

MiniMax M1 représente un bond significatif dans la technologie des modèles de langage IA, offrant des capacités avancées de raisonnement sur de longs contextes et des options de déploiement flexibles. Ce guide complet vous accompagne dans l’accès et l’implémentation de MiniMax M1, vous fournissant les outils nécessaires pour améliorer vos projets basés sur l’IA.
Points clés
MiniMax M1 : modèle MoE de 456B paramètres, contexte de 1M.
Utiliser MiniMax M1 via l’API
Simple, compatible avec l’API OpenAI.
Paramètres personnalisables, essai gratuit disponible.
Utiliser MiniMax M1 en local
Guide d’installation pas à pas.
Connecter MiniMax M1 sur des plateformes tierces
Intégrez facilement MiniMax M1 via Hugging Face Spaces, des frameworks d’agents et des API compatibles OpenAI pour des flux de développement rationalisés.
Pour une durée limitée, les nouveaux utilisateurs peuvent obtenir 10 $ de crédits gratuits pour explorer et construire avec l’API LLM sur Novita AI.
Qu’est-ce que MiniMax M1 ?
MiniMax M1 est le premier modèle de raisonnement hybride expert open-source à grande échelle. Il combine une architecture Mixture-of-Experts (MoE) avec le mécanisme innovant Lightning Attention, conçu spécifiquement pour le raisonnement sur de très longs contextes et les tâches complexes. MiniMax prend en charge l’appel de fonctions ; sa capacité à traiter jusqu’à 1 million de jetons de contexte le rend idéal pour la recherche, le développement logiciel, le raisonnement mathématique et d’autres applications exigeantes.
