

O PaddleOCR-VL já está disponível na plataforma Novita AI, trazendo capacidades de análise de documentos multilíngue de última geração por meio de um modelo de visão e linguagem ultracompacto de 0,9B. Essa solução inovadora integra um codificador visual de resolução dinâmica no estilo NaViT com o modelo de linguagem ERNIE-4.5-0.3B para permitir o reconhecimento preciso de elementos em 109 idiomas.
O PaddleOCR-VL-0.9B é um modelo de visão e linguagem compacto, mas poderoso, que se destaca no reconhecimento de elementos complexos como texto, tabelas, fórmulas e gráficos, mantendo um consumo mínimo de recursos. Por meio de avaliações abrangentes em benchmarks públicos amplamente utilizados e benchmarks internos, o PaddleOCR-VL alcança desempenho de última geração (SOTA) tanto na análise de documentos em nível de página quanto no reconhecimento em nível de elemento.
Ele supera significativamente as soluções existentes, apresenta forte competitividade contra os VLMs de nível superior e oferece velocidades de inferência rápidas, adequadas para implantação prática em cenários do mundo real.
O que é o PaddleOCR-VL?
O PaddleOCR-VL é um modelo de última geração (SOTA) e eficiente em recursos, desenvolvido especialmente para análise de documentos. Seu componente principal é o PaddleOCR-VL-0.9B, um modelo de visão e linguagem compacto, mas poderoso, que integra um codificador visual de resolução dinâmica no estilo NaViT com o modelo de linguagem ERNIE-4.5-0.3B para permitir o reconhecimento preciso de elementos.
Esse modelo inovador oferece suporte eficiente a 109 idiomas e se destaca no reconhecimento de elementos complexos, incluindo texto, tabelas, fórmulas e gráficos, mantendo um consumo mínimo de recursos. Por meio de avaliações abrangentes em benchmarks públicos amplamente utilizados e benchmarks internos, o PaddleOCR-VL alcança desempenho de última geração (SOTA) tanto na análise de documentos em nível de página quanto no reconhecimento em nível de elemento.
O modelo supera significativamente as soluções existentes, apresenta forte competitividade contra os VLMs de nível superior e oferece velocidades de inferência rápidas. Essas qualidades o tornam altamente adequado para implantação prática em cenários do mundo real.
Principais Funcionalidades
Arquitetura de VLM Compacta, mas Poderosa
O PaddleOCR-VL apresenta um modelo de visão e linguagem inovador, projetado especificamente para inferência eficiente em recursos, alcançando desempenho excepcional no reconhecimento de elementos. Ao integrar um codificador visual de alta resolução dinâmica no estilo NaViT com o modelo de linguagem leve ERNIE-4.5-0.3B, o sistema aumenta significativamente as capacidades de reconhecimento do modelo e a eficiência de decodificação. Essa integração mantém alta precisão enquanto reduz as demandas computacionais, tornando-o muito adequado para aplicações de processamento de documentos eficientes e práticas.
Desempenho de Última Geração (SOTA) na Análise de Documentos
O PaddleOCR-VL alcança desempenho de última geração (SOTA) tanto na análise de documentos em nível de página quanto no reconhecimento em nível de elemento. Ele supera significativamente as soluções baseadas em pipeline existentes e apresenta forte competitividade contra os principais modelos de visão e linguagem na análise de documentos. Além disso, o PaddleOCR-VL se destaca no reconhecimento de elementos complexos de documentos, como texto, tabelas, fórmulas e gráficos, tornando-o adequado para uma ampla variedade de tipos de conteúdo desafiadores, incluindo texto manuscrito e documentos históricos. Isso o torna altamente versátil e adequado para uma ampla gama de tipos de documentos e cenários.
Suporte Multilíngue
O PaddleOCR-VL oferece suporte a 109 idiomas, abrangendo os principais idiomas globais, incluindo, mas não se limitando a, chinês, inglês, japonês, latim e coreano. Ele também oferece suporte a idiomas com diferentes escritas e estruturas, como russo (escrita cirílica), árabe, hindi (escrita devanágari) e tailandês.
