

PaddleOCR-VL est désormais disponible sur la plateforme Novita AI, apportant des capacités d’analyse de documents multilingue de pointe (SOTA) grâce à un modèle vision-langage ultra-compact de 0,9B. Cette solution innovante intègre un encodeur visuel à résolution dynamique de type NaViT avec le modèle de langage ERNIE-4.5-0.3B pour permettre une reconnaissance précise des éléments dans 109 langues.
PaddleOCR-VL-0.9B est un modèle vision-langage compact mais puissant qui excelle dans la reconnaissance d’éléments complexes comme le texte, les tableaux, les formules et les graphiques, tout en maintenant une consommation de ressources minimale. Grâce à des évaluations complètes sur des benchmarks publics largement utilisés et des benchmarks internes, PaddleOCR-VL atteint des performances de pointe (SOTA) à la fois pour l’analyse de documents au niveau de la page et la reconnaissance au niveau des éléments.
Il surpasse de manière significative les solutions existantes, présente une forte compétitivité face aux meilleurs modèles VLMs et offre des vitesses d’inférence rapides adaptées à un déploiement pratique dans des scénarios réels.
Qu’est-ce que PaddleOCR-VL ?
PaddleOCR-VL est un modèle de pointe (SOTA) et économe en ressources, spécialement conçu pour l’analyse de documents. Son composant principal est PaddleOCR-VL-0.9B, un modèle vision-langage compact mais puissant qui intègre un encodeur visuel à résolution dynamique de type NaViT avec le modèle de langage ERNIE-4.5-0.3B pour permettre une reconnaissance précise des éléments.
Ce modèle innovant prend en charge 109 langues et excelle dans la reconnaissance d’éléments complexes incluant le texte, les tableaux, les formules et les graphiques, tout en maintenant une consommation de ressources minimale. Grâce à des évaluations complètes sur des benchmarks publics largement utilisés et des benchmarks internes, PaddleOCR-VL atteint des performances de pointe (SOTA) à la fois pour l’analyse de documents au niveau de la page et la reconnaissance au niveau des éléments.
Le modèle surpasse de manière significative les solutions existantes, présente une forte compétitivité face aux meilleurs modèles VLMs et offre des vitesses d’inférence rapides. Ces atouts le rendent particulièrement adapté à un déploiement pratique dans des scénarios réels.
Fonctionnalités principales
Architecture VLM compacte mais puissante
PaddleOCR-VL présente un nouveau modèle vision-langage spécialement conçu pour une inférence économe en ressources, atteignant des performances exceptionnelles dans la reconnaissance d’éléments. En intégrant un encodeur visuel à haute résolution et résolution dynamique de type NaViT avec le modèle de langage léger ERNIE-4.5-0.3B, le système améliore considérablement les capacités de reconnaissance du modèle et son efficacité de décodage. Cette intégration maintient une haute précision tout en réduisant les demandes computationnelles, ce qui le rend bien adapté aux applications de traitement de documents efficaces et pratiques.
Performances de pointe (SOTA) pour l’analyse de documents
PaddleOCR-VL atteint des performances de pointe (SOTA) à la fois pour l’analyse de documents au niveau de la page et la reconnaissance au niveau des éléments. Il surpasse de manière significative les solutions existantes basées sur des pipelines et présente une forte compétitivité face aux modèles vision-langage leaders dans le domaine de l’analyse de documents. De plus, PaddleOCR-VL excelle dans la reconnaissance d’éléments de documents complexes, tels que le texte, les tableaux, les formules et les graphiques, ce qui le rend adapté à une large gamme de types de contenu difficiles, incluant le texte manuscrit et les documents historiques. Cela le rend très polyvalent et adapté à une grande variété de types de documents et de scénarios.
Prise en charge multilingue
PaddleOCR-VL prend en charge 109 langues, couvrant les principales langues mondiales, incluant mais sans s’y limiter le chinois, l’anglais, le japonais, le latin et le coréen. Il prend également en charge des langues avec des écritures et structures différentes, comme le russe (écriture cyrillique), l’arabe, l’hindi (écriture devanagari) et le thaï.
