

Модель PaddleOCR-VL теперь доступна на платформе Novita AI, предоставляя передовые возможности многоязычного парсинга документов благодаря ультракомпактной 0.9B зрительно-языковой модели. Это инновационное решение объединяет визуальный энкодер с динамическим разрешением в стиле NaViT и языковую модель ERNIE-4.5-0.3B, что обеспечивает точное распознавание элементов на 109 языках.
PaddleOCR-VL-0.9B — это компактная, но мощная зрительно-языковая модель, которая отлично справляется с распознаванием сложных элементов, таких как текст, таблицы, формулы и диаграммы, при минимальном потреблении ресурсов. По результатам комплексных оценок на широко используемых публичных бенчмарках и внутренних бенчмарках PaddleOCR-VL достигает передовых (SOTA) результатов как в парсинге документов на уровне страницы, так и в распознавании отдельных элементов.
Модель значительно превосходит существующие решения, демонстрирует высокую конкурентоспособность по сравнению с топовыми зрительно-языковыми моделями (VLM) и обеспечивает высокую скорость инференса, подходящую для практического развертывания в реальных сценариях использования.
Что такое PaddleOCR-VL?
PaddleOCR-VL — это передовая (SOTA) и ресурсоэффективная модель, созданная специально для парсинга документов. Её основным компонентом является PaddleOCR-VL-0.9B — компактная, но мощная зрительно-языковая модель, которая объединяет визуальный энкодер с динамическим разрешением в стиле NaViT и языковую модель ERNIE-4.5-0.3B для обеспечения точного распознавания элементов.
Эта инновационная модель эффективно поддерживает 109 языков и отлично справляется с распознаванием сложных элементов, включая текст, таблицы, формулы и диаграммы, при минимальном потреблении ресурсов. По результатам комплексных оценок на широко используемых публичных и внутренних бенчмарках PaddleOCR-VL достигает передовых (SOTA) результатов как в парсинге документов на уровне страницы, так и в распознавании отдельных элементов.
Модель значительно превосходит существующие решения, демонстрирует высокую конкурентоспособность по сравнению с топовыми зрительно-языковыми моделями (VLM) и обеспечивает высокую скорость инференса. Эти преимущества делают её идеально подходящей для практического развертывания в реальных сценариях использования.
Основные возможности
Компактная, но мощная архитектура зрительно-языковой модели
PaddleOCR-VL представляет собой новую зрительно-языковую модель, специально разработанную для ресурсоэффективного инференса, которая достигает выдающихся результатов в распознавании элементов. Благодаря интеграции визуального энкодера с динамическим высоким разрешением в стиле NaViT и легковесной языковой модели ERNIE-4.5-0.3B система значительно повышает возможности распознавания модели и эффективность декодирования. Такая интеграция сохраняет высокую точность при снижении вычислительных требований, что делает модель хорошо подходящей для эффективных и практических приложений обработки документов.
Передовые (SOTA) результаты в парсинге документов
PaddleOCR-VL достигает передовых (SOTA) результатов как в парсинге документов на уровне страницы, так и в распознавании отдельных элементов. Модель значительно превосходит существующие решения на основе конвейерной обработки и демонстрирует высокую конкурентоспособность по сравнению с ведущими зрительно-языковыми моделями в области парсинга документов. Более того, PaddleOCR-VL отлично справляется с распознаванием сложных элементов документов, таких как текст, таблицы, формулы и диаграммы, что делает её подходящей для широкого спектра сложных типов контента, включая рукописный текст и исторические документы. Это делает модель крайне универсальной и подходящей для множества типов документов и сценариев использования.
Многоязычная поддержка
PaddleOCR-VL поддерживает 109 языков, включая основные мировые языки, в том числе китайский, английский, японский, латинский и корейский. Модель также поддерживает языки с разными системами письма и структурами, такие как русский (кириллица), арабский, хинди (деванагари) и тайский.
