

GLM-4.7 هو نموذج تفكير كبير من نوع Mixture-of-Experts (MoE) مصمم للاستدلال، البرمجة، استخدام الأدوات، وأحمال العمل ذات السياقات الطويلة. وهو متاح الآن على Novita AI بأداء قوي وأسعار تنافسية.
عند محاولة تشغيل GLM-4.7 محليًا، يكون الاختناق الأول عادةً هو الذاكرة، وليس قوة المعالجة الخام—خاصةً ذاكرة الفيديو (VRAM) للوحدة المعالجة الرسومية، بالإضافة إلى ذاكرة الوصول العشوائي للنظام (RAM) المطلوبة لتفريغ البيانات في عمليات نشر MoE العملية.
💡 أبرز النقاط
- إذا كنت تريد أسرع مسار للإنتاج: واجهة برمجة تطبيقات Novita للنماذج
- إذا كنت تريد تحكمًا “بنمط محلي” دون شراء وحدات معالجة رسومية: سحابة Novita GPU
- إذا كان يجب عليك التشغيل بدون اتصال / على الموقع: اختر محلي، ولكن توقع الاعتماد على الضبط الكمي + التفريغ
GLM-4.7: ما هي نقاط قوته؟
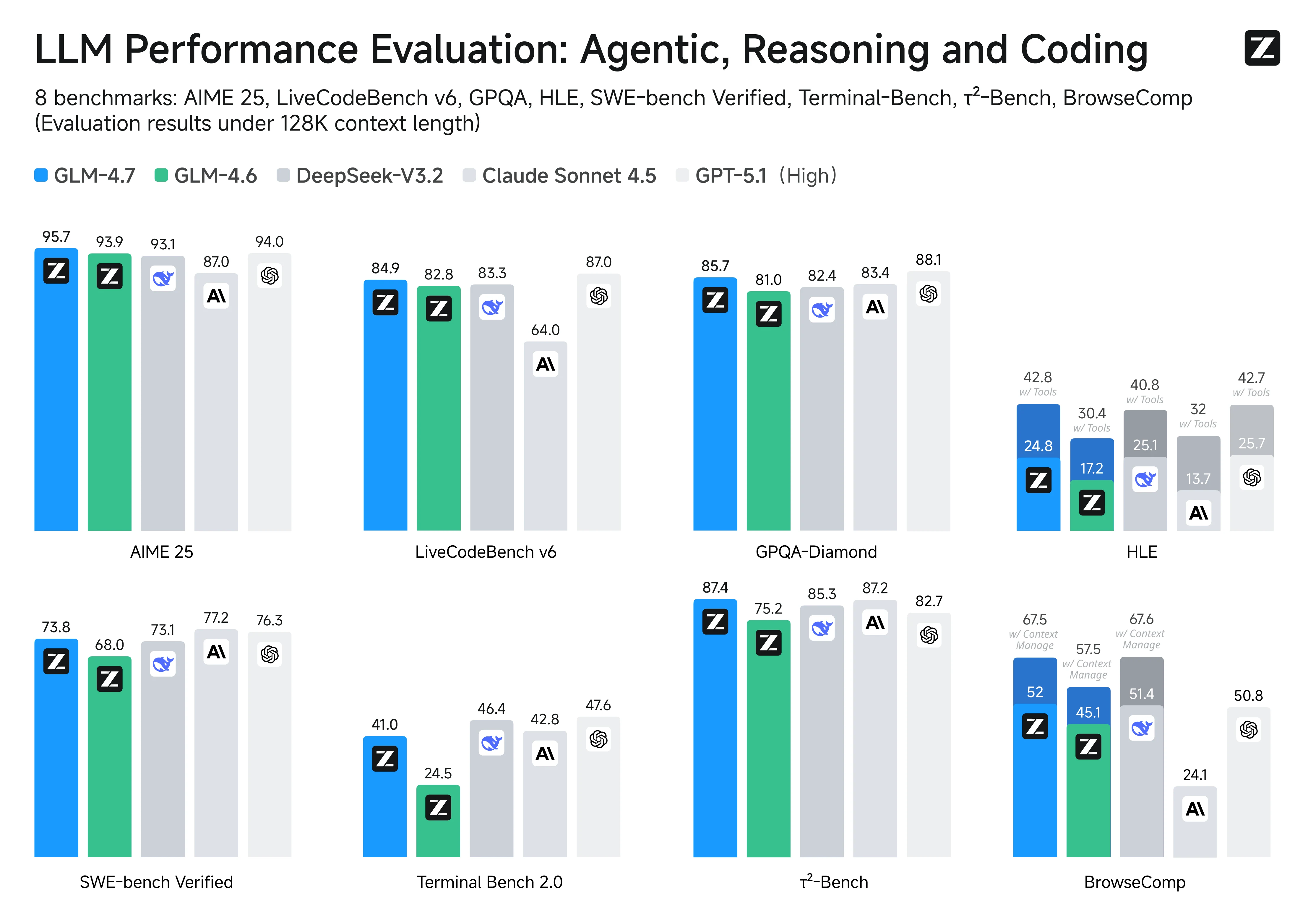
عبر معايير البرمجة والوكلاء الرئيسية، يأتي GLM-4.7 في مستوى متساوٍ بشكل عام مع Claude Sonnet 4.5، وتوضح النتائج بشكل واضح نقاط قوته:
- هندسة البرمجيات على مستوى المستودعات: في اختبار SWE-bench Verified، يحتل GLM-4.7 المرتبة الأولى بين النماذج مفتوحة المصدر بنسبة 73.8% (بزيادة 5.8% مقارنة بـ GLM-4.6)، مما يشير إلى قدرة قوية من البداية إلى النهاية لتشخيص المشكلات، التعديل عبر الملفات، وإنتاج تصحيحات تجتاز الاختبارات في المستودعات الحقيقية.
