

PaddleOCR-VL 現已上線 Novita AI 平台,搭載超輕量 0.9B 視覺語言模型,提供最先進的多語言文件解析能力。這款創新型解決方案整合了 NaViT 風格的動態解析度視覺編碼器與 ERNIE-4.5-0.3B 語言模型,可精準辨識 109 種語言的文件元素。
PaddleOCR-VL-0.9B 是一款輕量卻功能強大的視覺語言模型,擅長辨識文字、表格、公式、圖表等複雜元素,同時資源消耗極低。透過在廣泛使用的公開基準測試與內部基準測試中的全面評估,PaddleOCR-VL 在頁面級文件解析與元素級辨識兩方面都達到了 SOTA(最先進)效能。
其效能顯著優於現有解決方案,對比其他級頂尖視覺語言模型(VLM)也具備極強競爭力,且推論速度快速,非常適合在真實場景中實際部署。
什麼是 PaddleOCR-VL?
PaddleOCR-VL 是一款專為文件解析設計的 SOTA(最先進)高資源效率模型。其核心組件為 PaddleOCR-VL-0.9B,這是一款輕量卻功能強大的視覺語言模型,整合了 NaViT 風格的動態解析度視覺編碼器與 ERNIE-4.5-0.3B 語言模型,可實現精準的元素辨識。
這款創新型模型高效支援 109 種語言,擅長辨識文字、表格、公式、圖表等複雜元素,同時資源消耗極低。透過在廣泛使用的公開基準測試與內部基準測試中的全面評估,PaddleOCR-VL 在頁面級文件解析與元素級辨識兩方面都達到了 SOTA(最先進)效能。
該模型效能顯著優於現有解決方案,對比其他級頂尖視覺語言模型(VLM)也具備極強競爭力,且推論速度快速。這些優勢使其非常適合在真實場景中實際部署。
核心特色
輕量卻強大的 VLM 架構
PaddleOCR-VL 是一款新穎的視覺語言模型,專為資源高效的推論設計,在元素辨識方面表現優異。透過整合 NaViT 風格的動態高解析度視覺編碼器與輕量 ERNIE-4.5-0.3B 語言模型,系統大幅提升了模型的辨識能力與解碼效率。這種整合方式在降低運算需求的同時維持高準確率,非常適合高效且實用的文件處理應用場景。
文件解析的 SOTA(最先進)效能
PaddleOCR-VL 在頁面級文件解析與元素級辨識兩方面都達到了最先進的效能水準。其效能顯著優於現有基於管線的解決方案,在文件解析領域對比領先的視覺語言模型也具備極強競爭力。此外,PaddleOCR-VL 擅長辨識文字、表格、公式、圖表等複雜文件元素,適用於多種高難度內容類型,包含手寫文字與歷史文件,通用性極高,可適用於各類文件與場景。
多語言支援
