

MiniMax M1 代表了 AI 语言模型技术的重大飞跃,引入了强大的长上下文推理能力和灵活的部署选项。本综合指南将带你了解如何访问和实现 MiniMax M1,为增强 AI 驱动项目提供所需工具。
关键亮点
MiniMax M1:456B 参数 MoE 模型,1M 上下文。
通过 API 使用 MiniMax M1
简单,兼容 OpenAI 的 API。
可自定义参数,提供免费试用。
本地使用 MiniMax M1
分步安装指南。
在第三方平台上连接 MiniMax M1
通过 Hugging Face Spaces、智能体框架和兼容 OpenAI 的 API 无缝集成 MiniMax M1,实现高效的开发工作流程。
限时活动:新用户可领取 $10 免费额度,在 Novita AI 上探索并构建 LLM 应用。
MiniMax M1 是什么?
MiniMax M1 是世界上首个开源的大规模混合专家推理模型。它结合了专家混合(MoE)架构与创新的 Lightning Attention 机制,专为超长上下文推理和复杂任务而设计。MiniMax 支持 函数调用,其处理高达 100 万 token 上下文 的能力使其成为研究、软件开发、数学推理等要求苛刻的应用程序的理想选择。
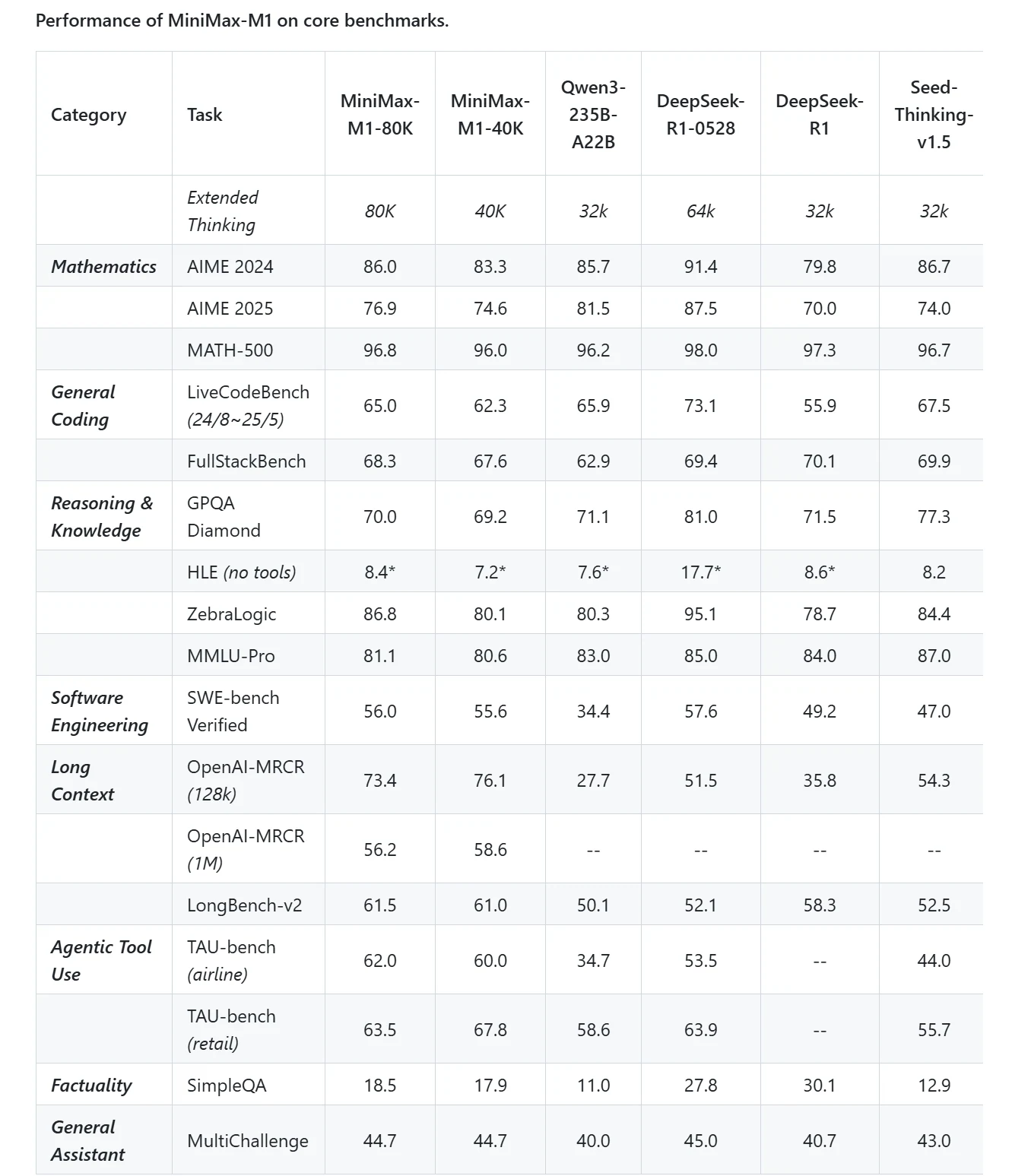
| 基本信息 | 详情 |
| 发布日期 | 2025 年 6 月 |
| 模型规模 | 456B 参数(45.9B 活跃) |
| 架构 | 混合专家混合(MoE)与 Lightning Attention |
| 上下文长度 | 1M token |
| 训练 | 基于多样化问题集的大规模强化学习 |
| 特色功能 | 测试时计算的高效扩展,用于强化学习的混合注意力 |
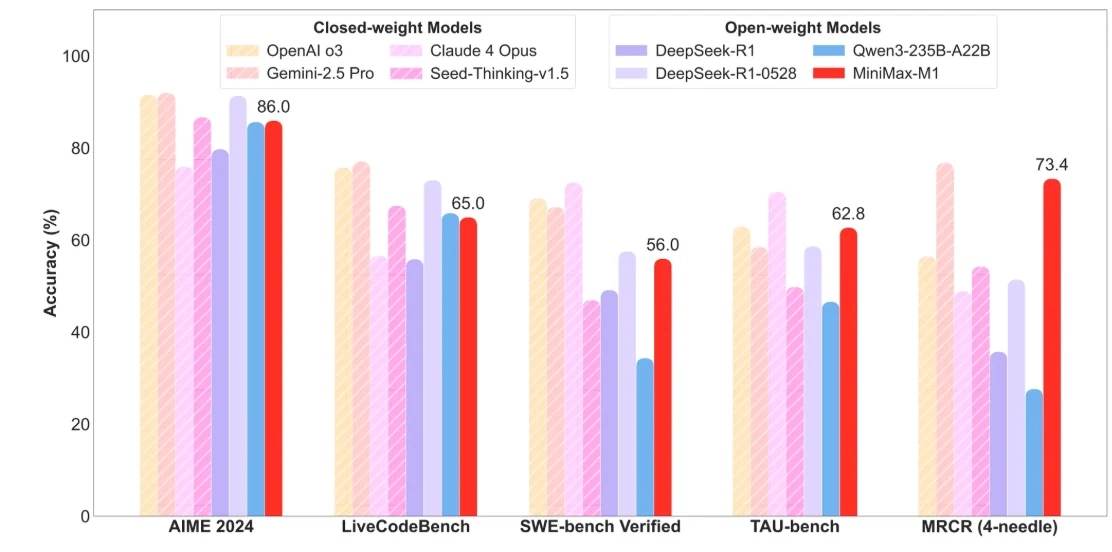
Minimax M1
高效长上下文处理:
