

今天,我們興奮地宣布 Novita AI 與 Z.ai 合作,以 Z.ai 啟動夥伴的身份,在 Novita AI 平台上首日支援 GLM-4.5。這項突破性的合作推出了全球最統一的 AI 模型系列,將先進推理、精密程式碼能力以及原生自主功能整合於一個強大的框架中,專為打造下一代 AI 應用程式的開發者設計。
Novita AI 現已提供革命性的 GLM-4.5 模型(總參數 355B,活躍參數 32B):採用混合推理模式,提供 思考模式 ** 以處理複雜推理和工具使用,以及 ** 非思考模式 以實現即時回應。在綜合基準測試中排名第二。
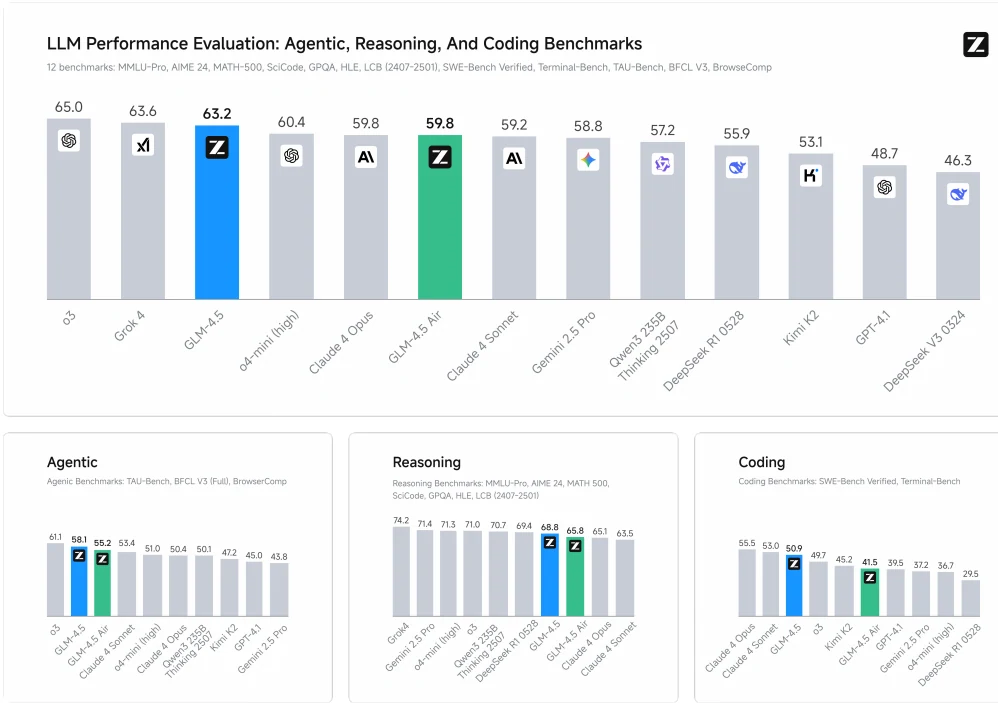
兩個模型皆具備 128k 上下文長度及原生函式呼叫能力,並可透過 Novita AI 最佳化的推論基礎架構取得。
⚡ 整體表現
GLM-4.5 在涵蓋自主(3 項)、推理(7 項)和程式碼(2 項)任務的 12 項基準測試中排名第二,GLM-4.5-Air 排名第五,比較對象包含 OpenAI、Anthropic、Google DeepMind、xAI、阿里巴巴、Moonshot 及 DeepSeek 的模型。
GLM-4.5 統一了所有能力,過去的模型雖然在程式碼、數學或推理等特定領域表現出色,但沒有任一模型能在所有任務上都達到最佳表現。
自主任務
GLM-4.5 是針對自主任務最佳化的基礎模型。它提供 128k 上下文長度及原生函式呼叫能力。Z.ai 在 τ-bench 和 BFCL-v3(Berkeley 函式呼叫排行榜 v3)上衡量其自主能力。在這兩個基準測試中,GLM-4.5 的表現與 Claude-4-Sonnet 相當。
網頁瀏覽是一種常見的自主應用,需要複雜推理和多輪工具使用。Z.ai 在 BrowseComp 基準測試上評估 GLM-4.5,這項網頁瀏覽的挑戰性基準測試包含需要簡短答案的複雜問題。在使用網頁瀏覽工具的情況下,GLM-4.5 對所有問題的正確回答率達 26.4%,明顯優於 Claude-4-Opus(18.8%)且接近 o4-mini-high(28.0%)。
| 基準測試 | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Qwen3 235B Thinking 2507 | DeepSeek R1 0528 | Kimi K2 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TAU-bench | 70.1 | 69.4 | 61.2 | 57.4 | 62.0 | 70.5 | 70.3 | 62.5 | 73.2 | 58.7 | 62.6 | 67.5 |
| BFCL v3 (Full) | 77.8 | 76.4 | 72.4 | 67.2 | 68.9 | 61.8 | 75.2 | 61.2 | 72.4 | 63.8 | 71.1 | 66.2 |
