

GLM-4.7は、推論、コーディング、ツール利用、長文脈ワークロード向けに構築された大規模Mixture-of-Experts(MoE)「思考」モデルです。現在Novita AIで利用可能で、強力なパフォーマンスと競争力のある価格設定が特徴です。
GLM-4.7をローカルで実行しようとすると、最初のボトルネックは通常、生の計算能力ではなくメモリ、特にGPU VRAM、そして実用的なMoEデプロイにおけるオフロードに必要なシステムRAMになります。
💡ハイライト
-
本番環境への最速のパスを求めるなら:Novita Model API
-
GPUを購入せずに「ローカル的な制御」を求めるなら:Novita GPU Cloud
-
オフライン/オンプレミスで実行する必要があるなら:ローカルへ。ただし、量子化+オフロードに依存することになります。
GLM-4.7:得意なこと
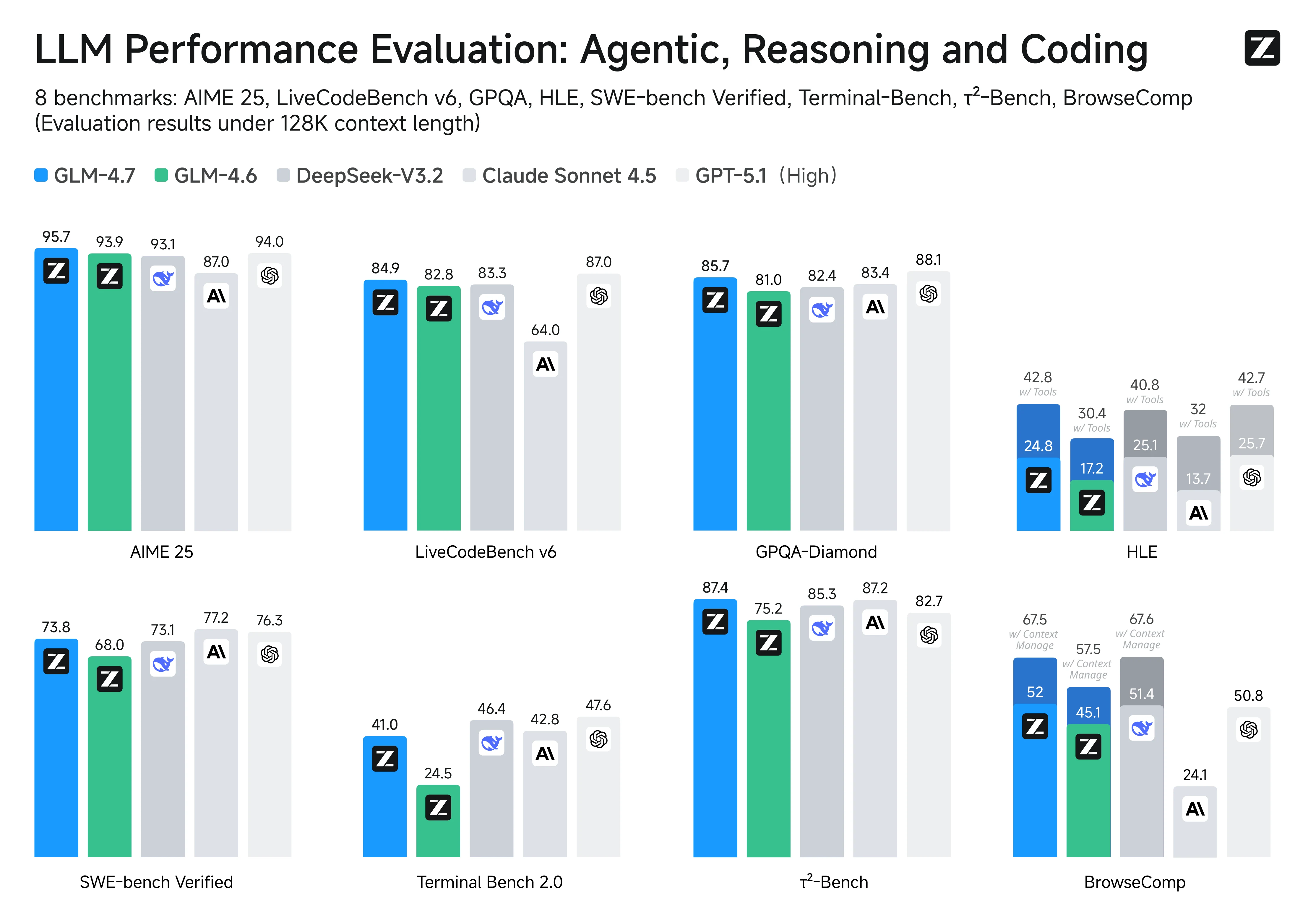
主要なコーディングおよびエージェントベンチマークにおいて、GLM-4.7はClaude Sonnet 4.5と概ね同等の性能と位置づけられており、スコアからその強みが明確に見えます:
- リポジトリレベルのソフトウェアエンジニアリング: SWE-bench Verifiedでは、GLM-4.7がオープンソースモデルの中で73.8%(GLM-4.6比+5.8%)で第1位。これは、実際のリポジトリで問題を診断し、ファイルを横断して編集し、テストを通すパッチを生成するエンドツーエンドの高い能力を示しています。
- 高品質なコード生成: LiveCodeBench v6では、オープンソースのSOTAである84.9を達成。Claude Sonnet 4.5を上回ると報告されており、正確性と実装品質を重視するコーディング問題で競争力のあるパフォーマンスを示しています。
- 言語間の堅牢性: SWE-bench Multilingualで66.7%(+12.9%)のスコアは、リポジトリのコンテキストが複数のプログラミング言語や混合言語のアーティファクトにまたがる場合の信頼性向上を示しています。
- 実際のエージェント的ツール使用: Terminal-Bench 2.0で41%(+16.5%)は、マルチステップのツール駆動型ワークフロー、まさにCLIベースのコーディングエージェントに求められる「計画→実行→反復」のループにおいて有意な改善を示しています。
VRAMが真のボトルネックである理由
MoEモデルはトークンごとに一部のエキスパートのみを活性化しますが、ローカル推論は依然として主にVRAMによって制限されます。なぜなら、GPUは「モデルファイル」以上のものを保持する必要があるからです。
実際にVRAMを消費するもの
- モデルウェイト 量子化によりウェイトサイズは減少しますが、非常に大規模なMoEモデルは依然として重いままです。
- KVキャッシュ(コンテキストメモリ) KVキャッシュは次の要因で急速に増加します:
- コンテキスト長(8K → 32K → 128K)、
- 同時実行性(並列セッションがキャッシュを倍増)、
- スループット設定(バッチ処理には通常、より多くの余裕が必要)。
- ランタイムオーバーヘッド フレームワークバッファ、一時的な割り当て、断片化、カーネルワークスペース — 多くの場合、数GBに及びます。
「収まる」がOOMになる理由
よくある失敗パターン:ウェイトがかろうじてVRAMに収まる → コンテキスト長を増やすか、2つ目のリクエストを実行すると、KVキャッシュ+オーバーヘッドが限界を超える → メモリ不足エラー、または大幅なCPU/RAMオフロード(速度が大幅に低下する可能性あり)。
実用的な計画のルール
ウェイトでVRAMの100%を目指さないでください。
- 中程度のコンテキストでは、ウェイト ≈ VRAMの70~80% に保つ
