

GLM-4.7 ist ein großes Mixture-of-Experts (MoE)-„Thinking“-Modell, das für Reasoning, Coding, Tool-Nutzung und Long-Context-Workloads entwickelt wurde. Es ist jetzt bei Novita AI mit starker Leistung und wettbewerbsfähigen Preisen verfügbar.
💡 Highlights
- Wenn Sie den schnellsten Weg zur Produktion wünschen: Novita Model API
- Wenn Sie „lokale“ Kontrolle ohne Kauf von GPUs wünschen: Novita GPU Cloud
- Wenn Sie offline/on-prem ausführen müssen: Wählen Sie Lokal, aber erwarten Sie, auf Quantisierung + Offloading angewiesen zu sein.
Probieren Sie GLM-4.7 jetzt aus
GLM-4.7: Stärken und Einsatzbereiche
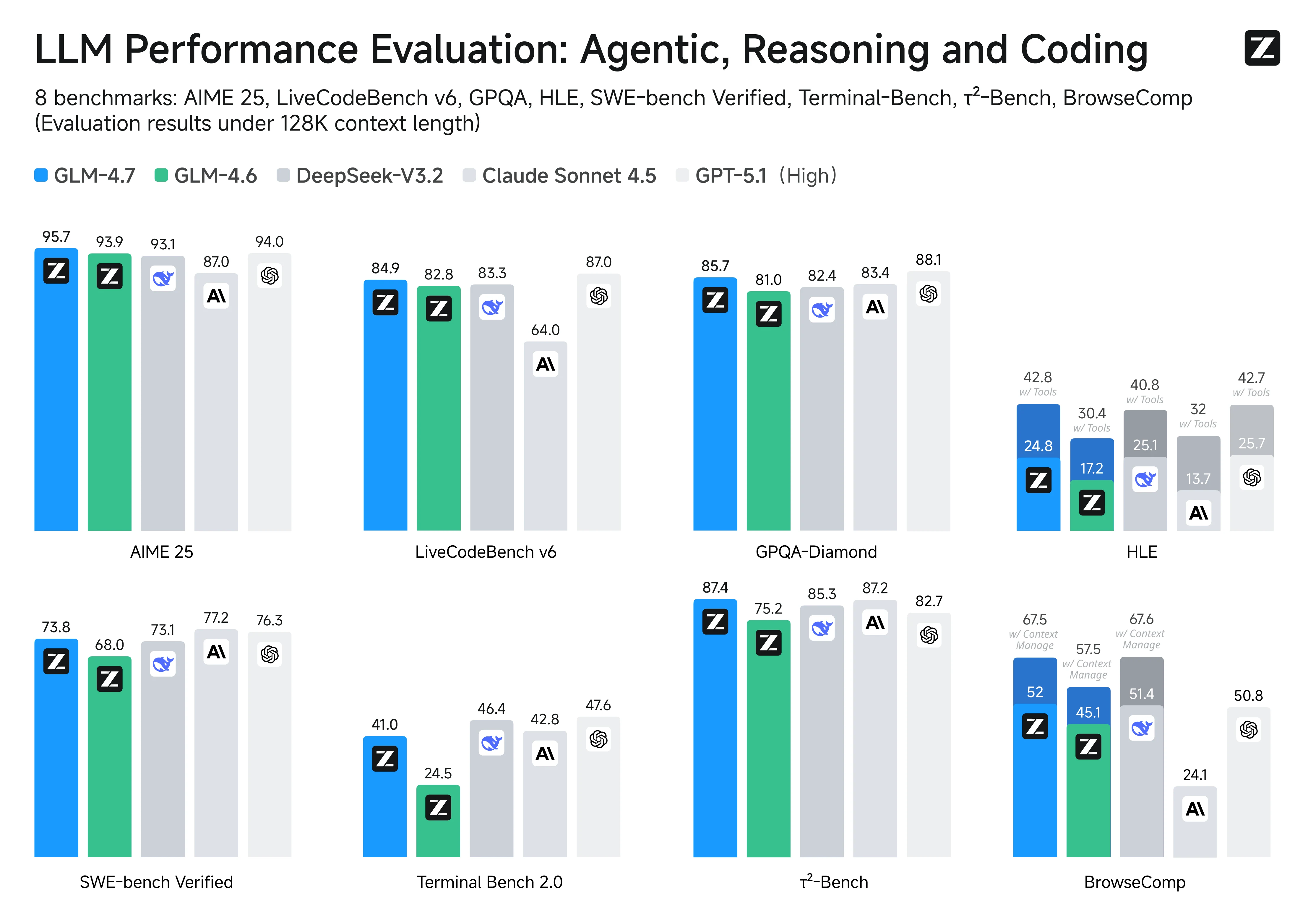
Bei wichtigen Coding- und Agenten-Benchmarks ist GLM-4.7 weitgehend auf Augenhöhe mit Claude Sonnet 4.5, und die Ergebnisse zeichnen ein klares Bild seiner Stärken:
- Softwareentwicklung auf Repository-Ebene: Beim SWE-bench Verified belegt GLM-4.7 mit 73,8 % (+5,8 % gegenüber GLM-4.6) den ersten Platz unter den Open-Source-Modellen. Dies deutet auf starke End-to-End-Fähigkeiten bei der Fehlerdiagnose, der Bearbeitung über Dateien hinweg und der Erstellung von testbestandenen Patches in echten Repositories hin.
- Hochwertige Codegenerierung: Beim LiveCodeBench v6 erreicht es einen Open-Source-SOTA-Wert von 84,9, der laut Berichten über dem von Claude Sonnet 4.5 liegt. Dies zeigt eine wettbewerbsfähige Leistung bei Coding-Aufgaben, die Wert auf Korrektheit und Implementierungsqualität legen.
- Sprachübergreifende Robustheit: Ein Ergebnis von 66,7 % beim SWE-bench Multilingual (+12,9 %) weist auf eine verbesserte Zuverlässigkeit hin, wenn der Repository-Kontext mehrere Programmiersprachen und sprachübergreifende Artefakte umfasst.
