

GLM-4.7 是大型混合專家(MoE)「思考型」模型,專為推理、編程、工具使用與長上下文工作負載設計,現在已在 Novita AI 上線,效能優異且定價具競爭力。
當你嘗試在本地運行 GLM-4.7 時,第一個瓶頸通常是記憶體,而非原始運算能力——尤其是GPU VRAM,再加上實用 MoE 部署中用於卸載的系統記憶體。
💡重點
- 若想最快上線生產環境:Novita 模型 API
- 若想要「本地級控制權」又不想購買 GPU:Novita GPU 雲端
- 若必須離線/本地部署:選擇本地,但需要依賴量化 + 卸載技術
GLM-4.7:核心優勢
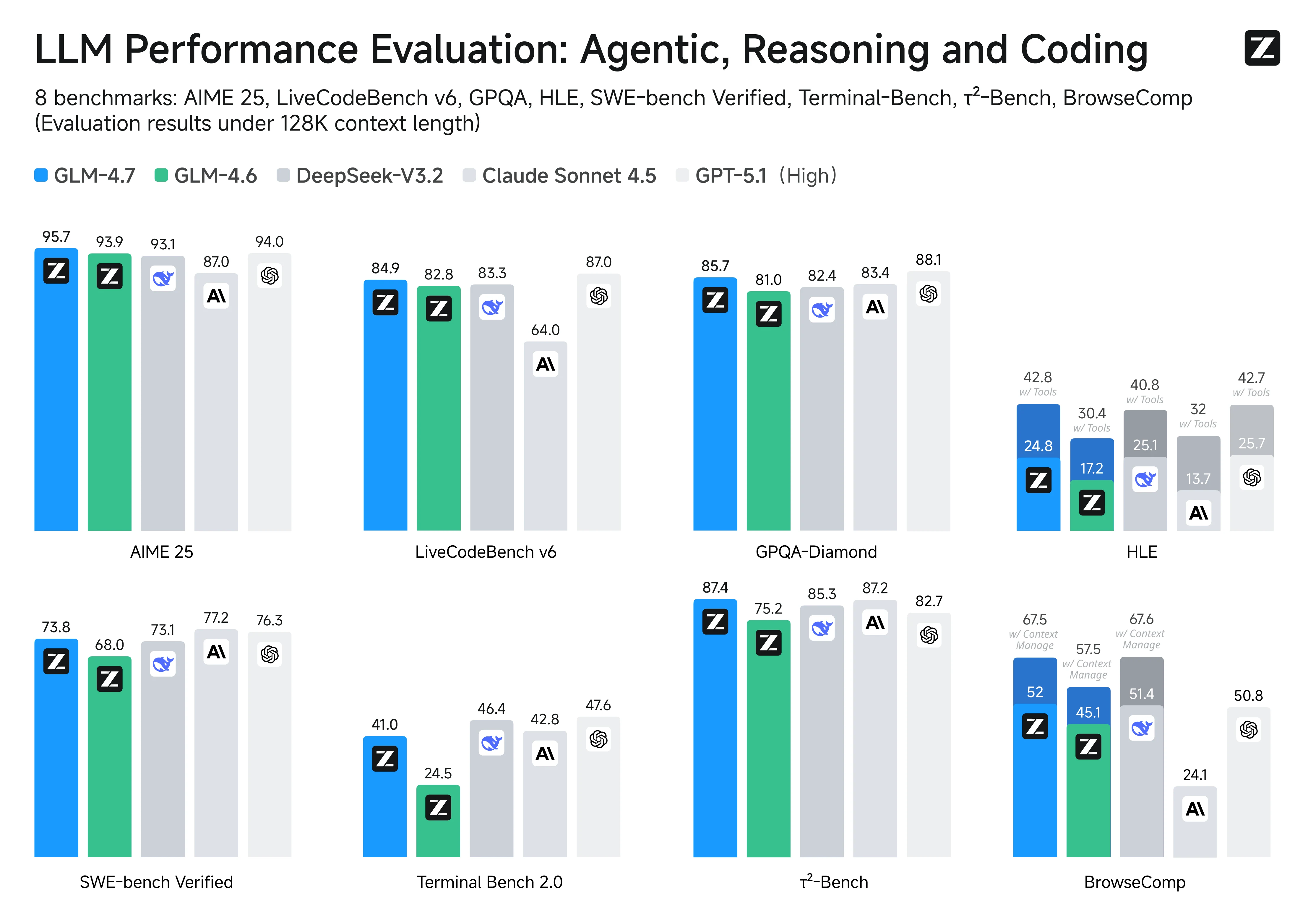
在主流編程與智能體基準測試中,GLM-4.7 的表現與 Claude Sonnet 4.5 基本持平,分數清楚展現了它的核心優勢:
- 倉庫級軟體工程: 在 SWE-bench Verified 測試中,GLM-4.7 以 73.8% 的分數位列開源模型第一(較 GLM-4.6 提升 5.8%),展現了在真實倉庫中診斷問題、跨文件編輯、生成可通過測試的補丁的端到端能力。
- 高品質程式碼生成: 在 LiveCodeBench v6 測試中達到 84.9 分的開源 SOTA(state-of-the-art)成績,據報導超過 Claude Sonnet 4.5,在強調正確性與實作品質的編程問題上表現具有競爭力。
- 跨語言穩定性: 在 SWE-bench 多語言測試中獲得 66.7% 的分數(提升 12.9%),在倉庫上下文涵蓋多種程式語言與混合語言產物時,可靠性有所提升。
- 實用智能體工具使用: Terminal-Bench 2.0 測試中得分 41%(提升 16.5%),在多步驟、工具驅動的工作流程中實現了明顯提升,正是 CLI 編程智能體所需的「規劃 → 執行 → 迭代」循環所需的效能。
為什麼 VRAM 是真正的瓶頸
即使 MoE 模型每個 token 只激活部分專家,本地推理仍主要受 VRAM 限制,因為 GPU 需要儲存的不仅是「模型檔案」。
什麼實際消耗 VRAM?
- 模型權重:量化可以降低權重大小,但超大型 MoE 模型仍然非常佔空間。
- KV 快取(上下文記憶體):KV 快取會隨以下因素快速增長:
- 上下文長度(8K → 32K → 128K),
- 並發數(並行工作階段會倍增快取需求),
- 吞吐量設定(批次處理通常需要更多緩衝空間)。
- 執行階段開銷:框架緩衝區、臨時分配、記憶體碎片、核心工作空間——通常就佔用數 GB。
為什麼「裝得下」還是會出現記憶體不足(OOM)?
常見的失敗場景:權重勉強塞進 VRAM,之後你增加上下文長度或運行第二個請求,KV 快取 + 開銷就會超過限制 → 觸發記憶體不足錯誤,或大量使用 CPU/RAM 卸載(會嚴重拖慢速度)。
實用規劃原則
不要讓權重佔用 100% 的 VRAM。
- 中等上下文場景下,權重佔用保持在 VRAM 的 70–80%
- 保留 20–30% 的緩衝空間給 KV 快取 + 開銷