Широкий охват языков значительно расширяет применимость системы в многоязычных и глобальных сценариях обработки документов.
Архитектура модели
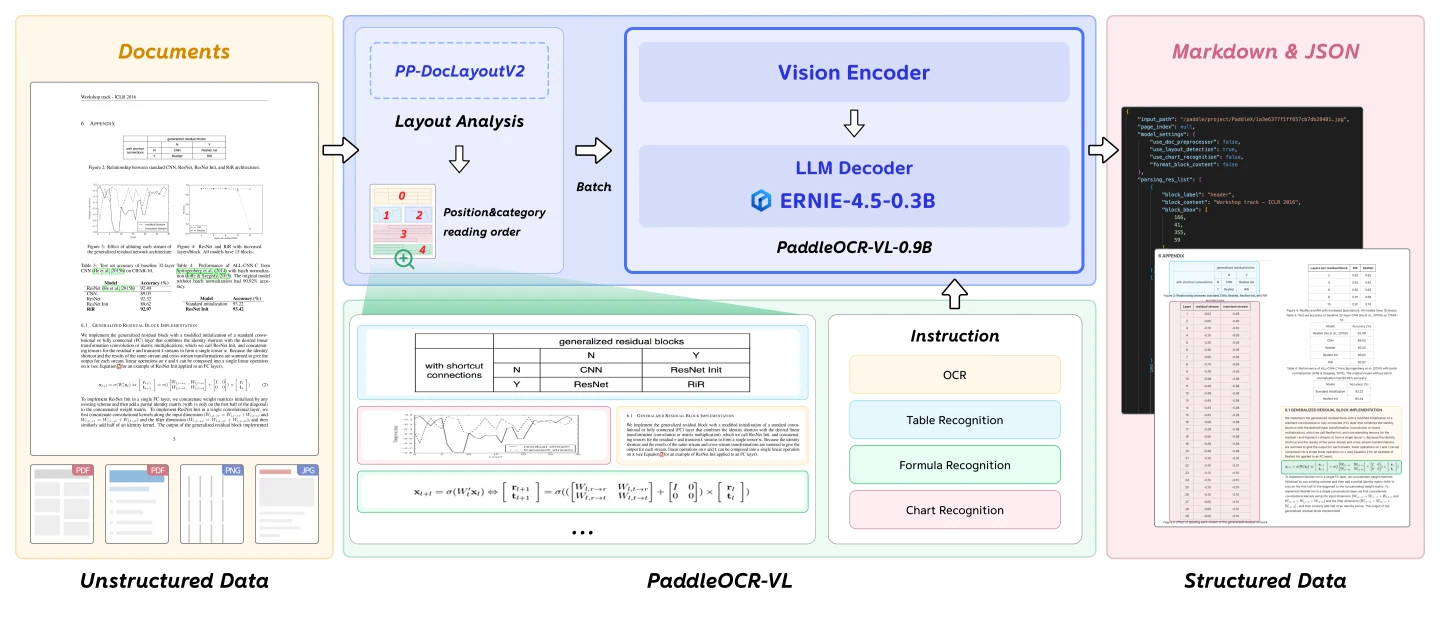
Визуальный энкодер с динамическим высоким разрешением в стиле NaViT позволяет модели эффективно обрабатывать документы с разным разрешением, сохраняя высокое качество извлечения признаков для различных типов и макетов документов. Легковесная языковая модель ERNIE-4.5-0.3B обеспечивает надежные возможности понимания и генерации языка, обрабатывая визуальные признаки для создания структурированных выходных данных.
Такая архитектурная конструкция обеспечивает оптимальный баланс между размером модели, скоростью инференса и точностью распознавания, что делает PaddleOCR-VL-0.9B идеальным для практического развертывания в сценариях, где критически важны как производительность, так и эффективность.
