eines dynamischen Hochauflösungs-Bildencoders im NaViT-Stil mit dem leichtgewichtigen Sprachmodell ERNIE-4.5-0.3B werden die Erkennungsfähigkeiten und die Dekodierungseffizienz des Modells deutlich verbessert. Diese Integration gewährleistet eine hohe Genauigkeit bei gleichzeitig reduziertem Rechenaufwand, sodass das Modell ideal für effiziente und praktische Dokumentenverarbeitungsanwendungen geeignet ist.
State-of-the-Art-Leistung bei der Dokumentenanalyse
PaddleOCR-VL erreicht state-of-the-art-Leistung sowohl bei der seitenweisen Dokumentenanalyse als auch bei der elementweisen Erkennung. Es übertrifft bestehende pipeline-basierte Lösungen deutlich und zeigt eine starke Wettbewerbsfähigkeit gegenüber führenden Vision-Language-Modellen im Bereich der Dokumentenanalyse. Darüber hinaus zeichnet sich PaddleOCR-VL durch die Erkennung komplexer Dokumentelemente wie Text, Tabellen, Formeln und Diagramme aus, sodass es für eine Vielzahl anspruchsvoller Inhaltstypen geeignet ist, einschließlich handschriftlicher Texte und historischer Dokumente. Dies macht es äußerst vielseitig und für eine breite Palette an Dokumenttypen und Szenarien geeignet.
Mehrsprachige Unterstützung
