

Heute geben wir mit Freude die Partnerschaft zwischen Novita AI und Z.ai bekannt, die eine Unterstützung für GLM-4.5 ab dem ersten Tag auf der Novita AI-Plattform als Startpartner von Z.ai ermöglicht. Diese bahnbrechende Zusammenarbeit führt die weltweit einheitlichste KI-Modellreihe ein, die fortschrittliches Reasoning, hochentwickelte Coding-Fähigkeiten und native agentische Funktionalität in einem einzigen, leistungsstarken Framework vereint – entwickelt für Entwickler, die die nächste Generation von KI-Anwendungen bauen.
Novita AI bietet nun das wegweisende GLM-4.5-Modell (355B Gesamtparameter, 32B aktiv) an: Ausgestattet mit hybriden Reasoning-Modi, die sowohl einen Denkmodus für komplexes Reasoning und Tool-Nutzung als auch einen Nicht-Denkmodus für sofortige Antworten bieten. Belegt insgesamt den 2. Platz über umfassende Benchmarks hinweg.
Beide Modelle bieten eine Kontextlänge von 128k und native Funktionsaufrufkapazität, verfügbar über die optimierte Inferenzinfrastruktur von Novita AI.
⚡ Gesamtleistung
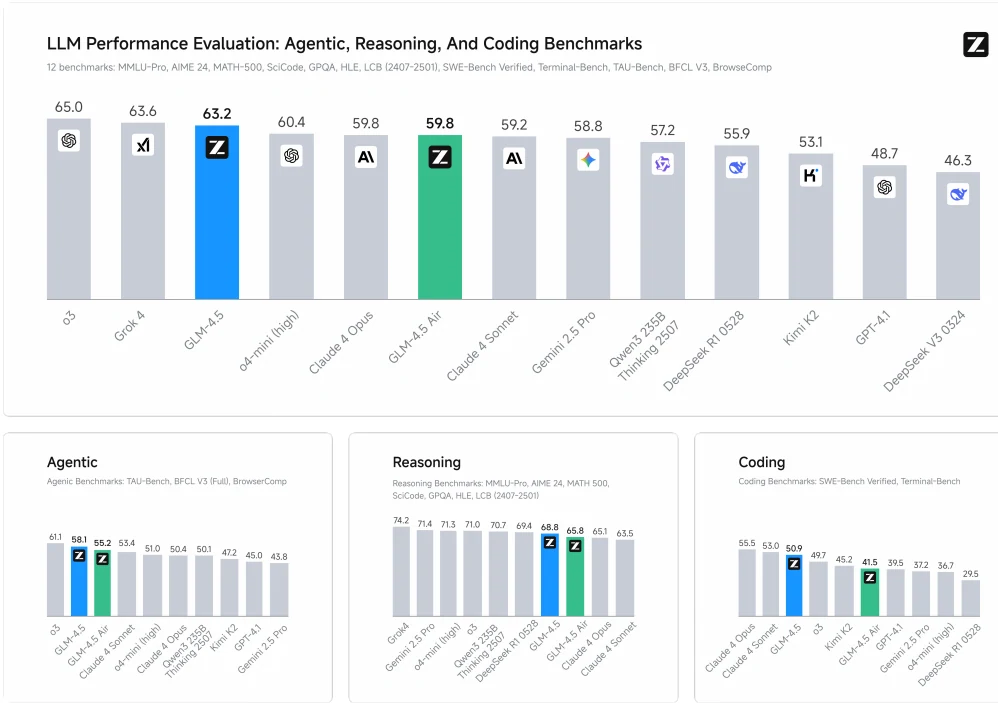
GLM-4.5 belegt den 2. Platz und GLM-4.5-Air den 5. Platz in 12 Benchmarks, die agentische (3), Reasoning- (7) und Coding-Aufgaben (2) abdecken – im Vergleich mit Modellen von OpenAI, Anthropic, Google DeepMind, xAI, Alibaba, Moonshot und DeepSeek.
GLM-4.5 vereint alle Fähigkeiten, bei denen frühere Modelle in bestimmten Bereichen herausragten – Coding, Mathematik oder Reasoning – ohne jedoch in allen Aufgaben Bestleistungen zu erzielen.
Agentische Aufgaben
GLM-4.5 ist ein Foundation-Modell, das für agentische Aufgaben optimiert ist. Es bietet eine Kontextlänge von 128k und native Funktionsaufrufkapazität. Z.ai hat seine Agentenfähigkeiten anhand des τ-bench und BFCL-v3 (Berkeley Function Calling Leaderboard v3) gemessen. In beiden Benchmarks erreicht GLM-4.5 die Leistung von Claude-4-Sonnet.
