

اليوم، يسعدنا الإعلان عن شراكة Novita AI مع Z.ai لتقديم دعم فوري لنموذج GLM-4.5 على منصة Novita AI كشريك إطلاق لـ Z.ai. هذا التعاون الرائد يقدم سلسلة النماذج الذكية الأكثر توحيدًا في العالم، حيث تجمع بين التفكير المتقدم، وقدرات البرمجة المتطورة، والوظائف الوكيلة الأصلية في إطار واحد قوي، مصمم للمطورين الذين يبنون الجيل التالي من تطبيقات الذكاء الاصطناعي.
تقدم Novita AI الآن النموذج الرائد GLM-4.5 (إجمالي 355B معلمة، 32B نشطة): مبني بأوضاع تفكير هجينة تقدم وضع التفكير للاستدلال المعقد واستخدام الأدوات، ووضع عدم التفكير للاستجابات الفورية. يحتل المرتبة الثانية بشكل عام عبر المعايير الشاملة.
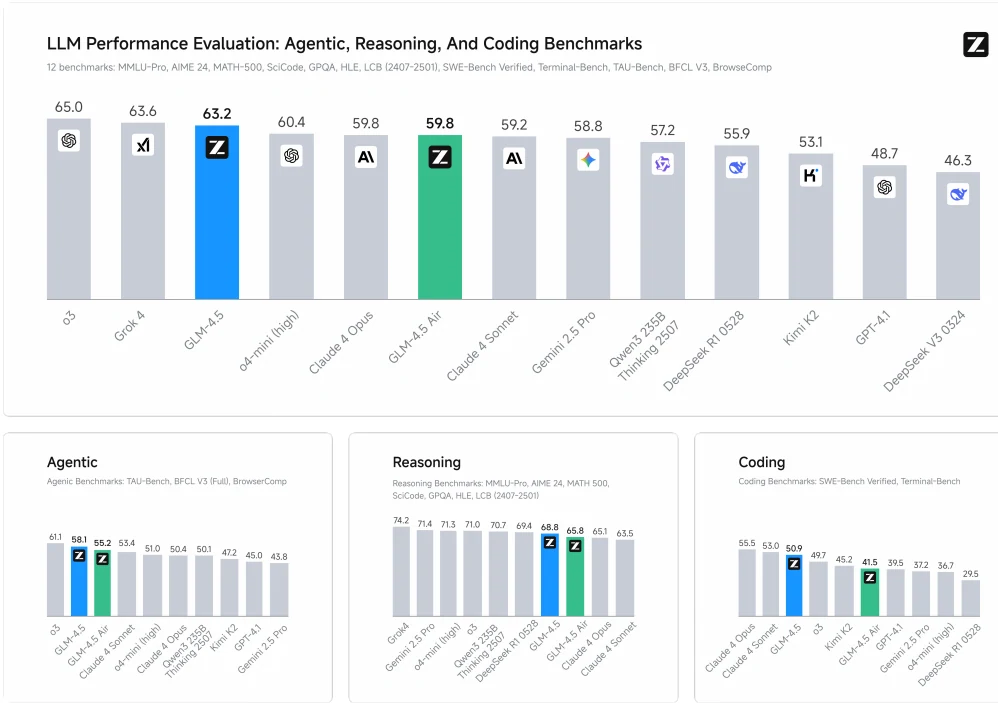
كلا النموذجين يتميزان بطول سياق 128k وقدرة أصلية على استدعاء الدوال، متاحان عبر بنية الاستدلال المحسّنة من Novita AI.
⚡ الأداء العام
يحتل GLM-4.5 المرتبة الثانية و GLM-4.5-Air المرتبة الخامسة عبر 12 معيارًا تغطي مهام الوكيل (3)، والتفكير (7)، والبرمجة (2)، مقارنة بنماذج من OpenAI و Anthropic و Google DeepMind و xAI و Alibaba و Moonshot و DeepSeek.
يوحّد GLM-4.5 جميع القدرات التي تفوقت فيها النماذج السابقة في مجالات محددة - البرمجة، أو الرياضيات، أو التفكير - لكن لم يحقق أي منها أفضل أداء عبر جميع المهام.
مهام الوكيل
GLM-4.5 هو نموذج أساسي محسّن لمهام الوكيل. يوفر طول سياق 128k وقدرة أصلية على استدعاء الدوال. قامت Z.ai بقياس قدرته الوكيلة على τ-bench و BFCL-v3 (مؤشر أداء استدعاء الدوال في بيركلي الإصدار 3). في كلا المعيارين، يتطابق أداء GLM-4.5 مع Claude-4-Sonnet.