PaddleOCR-VL unterstützt 109 Sprachen, darunter alle wichtigen globalen Sprachen wie Chinesisch, Englisch, Japanisch, Latein und Koreanisch. Es unterstützt zudem Sprachen mit unterschiedlichen Schriften und Strukturen, wie Russisch (kyrillische Schrift), Arabisch, Hindi (Devanagari-Schrift) und Thailändisch.
Diese breite Sprachabdeckung verbessert die Einsetzbarkeit des Systems für mehrsprachige und globalisierte Dokumentenverarbeitungsszenarien erheblich.
Modellarchitektur
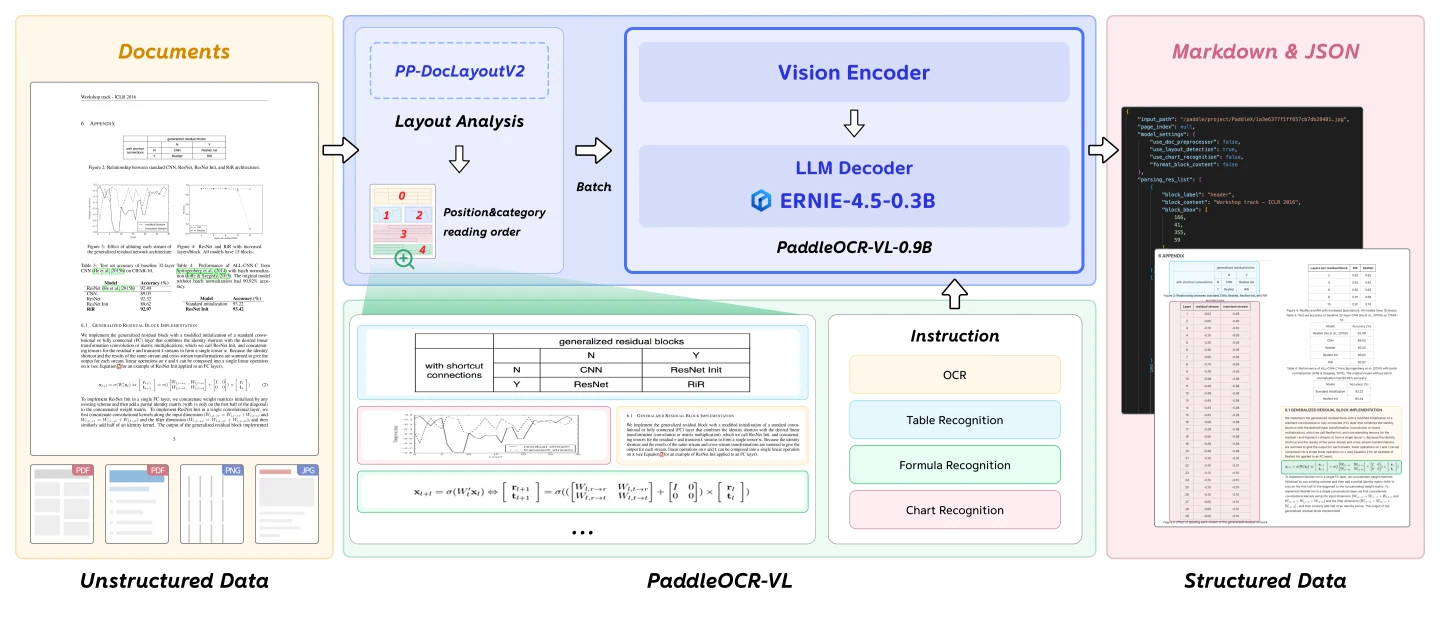
Der dynamische Hochauflösungs-Bildencoder im NaViT-Stil ermöglicht es dem Modell, Dokumente mit unterschiedlichen Auflösungen effizient zu verarbeiten und eine hochwertige Merkmalsextraktion über verschiedene Dokumenttypen und Layouts hinweg aufrechtzuerhalten. Das leichtgewichtige Sprachmodell ERNIE-4.5-0.3B bietet robuste Sprachverständnis- und Generierungsfähigkeiten, um die visuellen Merkmale zu verarbeiten und strukturierte Ausgaben zu erzeugen.
Dieses architektonische Design erreicht ein optimales Gleichgewicht zwischen Modellgröße, Inferenzgeschwindigkeit und Erkennungsgenauigkeit, sodass PaddleOCR-VL-0.9B ideal für den praktischen Einsatz ist, bei dem sowohl Leistung als auch Effizienz kritische Anforderungen sind.
Leistungsbenchmarks
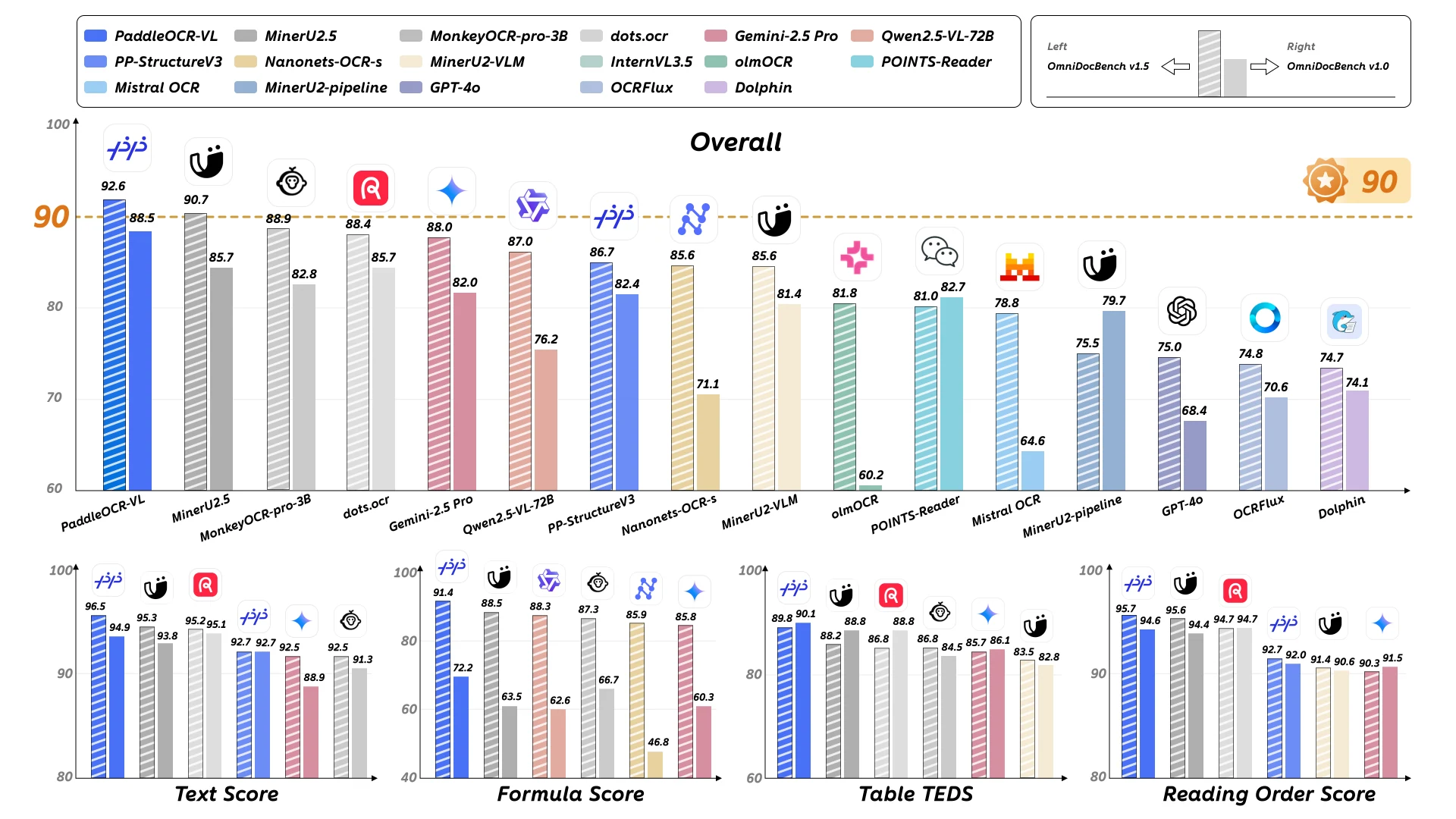