- 對於 64K–128K 上下文或多個並發工作階段,需要保留更多緩衝空間
選項 1:本地運行 GLM-4.7
本地部署適合必須離線/本地部署、或需要對整個技術棧有完全控制權的場景,大多數其他情況下,這是投入最高、維護成本最高的路徑。
GLM-4.7 需要多少記憶體?(GGUF 變體)
下表總結了 GGUF 變體與 Hugging Face 推論端點顯示的部署記憶體估算:
重要提示
- 大小 = GGUF 檔案大小(僅權重;儲存佔用空間)
- 記憶體需求 = HF 推論端點部署估算(權重 + 執行階段開銷) 實際需求會隨上下文長度和並發數增加而上升。
| 位元寬度 | 代表性量化 | 大小 | 記憶體需求 | HF 建議 GPU | 總 VRAM |
|---|---|---|---|---|---|
| 1-bit | TQ1_0 | 84.5 GB | 86 GB | Nvidia L4 × 4 | 96 GB |
| 2-bit | Q2_K | 131 GB | 133 GB | Nvidia A100 × 2 | 160 GB |
| 3-bit | Q3_K_M | 171 GB | 173 GB | Nvidia L40S × 4 | 192 GB |
| 4-bit | Q4_K_M | 216 GB | 218 GB | Nvidia A100 × 4 | 320 GB |
| 5-bit | Q5_K_M | 254 GB | 256 GB | Nvidia A100 × 4 | 320 GB |
| 6-bit | Q6_K | 294 GB | 296 GB | Nvidia A100 × 4 | 320 GB |
| 8-bit | Q8_0 | 381 GB | 383 GB | Nvidia A100 × 8 | 640 GB |
| 16-bit | BF16 | 717 GB | 719 GB | Nvidia H200 × 8 | 1128 GB |
本地部署的關鍵調整項
如果選擇本地部署,重點關注三個參數:
- 量化(最大的 VRAM 調節項)
- 卸載(將部分層轉移到 CPU/RAM)
- 上下文長度(如果出現 OOM 優先減少上下文長度)
選項 2:Novita GPU 雲端
如果覺得本地部署基礎設施工作量太大,Novita GPU 雲端是完美的中間路徑:你可以保留「本地級」的工作流程——自己的執行環境、推理技術棧、基準測試腳本——無需購買 GPU、管理驅動、處理故障與容量問題。
運行模式
- GPU 實例:適用於長期運行、可重複的工作負載的 GPU 虛擬機
- 無伺服器 GPU:按秒計費的端點,適合突發性使用場景
- 裸金屬伺服器:最高隔離等級,效能最穩定
為什麼 GPU 雲端適合運行 GLM-4.7 本地部署通常受 VRAM 緩衝空間限制(權重 + KV 快取 + 開銷),尤其是長上下文或高並發場景。GPU 雲端讓你可以跨真實硬體層級(24GB / 48GB / 80GB+)測試這些限制,無需購買硬體。
選項 3:Novita 模型 API