- 支持长上下文窗口,能够一次性处理极长文档、技术代码库和多轮对话。
- 采用混合专家混合(MoE)架构与 Lightning Attention,实现高效推理,计算成本约为同等密集模型的 25%。
- 非常适合需要深入上下文理解的企业级大规模知识库、研究论文和智能体工作流。
经济高效的部署:
- 提供具有竞争力的 API 定价:每百万输入 token 0.55 美元,每百万输出 token 2.2 美元。
开源且对研究友好:
- 完全开源权重的模型,鼓励社区微调和集成,支持法律、医学和科学研究等领域的特定领域定制。
- 支持函数调用和智能体 AI 工具使用,实现复杂工作流和多步推理。
通过 API 使用 MiniMax M1
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,并提供经济可靠的 GPU 云用于构建和扩展。
第 1 步:登录并访问模型库
登录你的账户,点击 模型库 按钮。
第 2 步:选择模型
浏览可用选项,选择适合你需求的模型。
第 3 步:开始免费试用
开始免费试用,探索所选模型的功能。
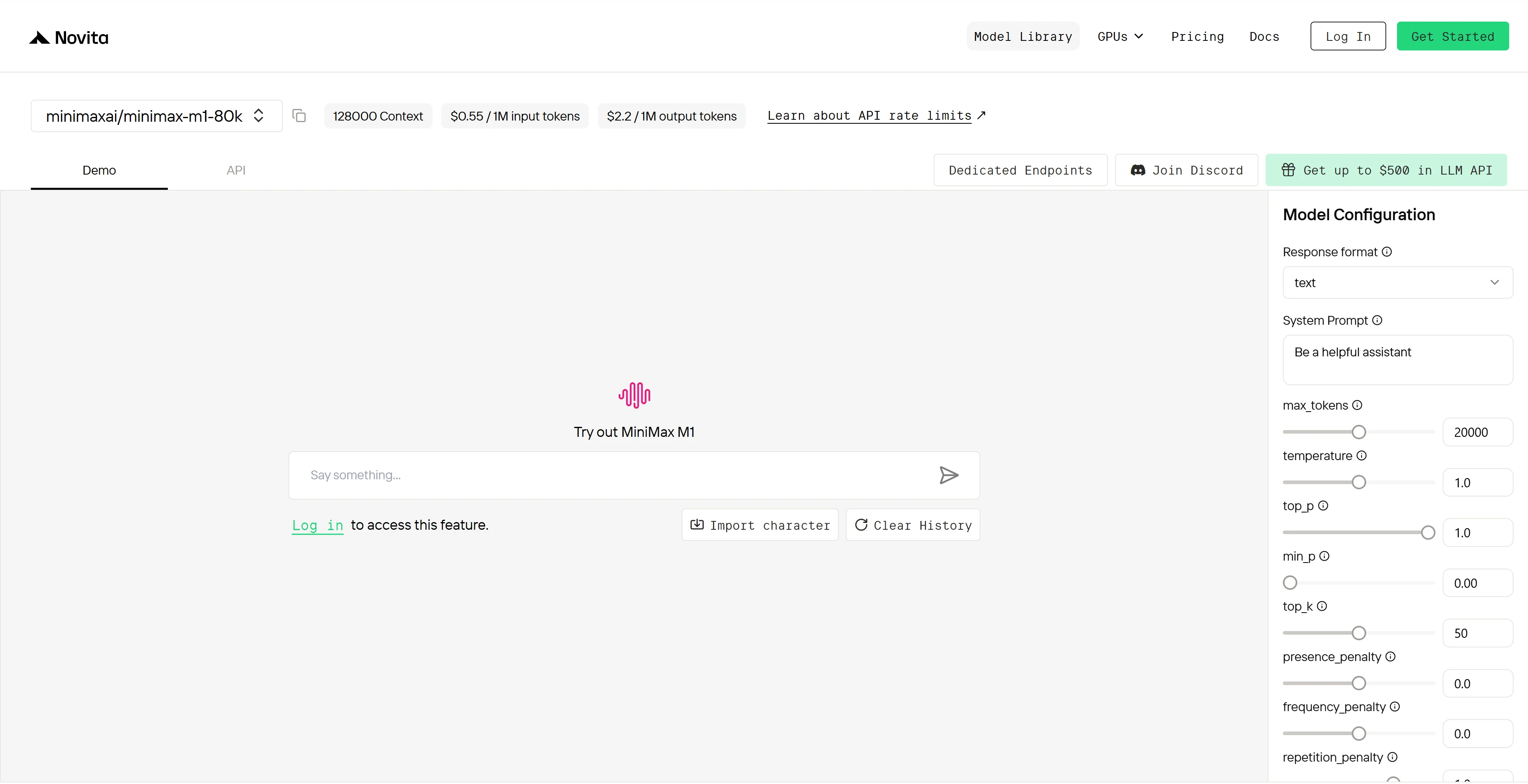
第 4 步:获取 API 密钥
为了通过 API 进行身份验证,我们将为你提供一个新的 API 密钥。进入“设置”页面,可以复制 API 密钥,如图所示。

第 5 步:安装 API
使用特定于编程语言的包管理器安装 API。
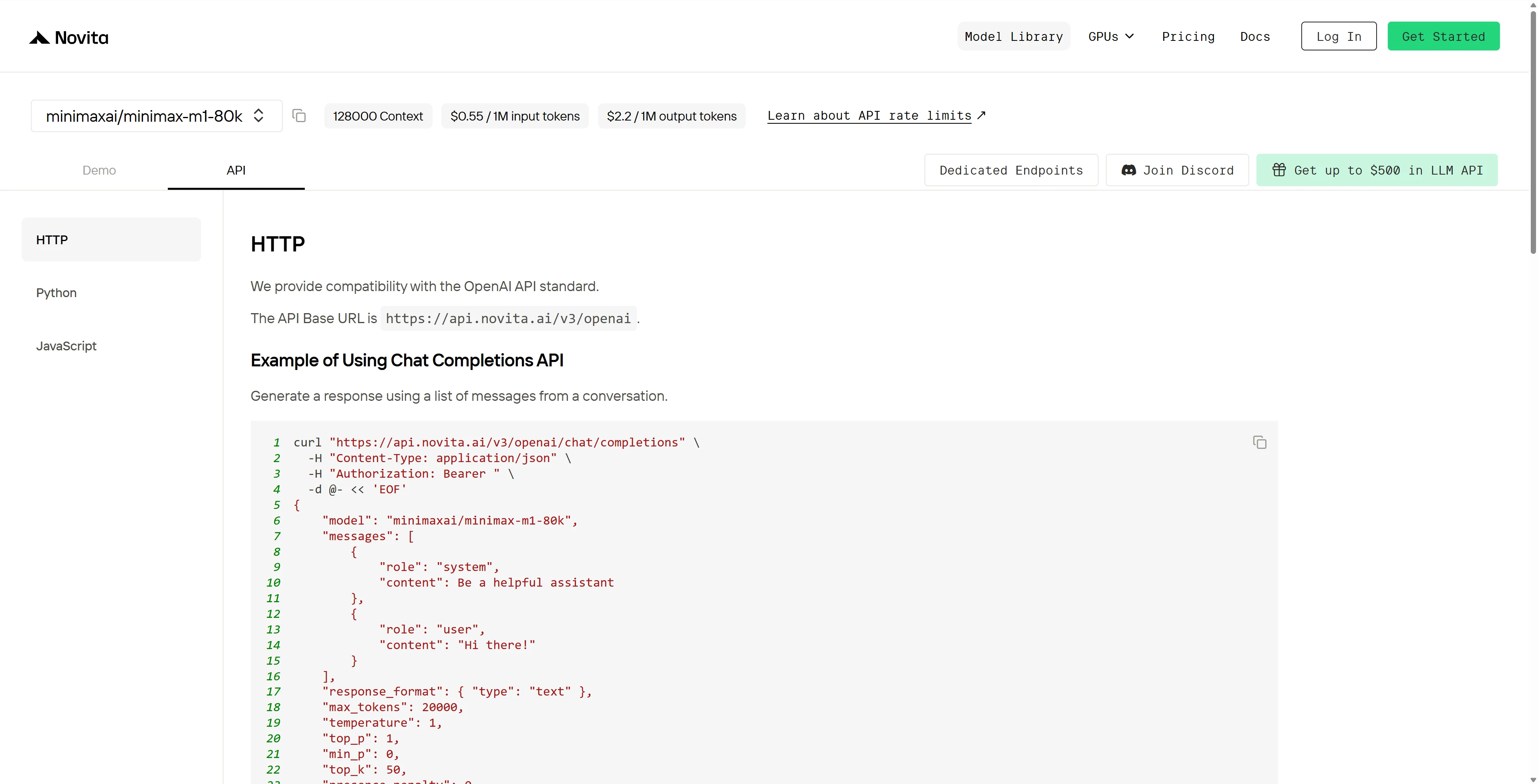
安装后,将所需库导入到开发环境中。使用你的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是适用于 Python 用户的聊天补全 API 示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "minimaxai/minimax-m1-80k"