Essa ampla cobertura de idiomas aumenta substancialmente a aplicabilidade do sistema em cenários de processamento de documentos multilíngues e globalizados.
Arquitetura do Modelo
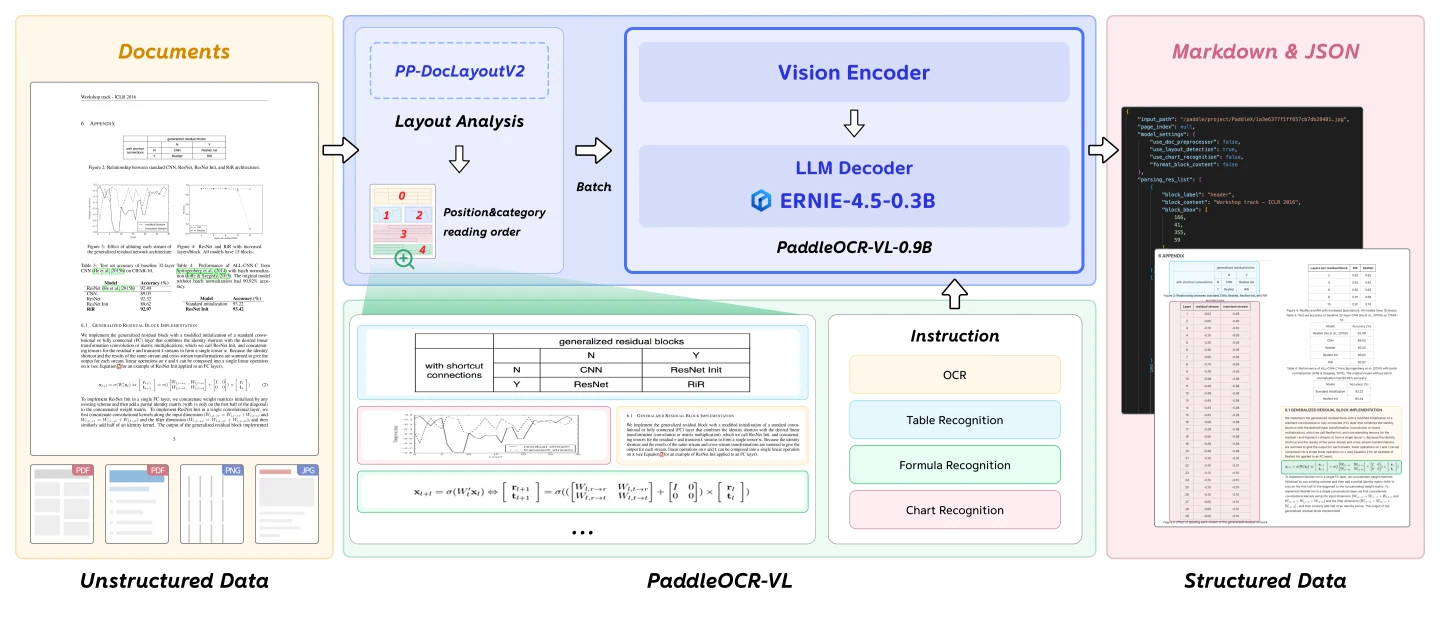
O codificador visual de alta resolução dinâmica no estilo NaViT permite que o modelo processe documentos de resoluções variadas de forma eficiente, mantendo a extração de recursos de alta qualidade em diferentes tipos e layouts de documentos. O modelo de linguagem leve ERNIE-4.5-0.3B fornece capacidades robustas de compreensão e geração de linguagem, processando os recursos visuais para gerar saídas estruturadas.
Esse projeto arquitetônico alcança um equilíbrio ideal entre tamanho do modelo, velocidade de inferência e precisão de reconhecimento, tornando o PaddleOCR-VL-0.9B ideal para implantação prática, onde desempenho e eficiência são requisitos críticos.