- توليد كود عالي الجودة: في اختبار LiveCodeBench v6، يصل إلى أفضل أداء مفتوح المصدر (SOTA) بنسبة 84.9، ويُقال إنه يتفوق على Claude Sonnet 4.5، مما يدل على أداء تنافسي في مشاكل البرمجة التي تركز على الصحة وجودة التنفيذ.
- متانة عبر اللغات: نتيجة 66.7% في اختبار SWE-bench Multilingual (بزيادة 12.9%) تشير إلى موثوقية محسنة عندما يمتد سياق المستودع عبر عدة لغات برمجة و artifacts مختلطة اللغات.
- استخدام الأدوات من قبل الوكلاء في الممارسة العملية: نتيجة 41% في اختبار Terminal-Bench 2.0 (بزيادة 16.5%) تسلط الضوء على مكاسب معنوية في سير العمل متعددة الخطوات المعتمدة على الأدوات—وهو بالضبط نوع حلقة “التخطيط → التنفيذ → التكرار” التي تريدها في وكلاء البرمجة المعتمدين على واجهة سطر الأوامر.
لماذا تعتبر ذاكرة الفيديو (VRAM) الاختناق الحقيقي؟
على الرغم من أن نماذج MoE تفعّل فقط مجموعة فرعية من الخبراء لكل رمز، فإن الاستدلال المحلي لا يزال مقيدًا في الغالب بذاكرة الفيديو (VRAM) لأن الوحدة المعالجة الرسومية يجب أن تحمل أكثر من مجرد “ملف النموذج”.
ما الذي يستهلك ذاكرة الفيديو (VRAM) في الواقع؟
- أوزان النموذج يقلل الضبط الكمي من حجم الأوزان، لكن نماذج MoE الكبيرة جدًا تظل ثقيلة.
- ذاكرة التخزين المؤقت KV (ذاكرة السياق) تنمو ذاكرة التخزين المؤقت KV بسرعة مع:
- طول السياق (8K ← 32K ← 128K),
- التزامن (الجلسات المتوازية تضاعف الذاكرة المؤقتة),
- إعدادات الإنتاجية (الدفعات غالبًا تحتاج إلى مساحة إضافية أكبر).
- النفقات العامة للوقت التشغيلي مخازن مؤقتة للأطر، تخصيصات مؤقتة، تجزئة، ومساحات عمل النواة—غالبًا عدة جيجابايت.
لماذا يمكن أن يحدث خطأ نفاد الذاكرة (OOM) حتى لو “تناسب النموذج”
وضع فشل شائع: تتلاءم الأوزان بالكاد مع ذاكرة الفيديو، ثم تزيد من طول السياق أو تشغيل طلب ثاني وتدفعك ذاكرة التخزين المؤقت KV + النفقات العامة إلى تجاوز الحد → أخطاء نفاد الذاكرة أو تفريغ ثقيل لوحدة المعالجة المركزية / الذاكرة العشوائية (الذي يمكن أن يقلل السرعة بشكل كبير).
قاعدة تخطيط عملية
لا تهدف إلى استخدام 100% من ذاكرة الفيديو من قبل الأوزان.
- احتفظ بـ الأوزان ≈ 70-80% من ذاكرة الفيديو للسياقات المتوسطة
- احجز هامش 20-30% لذاكرة التخزين المؤقت KV + النفقات العامة
- بالنسبة لـ سياق 64K-128K أو جلسات متزامنة متعددة، احجز هامشًا إضافيًا أكبر
الخيار 1: تشغيل GLM-4.7 محليًا
يستحق النشر المحلي عندما يجب عليك التشغيل بدون اتصال / على الموقع أو تحتاج إلى تحكم كامل في المكدس بالكامل. في معظم الحالات الأخرى، هو المسار الذي يتطلب أعلى جهد وأعلى صيانة.