PaddleOCR-VL 支援 109 種語言,涵蓋全球主要語言,包含但不限於中文、英文、日文、拉丁語系與韓文。同時也支援不同書寫系統與結構的語言,例如俄文(西里爾字母)、阿拉伯文、印地文(天城文)與泰文。
如此廣泛的語言覆蓋範圍大幅提升了系統在多語言與全球化文件處理場景中的適用性。
模型架構
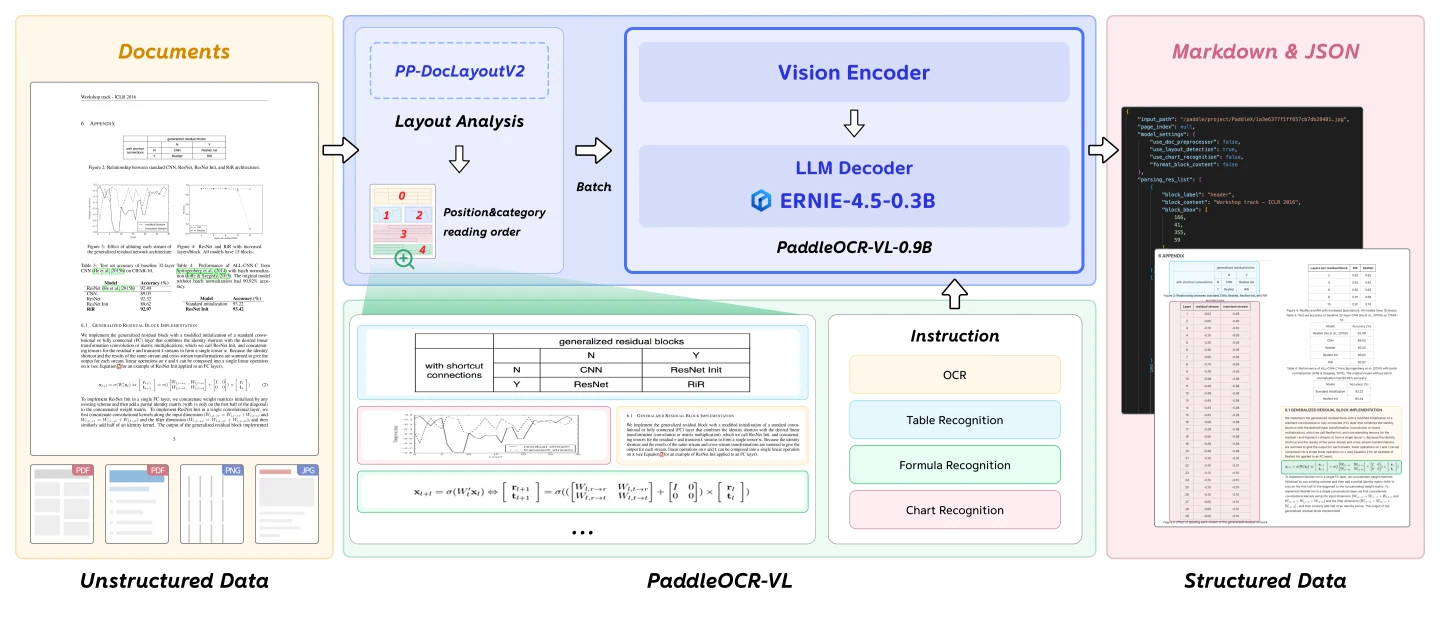
NaViT 風格的動態高解析度視覺編碼器能讓模型高效處理不同解析度的文件,在不同文件類型與版式中維持高品質的特徵提取。輕量 ERNIE-4.5-0.3B 語言模型則提供強大的語言理解與生成能力,可處理視覺特徵並輸出結構化結果。
這樣的架構設計在模型大小、推論速度與辨識準確率之間達到了最佳平衡,使得 PaddleOCR-VL-0.9B 非常適合在效能與效率皆為關鍵需求的實際部署場景中使用。
效能基準測試
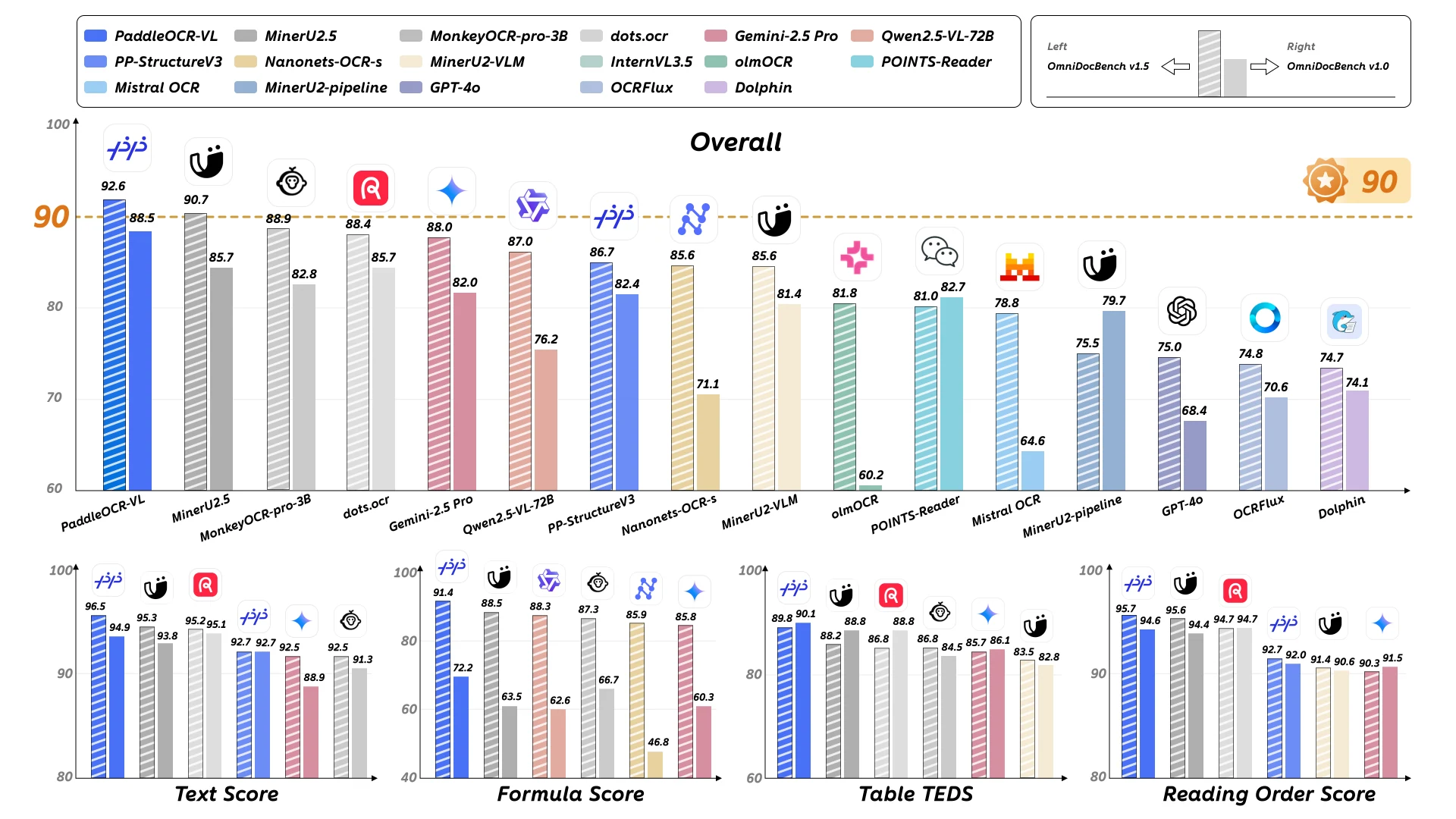
PaddleOCR-VL 在多項評估維度中都展現了卓越的效能,確立了其作為文件解析與元素辨識領域最先進解決方案的地位。
頁面級文件解析
OmniDocBench v1.5:PaddleOCR-VL 在 OmniDocBench v1.5 的整體、文字、公式、表格與閱讀順序等指標上都達到了 SOTA(最先進)效能。 該模型在所有評估類別中都持續優於競爭對手的解決方案,展現了其全面的文件理解能力。
OmniDocBench v1.0:PaddleOCR-VL 在 OmniDocBench v1.0 的整體、文字、公式、表格與閱讀順序等幾乎所有指標上都達到了 SOTA(最先進)效能。 這些結果驗證了該模型在多元文件類型與不同複雜度下的強勁能力。
備註: 各項指標數據來自 MinerU、OmniDocBench 以及內部評估。
元素級辨識
文字辨識:PaddleOCR-VL 處理多元文件類型的強勁且通用能力,使其成為 OmniDocBench-OCR-block 效能評估中的領先方法。 內部 OCR 評估針對多種語言與文字類型進行效能測試,PaddleOCR-VL 在所有評估的書寫系統中都展現了優異的準確率,編輯距離最低。
表格辨識:自建評估集包含多元類型的表格圖片,例如中文、英文、中英混合表格,有完整邊框、部分邊框或無邊框的表格,書籍/手冊格式、清單、學術論文、合併儲存格的表格,以及低品質、帶浮水印的表格。 PaddleOCR-VL 在所有類別中都展現了卓越的效能。
公式辨識:評估集包含簡單印刷、複雜印刷、相機掃描與手寫公式。 PaddleOCR-VL 在每個類別中都展現了最佳效能。
