

MiniMax M1 stellt einen bedeutenden Sprung in der KI-Sprachmodell-Technologie dar und bietet leistungsstarke Fähigkeiten zur Verarbeitung langer Kontexte sowie flexible Einsatzoptionen. Diese umfassende Anleitung führt Sie durch den Zugriff und die Implementierung von MiniMax M1 und liefert die Werkzeuge, die Sie benötigen, um Ihre KI-gestützten Projekte zu verbessern.
Wichtige Highlights
MiniMax M1: 456B Parameter MoE-Modell, 1M Kontext.
MiniMax M1 über API nutzen
Einfach, OpenAI-kompatibel.
Anpassbare Parameter, kostenlose Testversion verfügbar.
MiniMax M1 lokal nutzen
Schritt-für-Schritt-Installationsanleitung.
MiniMax M1 auf Plattformen Dritter verbinden
Nahtlose Integration von MiniMax M1 über Hugging Face Spaces, Agent-Frameworks und OpenAI-kompatible APIs für optimierte Entwicklungsworkflows.
Neue Nutzer können für eine begrenzte Zeit Guthaben von 10 $ erhalten, um die LLM API auf Novita AI zu erkunden und zu nutzen.
Was ist MiniMax M1?
MiniMax M1 ist das weltweit erste quelloffene, große Hybrid-Expertise-Argumentationsmodell. Es kombiniert eine Mixture-of-Experts (MoE)-Architektur mit dem innovativen Lightning Attention-Mechanismus, der speziell für das Denken mit extrem langen