كم ذاكرة يحتاجها GLM-4.7؟ (متغيرات GGUF)
يلخص الجدول أدناه متغيرات GGUF وتقديرات ذاكرة النشر التي تظهرها نقاط نهاية الاستدلال من Hugging Face.
هام
- الحجم = حجم ملف GGUF (الأوزان فقط؛ بصمة التخزين)
- متطلبات الذاكرة = تقدير نشر نقاط نهاية HF (الأوزان + النفقات العامة للوقت التشغيلي)
تزداد المتطلبات الفعلية مع طول السياق و التزامن.
| عرض البت | الضبط الكمي الممثل | الحجم | متطلبات الذاكرة | وحدة المعالجة الرسومية المقترحة من HF | إجمالي ذاكرة الفيديو |
|---|---|---|---|---|---|
| 1 بت | TQ1_0 | 84.5 GB | 86 GB | Nvidia L4 × 4 | 96 GB |
| 2 بت | Q2_K | 131 GB | 133 GB | Nvidia A100 × 2 | 160 GB |
| 3 بت | Q3_K_M | 171 GB | 173 GB | Nvidia L40S × 4 | 192 GB |
| 4 بت | Q4_K_M | 216 GB | 218 GB | Nvidia A100 × 4 | 320 GB |
| 5 بت | Q5_K_M | 254 GB | 256 GB | Nvidia A100 × 4 | 320 GB |
| 6 بت | Q6_K | 294 GB | 296 GB | Nvidia A100 × 4 | 320 GB |
| 8 بت | Q8_0 | 381 GB | 383 GB | Nvidia A100 × 8 | 640 GB |
| 16 بت | BF16 | 717 GB | 719 GB | Nvidia H200 × 8 | 1128 GB |
أدوات التحكم المحلية الأساسية التي تهمك
إذا اخترت التشغيل المحلي، ركز على ثلاث أدوات تحكم:
- الضبط الكمي (أكبر أداة لتقليل استهلاك ذاكرة الفيديو)
- التفريغ (نقل بعض الطبقات إلى وحدة المعالجة المركزية / الذاكرة العشوائية)
- طول السياق (قلل السياق أولاً إذا حدث خطأ نفاد الذاكرة OOM)
الخيار 2: سحابة Novita GPU
إذا كان التشغيل المحلي يبدو وكأنه عمل بنية تحتية مرهق، فإن سحابة Novita GPU هي مسار وسيط نظيف: تحافظ على سير عمل “بنمط محلي”—بيئة التشغيل الخاصة بك، مكدس الاستدلال الخاص بك، نصوص اختبار الأداء الخاصة بك—دون شراء وحدات معالجة رسومية أو إدارة برامج التشغيل، الأعطال، والسعة.
الأوضاع
- مثيلات لوحدة المعالجة الرسومية — أجهزة افتراضية للوحدة المعالجة الرسومية لأحمال العمل طويلة الأمد والقابلة للتكرار
- وحدات معالجة رسومية بدون خادم — نقاط نهاية بالثانية مثالية للاستخدام المتقطع
- معادن عارية — أقصى درجات العزل وأداء متسق للغاية
لماذا تعمل سحابة GPU بشكل جيد مع GLM-4.7
عمليات النشر المحلية مقيدة عادةً بهامش ذاكرة الفيديو (الأوزان + ذاكرة التخزين المؤقت KV + النفقات العامة)، خاصة مع السياقات الطويلة أو التزامن. تتيح لك سحابة GPU اختبار هذه القيود عبر مستويات أجهزة حقيقية (24 جيجابايت / 48 جيجابايت / 80 جيجابايت+)—دون امتلاك الأجهزة.
الخيار 3: واجهة برمجة تطبيقات Novita للنماذج
بمجرد أن ترى مدى سرعة تحول ذاكرة الفيديو، طول السياق، والتزامن إلى قيود—محليًا أو على سحابة GPU—فإن المسار الأقل احتكاكًا هو غالبًا واجهة برمجة تطبيقات Novita للنماذج.
استخدم GLM 4.7 عبر واجهة برمجة التطبيقات
تقدم Novita AI وصولًا إلى واجهة برمجة تطبيقات GLM-4.7، مما يلغي الحاجة إلى أجهزة محلية باهظة الثمن مع توفير استدلال جاهز للإنتاج على نطاق واسع.