Benchmarks de Desempenho
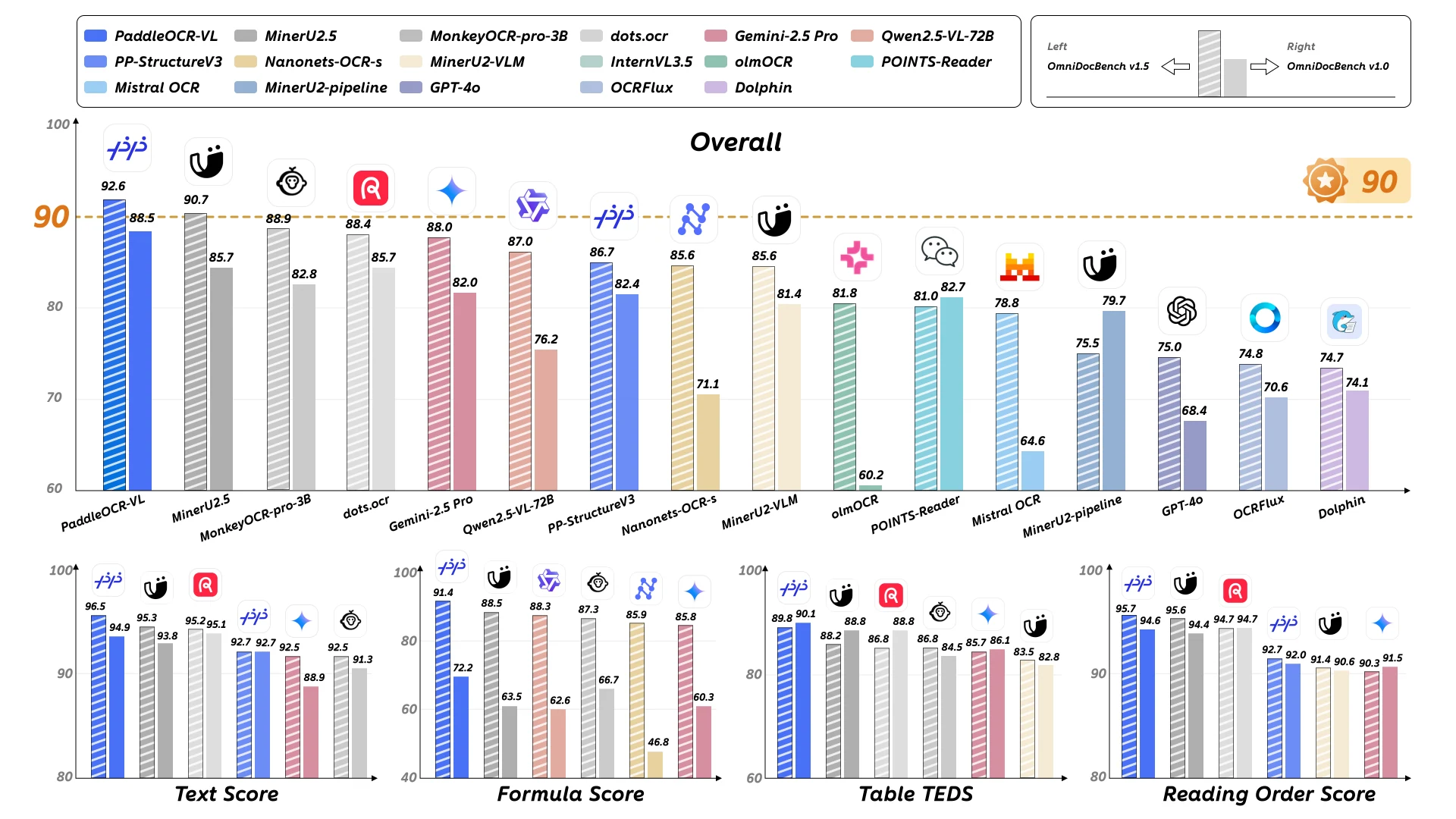
O PaddleOCR-VL demonstra desempenho excepcional em múltiplas dimensões de avaliação, consolidando-se como uma solução de última geração (SOTA) para análise de documentos e reconhecimento de elementos.
