

今天,我们激动地宣布 Novita AI 与 Z.ai 达成合作,作为 Z.ai 的首发合作伙伴,在 Novita AI 平台上率先支持 GLM-4.5。这一突破性的合作将世界上最统一的 AI 模型系列引入平台,将高级推理、复杂的代码编写能力和原生智能体功能整合到一个强大的框架中,专为构建下一代 AI 应用的开发者设计。
Novita AI 现已提供突破性的 GLM-4.5 模型(总参数 355B,激活参数 32B):它采用混合推理模式,提供用于复杂推理和工具使用的思考模式,以及用于即时响应的非思考模式。在综合基准测试中总体排名第二。
两个模型均支持 128K 上下文长度和原生函数调用能力,通过 Novita AI 优化的推理基础设施提供。
⚡ 整体性能
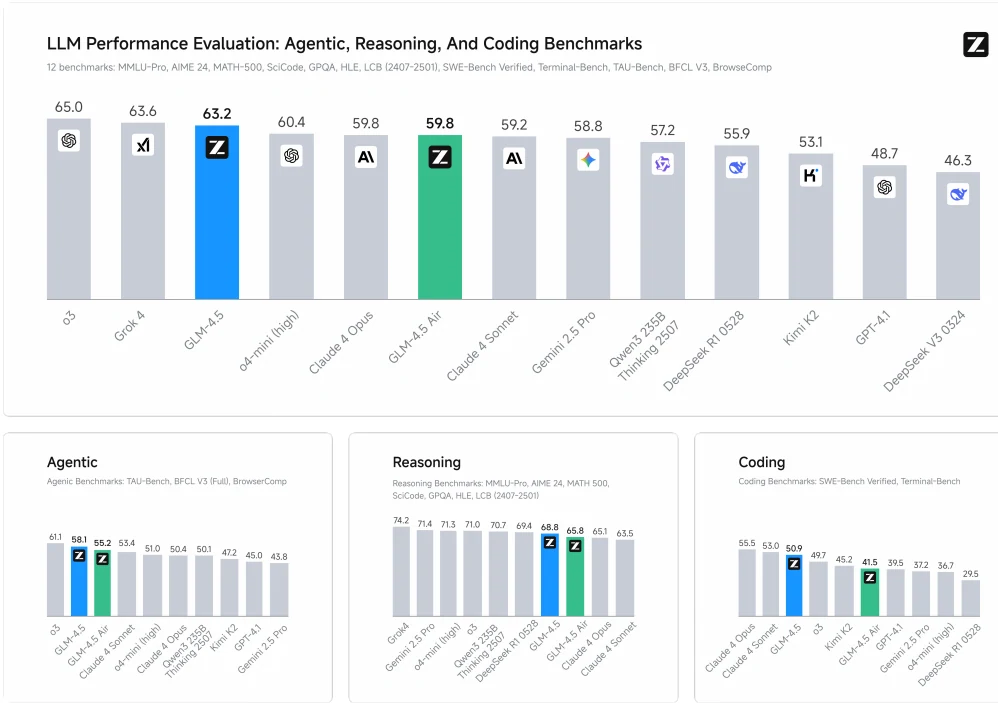
GLM-4.5 排名第二,GLM-4.5-Air 排名第五,涵盖了智能体(3 项)、推理(7 项)和代码(2 项)共 12 项基准测试,与来自 OpenAI、Anthropic、Google DeepMind、xAI、阿里巴巴、月之暗面和 DeepSeek 的模型进行对比。
GLM-4.5 统一了所有能力——以往模型在代码、数学或推理等特定领域表现出色,但没有一个能在所有任务上达到最佳性能。
智能体任务
GLM-4.5 是一个针对智能体任务优化的基础模型。它提供 128K 上下文长度和原生函数调用能力。Z.ai 在 τ-bench 和 BFCL-v3(Berkeley 函数调用排行榜 v3)上衡量了其智能体能力。在这两个基准测试中,GLM-4.5 的性能与 Claude-4-Sonnet 相当。
网页浏览是一种流行的智能体应用,需要复杂的推理和多轮工具使用。Z.ai 在 BrowseComp 基准测试上评估了 GLM-4.5,这是一个具有挑战性的网页浏览基准测试,包含复杂问题并期望简短答案。在使用网页浏览工具的情况下,GLM-4.5 对 26.4% 的问题给出了正确答案,明显优于 Claude-4-Opus(18.8%),接近 o4-mini-high(28.0%)。
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Qwen3 235B Thinking 2507 | DeepSeek R1 0528 | Kimi K2 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TAU-bench | 70.1 | 69.4 | 61.2 | 57.4 | 62.0 | 70.5 | 70.3 | 62.5 | 73.2 | 58.7 | 62.6 | 67.5 |
| BFCL v3 (Full) | 77.8 | 76.4 | 72.4 | 67.2 | 68.9 | 61.8 | 75.2 | 61.2 | 72.4 | 63.8 | 71.1 | 66.2 |
| BrowseComp | 26.4 | 21.3 | 49.7 | 28.3 | 4.1 | 18.8 | 14.7 | 7.6 | 4.6 | 3.2 | 7.9 | 32.6 |
推理
在思考模式下,GLM-4.5 和 GLM-4.5-Air 可以解决复杂的推理问题,包括数学、科学和逻辑问题。
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | DeepSeek R1 0528 | Qwen3-235B Thinking 2507 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MMLU Pro | 84.6 | 81.4 | 85.3 | 83.2 | 87.3 | 84.2 | 86.2 | 83.2 | 84.9 | 84.5 | 86.6 |