PaddleOCR-VL zeigt eine außergewöhnliche Leistung über mehrere Bewertungsdimensionen hinweg und etabliert sich als state-of-the-art-Lösung für Dokumentenanalyse und Elementerkennung.
Seitenweise Dokumentenanalyse
OmniDocBench v1.5: PaddleOCR-VL erreicht SOTA-Leistung bei den Gesamtergebnissen, Text, Formeln, Tabellen und Lesereihenfolge auf OmniDocBench v1.5.
Das Modell übertrifft konkurrierende Lösungen konsistent in allen bewerteten Kategorien und demonstriert seine umfassenden Dokumentenverständnisfähigkeiten.
OmniDocBench v1.0: PaddleOCR-VL erreicht SOTA-Leistung bei fast allen Metriken für Gesamtergebnisse, Text, Formeln, Tabellen und Lesereihenfolge auf OmniDocBench v1.0.
Diese Ergebnisse bestätigen die robusten Fähigkeiten des Modells über verschiedene Dokumenttypen und Komplexitätsstufen hinweg.
Hinweis: Die Metriken stammen von MinerU, OmniDocBench und internen Auswertungen.
Elementweise Erkennung
Texterkennung: Die robuste und vielseitige Fähigkeit von PaddleOCR-VL, unterschiedliche Dokumenttypen zu verarbeiten, macht es zur führenden Methode in der OmniDocBench-OCR-Block-Leistungsauswertung.
Die interne OCR-Auswertung bietet eine Bewertung der Leistung über mehrere Sprachen und Texttypen hinweg. PaddleOCR-VL zeigt eine herausragende Genauigkeit mit den niedrigsten Editierdistanzen in allen bewerteten Schriften.