Бенчмарки производительности
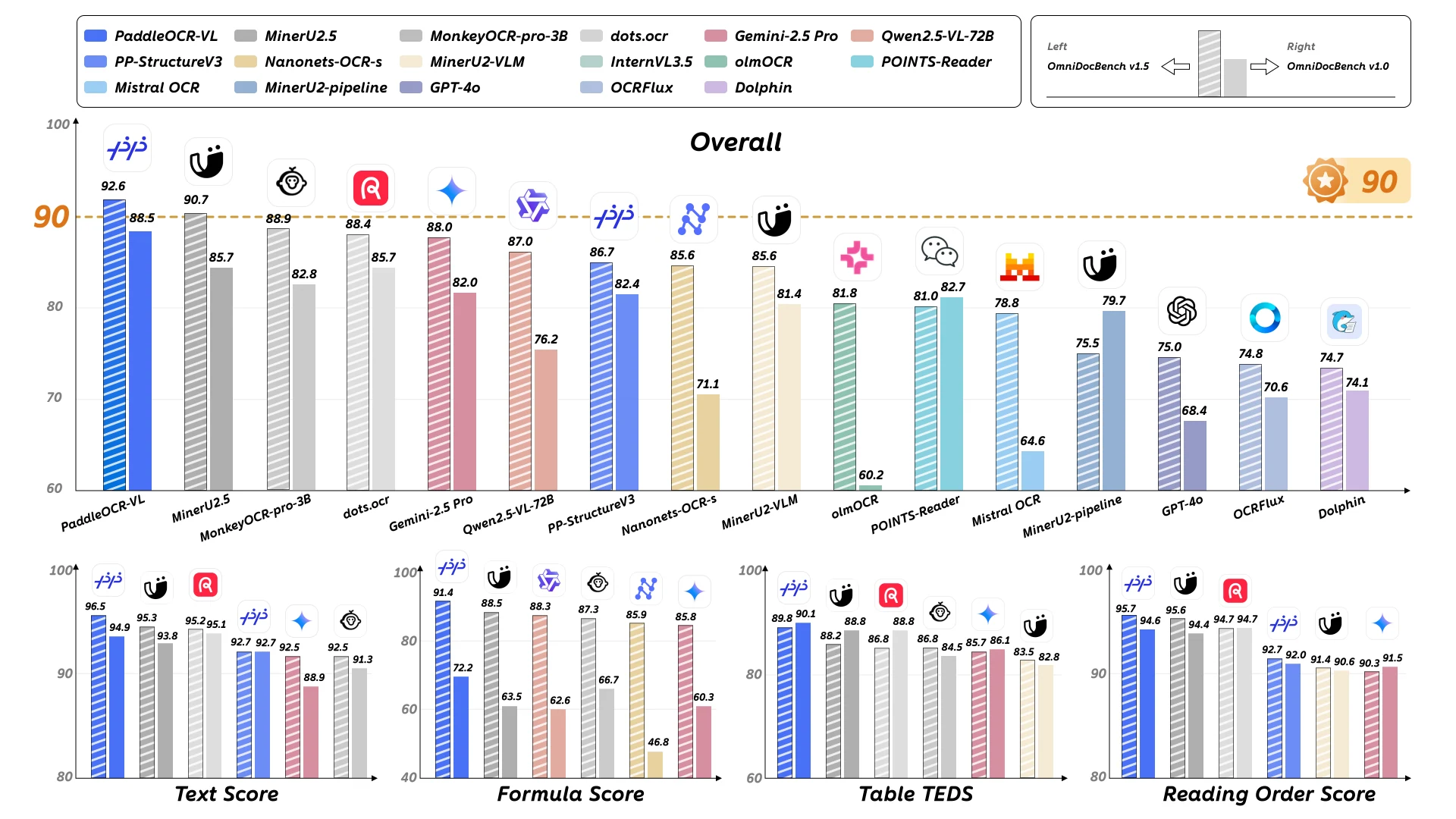
PaddleOCR-VL демонстрирует исключительные результаты по нескольким оценочным измерениям, подтверждая свой статус передового решения для парсинга документов и распознавания элементов.