Kontexten und komplexe Aufgaben entwickelt wurde. MiniMax unterstützt Funktionsaufrufe (function calling); seine Fähigkeit, Kontexte von bis zu 1 Million Token zu verarbeiten, macht es ideal für Forschung, Softwareentwicklung, mathematisches Denken und andere anspruchsvolle Anwendungen.
| Grundlegende Informationen | Details |
| Veröffentlichungsdatum | Juni 2025 |
| Modellgröße | 456B Parameter (45,9B aktiv) |
| Architektur | Hybride Mixture-of-Experts (MoE) mit Lightning Attention |
| Kontextlänge | 1M Token |
| Training | Groß angelegtes Reinforcement Learning auf vielfältigen Problemstellungen |
| Besondere Merkmale | Effiziente Skalierung der Rechenzeit beim Testen, hybride Aufmerksamkeit für RL |
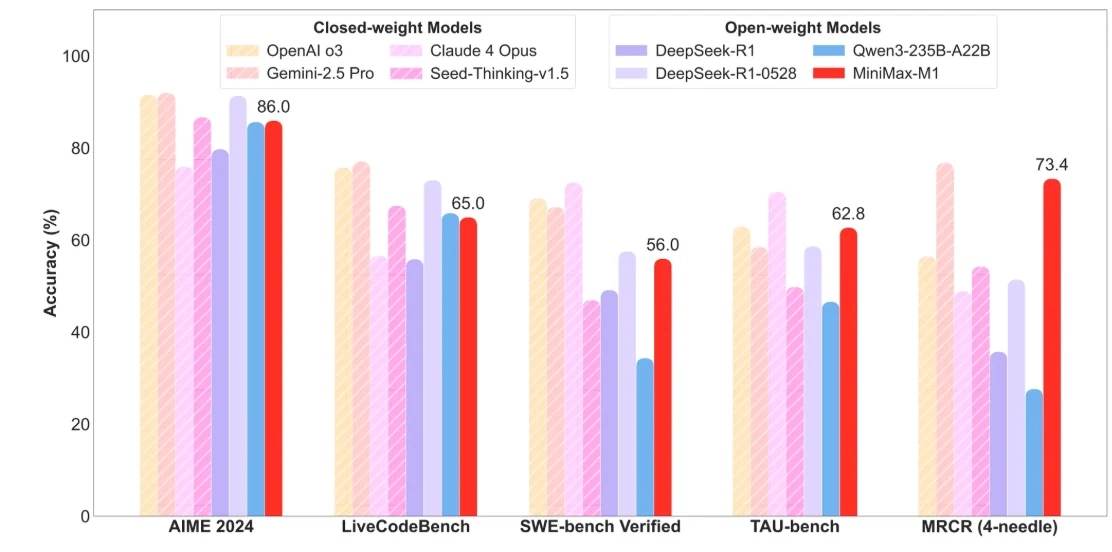
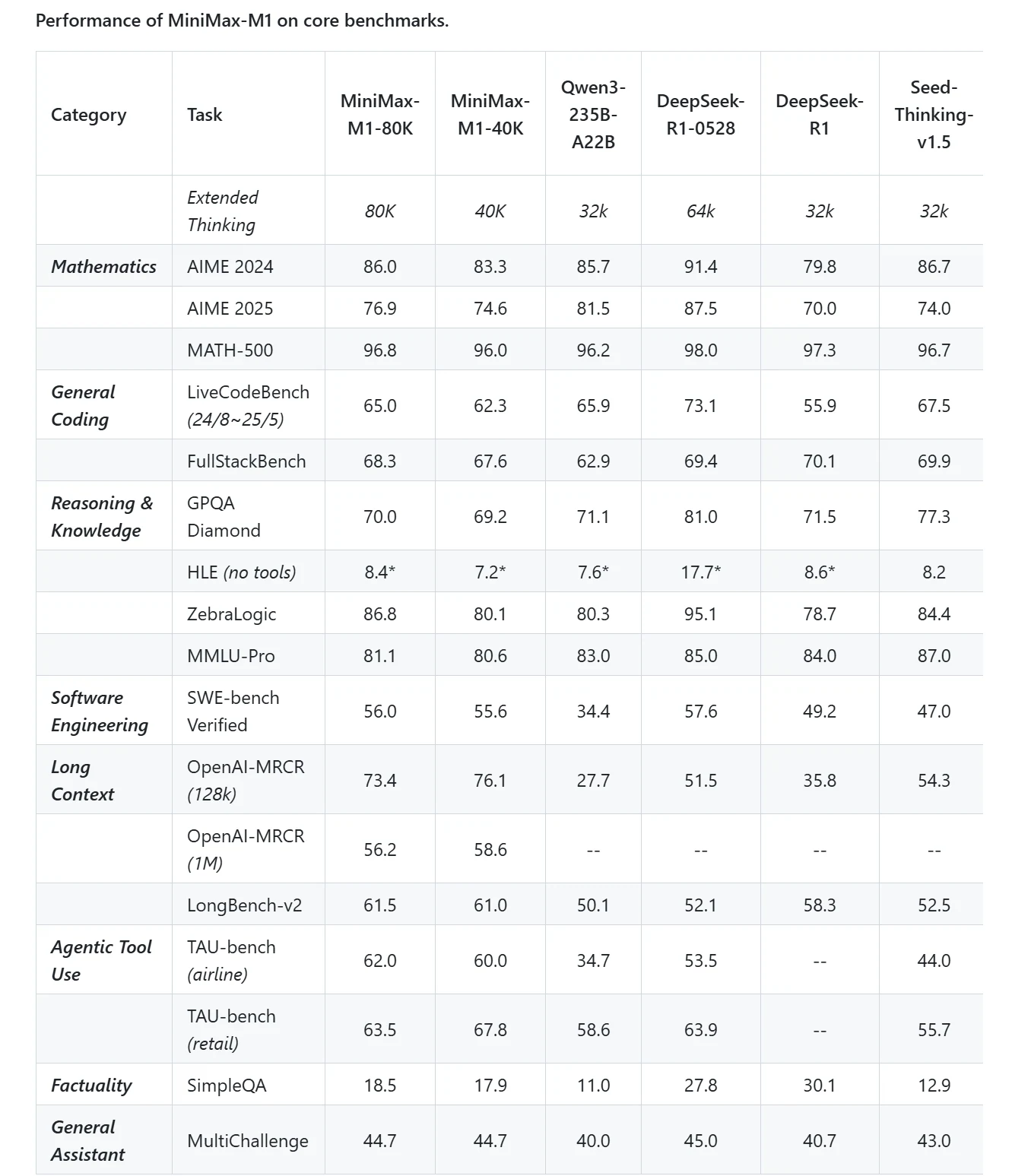
Minimax M1
Effiziente Verarbeitung langer Kontexte:
- Unterstützt ein langes Kontextfenster, das die Verarbeitung extrem langer Dokumente, technischer Codebasen und mehrteiliger Gespräche in einem Durchlauf ermöglicht.
- Verwendet eine hybride Mixture-of-Experts (MoE)-Architektur mit Lightning Attention für effiziente Inferenz, wodurch die Rechenkosten auf etwa 25 % vergleichbarer dichter Modelle reduziert werden.