| AIME24 | 91.0 | 89.4 | 90.3 | 94.0 | 75.7 | 77.3 | 88.7 | 82.3 | 89.3 | 94.1 | 94.3 |
| MATH 500 | 98.2 | 98.1 | 99.2 | 98.9 | 98.2 | 99.1 | 96.7 | 98.1 | 98.3 | 98.0 | 99.0 |
| SciCode | 41.7 | 37.3 | 41.0 | 46.5 | 39.8 | 40.0 | 42.8 | 39.4 | 40.3 | 42.9 | 45.7 |
| GPQA | 79.1 | 75.0 | 82.7 | 78.4 | 79.6 | 77.7 | 84.4 | 79.0 | 81.3 | 81.1 | 87.7 |
| HLE | 14.4 | 10.6 | 20.0 | 17.5 | 11.7 | 8.5 | 21.1 | 11.1 | 14.9 | 15.8 | 23.9 |
| LiveCodeBench (2407-2501) | 72.9 | 70.7 | 78.4 | 80.4 | 63.6 | 58.0 | 80.1 | 69.5 | 77.0 | 78.2 | 81.9 |
| AA-Index (Estimated) | 67.7 | 64.8 | 70.0 | 69.8 | 64.4 | 62.7 | 70.5 | 65.1 | 68.3 | 69.4 | 73.2 |
代码编写
GLM-4.5 同样擅长代码编写,包括从头构建代码项目,以及在现有项目中以智能体方式解决代码任务。它可以与现有的代码工具包(如 Claude Code、Roo Code 和 CodeGeex)无缝结合。为了评估代码编写能力,Z.ai 在 SWE-bench Verified 和 Terminal Bench 上对不同模型进行了比较。
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | Qwen3 235B Thinking 2507 | Qwen3 235B | DeepSeek R1 0528 | Kimi K2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 64.2 | 57.6 | 69.1 | 54.8 | 48.6 | 67.8 | 70.4 | 49.0 | 60.4 | 35.0 | 36.2 | 41.4 | 65.4 |
| Terminal-Bench | 37.5 | 30.0 | 30.2 | 18.5 | 30.3 | 43.2 | 35.5 | 25.3 | 16.8 | 6.3 | 6.6 | 17.5 | 25.0 |
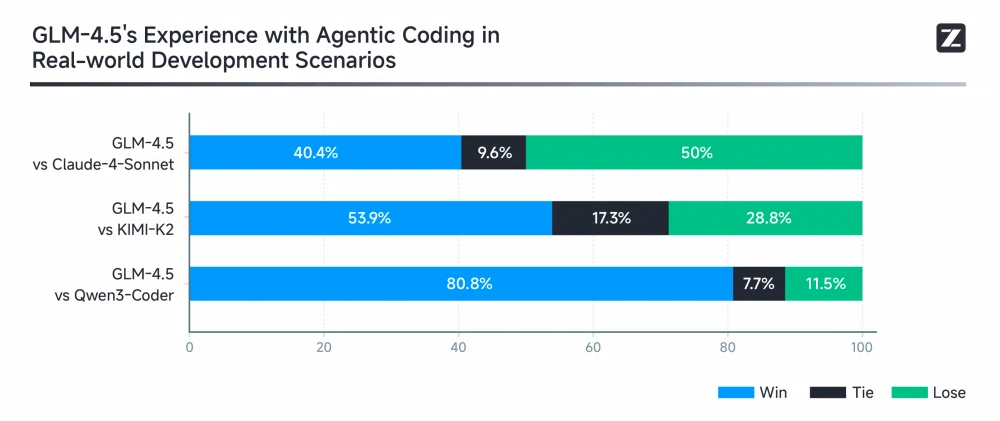
为了评估 GLM-4.5 在真实场景中的智能体代码编写能力,Z.ai 使用 Claude Code 对 GLM-4.5、Claude-4-Sonnet、Kimi K2 和 Qwen3-Coder 进行了全面的测试,涉及 52 个代码任务,涵盖前端开发、工具开发、数据分析、测试和算法应用。GLM-4.5 在 53.9% 的任务中击败了 Kimi K2,并以 80.8% 的胜率压倒 Qwen3-Coder,同时在与 Claude-4-Sonnet 的对比中仍有提升空间。
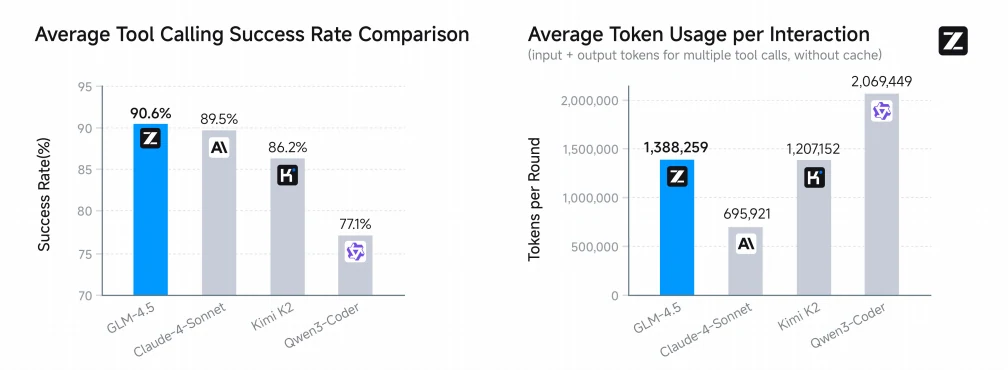
值得注意的是,GLM-4.5 的平均工具调用成功率达到最高的 90.6%,超过了 Claude-4-Sonnet(89.5%)、Kimi-K2(86.2%)和 Qwen3-Coder(77.1%),在智能体代码编写任务中表现出卓越的可靠性和效率。
🚀 开始使用 Novita AI