| BrowseComp | 26.4 | 21.3 | 49.7 | 28.3 | 4.1 | 18.8 | 14.7 | 7.6 | 4.6 | 3.2 | 7.9 | 32.6 |
推理
在思考模式下,GLM-4.5 和 GLM-4.5-Air 能夠解決複雜的推理問題,包括數學、科學和邏輯問題。
| 基準測試 | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | DeepSeek R1 0528 | Qwen3-235B Thinking 2507 | Grok4 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MMLU Pro | 84.6 | 81.4 | 85.3 | 83.2 | 87.3 | 84.2 | 86.2 | 83.2 | 84.9 | 84.5 | 86.6 |
| AIME24 | 91.0 | 89.4 | 90.3 | 94.0 | 75.7 | 77.3 | 88.7 | 82.3 | 89.3 | 94.1 | 94.3 |
| MATH 500 | 98.2 | 98.1 | 99.2 | 98.9 | 98.2 | 99.1 | 96.7 | 98.1 | 98.3 | 98.0 | 99.0 |
| SciCode | 41.7 | 37.3 | 41.0 | 46.5 | 39.8 | 40.0 | 42.8 | 39.4 | 40.3 | 42.9 | 45.7 |
| GPQA | 79.1 | 75.0 | 82.7 | 78.4 | 79.6 | 77.7 | 84.4 | 79.0 | 81.3 | 81.1 | 87.7 |
| HLE | 14.4 | 10.6 | 20.0 | 17.5 | 11.7 | 8.5 | 21.1 | 11.1 | 14.9 | 15.8 | 23.9 |
| LiveCodeBench (2407-2501) | 72.9 | 70.7 | 78.4 | 80.4 | 63.6 | 58.0 | 80.1 | 69.5 | 77.0 | 78.2 | 81.9 |
| AA-Index (Estimated) | 67.7 | 64.8 | 70.0 | 69.8 | 64.4 | 62.7 | 70.5 | 65.1 | 68.3 | 69.4 | 73.2 |
程式碼
GLM-4.5 在程式碼方面也表現優異,包含從頭建立程式碼專案,以及以自主方式解決現有專案中的程式碼任務。它可以無縫地與現有的程式碼工具包(如 Claude Code、Roo Code 和 CodeGeex)結合使用。為了評估程式碼能力,Z.ai 在 SWE-bench Verified 和 Terminal Bench 上比較了不同模型。
