

MiniMax M1 は、AI 言語モデル技術における重要な進歩であり、強力な長文脈推論機能と柔軟なデプロイオプションを提供します。この包括的なガイドでは、MiniMax M1 へのアクセス方法と実装方法を順を追って説明し、AI を活用したプロジェクトを強化するために必要なツールを提供します。
主なハイライト
MiniMax M1:456B パラメータの MoE モデル、1M コンテキスト。
API 経由での MiniMax M1 の使用
簡単、OpenAI 互換 API。
カスタマイズ可能なパラメータ、無料トライアルあり。
ローカルでの MiniMax M1 の使用
ステップバイステップのインストールガイド。
サードパーティプラットフォームでの MiniMax M1 の接続
Hugging Face Spaces、エージェントフレームワーク、OpenAI 互換 API を通じて MiniMax M1 をシームレスに統合し、開発ワークフローを効率化します。
期間限定で、新規ユーザーは 10 ドルの無料クレジット を請求して、Novita AI で LLM API を探索・構築できます。
MiniMax M1 とは?
MiniMax M1 は、世界初のオープンソース大規模ハイブリッド専門家推論モデルです。Mixture-of-Experts(**MoE)アーキテクチャ ** と革新的な Lightning Attention メカニズムを組み合わせており、超長文脈推論と複雑なタスク向けに特別に設計されています。MiniMax は ** 関数呼び出し ** をサポートし、最大 100 万トークンのコンテキスト を処理できるため、研究、ソフトウェア開発、数学的推論、その他の要求の厳しいアプリケーションに最適です。