- Ideal für Unternehmen, die große Wissensdatenbanken, Forschungspapiere und agentische Workflows verarbeiten, die ein tiefes kontextuelles Verständnis erfordern.
Kosteneffiziente Bereitstellung:
- Bietet wettbewerbsfähige API-Preise von 0,55 $ pro Million Input-Token und 2,2 $ pro Million Output-Token.
Quelloffen und forschungsfreundlich:
- Vollständig offenes Gewichtsmodell, das Community-Feintuning und Integration fördert und domänenspezifische Anpassungen in Bereichen wie Recht, Medizin und wissenschaftlicher Forschung ermöglicht.
- Unterstützt Funktionsaufrufe und die Nutzung von KI-Agenten-Werkzeugen, wodurch komplexe Workflows und mehrstufige Argumentationen ermöglicht werden.
MiniMax M1 über API nutzen
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine kostengünstige und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.
Jetzt MiniMax M1 Demo ausprobieren!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
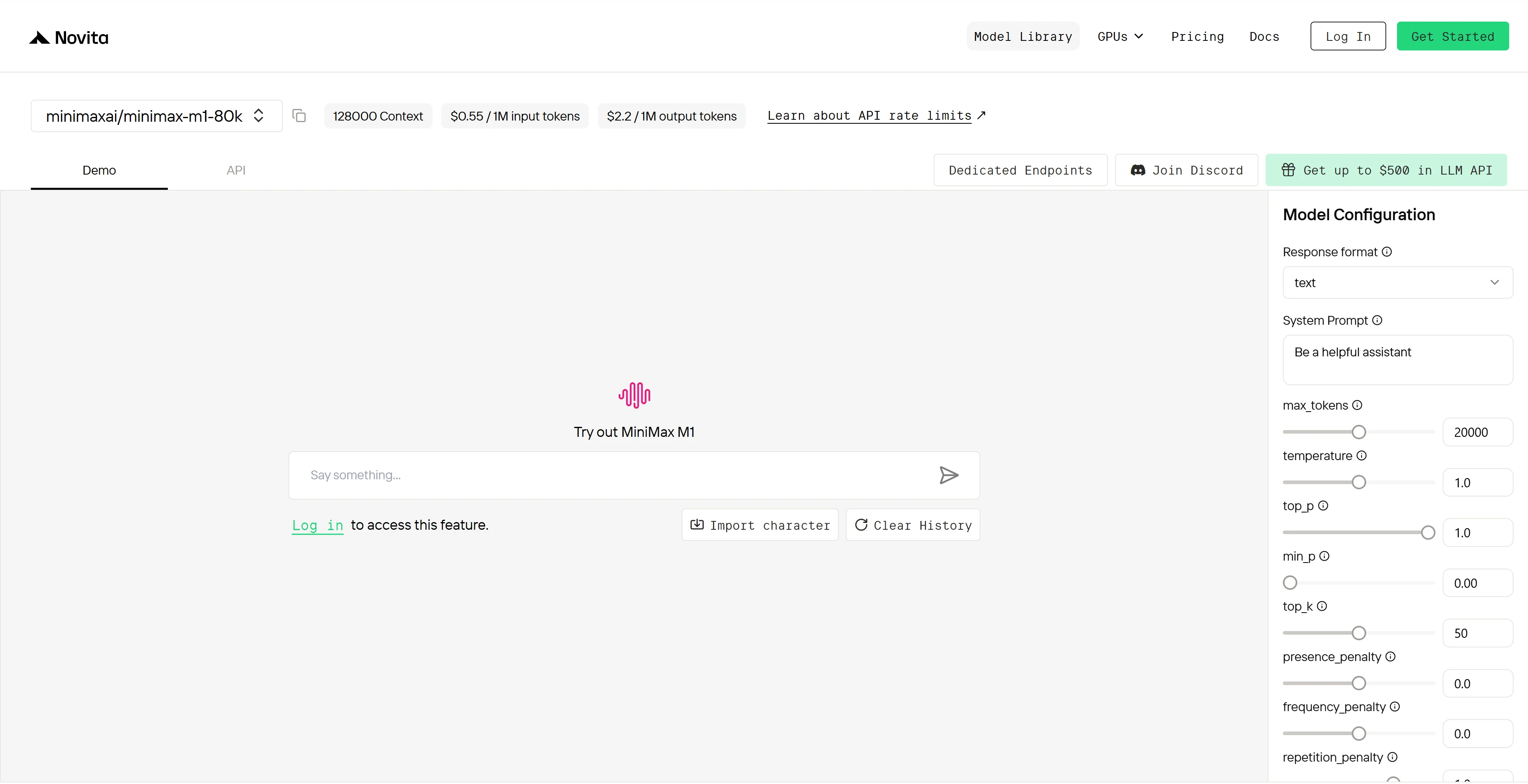
Schritt 4: API-Schlüssel abrufen
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie auf die Seite „Einstellungen“ und kopieren Sie den API-Schlüssel wie im Bild gezeigt.