Cette couverture linguistique étendue améliore considérablement l’applicabilité du système à des scénarios de traitement de documents multilingues et mondialisés.
Architecture du modèle
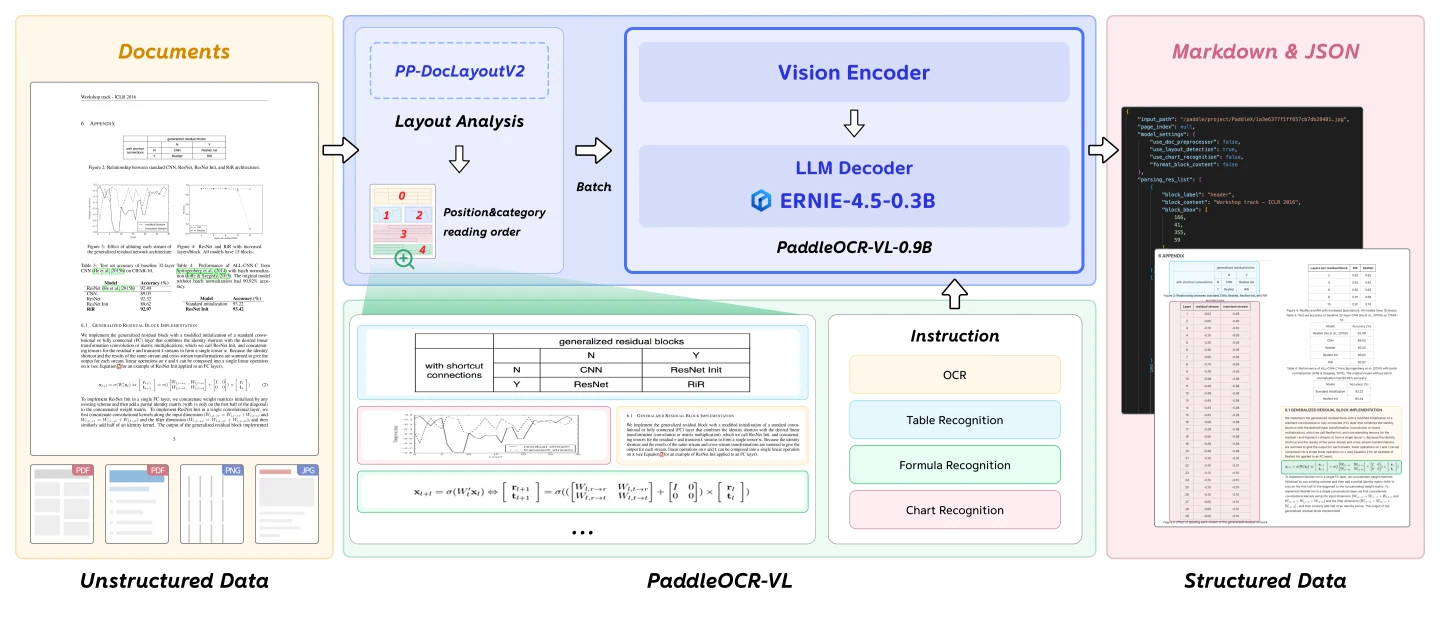
L’encodeur visuel à haute résolution et résolution dynamique de type NaViT permet au modèle de traiter efficacement des documents de résolutions variées, maintenant une extraction de caractéristiques de haute qualité à travers différents types de documents et mises en page. Le modèle de langage léger ERNIE-4.5-0.3B fournit des capacités robustes de compréhension et génération de langage, traitant les caractéristiques visuelles pour générer des sorties structurées.
Cette conception architecturale atteint un équilibre optimal entre la taille du modèle, la vitesse d’inférence et la précision de reconnaissance, ce qui rend PaddleOCR-VL-0.9B idéal pour un déploiement pratique où les performances et l’efficacité sont des exigences critiques.