| Informations de base | Détails |
| Date de sortie | Juin 2025 |
| Taille du modèle | 456B paramètres (45,9B actifs) |
| Architecture | Hybride Mixture-of-Experts (MoE) avec Lightning Attention |
| Longueur du contexte | 1M jetons |
| Entraînement | Apprentissage par renforcement à grande échelle sur divers ensembles de problèmes |
| Fonctionnalités spéciales | Mise à l’échelle efficace du temps de calcul d’inférence, attention hybride pour RL |
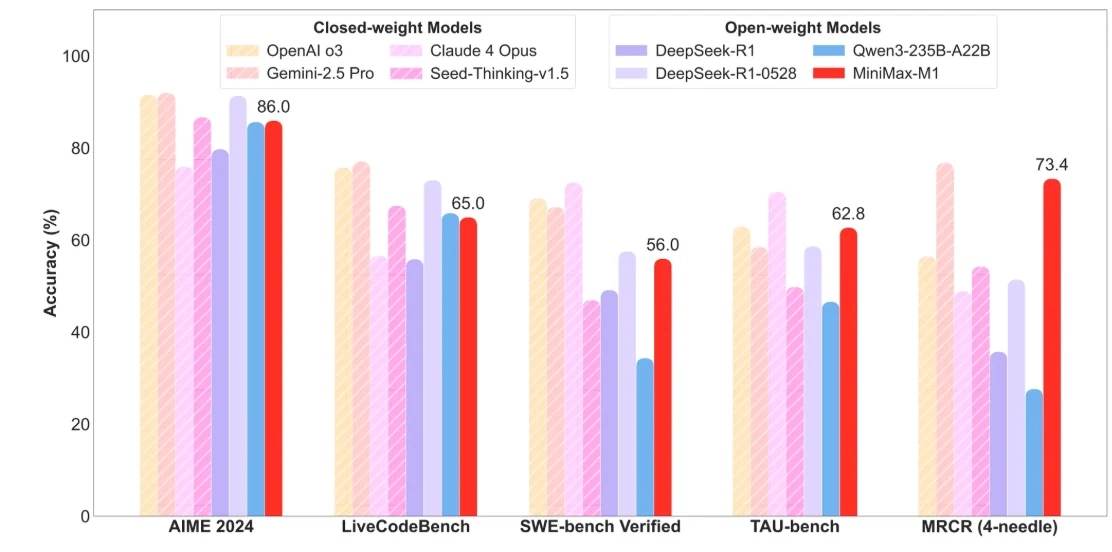
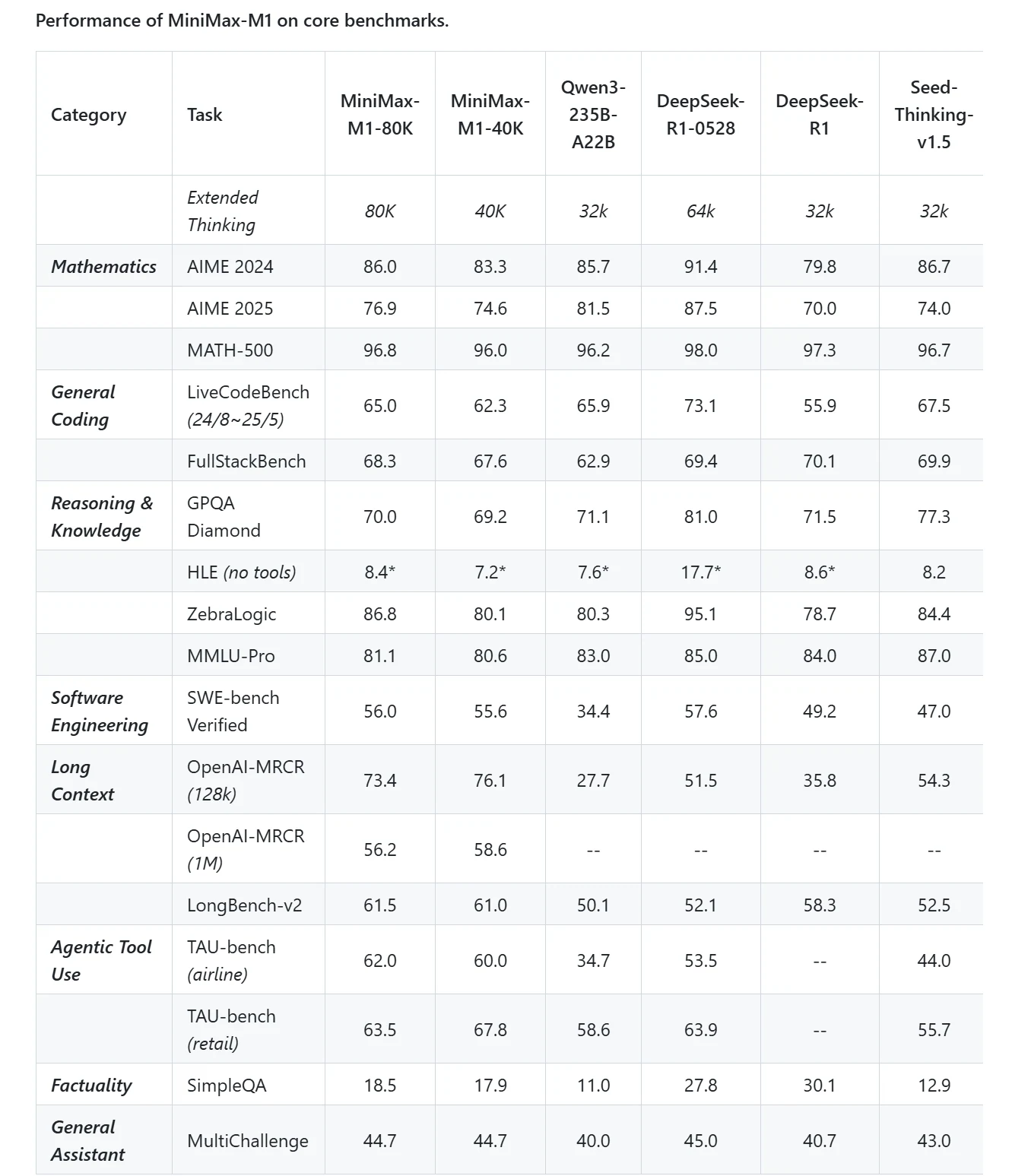
MiniMax M1
Traitement efficace des longs contextes :
- Prend en charge une fenêtre de contexte longue, permettant le traitement en une seule passe de documents extrêmement longs, de bases de code techniques et de conversations multi-tours.
- Utilise une architecture hybride Mixture-of-Experts (MoE) avec attention lightning pour une inférence efficace, réduisant le coût de calcul à environ 25 % de celui des modèles denses comparables.
- Idéal pour les entreprises manipulant des bases de connaissances à grande échelle, des documents de recherche et des flux de travail agentiques nécessitant une compréhension contextuelle profonde.
