

GLM-4.7 es un modelo grande de Mezcla de Expertos (MoE) de “pensamiento” diseñado para razonamiento, codificación, uso de herramientas y cargas de trabajo de contexto largo. Ahora está disponible en Novita AI con un rendimiento sólido y precios competitivos.
Cuando intentas ejecutar GLM-4.7 localmente, el primer cuello de botella suele ser la memoria, no el poder de cómputo bruto—especialmente la VRAM de la GPU, más la RAM del sistema necesaria para la descarga en implementaciones prácticas de MoE.
💡Aspectos destacados
-
Si buscas la ruta más rápida a producción: API de Modelo de Novita
-
Si deseas un “control estilo local” sin comprar GPUs: Novita GPU Cloud
-
Si debes ejecutarlo sin conexión/on-prem: opta por Local, pero espera depender de cuantificación + descarga
GLM-4.7: En qué destaca
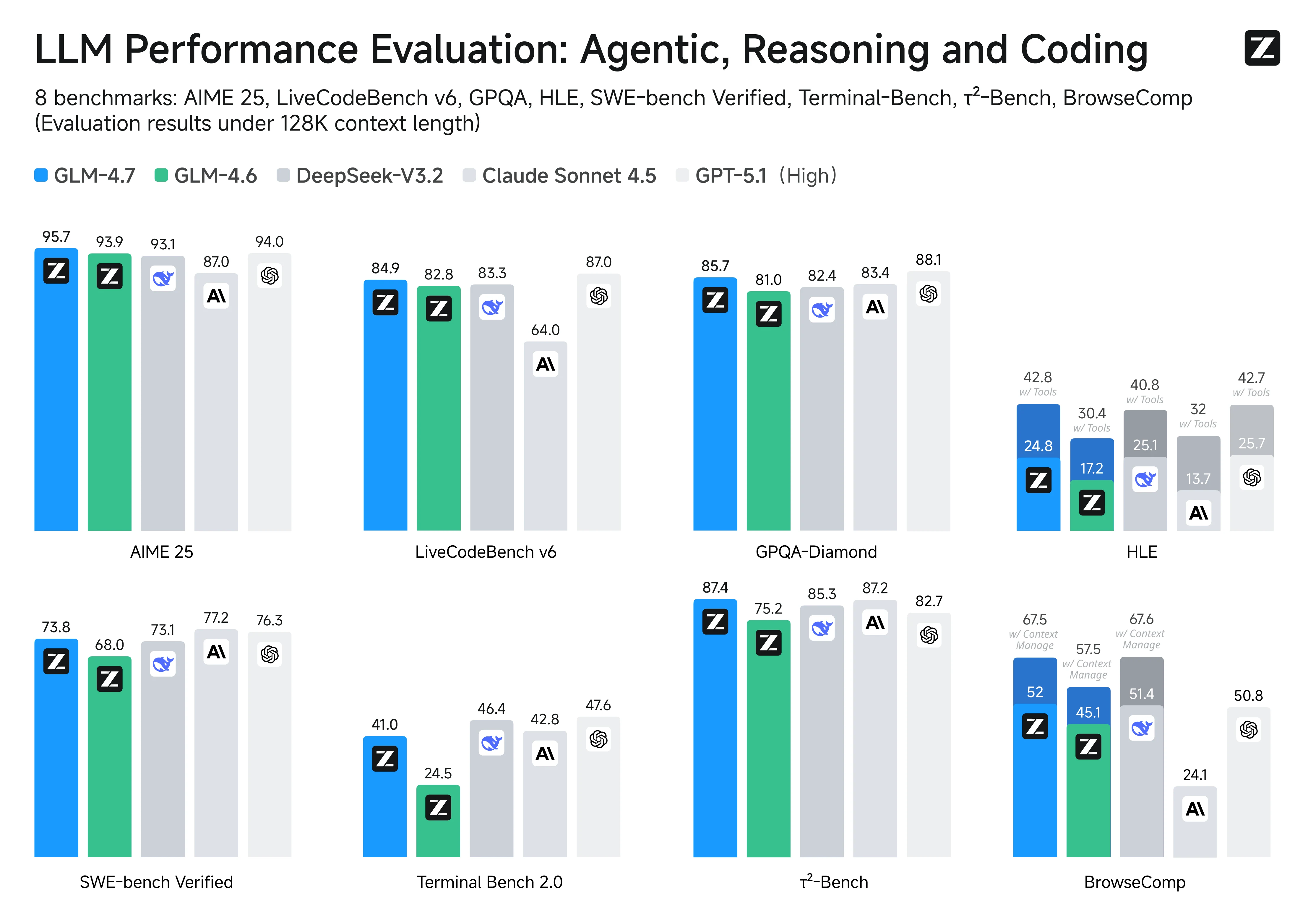
En los principales benchmarks de codificación y agentes, GLM-4.7 se sitúa a la par de Claude Sonnet 4.5, y las puntuaciones dibujan una imagen clara de sus fortalezas:
- Ingeniería de software a nivel de repositorio: En SWE-bench Verified, GLM-4.7 ocupa el primer lugar entre los modelos de código abierto con un 73.8% (+5.8% vs. GLM-4.6), lo que sugiere una sólida capacidad de extremo a extremo para diagnosticar problemas, editar archivos y producir parches que pasan pruebas en repositorios reales.
- Generación de código de alta calidad: En LiveCodeBench v6, alcanza un SOTA de código abierto del 84.9, superando supuestamente a Claude Sonnet 4.5, lo que indica un rendimiento competitivo en problemas de codificación que enfatizan la corrección y la calidad de implementación.
- Robustez multilingüe: Una puntuación del 66.7% en SWE-bench Multilingual (+12.9%) apunta a una mayor fiabilidad cuando el contexto del repositorio abarca múltiples lenguajes de programación y artefactos multilingües.