| 基準測試 | GLM-4.5 | GLM-4.5-Air | o3 | o4-mini-high | GPT-4.1 | Claude 4 Opus | Claude 4 Sonnet | Gemini 2.5 Pro | Gemini 2.5 Flash | Qwen3 235B Thinking 2507 | Qwen3 235B | DeepSeek R1 0528 | Kimi K2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SWE-bench Verified | 64.2 | 57.6 | 69.1 | 54.8 | 48.6 | 67.8 | 70.4 | 49.0 | 60.4 | 35.0 | 36.2 | 41.4 | 65.4 |
| Terminal-Bench | 37.5 | 30.0 | 30.2 | 18.5 | 30.3 | 43.2 | 35.5 | 25.3 | 16.8 | 6.3 | 6.6 | 17.5 | 25.0 |
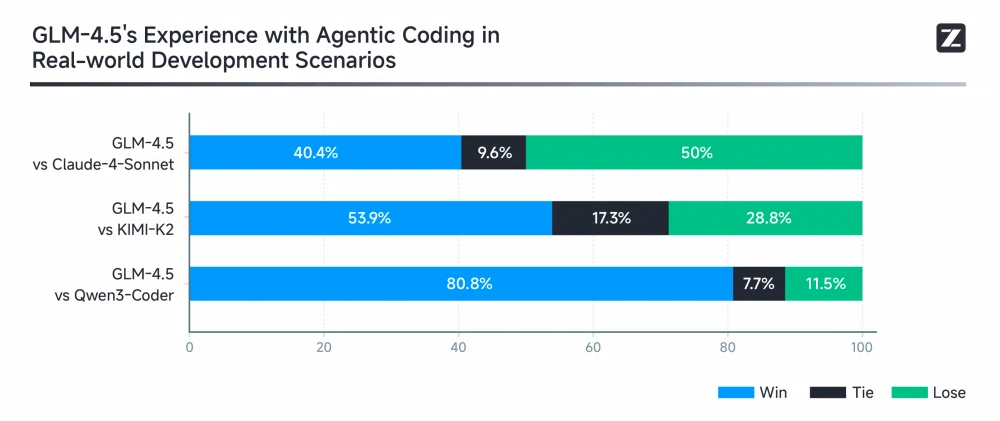
為了在真實場景中評估 GLM-4.5 的自主程式碼能力,Z.ai 使用 Claude Code 針對 52 項程式碼任務(涵蓋前端開發、工具開發、資料分析、測試和演算法應用)進行全面測試,與 Claude-4-Sonnet、Kimi K2 和 Qwen3-Coder 比較。GLM-4.5 在 53.9% 的任務中勝過 Kimi K2,並以 80.8% 的勝率壓制 Qwen3-Coder,同時顯示與 Claude-4-Sonnet 相比仍有進步空間。
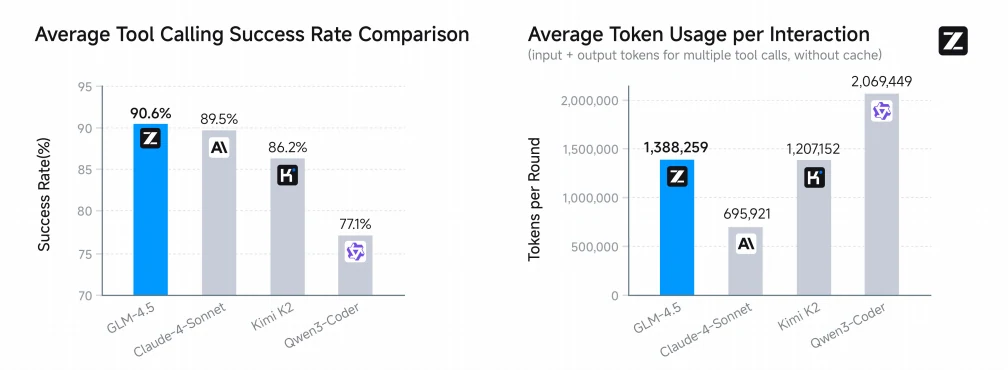
值得注意的是,GLM-4.5 的平均工具呼叫成功率最高,達 90.6%,優於 Claude-4-Sonnet(89.5%)、Kimi-K2(86.2%)和 Qwen3-Coder(77.1%),展現了在自主程式碼任務中卓越的可靠性與效率。
🚀 立即開始使用 Novita AI
使用 Playground(無需編寫程式碼)
- 即時存取:註冊後數秒內即可開始嘗試 GLM-4.5
- 互動式介面:即時測試複雜推理提示並視覺化結構化輸出
- 模型比較:根據您的特定使用案例,比較 GLM-4.5 與其他領先模型
透過 API 整合(適用於開發者)
使用 Novita AI 的統一 REST API 將 GLM-4.5 連接到您的應用程式。
選項一:直接 API 整合(Python 範例)
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_S4q9KTdBQujFkXSE5aZYZCrwN9f5QO96BtAFLw4FOgB__slLHW9KFAjmMgC12ag6mf2lJ1rASEvHbP_gv7Jh2Q==",
)
model = "zai-org/glm-4.5"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
主要功能:
- 與 OpenAI 相容的 API,實現無縫整合