Déploiement rentable :
- Tarification API compétitive à 0,55 $ par million de jetons d’entrée et 2,2 $ par million de jetons de sortie.
Open-source et adapté à la recherche :
- Modèle entièrement open-weight encourageant le fine-tuning et l’intégration par la communauté, prenant en charge la personnalisation dans des domaines spécifiques comme le juridique, le médical et la recherche scientifique.
- Prend en charge l’appel de fonctions et l’utilisation d’outils agentiques IA, permettant des flux de travail complexes et un raisonnement multi-étapes.
Utiliser MiniMax M1 via l’API
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour construire et faire évoluer.
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Model Library.
Essayez la démo MiniMax M1 maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Démarrez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
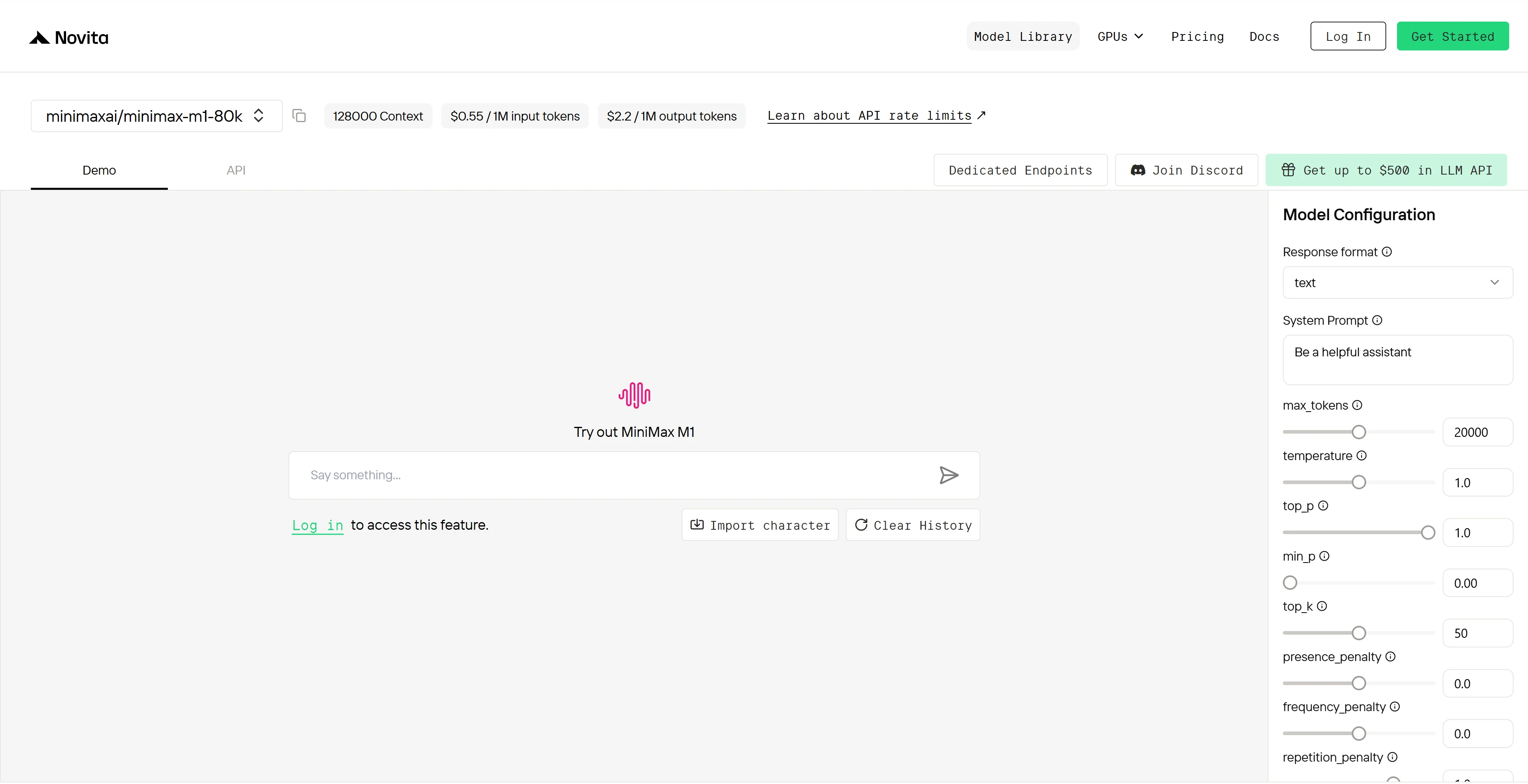
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En entrant dans la page « Settings », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
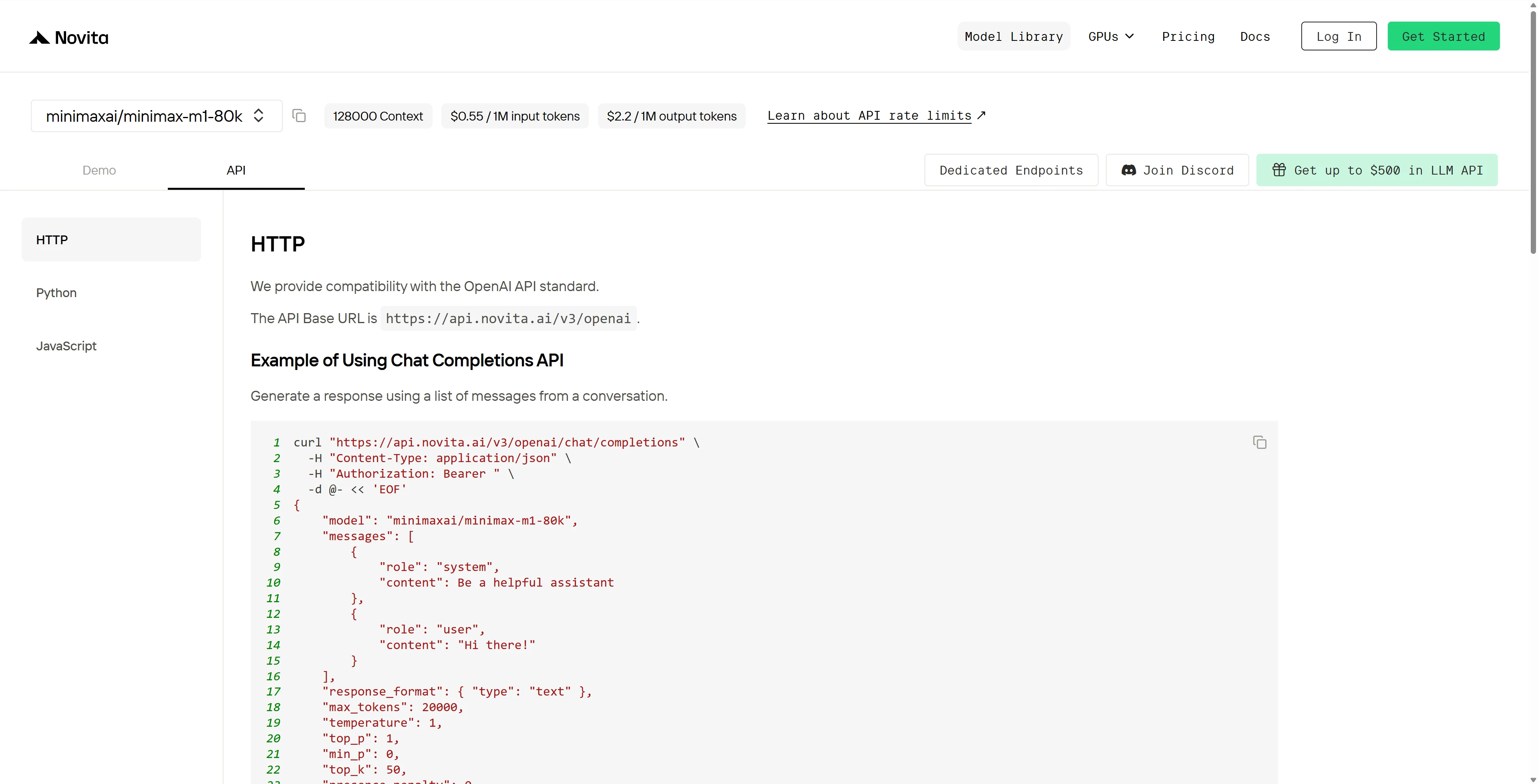
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Voici un exemple d’utilisation de l’API chat completions pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "minimaxai/minimax-m1-80k"
stream = True # or False
max_tokens = 20000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Exécuter MiniMax M1 en local