| 基本情報 | 詳細 |
| リリース日 | 2025 年 6 月 |
| モデルサイズ | 456B パラメータ(45.9B アクティブ) |
| アーキテクチャ | Lightning Attention を備えたハイブリッド Mixture-of-Experts (MoE) |
| コンテキスト長 | 100 万トークン |
| トレーニング | 多様な問題セットに対する大規模強化学習 |
| 特別機能 | テスト時計算の効率的なスケーリング、RL 用ハイブリッドアテンション |
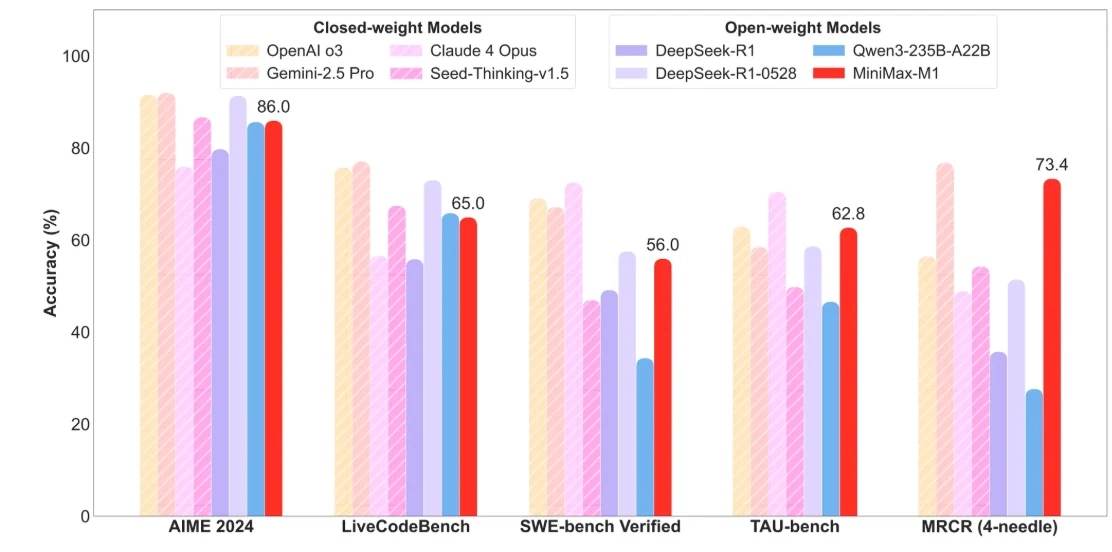
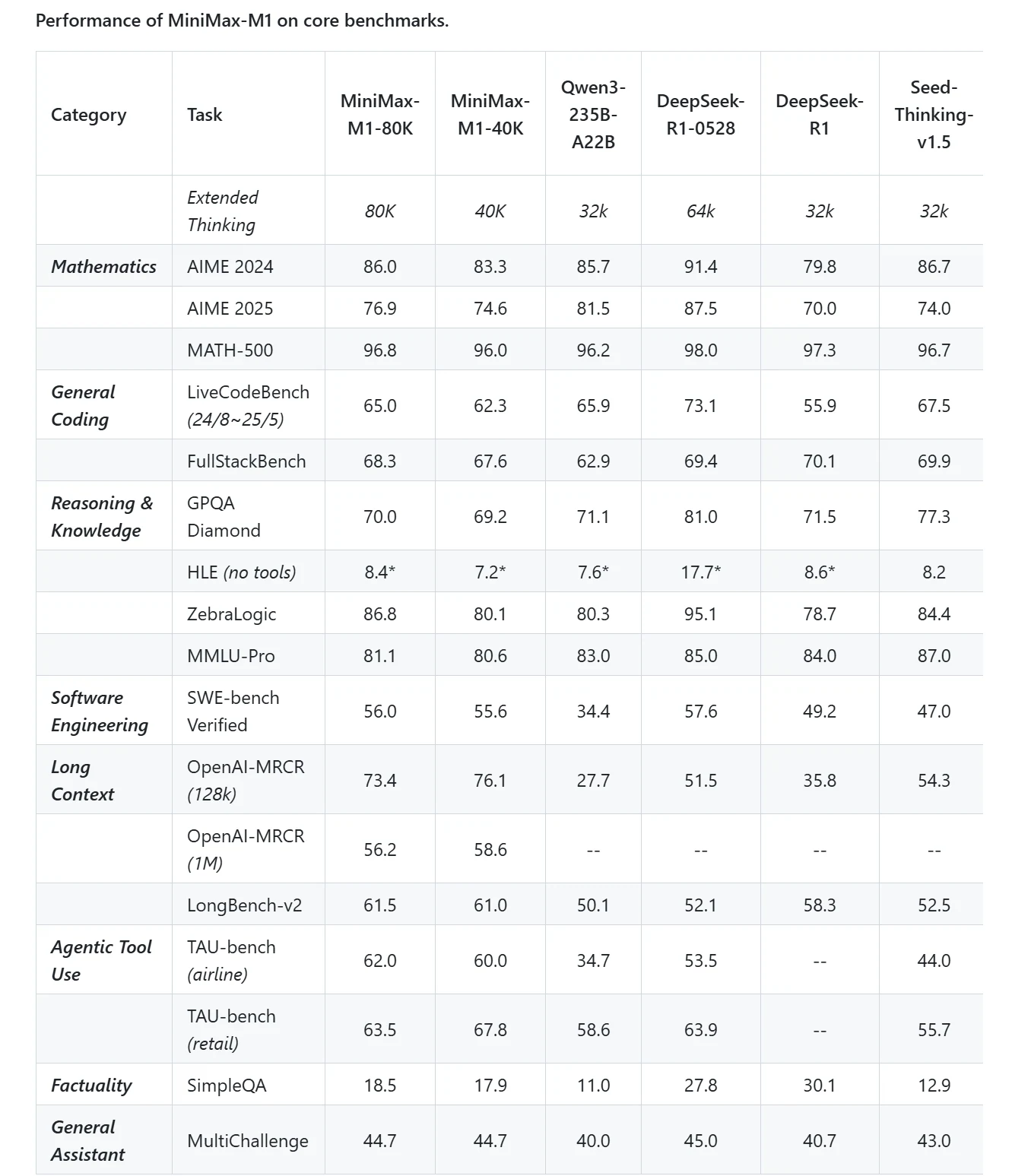
Minimax M1
効率的な長文脈処理:
- 長いコンテキストウィンドウをサポートし、非常に長いドキュメント、技術コードベース、複数ターンの会話を一度に処理できます。
- ハイブリッド Mixture-of-Experts (MoE) アーキテクチャと lightning attention を使用して効率的な推論を実現し、計算コストを同等の高密度モデルの約 25% に削減します。
- 深いコンテキスト理解を必要とする大規模ナレッジベース、研究論文、エージェンティックワークフローを扱う企業に最適です。
コスト効率の高いデプロイ:
- 入力トークン 100 万あたり 0.55 ドル、出力トークン 100 万あたり 2.2 ドルの競争力のある API 価格を提供します。
オープンソースで研究に優しい:
- 完全なオープンウェイトモデルで、コミュニティによるファインチューニングと統合を促進し、法律、医療、科学研究などの分野におけるドメイン固有のカスタマイズをサポートします。