當你發現本地或 GPU 雲端部署中,VRAM、上下文長度、並發數很快就會成為限制時,最低門檻的路徑通常是 Novita 模型 API。
Novita AI 提供 GLM-4.7 API 存取,無需昂貴的本地硬體,即可提供可擴展的生產級推理。
步驟 1:登入並存取模型庫
登入(或註冊)你的 Novita AI 帳號,導航至模型庫。
步驟 2:選擇 GLM-4.7
瀏覽可用模型,根據你的工作負載需求選擇 GLM-4.7。
步驟 3:開始免費試用
啟用免費試用,探索 GLM-4.7 的推理、長上下文與性價比特性。
步驟 4:獲取 API 金鑰
打開設定頁面,生成並複製你的 API 金鑰用於身份驗證。
步驟 5:安裝並呼叫 API(Python 範例)
以下是一個使用 Python 呼叫聊天補全 API 的簡單範例:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
這個設定讓你可以從 API 層級控制推理深度、token 使用量與生成行為——尤其適合當你想要結合回合級「思考」功能與可預測的成本與延遲,而不是根據 GLM-4.7 的 VRAM 需求來配置硬體時。
結論:你該選擇哪個選項?
根據控制權、運維成本與擴展性來選擇部署路徑:
| 選項 | 優點 | 缺點 |
|---|---|---|
| 本地 | 完全控制,無 per-token 成本 | 硬體限制 + 運維複雜度 |
| GPU 雲端 | 硬體靈活,接近本地控制權 | 驅動/執行環境管理 + 可變成本 |
| API | 最簡單的路徑,可預測的擴展性 | 低階控制權較少 |
決策樹
- 若必須離線/本地部署,或需要對資料 + 基礎設施有完全控制權,選擇本地
- 若想要可重複的基準測試與控制權,又不想購買 GPU,選擇**GPU 雲端**
- 若想要最簡單的上線生產路徑,運維開銷最低,選擇**API**
GLM-4.7 能力非常強,但本地部署在應對長上下文與高並發時會遇到 VRAM 限制;對大多數團隊而言,最務實的路徑是先明確分級預期,在 Novita GPU 雲端上進行測試,之後要么留在該平台,要么遷移到 Novita 的 OpenAI 相容 API,走運維成本最低的上線生產路徑。
常見問題
什麼是電腦中的 VRAM?
VRAM 是附在 GPU 上的高速記憶體,用於 AI 推理時儲存模型權重、KV 快取與中間緩衝區。
如何查看我的 VRAM?
Windows:工作管理員 → 效能 → GPU
macOS:關於這台 Mac → 系統報告 → 圖形/顯示器
Linux:nvidia-smi
AI 模型需要多少 VRAM?
對大多數用戶而言,8–12GB VRAM 足夠運行小型模型與輕度工作負載,但更大的前沿級模型通常需要 16–24GB 或更多的 VRAM,尤其是當你要求不錯的速度與上下文長度時。
Novita AI 是全方位雲端平台,助力你實現 AI 抱負。整合 API、無伺服器、GPU 實例——你需要的成本效益工具。消除基礎設施負擔,免費開始,將你的 AI 願景化為現實。