- Agentische Tool-Nutzung in der Praxis: Beim Terminal-Bench 2.0 erreicht es 41 % (+16,5 %), was deutliche Fortschritte bei mehrstufigen, toolgesteuerten Workflows hervorhebt – genau die Art von „Planen → Ausführen → Iterieren“-Schleife, die Sie bei CLI-basierten Coding-Agenten benötigen.
Warum VRAM der eigentliche Engpass ist
Auch wenn MoE-Modelle pro Token nur eine Teilmenge der Experten aktivieren, wird die lokale Inferenz immer noch größtenteils durch VRAM begrenzt, da die GPU mehr als nur „die Modelldatei“ speichern muss.
Was verbraucht tatsächlich VRAM?
- Modellgewichte: Quantisierung reduziert die Größe der Gewichte, aber sehr große MoE-Modelle bleiben dennoch sehr speicherintensiv.
- KV-Cache (Kontextspeicher): Der KV-Cache wächst schnell mit:
- Kontextlänge (8K → 32K → 128K),
- Nebenläufigkeit (parallele Sitzungen vervielfachen den Cache),
- Durchsatz-Einstellungen (Batching benötigt oft mehr Puffer).
- Laufzeit-Overhead: Framework-Puffer, temporäre Zuordnungen, Fragmentierung und Kernel-Arbeitsbereiche – oft mehrere GB.
Warum „es passt“ trotzdem zu OOM führen kann
Ein häufiger Fehlerfall: Die Gewichte passen gerade so in den VRAM, dann erhöhen Sie die Kontextlänge oder senden eine zweite Anfrage, und KV-Cache + Overhead bringen Sie über die Grenze → Out-of-Memory-Fehler oder schwerwiegendes CPU/RAM-Offloading (was die Geschwindigkeit stark einbrechen lassen kann).
Eine praktische Planungsregel
Streben Sie keine 100%ige VRAM-Nutzung durch die Gewichte an.