Benchmarks de performance
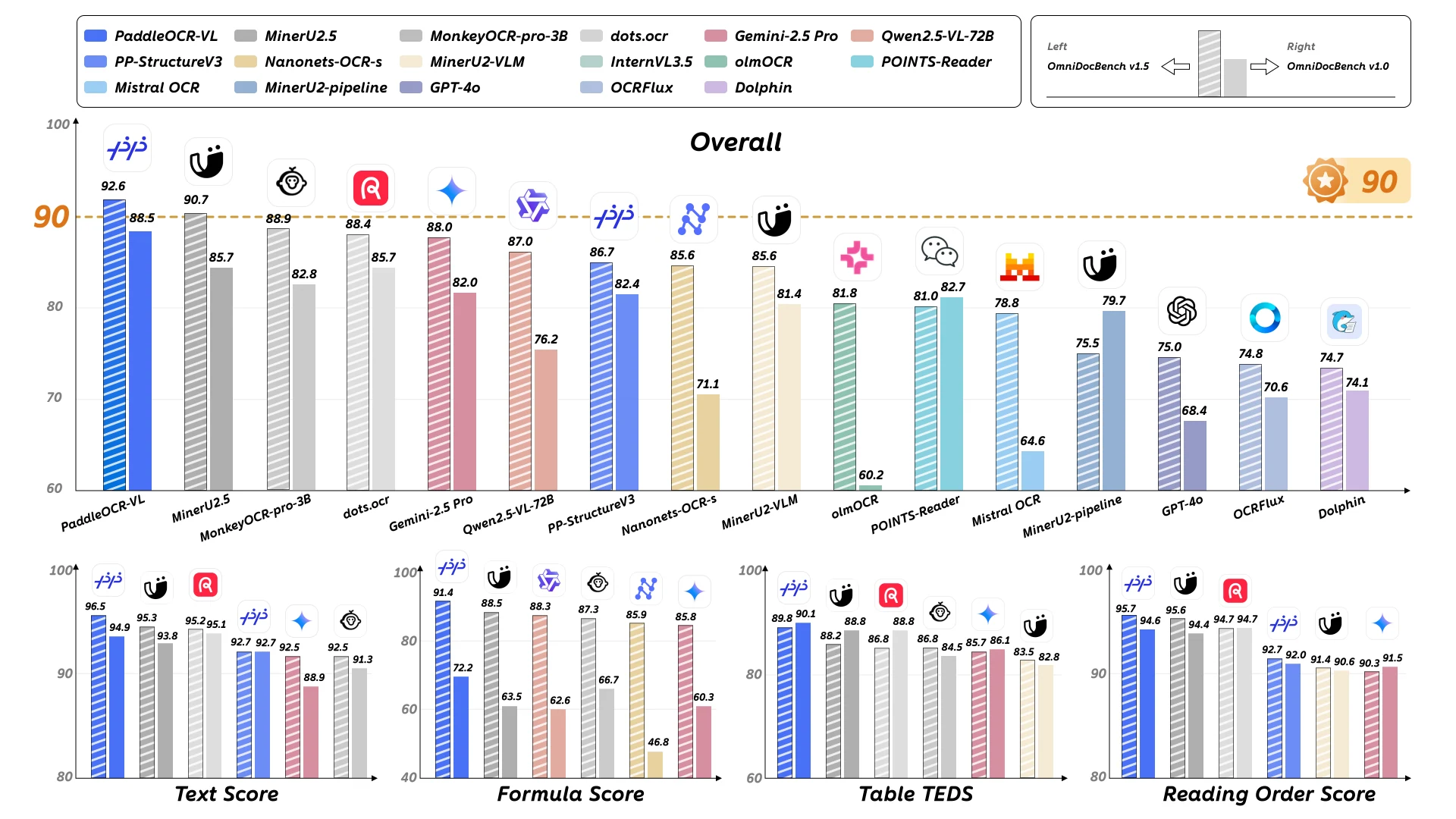
PaddleOCR-VL démontre des performances exceptionnelles à travers plusieurs dimensions d’évaluation, s’affirmant comme une solution de pointe (SOTA) pour l’analyse de documents et la reconnaissance d’éléments.