تصفح الويب هو تطبيق وكيل شائع يتطلب تفكيرًا معقدًا واستخدامًا متعدد الخطوات للأدوات. قامت Z.ai بتقييم GLM-4.5 على معيار BrowseComp، وهو معيار صعب لتصفح الويب يتكون من أسئلة معقدة تتوقع إجابات قصيرة. مع الوصول إلى أداة تصفح الويب، يعطي GLM-4.5 إجابات صحيحة لـ 26.4% من جميع الأسئلة، متجاوزًا بشكل واضح Claude-4-Opus (18.8%) ومقتربًا من o4-mini-high (28.0%).
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Qwen3 235B Thinking 2507 | DeepSeek R1 0528 | Kimi K2 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TAU-bench | 70.1 | 69.4 | 61.2 | 57.4 | 62.0 | 70.5 | 70.3 | 62.5 | 73.2 | 58.7 | 62.6 | 67.5 |
| BFCL v3 (Full) | 77.8 | 76.4 | 72.4 | 67.2 | 68.9 | 61.8 | 75.2 | 61.2 | 72.4 | 63.8 | 71.1 | 66.2 |
| BrowseComp | 26.4 | 21.3 | 49.7 | 28.3 | 4.1 | 18.8 | 14.7 | 7.6 | 4.6 | 3.2 | 7.9 | 32.6 |
التفكير
تحت وضع التفكير، يمكن لـ GLM-4.5 و GLM-4.5-Air حل مشاكل التفكير المعقدة بما في ذلك الرياضيات والعلوم والمشاكل المنطقية.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | DeepSeek R1 0528 | Qwen3-235B Thinking 2507 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MMLU Pro | 84.6 | 81.4 | 85.3 | 83.2 | 87.3 | 84.2 | 86.2 | 83.2 | 84.9 | 84.5 | 86.6 |
| AIME24 | 91.0 | 89.4 | 90.3 | 94.0 | 75.7 | 77.3 | 88.7 | 82.3 | 89.3 | 94.1 | 94.3 |
| MATH 500 | 98.2 | 98.1 | 99.2 | 98.9 | 98.2 | 99.1 | 96.7 | 98.1 | 98.3 | 98.0 | 99.0 |
| SciCode | 41.7 | 37.3 | 41.0 | 46.5 | 39.8 | 40.0 | 42.8 | 39.4 | 40.3 | 42.9 | 45.7 |
| GPQA | 79.1 | 75.0 | 82.7 | 78.4 | 79.6 | 77.7 | 84.4 | 79.0 | 81.3 | 81.1 | 87.7 |
| HLE | 14.4 | 10.6 | 20.0 | 17.5 | 11.7 | 8.5 | 21.1 | 11.1 | 14.9 | 15.8 | 23.9 |
| LiveCodeBench (2407-2501) | 72.9 | 70.7 | 78.4 | 80.4 | 63.6 | 58.0 | 80.1 | 69.5 | 77.0 | 78.2 | 81.9 |
| AA-Index (Estimated) | 67.7 | 64.8 | 70.0 | 69.8 | 64.4 | 62.7 | 70.5 | 65.1 | 68.3 | 69.4 | 73.2 |
البرمجة
يتميز GLM-4.5 أيضًا في البرمجة، بما في ذلك بناء مشروع برمجي من الصفر، وحل مهام البرمجة وكيليًا في المشاريع القائمة. يمكن دمجه بسلاسة مع أدوات البرمجة الحالية مثل Claude Code و Roo Code و CodeGeex. لتقييم قدرة البرمجة، قارنت Z.ai نماذج مختلفة على SWE-bench Verified و Terminal Bench.
| Benchmark | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | Qwen3 235B Thinking 2507 | Qwen3 235B | DeepSeek R1 0528 | Kimi K2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 64.2 | 57.6 | 69.1 | 54.8 | 48.6 | 67.8 | 70.4 | 49.0 | 60.4 | 35.0 | 36.2 | 41.4 | 65.4 |
| Terminal-Bench | 37.5 | 30.0 | 30.2 | 18.5 | 30.3 | 43.2 | 35.5 | 25.3 | 16.8 | 6.3 | 6.6 | 17.5 | 25.0 |
لتقييم قدرات البرمجة الوكيلة لـ GLM-4.5 في سيناريوهات العالم الحقيقي، استخدمت Z.ai Claude Code لإجراء اختبار شامل ضد Claude-4-Sonnet و Kimi K2 و Qwen3-Coder باستخدام 52 مهمة برمجية تغطي تطوير الواجهة الأمامية، وتطوير الأدوات، وتحليل البيانات، والاختبار، وتطبيقات الخوارزميات. يفوز GLM-4.5 ضد Kimi K2 في 53.9% من المهام ويتفوق على Qwen3-Coder بنسبة فوز 80.8%، مع إظهار مجال للتحسين ضد Claude-4-Sonnet.