Schritt 5: API installieren
Installieren Sie die API mit dem Paketmanager Ihrer Programmiersprache.
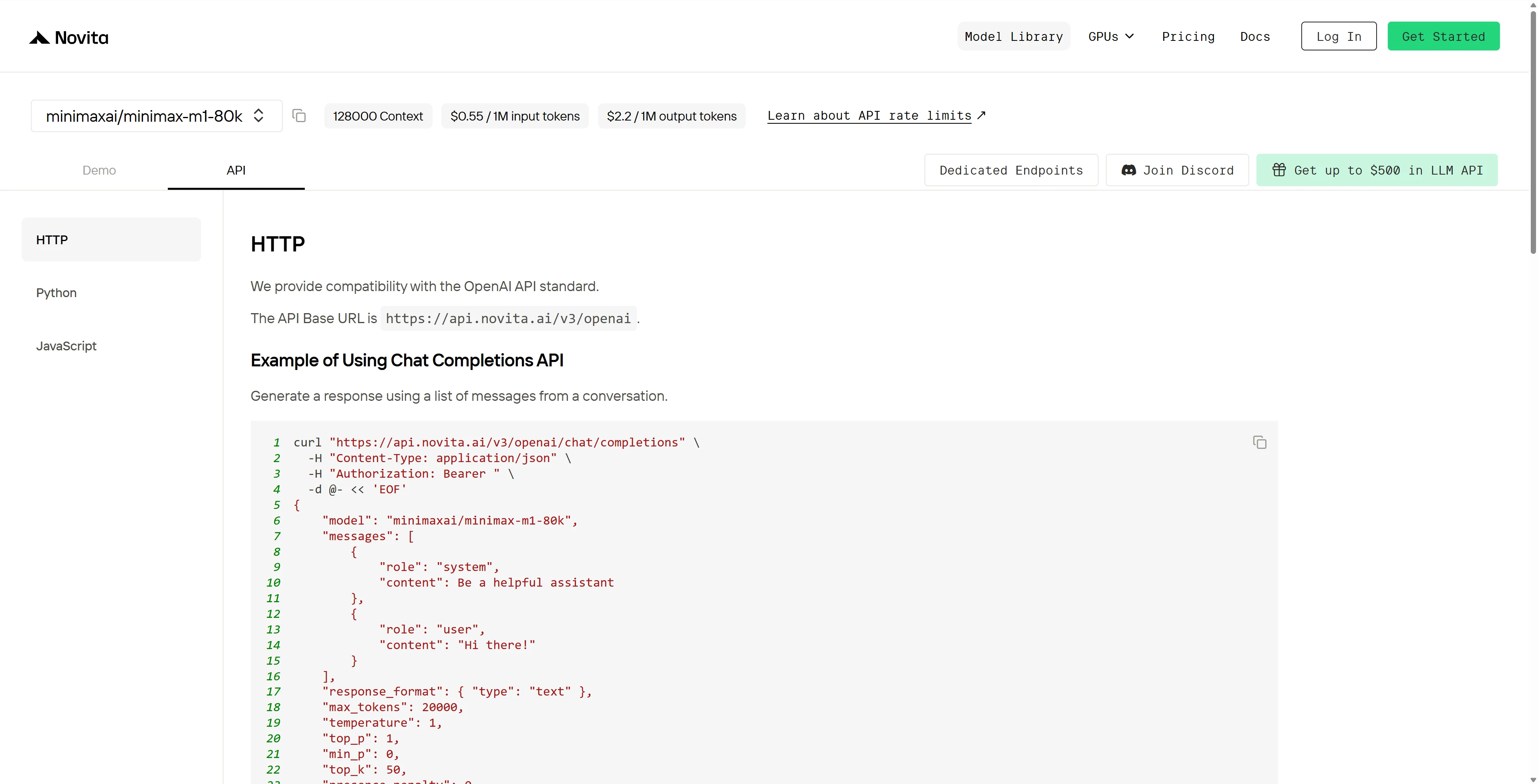
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit der Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat-Vervollständigungs-API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "minimaxai/minimax-m1-80k"