Парсинг документов на уровне страницы
OmniDocBench v1.5: PaddleOCR-VL достигает передовых (SOTA) результатов по общим показателям, распознаванию текста, формул, таблиц и порядку чтения на OmniDocBench v1.5. Модель стабильно превосходит конкурирующие решения во всех оцениваемых категориях, демонстрируя свои всесторонние возможности понимания документов.
OmniDocBench v1.0: PaddleOCR-VL достигает передовых (SOTA) результатов почти по всем метрикам общих показателей, распознавания текста, формул, таблиц и порядку чтения на OmniDocBench v1.0. Эти результаты подтверждают надежные возможности модели при работе с разнообразными типами документов и уровнями сложности.
Примечание: Метрики получены из MinerU, OmniDocBench и внутренних оценок.
Распознавание отдельных элементов
Распознавание текста: Надежная и универсальная возможность PaddleOCR-VL обрабатывать разнообразные типы документов делает её ведущим методом в оценке производительности OmniDocBench-OCR-block. Внутренняя оценка OCR позволяет оценить производительность на нескольких языках и типах текста. PaddleOCR-VL демонстрирует выдающуюся точность с наименьшими расстояниями редактирования во всех оцениваемых системах письма.
Распознавание таблиц: Собственный набор для оценки содержит разнообразные типы изображений таблиц: китайские, английские и смешанные китайско-английские таблицы, таблицы с полными, частичными или отсутствующими рамками, в формате книг/руководств, списки, научные статьи, таблицы с объединенными ячейками, а также низкокачественные и таблицы с водяными знаками. PaddleOCR-VL достигает выдающихся результатов во всех категориях.
Распознавание формул: Набор для оценки содержит простые печатные формулы, сложные печатные формулы, сканированные с камеры формулы и рукописные формулы. PaddleOCR-VL демонстрирует лучшие результаты в каждой категории.
Распознавание диаграмм: Набор для оценки разделен на 11 категорий диаграмм, включая гибридные столбчато-линейные, круговые, 100% накопленные столбчатые, площадные, столбчатые, пузырьковые, гистограммы, линейные, диаграммы рассеяния, накопленные площадные и накопленные столбчатые диаграммы. PaddleOCR-VL не только превосходит экспертные зрительно-языковые модели для OCR, но и опережает некоторые многоязыковые языковые модели уровня 72B.
Сценарии использования и применения
Оцифровка документов
Преобразуйте бумажные документы в поисковые цифровые форматы с помощью мощного распознавания текста PaddleOCR-VL на 109 языках. Эффективно обрабатывайте счета, квитанции, контракты и бизнес-документы, сохраняя высокую точность даже при работе с низкокачественными сканами или контентом с водяными знаками.
Научные исследования
Извлекайте математические формулы, таблицы и текст из научных статей и публикаций. Исключительные возможности распознавания формул PaddleOCR-VL позволяют работать как с простыми, так и со сложными математическими выражениями, что делает модель идеальной для обзора литературы и извлечения данных из академического контента.
Обработка финансовых документов
Автоматизируйте извлечение данных из финансовых отчетов, балансов и бухгалтерской отчетности. Продвинутое распознавание таблиц модели точно парсит сложные таблицы с объединенными ячейками, несколькими языками и различными стилями форматирования, обычно встречающимися в финансовых документах.
Оцифровка исторических архивов
Сохраняйте исторические документы и рукописи благодаря надежной обработке сложного контента PaddleOCR-VL, включая рукописный текст, старые шрифты, выцветшую краску и состаренную бумагу. Модель сохраняет точность даже при работе с историческими документами на различных системах письма и языках.
Анализ диаграмм и данных
Извлекайте инсайты из визуальных представлений данных 11 типов диаграмм, включая столбчатые диаграммы, круговые диаграммы, линейные графики и сложные гибридные визуализации. Идеально подходит для приложений бизнес-аналитики и автоматизированных систем отчетности.