Tabellenerkennung: Der selbst erstellte Auswertungssatz enthält unterschiedliche Arten von Tabellenbildern, wie chinesische, englische und gemischt chinesisch-englische Tabellen, Tabellen mit vollen, teilweisen oder keinen Rahmen, Buch-/Handbuchformate, Listen, wissenschaftliche Arbeiten, Tabellen mit zusammengeführten Zellen sowie niedrig aufgelöste und mit Wasserzeichen versehene Tabellen.
PaddleOCR-VL erzielt in allen Kategorien eine bemerkenswerte Leistung.
Formelerkennung: Der Auswertungssatz enthält einfache Drucke, komplexe Drucke, Kamerascans und handschriftliche Formeln.
PaddleOCR-VL zeigt in jeder Kategorie die beste Leistung.
Diagrammerkennung: Der Auswertungssatz ist grob in 11 Diagrammkategorien unterteilt, darunter kombinierte Balken-Linien-Diagramme, Kreisdiagramme, 100 % gestapelte Balken, Flächendiagramme, Balkendiagramme, Blasendiagramme, Histogramme, Liniendiagramme, Streudiagramme, gestapelte Flächendiagramme und gestapelte Balken.
PaddleOCR-VL übertrifft nicht nur Experten-OCR-VLMs, sondern übersteigt auch einige multimodale Sprachmodelle der 72B-Klasse.
Anwendungsfälle und Einsatzgebiete
Dokumentendigitalisierung
Wandeln Sie Papierdokumente mit der leistungsstarken Texterkennung von PaddleOCR-VL in 109 Sprachen in durchsuchbare digitale Formate um. Verarbeiten Sie Rechnungen, Quittungen, Verträge und Geschäftsdokumente effizient, bei gleichzeitig hoher Genauigkeit auch bei niedrig aufgelösten Scans oder mit Wasserzeichen versehenen Inhalten.
Wissenschaftliche Forschung
Extrahieren Sie mathematische Formeln, Tabellen und Text aus Forschungsarbeiten und wissenschaftlichen Veröffentlichungen. Die herausragende Formelerkennung von PaddleOCR-VL verarbeitet sowohl einfache als auch komplexe mathematische Ausdrücke, sodass es ideal für Literaturrecherchen und Datenextraktion aus akademischen Inhalten ist.
Verarbeitung von Finanzdokumenten
Automatisieren Sie die Extraktion von Daten aus Finanzberichten, Bilanzen und Reports. Die fortschrittliche Tabellenerkennung des Modells parst komplexe Tabellen mit zusammengeführten Zellen, mehreren Sprachen und verschiedenen Formatierungsstilen, die in Finanzdokumenten üblich sind, genau.
Digitalisierung historischer Archive
Bewahren Sie historische Dokumente und Manuskripte mit der robusten Verarbeitung anspruchsvoller Inhalte durch PaddleOCR-VL, einschließlich handschriftlicher Texte, alter Schriftarten, verblasster Tinte und gealtertem Papier. Das Modell behält auch bei historischen Dokumenten in verschiedenen Schriften und Sprachen eine hohe Genauigkeit.
Diagramm- und Datenanalyse
Gewinnen Sie Erkenntnisse aus visuellen Datendarstellungen in 11 Diagrammtypen, darunter Balkendiagramme, Kreisdiagramme, Liniendiagramme und komplexe hybride Visualisierungen. Perfekt für Geschäftsintelligenz-Anwendungen und automatisierte Berichtssysteme.
Erste Schritte mit PaddleOCR auf der Novita AI-Plattform
Der Zugriff auf PaddleOCR-VL über Novita AI bietet mehrere Wege, die auf unterschiedliche technische Kenntnisstände und Anwendungsfälle zugeschnitten sind. Egal, ob Sie ein Geschäftsanwender sind, der AI-Funktionen erkundet, oder ein Entwickler, der Produktionsanwendungen erstellt: Novita AI stellt Ihnen die benötigten Tools zur Verfügung.