stream = True # or False
max_tokens = 20000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
MiniMax M1 lokal ausführen
Schritt-für-Schritt-Installationsanleitung
# Schritt 1: Python installieren und eine virtuelle Umgebung erstellen
# Stellen Sie sicher, dass Python 3.8+ installiert ist, erstellen und aktivieren Sie dann eine virtuelle Umgebung.
python3 -m venv minimax_env
source minimax_env/bin/activate # Unter Windows: `minimax_env\Scripts\activate`
# Schritt 2: Erforderliche Bibliotheken installieren
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # GPU-optimiertes PyTorch
pip install vllm huggingface-hub # vLLM zum Bereitstellen von MiniMax M1 und Hugging Face-Utilities
# Schritt 3: (Optional) Bei Hugging Face anmelden, falls Sie später Modelle abrufen möchten
pip install huggingface-cli
huggingface-cli login # Folgen Sie den Anweisungen zur Authentifizierung
# Schritt 4: MiniMax M1-Modell herunterladen (falls noch nicht geschehen)
# Ersetzen Sie <model-name> durch den tatsächlichen MiniMax M1-Repo-Namen auf Hugging Face
huggingface-cli download MiniMaxAI/MiniMax-M1-80k --local-dir ./minimax-m1
# Schritt 5: Umgebungsvariable für schnelles Laden setzen (Linux/macOS)
export SAFETENSORS_FAST_GPU=1
# Schritt 6: MiniMax M1-API-Server mit vLLM starten
# Passen Sie --tensor-parallel-size entsprechend Ihrer GPU-Anzahl an
python3 -m vllm.entrypoints.api_server \
--model ./minimax-m1 \
--tensor-parallel-size 8 \
--trust-remote-code \
--max_model_len 8192 \
--dtype bfloat16
# Schritt 7: Inferenz mit curl testen (in einem neuen Terminal)
curl -X POST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"prompt": "Explain quantum computing in simple terms.", "max_tokens": 100}'
# Schritt 8: (Optional) Python-Inferenz-Beispiel
python3 -c "
import requests
response = requests.post('http://localhost:8000/generate', json={
'prompt': 'Explain quantum computing in simple terms.',
'max_tokens': 100
})
print(response.json())
"
GPU-Arbeitsspeicher-Anforderungen:
- Minimum: 640 GB VRAM