Web-Browsing ist eine beliebte agentische Anwendung, die komplexes Reasoning und mehrfache Tool-Nutzung erfordert. Z.ai hat GLM-4.5 mit dem Benchmark BrowseComp evaluiert – einem anspruchsvollen Benchmark für Web-Browsing, der aus komplizierten Fragen besteht, die kurze Antworten erwarten. Mit Zugriff auf das Web-Browsing-Tool gibt GLM-4.5 bei 26,4 % aller Fragen korrekte Antworten und übertrifft damit Claude-4-Opus (18,8 %) und liegt nahe an o4-mini-high (28,0 %).
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Qwen3 235B Thinking 2507 | DeepSeek R1 0528 | Kimi K2 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TAU-bench | 70.1 | 69.4 | 61.2 | 57.4 | 62.0 | 70.5 | 70.3 | 62.5 | 73.2 | 58.7 | 62.6 | 67.5 |
| BFCL v3 (Full) | 77.8 | 76.4 | 72.4 | 67.2 | 68.9 | 61.8 | 75.2 | 61.2 | 72.4 | 63.8 | 71.1 | 66.2 |
| BrowseComp | 26.4 | 21.3 | 49.7 | 28.3 | 4.1 | 18.8 | 14.7 | 7.6 | 4.6 | 3.2 | 7.9 | 32.6 |
Reasoning
Im Denkmodus können GLM-4.5 und GLM-4.5-Air komplexe Reasoning-Probleme lösen, darunter mathematische, wissenschaftliche und logische Probleme.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | DeepSeek R1 0528 | Qwen3-235B Thinking 2507 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MMLU Pro | 84.6 | 81.4 | 85.3 | 83.2 | 87.3 | 84.2 | 86.2 | 83.2 | 84.9 | 84.5 | 86.6 |
| AIME24 | 91.0 | 89.4 | 90.3 | 94.0 | 75.7 | 77.3 | 88.7 | 82.3 | 89.3 | 94.1 | 94.3 |
| MATH 500 | 98.2 | 98.1 | 99.2 | 98.9 | 98.2 | 99.1 | 96.7 | 98.1 | 98.3 | 98.0 | 99.0 |
| SciCode | 41.7 | 37.3 | 41.0 | 46.5 | 39.8 | 40.0 | 42.8 | 39.4 | 40.3 | 42.9 | 45.7 |
| GPQA | 79.1 | 75.0 | 82.7 | 78.4 | 79.6 | 77.7 | 84.4 | 79.0 | 81.3 | 81.1 | 87.7 |
| HLE | 14.4 | 10.6 | 20.0 | 17.5 | 11.7 | 8.5 | 21.1 | 11.1 | 14.9 | 15.8 | 23.9 |
| LiveCodeBench (2407-2501) | 72.9 | 70.7 | 78.4 | 80.4 | 63.6 | 58.0 | 80.1 | 69.5 | 77.0 | 78.2 | 81.9 |
| AA-Index (Estimated) | 67.7 | 64.8 | 70.0 | 69.8 | 64.4 | 62.7 | 70.5 | 65.1 | 68.3 | 69.4 | 73.2 |
Coding
GLM-4.5 zeichnet sich auch beim Coding aus – sowohl beim Aufbau eines Coding-Projekts von Grund auf als auch beim agentischen Lösen von Coding-Aufgaben in bestehenden Projekten. Es kann nahtlos mit vorhandenen Coding-Toolkits wie Claude Code, Roo Code und CodeGeex kombiniert werden. Um die Coding-Fähigkeit zu bewerten, hat Z.ai verschiedene Modelle auf SWE-bench Verified und Terminal Bench verglichen.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | Qwen3 235B Thinking 2507 | Qwen3 235B | DeepSeek R1 0528 | Kimi K2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 64.2 | 57.6 | 69.1 | 54.8 | 48.6 | 67.8 | 70.4 | 49.0 | 60.4 | 35.0 | 36.2 | 41.4 | 65.4 |
| Terminal-Bench | 37.5 | 30.0 | 30.2 | 18.5 | 30.3 | 43.2 | 35.5 | 25.3 | 16.8 | 6.3 | 6.6 | 17.5 | 25.0 |
Um die agentischen Coding-Fähigkeiten von GLM-4.5 in realen Szenarien zu bewerten, hat Z.ai mit Claude Code umfassende Tests gegen Claude-4-Sonnet, Kimi K2 und Qwen3-Coder durchgeführt, wobei 52 Coding-Aufgaben aus den Bereichen Frontend-Entwicklung, Tool-Entwicklung, Datenanalyse, Testen und Algorithmenanwendungen abgedeckt wurden. GLM-4.5 schlägt Kimi K2 in 53,9 % der Aufgaben und dominiert Qwen3-Coder mit einer Gewinnquote von 80,8 %, während es gegenüber Claude-4-Sonnet noch Verbesserungspotenzial zeigt.