Analyse de documents au niveau de la page
OmniDocBench v1.5 : PaddleOCR-VL atteint des performances de pointe (SOTA) pour l’ensemble des métriques, le texte, les formules, les tableaux et l’ordre de lecture sur OmniDocBench v1.5.
Le modèle surpasse systématiquement les solutions concurrentes à travers toutes les catégories évaluées, démontrant ses capacités globales de compréhension de documents.
OmniDocBench v1.0 : PaddleOCR-VL atteint des performances de pointe (SOTA) pour presque toutes les métriques d’ensemble, de texte, de formules, de tableaux et d’ordre de lecture sur OmniDocBench v1.0.
Ces résultats valident les capacités robustes du modèle à travers des types de documents et des niveaux de complexité variés.
Note : Les métriques proviennent de MinerU, d’OmniDocBench et d’évaluations internes.
Reconnaissance au niveau des éléments
Reconnaissance de texte : La capacité robuste et polyvalente de PaddleOCR-VL à traiter des types de documents variés en fait la méthode leader dans l’évaluation des performances OmniDocBench-OCR-block.
L’évaluation OCR interne fournit une évaluation des performances à travers plusieurs langues et types de texte. PaddleOCR-VL démontre une précision exceptionnelle avec les distances d’édition les plus faibles dans toutes les écritures évaluées.
Reconnaissance de tableaux : L’ensemble d’évaluation construit en interne contient des types variés d’images de tableaux, comme des tableaux en chinois, en anglais et mixtes chinois-anglais, des tableaux avec des bordures complètes, partielles ou inexistantes, des formats de livres/manuels, des listes, des articles académiques, des tableaux avec des cellules fusionnées, ainsi que des tableaux de basse qualité et avec filigrane.
PaddleOCR-VL atteint des performances remarquables dans toutes les catégories.
Reconnaissance de formules : L’ensemble d’évaluation contient des impressions simples, des impressions complexes, des scans par caméra et des formules manuscrites.
PaddleOCR-VL démontre les meilleures performances dans chaque catégorie.
Reconnaissance de graphiques : L’ensemble d’évaluation est largement classé en 11 catégories de graphiques, incluant les hybrides barres-courbes, les camemberts, les barres empilées à 100 %, les aires, les barres, les bulles, les histogrammes, les courbes, les nuages de points, les aires empilées et les barres empilées.
PaddleOCR-VL surpasse non seulement les modèles VLM OCR experts, mais également certains modèles de langage multimodaux de 72 milliards de paramètres.
Cas d’usage et applications
Numérisation de documents
Transformez des documents papier en formats numériques consultables grâce à la puissante capacité de reconnaissance de texte de PaddleOCR-VL à travers 109 langues. Traitez des factures, des reçus, des contrats et des documents professionnels efficacement tout en maintenant une haute précision même avec des scans de basse qualité ou du contenu avec filigrane.
Recherche académique
Extrayez des formules mathématiques, des tableaux et du texte d’articles de recherche et de publications scientifiques. La capacité exceptionnelle de reconnaissance de formules de PaddleOCR-VL gère à la fois des expressions mathématiques simples et complexes, ce qui le rend idéal pour la revue de littérature et l’extraction de données de contenus académiques.
Traitement de documents financiers
Automatisez l’extraction de données d’états financiers, de bilans et de rapports. La reconnaissance avancée de tableaux du modèle analyse avec précision des tableaux complexes avec des cellules fusionnées, plusieurs langues et divers styles de formatage couramment présents dans les documents financiers.
Numérisation d’archives historiques
Préservez des documents historiques et des manuscrits grâce à la capacité robuste de PaddleOCR-VL à traiter des contenus difficiles incluant le texte manuscrit, les anciennes polices, l’encre effacée et le papier vieilli. Le modèle maintient sa précision même avec des documents historiques dans diverses écritures et langues.