- 関数呼び出しとエージェンティック AI ツールの使用をサポートし、複雑なワークフローと多段階推論を可能にします。
API 経由での MiniMax M1 の使用
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、同時に手頃で信頼性の高い GPU クラウドを提供して構築とスケーリングを可能にします。
ステップ 1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。
ステップ 2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ 3:無料トライアルを開始
無料トライアルを開始して、選択したモデルの機能を試してみましょう。
ステップ 4:API キーを取得
API で認証するために、新しい API キーを提供します。「設定」ページに移動し、画像に示されているように API キーをコピーします。

ステップ 5:API をインストール
プログラミング言語に固有のパッケージマネージャーを使用して API をインストールします。
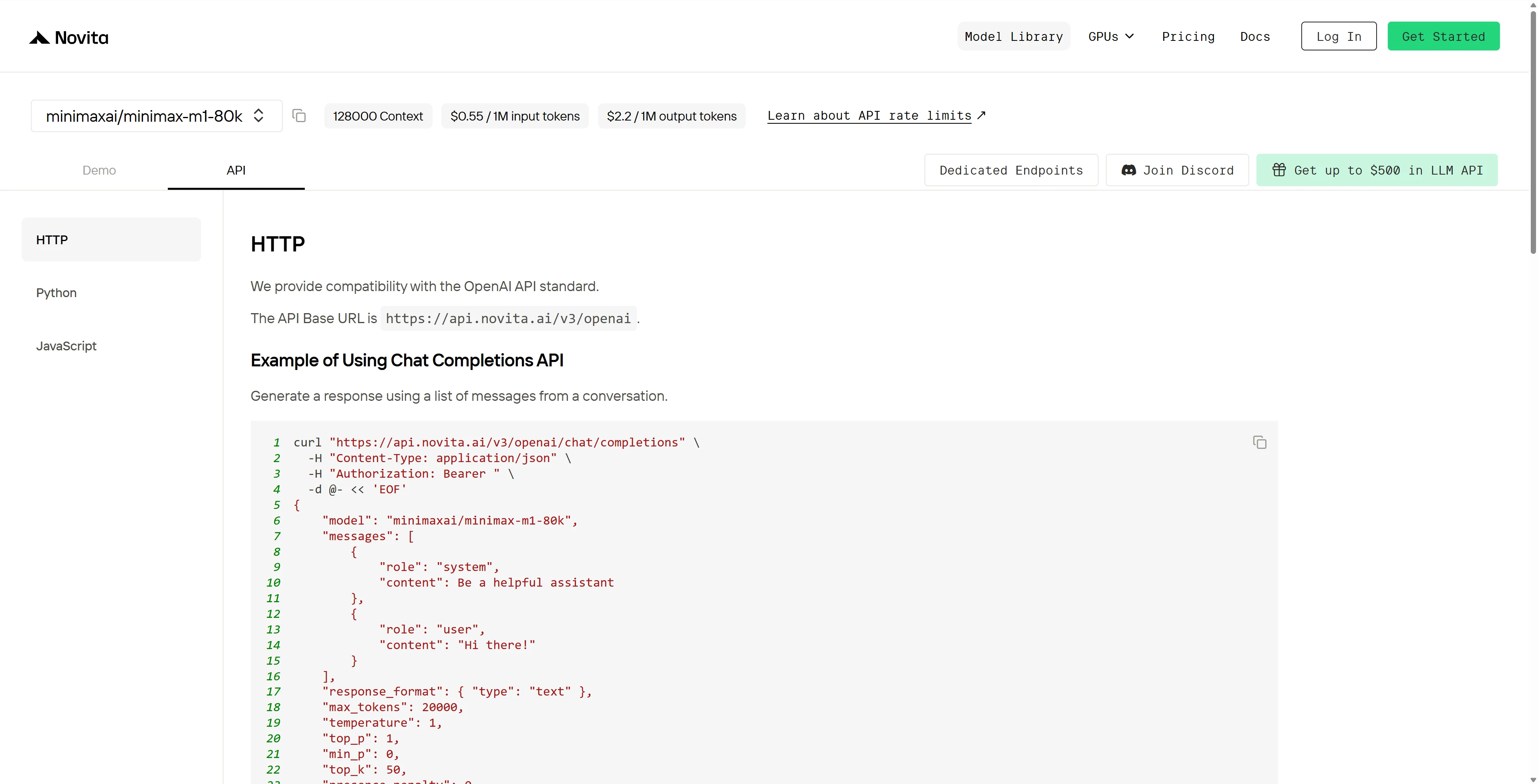
インストール後、必要なライブラリを開発環境にインポートします。API キーを使用して API を初期化し、Novita AI LLM との対話を開始します。これは、Python ユーザー向けのチャット補完 API を使用した例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "minimaxai/minimax-m1-80k"