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج سجل الدخول (أو أنشئ حسابًا جديدًا) إلى حساب Novita AI الخاص بك وانتقل إلى مكتبة النماذج.
الخطوة 2: اختر GLM-4.7 تصفح النماذج المتاحة واختر GLM-4.7 بناءً على متطلبات أحمال العمل الخاصة بك.
الخطوة 3: ابدأ تجربتك المجانية فعّل تجربتك المجانية لاستكشاف خصائص الاستدلال، السياقات الطويلة، والتكلفة-الأداء لـ GLM-4.7.
الخطوة 4: احصل على مفتاح واجهة برمجة التطبيقات الخاص بك افتح صفحة الإعدادات لإنشاء ونسخ مفتاح واجهة برمجة التطبيقات الخاص بك للمصادقة.
الخطوة 5: تثبيت واستدعاء واجهة برمجة التطبيقات (مثال بلغة Python) أدناه مثال بسيط باستخدام واجهة برمجة تطبيقات إكمال الدردشة مع Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
يتيح لك هذا الإعداد التحكم في عمق الاستدلال، استخدام الرموز، وسلوك التوليد على مستوى واجهة برمجة التطبيقات—مفيد بشكل خاص عندما تريد دمج “التفكير” على مستوى الدور مع تكلفة وزمن استجابة متوقعين، بدلاً من تحديد حجم الأجهزة بناءً على احتياجات ذاكرة الفيديو لـ GLM-4.7.
الخلاصة: أي خيار يجب أن تختاره؟
اختر مسار نشر بناءً على التحكم مقابل جهد التشغيل مقابل القابلية للتوسع:
| الخيار | المزايا | العيوب |
|---|---|---|
| محلي | تحكم كامل، لا توجد تكلفة لكل رمز | قيود الأجهزة + تعقيد تشغيلي |
| سحابة GPU | أجهزة مرنة، تحكم شبه محلي | إدارة برامج التشغيل / بيئة التشغيل + تكاليف متغيرة |
| واجهة برمجة التطبيقات | أبسط مسار، توسع متوقع | تحكم منخفض المستوى أقل |
شجرة القرار
- اختر محلي إذا كان يجب عليك التشغيل بدون اتصال / على الموقع أو تحتاج إلى تحكم كامل في البيانات + البنية التحتية.
- اختر سحابة GPU إذا كنت تريد اختبار أداء قابل للتكرار وتحكم دون امتلاك وحدات معالجة رسومية.
- اختر واجهة برمجة التطبيقات إذا كنت تريد أبسط مسار للإنتاج مع أقل نفقات تشغيلية.
GLM-4.7 قادر للغاية، لكن عمليات النشر المحلية تواجه قيود ذاكرة الفيديو بمجرد دفع السياقات الطويلة والتزامن العالي؛ لمعظم الفرق، المسار الأكثر عملية هو البدء بتوقعات مستوى واضحة، التجربة على سحابة Novita GPU، ثم إما البقاء هناك أو الانتقال إلى واجهة برمجة تطبيقات Novita المتوافقة مع OpenAI لأقل مسار تشغيلي للإنتاج.
الأسئلة الشائعة
ما هي ذاكرة الفيديو (VRAM) في الكمبيوتر؟
ذاكرة الفيديو هي ذاكرة عالية السرعة متصلة بوحدة المعالجة الرسومية الخاصة بك. للاستدلال في الذكاء الاصطناعي، تحمل أوزان النموذج، ذاكرة التخزين المؤقت KV، والمخازن المؤقتة الوسيطة.
كيف أتحقق من ذاكرة الفيديو الخاصة بي؟
Windows: إدارة المهام → الأداء → وحدة المعالجة الرسومية
macOS: حول هذا Mac → تقرير النظام → الرسومات / الشاشات
Linux: nvidia-smi
كم ذاكرة فيديو أحتاجها لنماذج الذكاء الاصطناعي؟
للمستخدمين الأغلبية، تعتبر ذاكرة الفيديو 8-12 جيجابايت كافية للنماذج الصغيرة وأحمال العمل الخفيفة، لكن النماذج الكبيرة من نوع frontier تحتاج عادةً إلى 16-24 جيجابايت أو أكثر، خاصة إذا كنت تريد سرعة جيدة وطول سياق مقبول.
Novita AI هي منصة سحابية شاملة تمكّن طموحاتك في الذكاء الاصطناعي. واجهات برمجة تطبيقات متكاملة، بدون خادم، مثيلات لوحدة المعالجة الرسومية — الأدوات فعالة التكلفة التي تحتاجها. أزل البنية التحتية، ابدأ مجانًا، وحقق رؤيتك في الذكاء الاصطناعي.