- Halten Sie Gewichte ≈ 70–80 % des VRAMs bei moderaten Kontexten
- Reservieren Sie 20–30 % Puffer für KV-Cache + Overhead
- Für 64K–128K-Kontext oder mehrere gleichzeitige Sitzungen reservieren Sie noch mehr Puffer
Option 1: GLM-4.7 lokal ausführen
Eine lokale Bereitstellung lohnt sich, wenn Sie offline/on-prem ausführen müssen oder volle Kontrolle über den gesamten Stack benötigen. In den meisten anderen Fällen ist es der Weg mit dem höchsten Aufwand und dem höchsten Wartungsaufwand.
Wie viel Speicher benötigt GLM-4.7? (GGUF-Varianten)
Die folgende Tabelle fasst GGUF-Varianten und die von Hugging Face Inference Endpoints angezeigten Speicherplatzschätzungen für die Bereitstellung zusammen.
Wichtig
- Größe = GGUF-Dateigröße (nur Gewichte; Speicherplatzbedarf)
- Speicheranforderungen = Bereitstellungsschätzung von HF Endpoints (Gewichte + Laufzeit-Overhead). Die tatsächlichen Anforderungen steigen mit Kontextlänge und Nebenläufigkeit.
| Bitbreite | Repräsentative Quantisierung | Größe | Speicherbedarf | Von HF empfohlene GPU | Gesamter VRAM |
|---|---|---|---|---|---|
| 1-Bit | TQ1_0 | 84,5 GB | 86 GB | Nvidia L4 × 4 | 96 GB |
| 2-Bit | Q2_K | 131 GB | 133 GB | Nvidia A100 × 2 | 160 GB |
| 3-Bit | Q3_K_M | 171 GB | 173 GB | Nvidia L40S × 4 | 192 GB |
| 4-Bit | Q4_K_M | 216 GB | 218 GB | Nvidia A100 × 4 | 320 GB |
| 5-Bit | Q5_K_M | 254 GB | 256 GB | Nvidia A100 × 4 | 320 GB |
| 6-Bit | Q6_K | 294 GB | 296 GB | Nvidia A100 × 4 | 320 GB |
| 8-Bit | Q8_0 | 381 GB | 383 GB | Nvidia A100 × 8 | 640 GB |
| 16-Bit | BF16 | 717 GB | 719 GB | Nvidia H200 × 8 | 1128 GB |
Wichtige lokale Einstellungen, die den Unterschied machen
Wenn Sie lokal betreiben, konzentrieren Sie sich auf drei Stellschrauben:
- Quantisierung (größter Hebel für VRAM-Einsparungen)
- Offloading (Verschieben einiger Schichten auf CPU/RAM)
- Kontextlänge (reduzieren Sie den Kontext zuerst, wenn Sie OOM-Fehler erhalten)
Option 2: Novita GPU Cloud
Wenn lokale Bereitstellung zu viel Infrastrukturarbeit bedeutet, ist die Novita GPU Cloud ein einfacher Mittelweg: Sie behalten einen „lokalen“ Workflow – Ihre Laufzeit, Ihren Inferenz-Stack, Ihre Benchmarking-Skripte – ohne GPUs kaufen oder Treiber, Ausfälle und Kapazität verwalten zu müssen.
Betriebsmodi
- GPU-Instanzen – GPU-VMs für langlaufende, reproduzierbare Workloads
- Serverlose GPUs – pro Sekunde abgerechnete Endpunkte, ideal für sprunghafte Nutzung
- Bare Metal – maximale Isolierung und die konsistenteste Leistung
Warum die GPU Cloud für GLM-4.7 gut geeignet ist Lokale Bereitstellungen sind normalerweise durch VRAM-Puffer (Gewichte + KV-Cache + Overhead) begrenzt, insbesondere bei langem Kontext oder hoher Nebenläufigkeit. Mit der GPU Cloud können Sie diese Einschränkungen auf echten Hardware-Stufen (24 GB / 48 GB / 80 GB+) testen – ohne die Hardware selbst zu besitzen.
Probieren Sie die GPU Cloud aus
Option 3: Novita Model API
Sobald Sie gesehen haben, wie schnell VRAM, Kontextlänge und Nebenläufigkeit zu Einschränkungen werden – lokal oder auf der GPU Cloud – ist der Novita Model API oft der Weg mit dem geringsten Widerstand.