圖表辨識:評估集大體分為 11 種圖表類別,包含長條-折線混合圖、圓餅圖、100% 堆疊長條圖、區域圖、長條圖、泡泡圖、直方圖、折線圖、散點圖、堆疊區域圖與堆疊長條圖。 PaddleOCR-VL 不僅效能優於專業 OCR 視覺語言模型,甚至超越了部分 72B 級的多模態語言模型。
使用場景與應用
文件數位化
透過 PaddleOCR-VL 支援 109 種語言的強大文字辨識能力,可將紙本文件轉換為可搜尋的數位格式。高效處理發票、收據、合約與商業文件,即使面對低品質掃描檔或帶浮水印的內容,也能維持高準確率。
學術研究
從研究論文與科學出版物中提取數學公式、表格與文字。PaddleOCR-VL 優異的公式辨識能力可處理簡單與複雜的數學表達式,非常適合學術內容的文獻回顧與數據提取。
金融文件處理
自動從財務報表、資產負債表與報告中提取數據。模型先進的表格辨識能力可精準解析金融文件中常見的合併儲存格、多語言、多種格式風格的複雜表格。
歷史檔案數位化
透過 PaddleOCR-VL 處理高難度內容的強勁能力,保存歷史文件與手稿,包含手寫文字、舊字體、褪色墨水與老舊紙張。即使面對不同書寫系統與語言的歷史文件,模型也能維持高準確率。
圖表與數據分析
從 11 種圖表類型的視覺數據呈現中提取洞察,包含長條圖、圓餅圖、折線圖與複雜的混合視覺化圖表。非常適合商業智慧應用與自動化報告系統。
開始在 Novita AI 平台使用 PaddleOCR
透過 Novita AI 使用 PaddleOCR-VL 提供多種路徑,可根據不同的技術專業程度與使用場景選擇。無論您是探索 AI 能力的企業用戶,還是建構生產應用的開發者,Novita AI 都能提供您需要的工具。
使用 playground(現已上線 – 無需編碼)
- 立即存取:註冊後即可在幾秒內開始試用 PaddleOCR-VL
- 互動介面:即時測試文件解析並可視化輸出結果
- 模型比較:可根據您的特定使用場景,將 PaddleOCR-VL 與其他領先模型進行比較
playground 讓您無需任何技術設定,即可測試各類文件並立即看到結果。非常適合在完整實作前進行原型開發、想法測試與了解模型能力。
透過 API 整合(已上線就緒 – 適用於開發者)
透過 Novita AI 的统一 REST API 將 PaddleOCR-VL 連接至您的應用程式。
選項 1:直接 API 整合(Python 範例)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="",