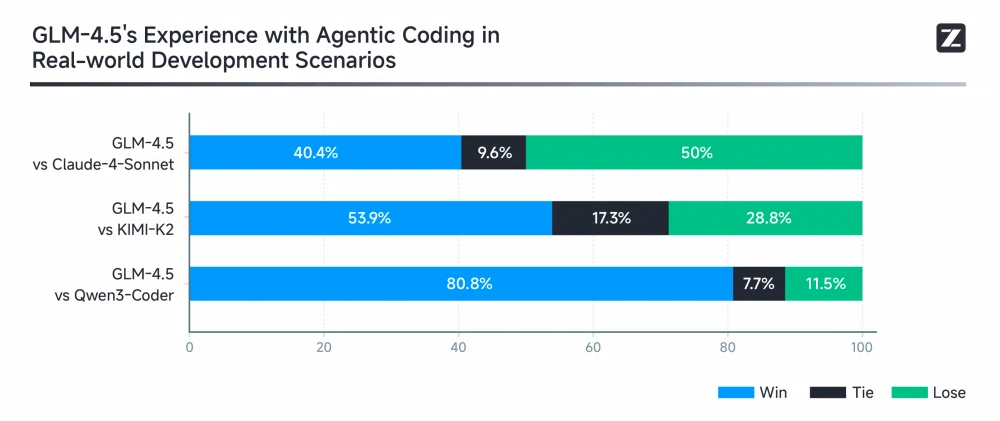
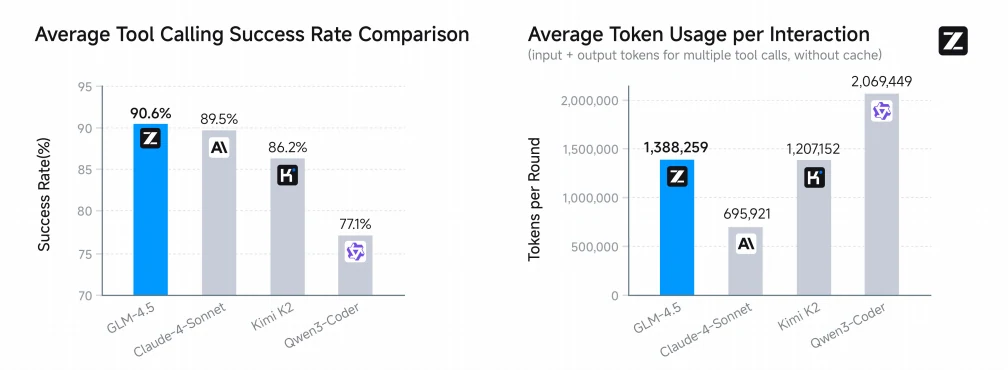
بشكل ملحوظ، يحقق GLM-4.5 أعلى معدل نجاح في استدعاء الأدوات بمتوسط 90.6%، متجاوزًا Claude-4-Sonnet (89.5%) و Kimi-K2 (86.2%) و Qwen3-Coder (77.1%)، مما يدل على موثوقية وكفاءة فائقة في مهام البرمجة الوكيلة.
🚀 ابدأ مع Novita AI
استخدم بيئة الاختبار (بدون برمجة)
- وصول فوري: سجل وابدأ بتجربة GLM-4.5 في ثوانٍ
- واجهة تفاعلية: اختبر استفسارات التفكير المعقدة وتصور المخرجات المنظمة في الوقت الفعلي
- مقارنة النماذج: قارن GLM-4.5 مع نماذج رائدة أخرى لحالة الاستخدام الخاصة بك
التكامل عبر API (للمطورين)
اربط GLM-4.5 بتطبيقاتك باستخدام REST API الموحد من Novita AI.