Nutzen Sie den Playground (Jetzt verfügbar – Keine Programmierkenntnisse erforderlich)
- Sofortiger Zugriff: Registrieren Sie sich und beginnen Sie innerhalb von Sekunden mit dem Experimentieren mit PaddleOCR-VL
- Interaktive Oberfläche: Testen Sie die Dokumentenanalyse und visualisieren Sie Ausgaben in Echtzeit
- Modellvergleich: Vergleichen Sie PaddleOCR-VL mit anderen führenden Modellen für Ihren spezifischen Anwendungsfall
Der Playground ermöglicht es Ihnen, verschiedene Dokumenttypen zu testen und sofortige Ergebnisse ohne technische Einrichtung zu sehen. Perfekt für Prototyping, das Testen von Ideen und das Verständnis der Modellfunktionen vor der vollständigen Implementierung.
Integration über API (Live und einsatzbereit – Für Entwickler)
Verbinden Sie PaddleOCR-VL mit Ihren Anwendungen über die einheitliche REST-API von Novita AI.
Option 1: Direkte API-Integration (Python-Beispiel)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="",
)
model = "paddlepaddle/paddleocr-vl"
stream = True # or False
max_tokens = 8192
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Option 2: Multi-Agent-Workflows mit OpenAI Agents SDK
Erstellen Sie anspruchsvolle Multi-Agent-Systeme, die die fortschrittlichen Dokumentenanalysefunktionen von PaddleOCR-VL nutzen:
- Plug-and-Play-Integration: Nutzen Sie PaddleOCR-VL in jedem OpenAI Agents-Workflow
- Erweiterte Agent-Funktionen: Unterstützung für Übergaben, Routing und Tool-Integration mit Dokumentenverständnis
- Skalierbare Architektur: Entwerfen Sie Agenten, die die mehrsprachige OCR- und Elementerkennungsfunktionen von PaddleOCR-VL nutzen
Option 3: Verbindung mit Drittanbieterplattformen
Entwicklungstools: Integrieren Sie sich nahtlos in beliebte IDEs und Entwicklungsumgebungen wie Cursor, Trae und Cline über OpenAI-kompatible APIs und Anthropic-kompatible APIs.
Orchestrierungsframeworks: Verbinden Sie sich mit LangChain, Dify, CrewAI, Langflow und anderen AI-Orchestrierungsplattformen über offizielle Connectors.
Hugging Face Integration: Novita AI ist offizieller Inferenzanbieter von Hugging Face und gewährleistet eine breite Ökosystemkompatibilität.
Fazit
PaddleOCR auf Novita AI bietet erstklassige mehrsprachige Dokumentenanalysefunktionen durch ein ultra-kompaktes 0.9B Vision-Language-Modell, das außergewöhnliche Genauigkeit mit bemerkenswerter Effizienz kombiniert. Mit Unterstützung für 109 Sprachen, SOTA-Leistung auf OmniDocBench-Benchmarks und herausragender Erkennung komplexer Dokumentelemente wie Text, Tabellen, Formeln und Diagramme ist PaddleOCR-VL die definitive Wahl für moderne Dokumentenverarbeitungsanwendungen.
Die kompakte Architektur des Modells, seine schnellen Inferenzgeschwindigkeiten und seine Ressourceneffizienz machen es besonders gut für den praktischen Einsatz in realen Szenarien geeignet. Egal, ob Sie mehrsprachige Dokumente verarbeiten, Daten aus komplexen Tabellen extrahieren, mathematische Formeln erkennen oder Diagramme analysieren: PaddleOCR-VL auf Novita AI bietet Ihnen die benötigte Leistung und Zuverlässigkeit.
Beginnen Sie noch heute mit der Erkundung der revolutionären Dokumentenanalysefunktionen von PaddleOCR-VL auf Novita AI und erleben Sie die Zukunft der intelligenten Dokumentenverarbeitung mit unserer entwicklerfreundlichen Plattform und nahtlosen Integrationsoptionen.
Novita AI ist eine AI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, AI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine kostengünstige und zuverlässige GPU-Cloud zum Erstellen und Skalieren von Anwendungen zur Verfügung stellt.