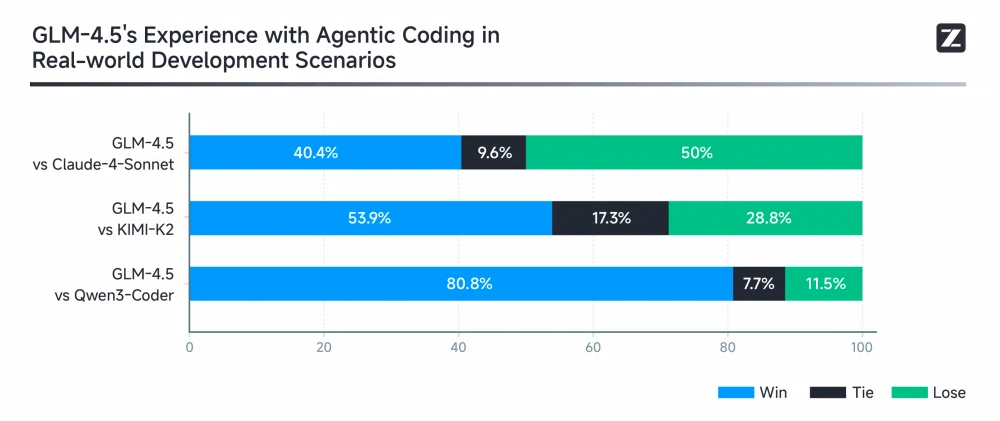
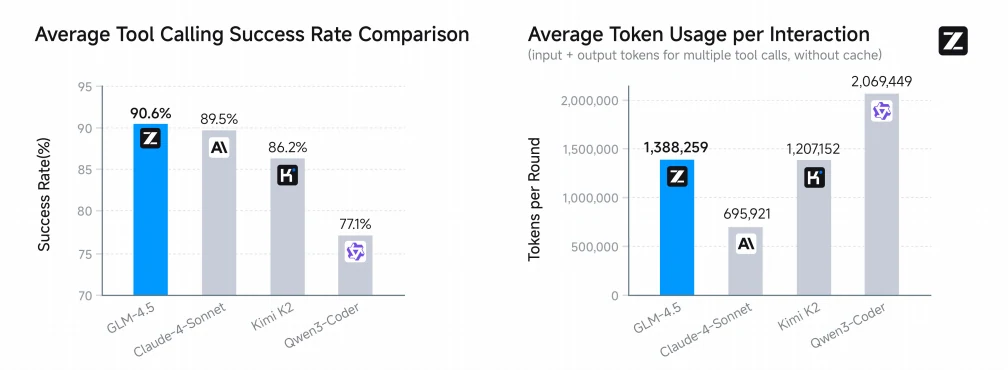
Bemerkenswert ist, dass GLM-4.5 mit 90,6 % die höchste durchschnittliche Tool-Call-Erfolgsquote erzielt und damit Claude-4-Sonnet (89,5 %), Kimi-K2 (86,2 %) und Qwen3-Coder (77,1 %) übertrifft – ein Beleg für überlegene Zuverlässigkeit und Effizienz bei agentischen Coding-Aufgaben.
🚀 Erste Schritte mit Novita AI
Nutzen Sie die Playground-Umgebung (kein Coding erforderlich)
- Sofortiger Zugriff: Melden Sie sich an und beginnen Sie sofort mit GLM-4.5 zu experimentieren
- Interaktive Oberfläche: Testen Sie komplexe Reasoning-Prompts und visualisieren Sie strukturierte Ausgaben in Echtzeit
- Modellvergleich: Vergleichen Sie GLM-4.5 mit anderen führenden Modellen für Ihren spezifischen Anwendungsfall
Integration über API (für Entwickler)
Verbinden Sie GLM-4.5 mit Ihren Anwendungen über die einheitliche REST-API von Novita AI.