stream = True # or False
max_tokens = 20000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
本地运行 MiniMax M1
分步安装指南
# Step 1: Install Python and Create a Virtual Environment
# Make sure Python 3.8+ is installed, then create and activate a virtual environment.
python3 -m venv minimax_env
source minimax_env/bin/activate # On Windows, use `minimax_env\Scripts\activate`
# Step 2: Install Required Libraries
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # GPU optimized PyTorch
pip install vllm huggingface-hub # vLLM for serving MiniMax M1, and Hugging Face utilities
# Step 3: (Optional) Login to Hugging Face if you want to pull models later
pip install huggingface-cli
huggingface-cli login # Follow prompts to authenticate
# Step 4: Download MiniMax M1 Model (if not already done)
# Replace <model-name> with actual MiniMax M1 repo name on Hugging Face
huggingface-cli download MiniMaxAI/MiniMax-M1-80k --local-dir ./minimax-m1
# Step 5: Set Environment Variable for Fast Loading (Linux/macOS)
export SAFETENSORS_FAST_GPU=1
# Step 6: Launch MiniMax M1 API Server with vLLM
# Adjust --tensor-parallel-size according to your GPU count
python3 -m vllm.entrypoints.api_server \
--model ./minimax-m1 \
--tensor-parallel-size 8 \
--trust-remote-code \
--max_model_len 8192 \
--dtype bfloat16