- Uso de herramientas agénticas en la práctica: Terminal-Bench 2.0 con un 41% (+16.5%) destaca ganancias significativas en flujos de trabajo de múltiples pasos impulsados por herramientas—exactamente el tipo de bucle “planificar → ejecutar → iterar” que deseas en agentes de codificación basados en CLI.
Por qué la VRAM es el verdadero cuello de botella
Aunque los modelos MoE activan solo un subconjunto de expertos por token, la inferencia local sigue estando limitada principalmente por la VRAM porque la GPU debe contener más que solo “el archivo del modelo”.
¿Qué consume realmente la VRAM?
- Pesos del modelo: La cuantificación reduce el tamaño de los pesos, pero los modelos MoE muy grandes siguen siendo pesados.
- Caché KV (memoria de contexto): La caché KV crece rápidamente con:
- longitud de contexto (8K → 32K → 128K),
- concurrencia (las sesiones paralelas multiplican la caché),
- configuraciones de rendimiento (el batching a menudo necesita más margen).
- Overhead de ejecución: Buffers del framework, asignaciones temporales, fragmentación y espacios de trabajo del kernel—a menudo varios GB.
Por qué “cabe” aún puede dar OOM
Un modo de fallo común: los pesos apenas caben en la VRAM, luego aumentas la longitud de contexto o ejecutas una segunda solicitud y la caché KV + el overhead te llevan al límite → errores de falta de memoria o una descarga pesada a CPU/RAM (que puede hundir la velocidad).
Una regla práctica de planificación
No apuntes a un uso del 100% de VRAM con los pesos.
- Mantén los pesos ≈ 70–80% de la VRAM para contextos moderados
- Reserva un 20–30% de margen para la caché KV + overhead
- Para contexto de 64K–128K o múltiples sesiones concurrentes, reserva aún más margen
Opción 1: Ejecutar GLM-4.7 Localmente
La implementación local merece la pena cuando debes ejecutar sin conexión/on-prem o necesitas control total sobre toda la pila. En la mayoría de las otras situaciones, es la ruta de mayor esfuerzo y mantenimiento.