Option 1: Direkte API-Integration (Python-Beispiel)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_S4q9KTdBQujFkXSE5aZYZCrwN9f5QO96BtAFLw4FOgB__slLHW9KFAjmMgC12ag6mf2lJ1rASEvHbP_gv7Jh2Q==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Hauptmerkmale:
- OpenAI-kompatible API für nahtlose Integration
- Flexible Parametersteuerung zur Feinabstimmung der Antworten
- Streaming-Unterstützung für Echtzeit-Antworten
Option 2: Multi-Agent-Workflows mit dem OpenAI Agents SDK Erstellen Sie anspruchsvolle Multi-Agent-Systeme mit GLM-4.5:
- Plug-and-Play-Integration: Verwenden Sie GLM-4.5 in jedem OpenAI-Agents-Workflow
- Erweiterte Agentenfähigkeiten: Unterstützung für Übergaben, Routing und Tool-Integration mit einer Erfolgsquote von 90,6 %
- Skalierbare Architektur: Entwickeln Sie Agenten, die die vereinheitlichten Fähigkeiten von GLM-4.5 in Reasoning, Coding und agentischer Funktion nutzen
Verbindung mit Drittanbieter-Plattformen
- Entwicklungstools: Nahtlose Integration mit gängigen IDEs und Entwicklungsumgebungen wie Cursor und Cline über OpenAI-kompatible APIs
- Orchestrierungs-Frameworks: Verbinden Sie sich mit LangChain, Dify, Langflow und anderen KI-Orchestrierungsplattformen über offizielle Konnektoren
- Hugging Face-Integration: Nutzen Sie GLM-4.5 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI-Endpunkte
🔬 Technische Innovation von GLM-4.5
MoE-Architektur-Exzellenz
GLM-4.5 übernimmt die Mixture-of-Experts (MoE)-Architektur, die die Recheneffizienz sowohl beim Training als auch bei der Inferenz verbessert. Im Vergleich zu DeepSeek-V3 reduziert das Design die Breite (Hidden-Dimension und geroutete Experten) und erhöht gleichzeitig die Höhe (Anzahl der Schichten).
Wichtigste technische Merkmale:
- Grouped-Query Attention mit partiellem RoPE (fortgeführt von ChatGLM2)
- QK-Norm zur Stabilisierung des Aufmerksamkeitslogit-Bereichs
- Muon-Optimierer für beschleunigte Konvergenz und größere Batch-Größen-Toleranz
- MTP (Multi-Token Prediction)-Schicht zur Unterstützung von spekulativem Decoding während der Inferenz
Fortschrittliche Training-Pipeline
Pre-Training: Zweistufiger Ansatz
- 15B Token auf generellem Pre-Training-Korpus
- 7B Token auf Code- und Reasoning-Korpus
Mid-Training: Domänenspezifische Optimierung
- Repo-Level Code-Daten (500B Token)
- Synthetische Reasoning-Daten (500B Token)
- Langkontext- und Agent-Daten (100B Token)
Post-Training: Anspruchsvoller hybrider Ansatz
- Expert-Training: Separate Modelle für Reasoning-, Agenten- und allgemeine Bereiche durch SFT und spezialisiertes RL
- Einheitliches Training: Wissensdestillation, die Experten durch groß angelegte SFT-Selbstdestillation in einem einzigen Modell vereint, gefolgt von dreistufiger RL-Ausrichtung
slime: Revolutionäre RL-Infrastruktur
Das Training von GLM-4.5 wird durch slime unterstützt, eine Open-Source-RL-Infrastruktur für große Modelle:
- Flexible hybride Trainingsarchitektur: Unterstützt sowohl synchrones Co-Located-Training als auch disaggregiertes asynchrones Training
- Entkoppeltes agentenorientiertes Design: Trennt Rollout-Engines von Training-Engines für optimierte Leistung
- Beschleunigte Datengenerierung: Mixed-Precision-Inferenz mit FP8 zur Datengenerierung bei gleichzeitiger Beibehaltung der BF16-Stabilität für das Training
🎯 Bereit für einheitliche KI?
Testen Sie GLM-4.5 und GLM-4.5-Air noch heute auf der Novita AI-Plattform. Erleben Sie aus erster Hand, wie einheitliche KI-Fähigkeiten das Mögliche verändern, wenn Reasoning, Coding und agentische Funktionalität in einer optimierten, produktionsreifen Infrastruktur zusammenkommen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere simple API bereitzustellen und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