Análise de Documentos em Nível de Página
OmniDocBench v1.5: O PaddleOCR-VL alcança desempenho SOTA nos indicadores gerais, de texto, fórmulas, tabelas e ordem de leitura no OmniDocBench v1.5.
O modelo supera consistentemente as soluções concorrentes em todas as categorias avaliadas, demonstrando suas capacidades abrangentes de compreensão de documentos.
OmniDocBench v1.0: O PaddleOCR-VL alcança desempenho SOTA em quase todos os indicadores gerais, de texto, fórmulas, tabelas e ordem de leitura no OmniDocBench v1.0.
Esses resultados validam as capacidades robustas do modelo em diferentes tipos de documentos e níveis de complexidade.
Nota: As métricas são provenientes de avaliações do MinerU, OmniDocBench e avaliações internas.
Reconhecimento em Nível de Elemento
Reconhecimento de Texto: A capacidade robusta e versátil do PaddleOCR-VL para lidar com diferentes tipos de documentos o estabelece como o método líder na avaliação de desempenho OmniDocBench-OCR-block.
A avaliação de OCR interna fornece uma avaliação de desempenho em múltiplos idiomas e tipos de texto. O PaddleOCR-VL demonstra precisão excepcional, com as menores distâncias de edição em todas as escritas avaliadas.
Reconhecimento de Tabelas: O conjunto de avaliação próprio contém diversos tipos de imagens de tabelas, como tabelas em chinês, inglês e mistas de chinês e inglês, tabelas com bordas completas, parciais ou sem bordas, formatos de livros/manuais, listas, artigos acadêmicos, tabelas com células mescladas, além de tabelas de baixa qualidade e com marca d’água.
O PaddleOCR-VL alcança desempenho notável em todas as categorias.
Reconhecimento de Fórmulas: O conjunto de avaliação contém impressões simples, impressões complexas, digitalizações de câmera e fórmulas manuscritas.
O PaddleOCR-VL demonstra o melhor desempenho em todas as categorias.
Reconhecimento de Gráficos: O conjunto de avaliação é amplamente categorizado em 11 tipos de gráficos, incluindo híbrido de barra e linha, pizza, barra empilhada 100%, área, barra, bolha, histograma, linha, dispersão, área empilhada e barra empilhada.
O PaddleOCR-VL não apenas supera os VLMs de OCR especializados, mas também ultrapassa alguns modelos de linguagem multimodais de nível 72B.
Casos de Uso e Aplicações
Digitalização de Documentos
Transforme documentos físicos em formatos digitais pesquisáveis com o poderoso reconhecimento de texto do PaddleOCR-VL em 109 idiomas. Processe faturas, recibos, contratos e documentos comerciais de forma eficiente, mantendo alta precisão mesmo com digitalizações de baixa qualidade ou conteúdo com marca d’água.
Pesquisa Acadêmica
Extraia fórmulas matemáticas, tabelas e texto de artigos de pesquisa e publicações científicas. O reconhecimento excepcional de fórmulas do PaddleOCR-VL lida com expressões matemáticas simples e complexas, tornando-o ideal para revisão de literatura e extração de dados de conteúdo acadêmico.
Processamento de Documentos Financeiros
Automatize a extração de dados de demonstrações financeiras, balanços patrimoniais e relatórios. O reconhecimento avançado de tabelas do modelo analisa com precisão tabelas complexas com células mescladas, múltiplos idiomas e vários estilos de formatação comuns em documentos financeiros.
Digitalização de Arquivos Históricos
Preserve documentos históricos e manuscritos com o tratamento robusto de conteúdo desafiador do PaddleOCR-VL, incluindo texto manuscrito, fontes antigas, tinta desbotada e papel envelhecido. O modelo mantém a precisão mesmo com documentos históricos em diferentes escritas e idiomas.