الخيار 1: التكامل المباشر مع API (مثال بلغة Python)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_S4q9KTdBQujFkXSE5aZYZCrwN9f5QO96BtAFLw4FOgB__slLHW9KFAjmMgC12ag6mf2lJ1rASEvHbP_gv7Jh2Q==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
الميزات الرئيسية:
- API متوافق مع OpenAI لتكامل سلس
- تحكم مرن في المعاملات لضبط الاستجابات بدقة
- دعم البث للاستجابات في الوقت الفعلي
الخيار 2: سير العمل متعدد الوكلاء باستخدام OpenAI Agents SDK بناء أنظمة متعددة الوكلاء متطورة باستخدام GLM-4.5:
- تكامل فوري: استخدم GLM-4.5 في أي سير عمل لـ OpenAI Agents
- قدرات وكيلة متقدمة: دعم للتسليم والتوجيه وتكامل الأدوات بنسبة نجاح 90.6%
- بنية قابلة للتوسع: تصميم وكلاء يستفيدون من قدرات GLM-4.5 الموحدة في التفكير والبرمجة والوكالة
الاتصال بمنصات الطرف الثالث
- أدوات التطوير: تكامل سلس مع بيئات التطوير الشهيرة مثل Cursor و Cline عبر APIs المتوافقة مع OpenAI
- أطر التنسيق: الاتصال مع LangChain و Dify و Langflow ومنصات تنسيق الذكاء الاصطناعي الأخرى باستخدام الموصلات الرسمية
- التكامل مع Hugging Face: استخدم GLM-4.5 في Spaces أو pipelines أو مع مكتبة Transformers عبر نقاط نهاية Novita AI
🔬 الابتكار التقني لـ GLM-4.5
تميز بنية MoE
يعتمد GLM-4.5 على بنية خليط الخبراء (MoE) التي تحسن كفاءة الحوسبة لكل من التدريب والاستدلال. مقارنة بـ DeepSeek-V3، يقلل التصميم من العرض (البعد المخفي والخبراء الموجهين) مع زيادة الارتفاع (عدد الطبقات).
الميزات التقنية الرئيسية:
- انتباه الاستعلام المجمع مع RoPE الجزئي (استمرار من ChatGLM2)
- QK-Norm لتثبيت نطاق نقاط الانتباه
- محسّن Muon لتسريع التقارب وتحمل حجم دفعة أكبر
- طبقة MTP (التنبؤ بعدة رموز) تدعم فك الترميز التخميني أثناء الاستدلال
خط أنابيب تدريب متقدم
ما قبل التدريب: نهج من مرحلتين
- 15 تريليون رمز على مجموعة تدريب عامة
- 7 تريليون رمز على مجموعة تدريب للبرمجة والتفكير
التدريب المتوسط: تحسين خاص بالمجال
- بيانات كود على مستوى المستودع (500 مليار رمز)
- بيانات تفكير اصطناعية (500 مليار رمز)
- بيانات سياق طويل ووكيل (100 مليار رمز)
ما بعد التدريب: نهج هجين متطور
- تدريب الخبراء: نماذج منفصلة لمجالات التفكير والوكالة والعامة عبر SFT و RL متخصص
- التدريب الموحد: تقطير المعرفة يجمع الخبراء في نموذج واحد عبر SFT ذاتي واسع النطاق، يليه محاذاة RL من ثلاث مراحل
slime: بنية RL ثورية
يتم تدريب GLM-4.5 بواسطة slime، وهي بنية RL مفتوحة المصدر مصممة للنماذج واسعة النطاق:
- بنية تدريب هجينة مرنة: تدعم التدريب المتزامن المشترك والتدريب غير المتزامن المنفصل
- تصميم وكيل مفصول: يفصل محركات النشر عن محركات التدريب لتحسين الأداء
- توليد بيانات متسارع: استدلال مختلط الدقة باستخدام FP8 لتوليد البيانات مع الحفاظ على استقرار BF16 للتدريب
🎯 هل أنت مستعد لتجربة الذكاء الاصطناعي الموحد؟
جرب GLM-4.5 و GLM-4.5-Air اليوم على منصة Novita AI. اختبر بنفسك كيف تحول قدرات الذكاء الاصطناعي الموحدة ما هو ممكن عندما تتقارب قدرات التفكير والبرمجة والوكالة في بنية تحتية محسّنة وجاهزة للإنتاج.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة تطبيقات بسيطة، مع توفير سحابة GPU ميسورة وموثوقة للبناء والتوسع.