Analyse de graphiques et de données
Extrayez des informations à partir de représentations visuelles de données à travers 11 types de graphiques incluant les graphiques à barres, les camemberts, les courbes et les visualisations hybrides complexes. Parfait pour les applications de business intelligence et les systèmes de reporting automatisé.
Démarrage avec PaddleOCR sur la plateforme Novita AI
Accéder à PaddleOCR-VL via Novita AI offre plusieurs voies adaptées à différents niveaux d’expertise technique et cas d’usage. Que vous soyez un utilisateur professionnel explorant les capacités de l’IA ou un développeur créant des applications de production, Novita AI vous fournit les outils dont vous avez besoin.
Utiliser le Playground (Disponible maintenant – Aucun code requis)
- Accès instantané : Inscrivez-vous et commencez à expérimenter avec PaddleOCR-VL en quelques secondes
- Interface interactive : Testez l’analyse de documents et visualisez les sorties en temps réel
- Comparaison de modèles : Comparez PaddleOCR-VL avec d’autres modèles leaders pour votre cas d’usage spécifique
Le playground vous permet de tester différents types de documents et de voir des résultats immédiats sans aucune configuration technique. Parfait pour le prototypage, le test d’idées et la compréhension des capacités du modèle avant une mise en œuvre complète.
Intégration via API (Disponible et prête – Pour les développeurs)
Connectez PaddleOCR-VL à vos applications avec l’API REST unifiée de Novita AI.
Option 1 : Intégration API directe (Exemple Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="",
)
model = "paddlepaddle/paddleocr-vl"
stream = True # or False
max_tokens = 8192
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Option 2 : Workflows multi-agents avec le SDK OpenAI Agents
Créez des systèmes multi-agents sophistiqués exploitant les capacités avancées d’analyse de documents de PaddleOCR-VL :
- Intégration prête à l’emploi : Utilisez PaddleOCR-VL dans tout workflow OpenAI Agents
- Capacités d’agents avancées : Prise en charge des transferts, du routage et de l’intégration d’outils avec la compréhension de documents
- Architecture évolutive : Concevez des agents qui exploitent les capacités d’OCR multilingue et de reconnaissance d’éléments de PaddleOCR-VL
Option 3 : Connexion avec des plateformes tierces
Outils de développement : Intégrez-vous de manière transparente avec des IDE et environnements de développement populaires comme Cursor, Trae et Cline via des API compatibles OpenAI et des API compatibles Anthropic.
Frameworks d’orchestration : Connectez-vous avec LangChain, Dify, CrewAI, Langflow et d’autres plateformes d’orchestration IA en utilisant des connecteurs officiels.
Intégration Hugging Face : Novita AI est un fournisseur d’inférence officiel de Hugging Face, garantissant une compatibilité large avec l’écosystème.
Conclusion
PaddleOCR sur Novita AI offre des capacités d’analyse de documents multilingue de pointe (SOTA) grâce à un modèle vision-langage ultra-compact de 0,9B qui combine une précision exceptionnelle et une efficacité remarquable. Avec la prise en charge de 109 langues, des performances de pointe (SOTA) sur les benchmarks OmniDocBench et l’excellence dans la reconnaissance d’éléments de documents complexes incluant le texte, les tableaux, les formules et les graphiques, PaddleOCR-VL représente le choix définitif pour les applications modernes de traitement de documents.
L’architecture compacte du modèle, ses vitesses d’inférence rapides et son efficacité en ressources le rendent particulièrement adapté à un déploiement pratique dans des scénarios réels. Que vous traitiez des documents multilingues, que vous extrayiez des données de tableaux complexes, que vous reconnaissiez des formules mathématiques ou que vous analysiez des graphiques, PaddleOCR-VL sur Novita AI vous fournit les performances et la fiabilité dont vous avez besoin.
Commencez à explorer les capacités révolutionnaires d’analyse de documents de PaddleOCR-VL sur Novita AI dès aujourd’hui et découvrez l’avenir du traitement intelligent de documents avec notre plateforme conviviale pour les développeurs et nos options d’intégration transparentes.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.