Novita AI bietet Zugriff auf die GLM-4.7 API, sodass keine teure lokale Hardware benötigt wird, und gleichzeitig produktionsreife Inferenz im großen Maßstab bereitgestellt wird.
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen Melden Sie sich bei Ihrem Novita AI-Konto an (oder registrieren Sie sich) und navigieren Sie zur Modellbibliothek.
Schritt 2: GLM-4.7 auswählen Durchsuchen Sie die verfügbaren Modelle und wählen Sie GLM-4.7 entsprechend Ihren Workload-Anforderungen aus.
Schritt 3: Kostenlose Testversion starten Aktivieren Sie Ihre kostenlose Testversion, um die Reasoning-, Long-Context- und Kosten-Leistungs-Merkmale von GLM-4.7 kennenzulernen.
Schritt 4: API-Schlüssel abrufen Öffnen Sie die Einstellungsseite, um Ihren API-Schlüssel zur Authentifizierung zu generieren und zu kopieren.
Schritt 5: API installieren und aufrufen (Python-Beispiel) Unten finden Sie ein einfaches Beispiel für die Nutzung der Chat Completions API mit Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Diese Konfiguration ermöglicht es Ihnen, die Reasoning-Tiefe, Token-Nutzung und das Generierungsverhalten auf API-Ebene zu steuern. Dies ist besonders nützlich, wenn Sie turn-level „Thinking“ mit vorhersagbaren Kosten und Latenzzeiten kombinieren möchten, anstatt die Hardware an die VRAM-Anforderungen von GLM-4.7 anzupassen.
Fazit: Welche Option sollten Sie wählen?
Wählen Sie einen Bereitstellungspfad basierend auf Kontrolle, Betriebsaufwand und Skalierbarkeit:
| Option | Vorteile | Nachteile |
|---|---|---|
| Lokal | Volle Kontrolle, keine Kosten pro Token | Hardware-Grenzen + betriebliche Komplexität |
| GPU Cloud | Flexible Hardware, nahezu lokale Kontrolle | Treiber-/Laufzeitverwaltung + variable Kosten |
| API | Einfachster Weg, vorhersagbare Skalierbarkeit | Geringere low-level-Kontrolle |
Entscheidungsbaum
- Wählen Sie Lokal, wenn Sie offline/on-prem ausführen müssen oder volle Kontrolle über Daten + Infrastruktur benötigen.
- Wählen Sie GPU Cloud, wenn Sie reproduzierbare Benchmarks und Kontrolle ohne eigene GPUs wünschen.
- Wählen Sie API, wenn Sie den einfachsten Weg zur Produktion mit minimalem Betriebsaufwand wünschen.
GLM‑4.7 ist extrem leistungsfähig, aber lokale Bereitstellungen stoßen schnell an VRAM-Grenzen, sobald Sie langen Kontext und hohe Nebenläufigkeit nutzen. Für die meisten Teams ist der praktischste Weg, mit klaren Erwartungen an die Hardware-Stufen zu beginnen, auf der Novita GPU Cloud zu experimentieren und dann entweder dort zu bleiben oder zur OpenAI‑kompatiblen API von Novita zu wechseln, um den Weg zur Produktion mit dem geringsten Betriebsaufwand zu gehen.
Häufig gestellte Fragen
Was ist VRAM in einem Computer? VRAM ist Hochgeschwindigkeitsspeicher, der an Ihre GPU angebunden ist. Für die KI-Inferenz speichert er Modellgewichte, KV-Cache und Zwischenpuffer.
Wie überprüfe ich meinen VRAM?
- Windows: Task-Manager → Leistung → GPU
- macOS: Über diesen Mac → Systembericht → Grafik/Displays
- Linux:
nvidia-smi
Wie viel VRAM benötige ich für KI-Modelle? Für die meisten Nutzer reichen 8–12 GB VRAM für kleine Modelle und leichte Workloads aus, aber größere Modelle im Frontier-Stil benötigen normalerweise 16–24 GB oder mehr, insbesondere wenn Sie eine angemessene Geschwindigkeit und Kontextlänge wünschen.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanzen – die kostengünstigen Tools, die Sie benötigen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