stream = True # or False
max_tokens = 20000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
MiniMax M1 をローカルで実行する
ステップバイステップのインストールガイド
# Step 1: Install Python and Create a Virtual Environment
# Make sure Python 3.8+ is installed, then create and activate a virtual environment.
python3 -m venv minimax_env
source minimax_env/bin/activate # On Windows, use `minimax_env\Scripts\activate`
# Step 2: Install Required Libraries
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # GPU optimized PyTorch
pip install vllm huggingface-hub # vLLM for serving MiniMax M1, and Hugging Face utilities
# Step 3: (Optional) Login to Hugging Face if you want to pull models later
pip install huggingface-cli
huggingface-cli login # Follow prompts to authenticate
# Step 4: Download MiniMax M1 Model (if not already done)
# Replace <model-name> with actual MiniMax M1 repo name on Hugging Face
huggingface-cli download MiniMaxAI/MiniMax-M1-80k --local-dir ./minimax-m1
# Step 5: Set Environment Variable for Fast Loading (Linux/macOS)
export SAFETENSORS_FAST_GPU=1
# Step 6: Launch MiniMax M1 API Server with vLLM
# Adjust --tensor-parallel-size according to your GPU count
python3 -m vllm.entrypoints.api_server \
--model ./minimax-m1 \
--tensor-parallel-size 8 \
--trust-remote-code \
--max_model_len 8192 \
--dtype bfloat16
# Step 7: Test Inference with curl (in a new terminal)
curl -X POST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"prompt": "Explain quantum computing in simple terms.", "max_tokens": 100}'
# Step 8: (Optional) Python inference example
python3 -c "
import requests
response = requests.post('http://localhost:8000/generate', json={
'prompt': 'Explain quantum computing in simple terms.',
'max_tokens': 100
})
print(response.json())
"
GPU メモリ要件:
- 最小: 640GB VRAM
- 推奨: 1,128GB VRAM(8 x H200 SXM 141GB 構成)で最適なパフォーマンス
サードパーティプラットフォームでの MiniMax M1 の接続
- Hugging Face:Novita AI エンドポイント経由で、Spaces、パイプライン、または Transformers ライブラリで MiniMax M1 を使用します。
- エージェントおよびオーケストレーションフレームワーク: 公式コネクタとステップバイステップの統合ガイドを通じて、Novita AI を Continue、AnythingLLM、LangChain、Dify、Langflow などのパートナープラットフォームと簡単に接続できます。
- OpenAI 互換 API: Cline や Cursor などのツールとの、OpenAI API 標準に準拠した手間のかからない移行と統合をお楽しみいただけます。
Novita AI は 20 以上のプラットフォームと統合しており、詳細なチュートリアルは ドキュメント にあります。
MiniMax M1 は、超長文脈長と複雑な推論タスクに優れた、画期的な大規模ハイブリッドアテンション推論モデルです。ハイブリッド Mixture-of-Experts (MoE) アーキテクチャと lightning attention メカニズムを組み合わせており、効率的でスケーラブルな推論を可能にします。MiniMax M1 は API 経由で使用するか、サードパーティプラットフォームで接続できます。
期間限定で、新規ユーザーは 10 ドルの無料クレジット を請求して、Novita AI で LLM API を探索・構築できます。
よくある質問
MiniMax AI を無料で使用するには?
Novita AI で MiniMax AI デモ を無料でお試しいただけます。新規ユーザーは 10 ドルの無料クレジット を請求して、Novita AI で LLM API を探索・構築できます。
MiniMax M1 をローカルで実行するために必要なハードウェアは?
最小: 640GB VRAM
推奨: 1,128GB VRAM(8 x H200 SXM 141GB 構成)で最適なパフォーマンス
MiniMax M1 はオープンソースですか?
はい、MiniMax M1 は完全にオープンソースであり、Hugging Face などのプラットフォームで利用可能です。
Novita AI について
Novita AI は、開発者がシンプルな API を使用して AI モデルを簡単にデプロイできる AI クラウドプラットフォームであり、同時に手頃で信頼性の高い GPU クラウドを提供して構築とスケーリングを可能にします。