- 彈性的參數控制,可微調回應
- 串流支援,實現即時回應
選項二:使用 OpenAI Agents SDK 建立多重代理工作流程 利用 GLM-4.5 建立精密的多重代理系統:
- 即插即用整合:在任何 OpenAI Agents 工作流程中使用 GLM-4.5
- 進階代理功能:支援交接、路由和工具整合,成功率達 90.6%
- 可擴展架構:設計能夠利用 GLM-4.5 統一推理、程式碼和自主能力的代理
連接第三方平台
- 開發工具:透過與 OpenAI 相容的 API,無縫整合至 Cursor、Cline 等熱門 IDE 和開發環境
- 編排框架:使用官方連接器連接 LangChain、Dify、Langflow 及其他 AI 編排平台
- Hugging Face 整合:透過 Novita AI 端點,在 Spaces、pipeline 或 Transformers 函式庫中使用 GLM-4.5
🔬 GLM-4.5 的技術創新
MoE 架構卓越性
GLM-4.5 採用混合專家(MoE)架構,提升了訓練和推論的計算效率。與 DeepSeek-V3 相比,其設計減少了寬度(隱藏維度和路由專家數量),同時增加了高度(層數)。
關鍵技術特點:
- 分組查詢注意力,搭配部分 RoPE(承襲自 ChatGLM2)
- QK-Norm,用於穩定注意力 logits 範圍
- Muon 優化器,實現加速收斂和更大的批次大小容差
- MTP(多 Token 預測)層,支援推論期間的投機解碼
先進的訓練流程
預訓練:兩階段方式
- 15T tokens 用於一般預訓練語料
- 7T tokens 用於程式碼與推理語料
中訓練:領域特定最佳化
- 儲存庫層級程式碼資料(500B tokens)
- 合成推理資料(500B tokens)
- 長上下文與代理資料(100B tokens)
後訓練:精密的混合方式
- 專家訓練:透過 SFT 和專門的強化學習,為推理、自主和一般領域分別訓練模型
- 統一訓練:透過大規模 SFT 自蒸餾,將專家知識提煉並合併為單一模型,隨後進行三階段 RL 對齊
slime:革命性的 RL 基礎架構
GLM-4.5 的訓練由 slime 驅動,這是一個專為大規模模型設計的開源 RL 基礎架構:
- 靈活的混合訓練架構:同時支援同步共置訓練和分離式非同步訓練
- 解耦的代理導向設計:分離推出引擎與訓練引擎,以實現最佳化效能
- 加速資料生成:使用 FP8 進行混合精度推論以生成資料,同時在訓練中維持 BF16 穩定性
🎯 準備好體驗統一的 AI 了嗎?
立即在 Novita AI 平台上嘗試 GLM-4.5 和 GLM-4.5-Air。親身體驗當推理、程式碼和自主功能在最佳化、生產就緒的基礎架構中匯聚時,統一的 AI 能力如何改變可能性。
立即開始打造 →
Novita AI 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的簡易方式,同時也提供價格合理且可靠的 GPU 雲端服務,用於建置和擴展。