Análise de Gráficos e Dados
Extraia insights de representações visuais de dados em 11 tipos de gráficos, incluindo gráficos de barras, gráficos de pizza, gráficos de linha e visualizações híbridas complexas. Perfeito para aplicações de inteligência de negócios e sistemas de relatórios automatizados.
Primeiros Passos com o PaddleOCR na Plataforma Novita AI
Acessar o PaddleOCR-VL por meio da Novita AI oferece múltiplos caminhos adaptados a diferentes níveis de conhecimento técnico e casos de uso. Seja você um usuário empresarial explorando capacidades de IA ou um desenvolvedor criando aplicações de produção, a Novita AI fornece as ferramentas que você precisa.
Use o Playground (Disponível Agora – Sem Necessidade de Código)
- Acesso Imediato: Cadastre-se e comece a experimentar o PaddleOCR-VL em segundos
- Interface Interativa: Teste a análise de documentos e visualize as saídas em tempo real
- Comparação de Modelos: Compare o PaddleOCR-VL com outros modelos líderes para seu caso de uso específico
O playground permite testar diferentes tipos de documentos e ver resultados imediatos sem nenhuma configuração técnica. Perfeito para prototipagem, teste de ideias e compreensão das capacidades do modelo antes da implementação completa.
Integre via API (Disponível e Pronto – Para Desenvolvedores)
Conecte o PaddleOCR-VL às suas aplicações com a API REST unificada da Novita AI.
Opção 1: Integração Direta via API (Exemplo em Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="",
)
model = "paddlepaddle/paddleocr-vl"
stream = True # or False
max_tokens = 8192
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Opção 2: Fluxos de Trabalho Multiagente com o SDK OpenAI Agents
Construa sistemas multiagente sofisticados aproveitando as capacidades avançadas de análise de documentos do PaddleOCR-VL:
- Integração Plug-and-Play: Use o PaddleOCR-VL em qualquer fluxo de trabalho do OpenAI Agents
- Capacidades Avançadas de Agente: Suporte a transferências, roteamento e integração de ferramentas com compreensão de documentos
- Arquitetura Escalável: Projete agentes que aproveitem as capacidades de OCR multilíngue e reconhecimento de elementos do PaddleOCR-VL
Opção 3: Conecte-se a Plataformas de Terceiros
Ferramentas de Desenvolvimento: Integre-se perfeitamente com IDEs populares e ambientes de desenvolvimento como Cursor, Trae e Cline por meio de APIs compatíveis com OpenAI e APIs compatíveis com Anthropic.
Frameworks de Orquestração: Conecte-se com LangChain, Dify, CrewAI, Langflow e outras plataformas de orquestração de IA usando conectores oficiais.
Integração com Hugging Face: A Novita AI atua como um provedor de inferência oficial do Hugging Face, garantindo ampla compatibilidade com o ecossistema.
Conclusão
O PaddleOCR na Novita AI oferece capacidades de análise de documentos multilíngue de última geração por meio de um modelo de visão e linguagem ultracompacto de 0,9B que combina precisão excepcional com eficiência notável. Com suporte a 109 idiomas, desempenho SOTA nos benchmarks OmniDocBench e excelência no reconhecimento de elementos complexos de documentos, incluindo texto, tabelas, fórmulas e gráficos, o PaddleOCR-VL representa a escolha definitiva para aplicações modernas de processamento de documentos.
A arquitetura compacta do modelo, as velocidades de inferência rápidas e a eficiência de recursos o tornam altamente adequado para implantação prática em cenários do mundo real. Seja você processando documentos multilíngues, extraindo dados de tabelas complexas, reconhecendo fórmulas matemáticas ou analisando gráficos, o PaddleOCR-VL na Novita AI fornece o desempenho e a confiabilidade que você precisa.
Comece a explorar as capacidades revolucionárias de análise de documentos do PaddleOCR-VL na Novita AI hoje e experimente o futuro do processamento de documentos inteligente com nossa plataforma amigável para desenvolvedores e opções de integração perfeitas.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construção e escalonamento.