使用 Playground(无需编码)
- 即时访问:注册后即可在几秒钟内开始体验 GLM-4.5
- 交互式界面:实时测试复杂推理提示,可视化结构化输出
- 模型对比:针对您的特定用例,将 GLM-4.5 与其他领先模型进行比较
通过 API 集成(面向开发者)
通过 Novita AI 的统一 REST API 将 GLM-4.5 连接到您的应用。
选项 1:直接 API 集成(Python 示例)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_S4q9KTdBQujFkXSE5aZYZCrwN9f5QO96BtAFLw4FOgB__slLHW9KFAjmMgC12ag6mf2lJ1rASEvHbP_gv7Jh2Q==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主要特点:
- 兼容 OpenAI 的 API,实现无缝集成
- 灵活的参数控制,精细调整响应
- 支持流式传输,实现实时响应
选项 2:使用 OpenAI Agents SDK 的多智能体工作流 利用 GLM-4.5 构建复杂的多智能体系统:
- 即插即用集成:在任何 OpenAI Agents 工作流中使用 GLM-4.5
- 高级智能体能力:支持交接、路由和工具集成,成功率高达 90.6%
- 可扩展架构:设计利用 GLM-4.5 统一推理、代码编写和智能体能力的智能体
连接第三方平台
- 开发工具:通过兼容 OpenAI 的 API,与 Cursor、Cline 等流行的 IDE 和开发环境无缝集成
- 编排框架:使用官方连接器连接 LangChain、Dify、Langflow 等 AI 编排平台
- Hugging Face 集成:通过 Novita AI 端点,在 Spaces、流水线或 Transformers 库中使用 GLM-4.5
🔬 GLM-4.5 的技术创新
MoE 架构优势
GLM-4.5 采用混合专家(MoE)架构,提高了训练和推理的计算效率。与 DeepSeek-V3 相比,其设计减少了宽度(隐藏维度和路由专家),同时增加了高度(层数)。
关键技术特点:
- 分组查询注意力,带有部分 RoPE(延续自 ChatGLM2)
- QK-Norm,用于稳定注意力 logits 范围
- Muon 优化器,加速收敛并容忍更大的批量大小
- MTP(多令牌预测)层,在推理期间支持推测解码
先进的训练流水线
预训练:两阶段方法
- 通用预训练语料库 15T 令牌
- 代码与推理语料库 7T 令牌
中期训练:领域特定优化
- 仓库级代码数据(500B 令牌)
- 合成推理数据(500B 令牌)
- 长上下文与智能体数据(100B 令牌)
后训练:复杂的混合方法
- 专家训练:通过 SFT 和专门的 RL 分别为推理、智能体和通用领域训练模型
- 统一训练:通过大规模 SFT 自蒸馏将专家知识整合到单个模型中,随后进行三阶段 RL 对齐
slime:革命性的 RL 基础设施
GLM-4.5 的训练由 slime 驱动,这是一个为大规模模型设计的开源 RL 基础设施:
- 灵活的混合训练架构:支持同步共地训练和分解异步训练
- 解耦的智能体导向设计:将推出引擎与训练引擎分离,以优化性能
- 加速数据生成:使用 FP8 混合精度推理进行数据生成,同时保持 BF16 稳定性进行训练
🎯 准备好体验统一的 AI 了吗?
立即在 Novita AI 平台 上体验 GLM-4.5 和 GLM-4.5-Air。亲身感受当推理、代码编写和智能体功能在优化的生产就绪基础设施中融合时,统一 AI 能力如何改变一切可能。
立即开始构建 →
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济且可靠的 GPU 云,用于构建和扩展应用。