)
model = "paddlepaddle/paddleocr-vl"
stream = True # or False
max_tokens = 8192
system_content = "Be a helpful assistant"
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
選項 2:使用 OpenAI Agents SDK 建構多代理工作流
打造運用 PaddleOCR-VL 先進文件解析能力的複雜多代理系統:
- 即插即用整合:可在任何 OpenAI Agents 工作流中使用 PaddleOCR-VL
- 進階代理能力:支援交接、路由,以及與文件理解功能的工具整合
- 可擴展架構:可設計能運用 PaddleOCR-VL 多語言 OCR 與元素辨識能力的代理
選項 3:連接第三方平台
開發工具:透過 OpenAI 相容 API 與 Anthropic 相容 API,與 Cursor、Trae、Cline 等熱門 IDE 與開發環境無縫整合。
協調框架:使用官方連接器與 LangChain、Dify、CrewAI、Langflow 及其他 AI 協調平台連接。
Hugging Face 整合:Novita AI 是 Hugging Face 的官方推論提供者,確保廣泛的生態系統相容性。
結論
Novita AI 上的 PaddleOCR 搭載超輕量 0.9B 視覺語言模型,結合卓越準確率與出色效率,提供最先進的多語言文件解析能力。憑藉 109 種語言支援、OmniDocBench 基準測試的 SOTA(最先進)效能,以及在文字、表格、公式、圖表等複雜文件元素辨識方面的優異表現,PaddleOCR-VL 是現代文件處理應用的首選方案。
模型的輕量架構、快速推論速度與資源效率使其非常適合在真實場景中實際部署。無論您是在處理多語言文件、從複雜表格提取數據、辨識數學公式,還是分析圖表,Novita AI 上的 PaddleOCR-VL 都能提供您需要的效能與可靠性。
立即開始探索 Novita AI 上 PaddleOCR-VL 革命性的文件解析能力,透過我們對開發者友善的平台與無縫整合選項,體驗智慧文件處理的未來。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來部署 AI 模型,同時也提供平價且可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。