- Empfohlen: 1.128 GB VRAM (8 x H200 SXM 141 GB Konfiguration) für optimale Leistung
MiniMax M1 auf Plattformen Dritter verbinden
- Hugging Face: Nutzen Sie MiniMax M1 in Spaces, Pipelines oder mit der Transformers-Bibliothek über Novita AI Endpunkte.
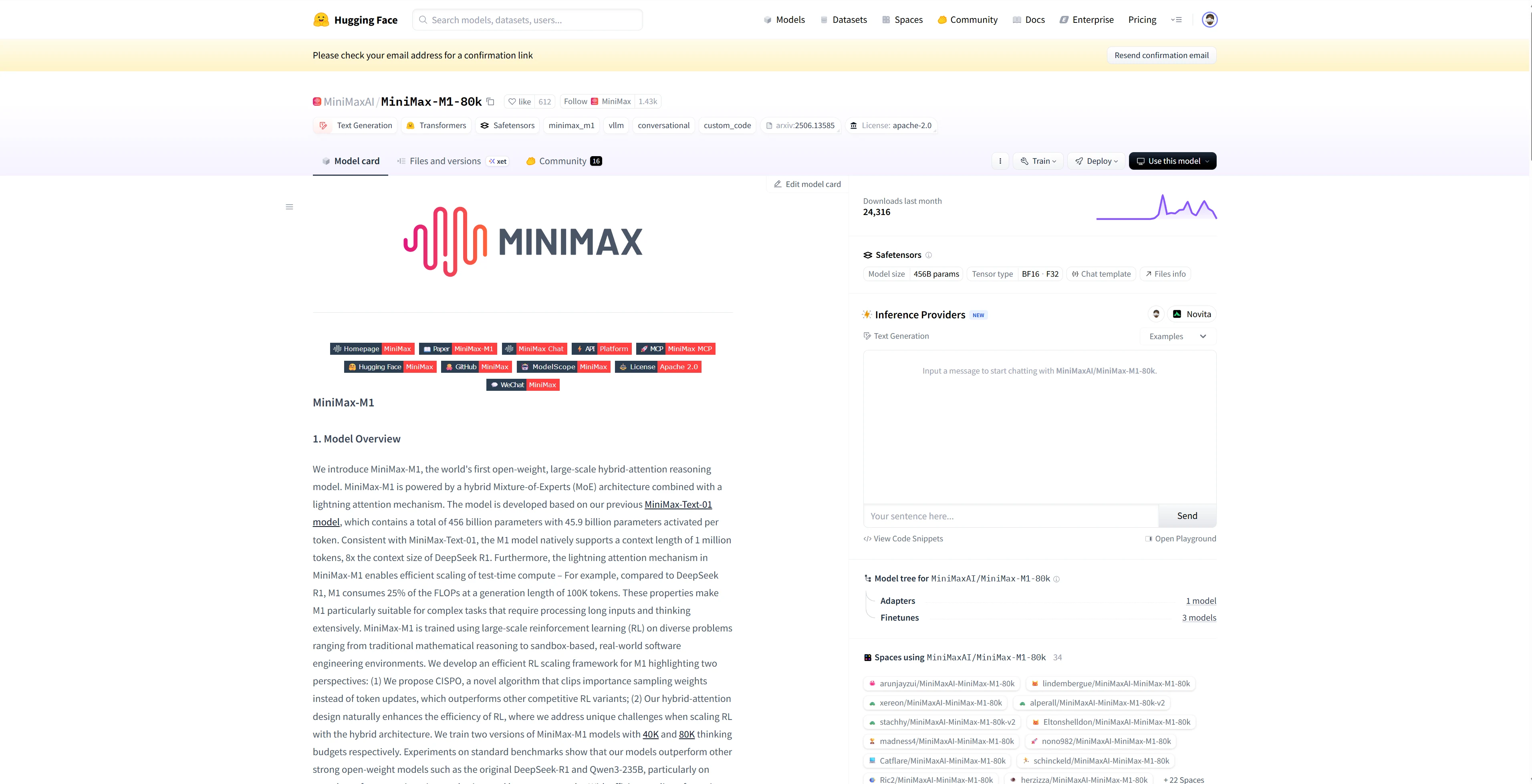
- Agent- und Orchestrierungs-Frameworks: Verbinden Sie Novita AI einfach mit Partnerplattformen wie Continue, AnythingLLM,LangChain, Dify und Langflow über offizielle Verbindungen und schrittweise Integrationsanleitungen.
- OpenAI-kompatible API: Genießen Sie eine problemlose Migration und Integration mit Tools wie Cline und Cursor, die für den OpenAI-API-Standard ausgelegt sind.
Novita AI ist mit über 20 Plattformen integriert; detaillierte Tutorials finden Sie in der Dokumentation.
MiniMax M1 ist ein bahnbrechendes, großes hybrides Aufmerksamkeits-Argumentationsmodell, das hervorragend für die Verarbeitung extrem langer Kontexte und komplexe Argumentationsaufgaben geeignet ist. Es verfügt über eine hybride Mixture-of-Experts (MoE)-Architektur in Kombination mit einem Lightning Attention-Mechanismus, der effiziente und skalierbare Inferenz ermöglicht. Sie können MiniMax M1 über die API nutzen oder auf Plattformen Dritter verbinden.
Neue Nutzer können für eine begrenzte Zeit Guthaben von 10 $ erhalten, um die LLM API auf Novita AI zu erkunden und zu nutzen.
Häufig gestellte Fragen
Wie kann ich MiniMax AI kostenlos nutzen?
Sie können die MiniMax AI Demo kostenlos auf Novita AI ausprobieren. Neue Nutzer können Guthaben von 10 $ erhalten, um die LLM API auf Novita AI zu erkunden und zu nutzen.
Welche Hardware wird benötigt, um MiniMax M1 lokal auszuführen?
Minimum: 640 GB VRAM
Empfohlen: 1.128 GB VRAM (8 x H200 SXM 141 GB Konfiguration) für optimale Leistung
Ist MiniMax M1 quelloffen?
Ja, MiniMax M1 ist vollständig quelloffen und auf Plattformen wie Hugging Face verfügbar.
Über Novita AI
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine kostengünstige und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.