# Step 7: Test Inference with curl (in a new terminal)
curl -X POST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"prompt": "Explain quantum computing in simple terms.", "max_tokens": 100}'
# Step 8: (Optional) Python inference example
python3 -c "
import requests
response = requests.post('http://localhost:8000/generate', json={
'prompt': 'Explain quantum computing in simple terms.',
'max_tokens': 100
})
print(response.json())
"
GPU 内存需求:
- 最低: 640GB VRAM
- 推荐: 1,128GB VRAM(8 x H200 SXM 141GB 配置)以获得最佳性能
在第三方平台上连接 MiniMax M1
- Hugging Face:通过 Novita AI 端点在 Spaces、管道或 Transformers 库中使用 MiniMax M1。
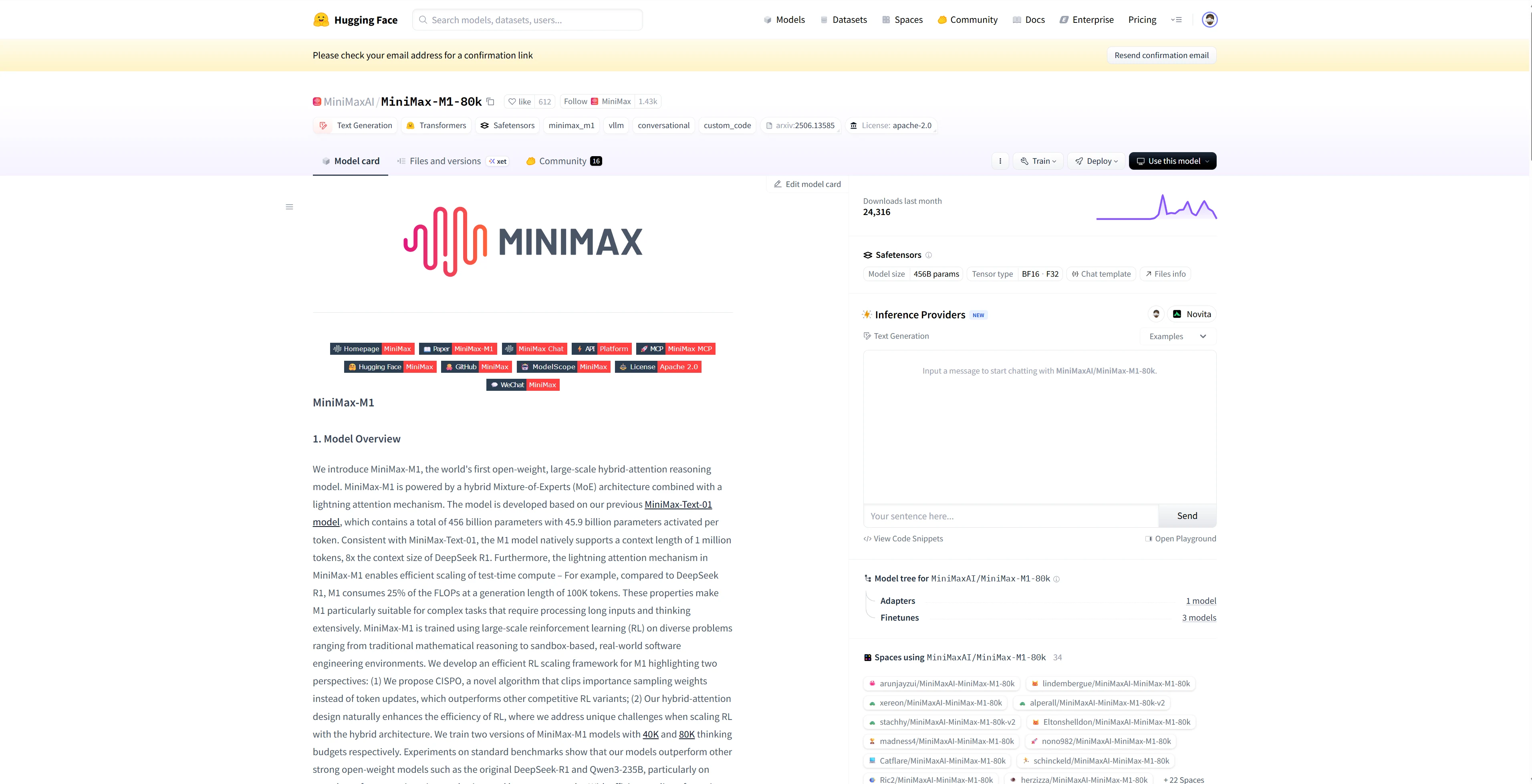
- 智能体与编排框架: 通过官方连接器和分步集成指南,轻松将 Novita AI 与合作伙伴平台(如 Continue、AnythingLLM、LangChain、Dify 和 Langflow)连接。
- 兼容 OpenAI 的 API: 享受与 Cline 和 Cursor 等工具的无缝迁移和集成,这些工具专为 OpenAI API 标准设计。
Novita AI 已与超过 20 个平台集成,详细教程可在文档中找到。
MiniMax M1 是一款开创性的大规模混合注意力推理模型,在处理超长上下文长度和复杂推理任务方面表现出色。它采用混合专家混合(MoE)架构与 Lightning Attention 机制,实现了高效且可扩展的推理。你可以通过 API 使用 MiniMax M1,或在第三方平台上进行连接。
限时活动:新用户可领取 $10 免费额度,在 Novita AI 上探索并构建 LLM 应用。
常见问题
如何免费使用 MiniMax AI?
你可以在 Novita AI 上免费尝试 MiniMax AI 演示。新用户可领取 $10 免费额度,在 Novita AI 上探索并构建 LLM 应用。
本地运行 MiniMax M1 需要什么硬件?
最低: 640GB VRAM
推荐: 1,128GB VRAM(8 x H200 SXM 141GB 配置)以获得最佳性能
MiniMax M1 是开源的吗?
是的,MiniMax M1 完全开源,可在 Hugging Face 等平台获取。
关于 Novita AI
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,并提供经济可靠的 GPU 云用于构建和扩展。