- KVキャッシュ+オーバーヘッドのために 20~30%の余裕 を確保
- 64K~128Kコンテキスト または 複数の同時セッション の場合は、さらに余裕を確保
オプション1:ローカルでGLM-4.7を実行する
ローカルデプロイは、オフライン/オンプレミスで実行する必要がある場合、またはスタック全体を完全に制御する必要がある場合に価値があります。それ以外のほとんどの状況では、最も労力がかかり、メンテナンス負荷が高いパスです。
GLM-4.7にはどのくらいのメモリが必要か?(GGUFバリアント)
以下の表は、GGUFバリアントとHugging Face Inference Endpointsが示すデプロイメントメモリ推定値をまとめたものです。
重要
- サイズ = GGUFファイルサイズ(ウェイトのみ;ストレージ容量)
- メモリ要件 = HF Endpointsのデプロイ推定値(ウェイト+ランタイムオーバーヘッド)
実際の要件は、コンテキスト長と同時実行性に応じて増加します。
| ビット幅 | 代表的な量子化 | サイズ | メモリ要件 | HF推奨GPU | 合計VRAM |
|---|---|---|---|---|---|
| 1ビット | TQ1_0 | 84.5 GB | 86 GB | Nvidia L4 × 4 | 96 GB |
| 2ビット | Q2_K | 131 GB | 133 GB | Nvidia A100 × 2 | 160 GB |
| 3ビット | Q3_K_M | 171 GB | 173 GB | Nvidia L40S × 4 | 192 GB |
| 4ビット | Q4_K_M | 216 GB | 218 GB | Nvidia A100 × 4 | 320 GB |
| 5ビット | Q5_K_M | 254 GB | 256 GB | Nvidia A100 × 4 | 320 GB |
| 6ビット | Q6_K | 294 GB | 296 GB | Nvidia A100 × 4 | 320 GB |
| 8ビット | Q8_0 | 381 GB | 383 GB | Nvidia A100 × 8 | 640 GB |
| 16ビット | BF16 | 717 GB | 719 GB | Nvidia H200 × 8 | 1128 GB |
ローカルで重要な最小限の調整項目
ローカルにする場合は、次の3つのレバーに焦点を当ててください:
- 量子化(最大のVRAMレバー)
- オフロード(一部のレイヤーをCPU/RAMに移動)
- コンテキスト長(OOMが発生した場合はまずコンテキストを減らす)
オプション2:Novita GPU Cloud
ローカルがインフラ作業が多すぎると感じる場合、Novita GPU Cloudはクリーンな中間パスです。「ローカル的な」ワークフロー(独自のランタイム、推論スタック、ベンチマークスクリプト)を維持しながら、GPUを購入したり、ドライバーや障害、キャパシティを管理したりする必要がありません。
モード
- GPUインスタンス — 長時間実行、再現可能なワークロード向けのGPU VM
- サーバーレスGPU — バースト的な使用に最適な秒単位のエンドポイント
- ベアメタル — 最大の分離性と最も一貫したパフォーマンス
GPU CloudがGLM-4.7に適している理由
ローカルデプロイは通常、特に長いコンテキストや同時実行性がある場合、VRAMの余裕(ウェイト+KVキャッシュ+オーバーヘッド)によって制約されます。GPU Cloudを使用すると、実際のハードウェア階層(24GB / 48GB / 80GB+)全体でこれらの制約をテストできます — ハードウェアを所有せずに。
オプション3:Novita Model API
VRAM、コンテキスト長、同時実行性がどれほど早く制約になるかをローカルまたはGPU Cloudで確認したら、最も摩擦の少ないルートは多くの場合Novita Model APIです。