Guide d’installation pas à pas
# Étape 1 : Installer Python et créer un environnement virtuel
# Assurez-vous que Python 3.8+ est installé, puis créez et activez un environnement virtuel.
python3 -m venv minimax_env
source minimax_env/bin/activate # Sous Windows, utilisez `minimax_env\Scripts\activate`
# Étape 2 : Installer les bibliothèques requises
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # PyTorch optimisé GPU
pip install vllm huggingface-hub # vLLM pour servir MiniMax M1, et utilitaires Hugging Face
# Étape 3 : (Facultatif) Connectez-vous à Hugging Face si vous souhaitez récupérer des modèles plus tard
pip install huggingface-cli
huggingface-cli login # Suivez les invites pour vous authentifier
# Étape 4 : Télécharger le modèle MiniMax M1 (si ce n'est pas déjà fait)
# Remplacez <model-name> par le nom réel du dépôt MiniMax M1 sur Hugging Face
huggingface-cli download MiniMaxAI/MiniMax-M1-80k --local-dir ./minimax-m1
# Étape 5 : Définir une variable d'environnement pour un chargement rapide (Linux/macOS)
export SAFETENSORS_FAST_GPU=1
# Étape 6 : Lancer le serveur API MiniMax M1 avec vLLM
# Ajustez --tensor-parallel-size en fonction du nombre de vos GPU
python3 -m vllm.entrypoints.api_server \
--model ./minimax-m1 \
--tensor-parallel-size 8 \
--trust-remote-code \
--max_model_len 8192 \
--dtype bfloat16
# Étape 7 : Tester l'inférence avec curl (dans un nouveau terminal)
curl -X POST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"prompt": "Explain quantum computing in simple terms.", "max_tokens": 100}'
# Étape 8 : (Facultatif) Exemple d'inférence en Python
python3 -c "
import requests
response = requests.post('http://localhost:8000/generate', json={
'prompt': 'Explain quantum computing in simple terms.',
'max_tokens': 100
})
print(response.json())
"
Exigences de mémoire GPU :
- Minimum : 640 Go de VRAM
- Recommandé : 1 128 Go de VRAM (configuration 8 x H200 SXM 141 Go) pour des performances optimales
Connecter MiniMax M1 sur des plateformes tierces
- Hugging Face : Utilisez MiniMax M1 dans Spaces, pipelines ou avec la bibliothèque Transformers via les points de terminaison Novita AI.
- Frameworks d’agents et d’orchestration : Connectez facilement Novita AI à des plateformes partenaires comme Continue, AnythingLLM,LangChain, Dify et Langflow grâce à des connecteurs officiels et des guides d’intégration pas à pas.
- API compatible OpenAI : Profitez d’une migration et d’une intégration sans tracas avec des outils tels que Cline et Cursor, conçus pour le standard d’API OpenAI.
Novita AI est intégré à plus de 20 plateformes, et des tutoriels détaillés sont disponibles dans la documentation.
MiniMax M1 est un modèle de raisonnement hybride à grande échelle révolutionnaire qui excelle dans le traitement de longueurs de contexte ultra-longues et de tâches de raisonnement complexes. Il dispose d’une architecture hybride Mixture-of-Experts (MoE) combinée à un mécanisme d’attention lightning, permettant une inférence efficace et évolutive. Vous pouvez utiliser MiniMax M1 via l’API ou le connecter sur des plateformes tierces.
Pour une durée limitée, les nouveaux utilisateurs peuvent obtenir 10 $ de crédits gratuits pour explorer et construire avec l’API LLM sur Novita AI.
Foire aux questions
Comment utiliser MiniMax AI gratuitement ?
Vous pouvez essayer la démo de MiniMax AI gratuitement sur Novita AI. Les nouveaux utilisateurs peuvent obtenir 10 $ de crédits gratuits pour explorer et construire avec l’API LLM sur Novita AI.
Quel matériel est nécessaire pour exécuter MiniMax M1 en local ?
Minimum : 640 Go de VRAM
Recommandé : 1 128 Go de VRAM (configuration 8 x H200 SXM 141 Go) pour des performances optimales
MiniMax M1 est-il open-source ?
Oui, MiniMax M1 est entièrement open-source et disponible sur des plateformes comme Hugging Face.
À propos de Novita AI
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant également un cloud GPU abordable et fiable pour construire et faire évoluer.