Начало работы с PaddleOCR на платформе Novita AI
Доступ к PaddleOCR-VL через Novita AI предоставляет несколько путей, адаптированных под разные уровни технической экспертизы и сценарии использования. Независимо от того, являетесь ли вы бизнес-пользователем, изучающим возможности ИИ, или разработчиком, создающим производственные приложения, Novita AI предоставляет все необходимые инструменты.
Используйте Playground (доступно сейчас — не требуется написание кода)
- Мгновенный доступ: Зарегистрируйтесь и начните экспериментировать с PaddleOCR-VL за считанные секунды
- Интерактивный интерфейс: Тестируйте парсинг документов и визуализируйте результаты в реальном времени
- Сравнение моделей: Сравнивайте PaddleOCR-VL с другими ведущими моделями для вашего конкретного сценария использования
Playground позволяет тестировать различные типы документов и получать мгновенные результаты без какой-либо технической настройки. Идеально подходит для прототипирования, тестирования идей и понимания возможностей модели перед полной реализацией.
Интеграция через API (работает и готово к использованию — для разработчиков)
Подключите PaddleOCR-VL к вашим приложениям с помощью унифицированного REST API Novita AI.
Вариант 1: Прямая интеграция через API (пример на Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="",
)
model = "paddlepaddle/paddleocr-vl"
stream = True # or False
max_tokens = 8192
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Вариант 2: Многоагентные рабочие процессы с помощью OpenAI Agents SDK
Создавайте сложные многоагентные системы, используя продвинутые возможности парсинга документов PaddleOCR-VL:
- Интеграция без дополнительной настройки: Используйте PaddleOCR-VL в любом рабочем процессе OpenAI Agents
- Продвинутые возможности агентов: Поддержка передачи задач, маршрутизации и интеграции инструментов с возможностью понимания документов
- Масштабируемая архитектура: Проектируйте агентов, которые используют многоязычные возможности OCR и распознавания элементов PaddleOCR-VL
Вариант 3: Подключение к сторонним платформам
Инструменты для разработки: Бесшовно интегрируйтесь с популярными IDE и средами разработки, такими как Cursor, Trae и Cline, через совместимые с OpenAI API и совместимые с Anthropic API.
Оркестрационные фреймворки: Подключайтесь к LangChain, Dify, CrewAI, Langflow и другим платформам для оркестрации ИИ с помощью официальных коннекторов.
Интеграция с Hugging Face: Novita AI является официальным провайдером инференса Hugging Face, что обеспечивает широкую совместимость с экосистемой.
Заключение
PaddleOCR на Novita AI предоставляет передовые возможности многоязычного парсинга документов благодаря ультракомпактной 0.9B зрительно-языковой модели, которая сочетает исключительную точность и высокую эффективность. При поддержке 109 языков, передовых (SOTA) результатах на бенчмарках OmniDocBench и выдающихся возможностях распознавания сложных элементов документов, включая текст, таблицы, формулы и диаграммы, PaddleOCR-VL является однозначным выбором для современных приложений обработки документов.
Компактная архитектура модели, высокая скорость инференса и ресурсоэффективность делают её крайне подходящей для практического развертывания в реальных сценариях. Независимо от того, обрабатываете ли вы многоязычные документы, извлекаете данные из сложных таблиц, распознаете математические формулы или анализируете диаграммы, PaddleOCR-VL на Novita AI предоставляет необходимую вам производительность и надежность.
Начните изучать революционные возможности парсинга документов PaddleOCR-VL на Novita AI уже сегодня и ощутите будущее интеллектуальной обработки документов с нашей удобной для разработчиков платформой и бесшовными вариантами интеграции.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развертывания моделей ИИ с помощью нашего простого API, а также предоставляет доступное и надежное облако GPU для разработки и масштабирования.