Novita AIは、高価なローカルハードウェアの必要性を排除しながら、プロダクション対応のスケーラブルな推論を提供するGLM-4.7 APIアクセスを提供しています。
ステップ1:ログインしてモデルライブラリにアクセス
Novita AIアカウントにログイン(またはサインアップ)し、モデルライブラリに移動します。
ステップ2:GLM-4.7を選択
利用可能なモデルを参照し、ワークロード要件に基づいてGLM-4.7を選択します。
ステップ3:無料トライアルを開始
無料トライアルをアクティブにして、GLM-4.7の推論、長文脈、コストパフォーマンスの特性を探索します。
ステップ4:APIキーを取得
設定ページを開き、認証用のAPIキーを生成してコピーします。
ステップ5:APIをインストールして呼び出す(Python例)
以下は、Chat Completions APIをPythonで使用する簡単な例です:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
この設定により、APIレベルで推論の深さ、トークン使用量、生成動作を制御できます。特に、ターンレベルの「思考」と予測可能なコストおよびレイテンシを組み合わせたい場合に便利であり、GLM-4.7のVRAM要件に合わせてハードウェアをサイジングする必要がありません。
結論:どのオプションを選ぶべきか?
制御性、運用労力、スケーラビリティに基づいてデプロイパスを選択してください:
| オプション | 長所 | 短所 |
| ローカル | 完全な制御、トークンごとのコストなし | ハードウェア制限+運用の複雑さ |
| GPU Cloud | 柔軟なハードウェア、ローカルに近い制御 | ドライバー/ランタイム管理+変動コスト |
| API | 最もシンプルなパス、予測可能なスケーリング | 低レベルの制御が少ない |
決定木
- ローカルを選ぶのは、オフライン/オンプレミスで実行する必要がある場合、またはデータとインフラストラクチャを完全に制御する必要がある場合。
- GPU Cloud を選ぶのは、GPUを所有せずに再現可能なベンチマークと制御を望む場合。
- API を選ぶのは、最小限の運用オーバーヘッドで本番環境への最もシンプルなパスを望む場合。
GLM-4.7は非常に高性能ですが、ローカルデプロイは長いコンテキストと高い同時実行性を押し進めるとVRAMの限界にぶつかります。ほとんどのチームにとって、最も実用的なパスは、明確な階層の期待値から始め、Novita GPU Cloudで実験し、その後そこに留まるか、最小運用ルートとしてNovitaのOpenAI互換APIに移行することです。
よくある質問
コンピュータにおけるVRAMとは何ですか?
VRAMはGPUに接続された高速メモリです。AI推論では、モデルウェイト、KVキャッシュ、中間バッファを保持します。
VRAMを確認するにはどうすればよいですか?
Windows:タスクマネージャー → パフォーマンス → GPU
macOS:このMacについて → システムレポート → グラフィックス/ディスプレイ
Linux:nvidia-smi
AIモデルにはどのくらいのVRAMが必要ですか?
ほとんどのユーザーにとって、8~12GBのVRAMは小規模モデルと軽いワークロードに十分ですが、大規模なフロンティアスタイルのモデルは通常、特に適切な速度とコンテキスト長を求める場合、16~24GB以上が必要です。
Novita AIは、あなたのAIの野心を強化するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — コスト効率の高いツールを提供します。インフラストラクチャを排除し、無料で始めて、AIのビジョンを現実にしましょう。