¿Cuánta memoria necesita GLM-4.7? (variantes GGUF)
La tabla a continuación resume las variantes GGUF y las estimaciones de memoria de implementación mostradas por Hugging Face Inference Endpoints.
Importante
- Tamaño = tamaño del archivo GGUF (solo pesos; huella de almacenamiento)
- Requisitos de memoria = estimación de implementación de HF Endpoints (pesos + overhead de ejecución)
Los requisitos reales aumentan con la longitud de contexto y la concurrencia.
| Ancho de bits | Cuantificación representativa | Tamaño | Req. de memoria | GPU sugerida por HF | VRAM total |
|---|---|---|---|---|---|
| 1-bit | TQ1_0 | 84.5 GB | 86 GB | Nvidia L4 × 4 | 96 GB |
| 2-bit | Q2_K | 131 GB | 133 GB | Nvidia A100 × 2 | 160 GB |
| 3-bit | Q3_K_M | 171 GB | 173 GB | Nvidia L40S × 4 | 192 GB |
| 4-bit | Q4_K_M | 216 GB | 218 GB | Nvidia A100 × 4 | 320 GB |
| 5-bit | Q5_K_M | 254 GB | 256 GB | Nvidia A100 × 4 | 320 GB |
| 6-bit | Q6_K | 294 GB | 296 GB | Nvidia A100 × 4 | 320 GB |
| 8-bit | Q8_0 | 381 GB | 383 GB | Nvidia A100 × 8 | 640 GB |
| 16-bit | BF16 | 717 GB | 719 GB | Nvidia H200 × 8 | 1128 GB |
Palancas locales mínimas que importan
Si optas por local, concéntrate en tres palancas:
- Cuantificación (la palanca de VRAM más grande)
- Descarga (mover algunas capas a CPU/RAM)
- Longitud de contexto (reduce el contexto primero si obtienes OOM)
Opción 2: Novita GPU Cloud
Si lo local parece demasiado trabajo de infraestructura, Novita GPU Cloud es una ruta intermedia limpia: mantienes un flujo de trabajo “estilo local”—tu runtime, tu pila de inferencia, tus scripts de benchmarking—sin comprar GPUs ni gestionar controladores, fallos y capacidad.
Modos
- Instancias de GPU — VMs de GPU para cargas de trabajo de larga duración y reproducibles
- GPUs Serverless — endpoints por segundo ideales para uso intermitente
- Bare Metal — máximo aislamiento y el rendimiento más consistente
Por qué GPU Cloud funciona bien para GLM-4.7
Las implementaciones locales suelen estar limitadas por el margen de VRAM (pesos + caché KV + overhead), especialmente con contexto largo o concurrencia. GPU Cloud te permite probar esas limitaciones en varios niveles de hardware real (24GB / 48GB / 80GB+)—sin poseer el hardware.
Opción 3: API de Modelo de Novita
Una vez que has visto lo rápido que VRAM, longitud de contexto y concurrencia se convierten en limitaciones—localmente o en GPU Cloud—la ruta de menor fricción suele ser la API de Modelo de Novita.
Novita AI ofrece acceso a la API de GLM-4.7, eliminando la necesidad de hardware local costoso y proporcionando inferencia lista para producción a escala.
Paso 1: Inicia sesión y accede a la Biblioteca de Modelos
Inicia sesión (o regístrate) en tu cuenta de Novita AI y navega a la Biblioteca de Modelos.
Paso 2: Elige GLM-4.7
Explora los modelos disponibles y selecciona GLM-4.7 según los requisitos de tu carga de trabajo.
Paso 3: Comienza tu prueba gratuita
Activa tu prueba gratuita para explorar las características de razonamiento, contexto largo y relación coste-rendimiento de GLM-4.7.
Paso 4: Obtén tu Clave API
Abre la página de Configuración para generar y copiar tu clave API para la autenticación.
Paso 5: Instala y llama a la API (Ejemplo en Python)
A continuación se muestra un ejemplo simple usando la API de Chat Completions con Python:
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Esta configuración te permite controlar la profundidad de razonamiento, el uso de tokens y el comportamiento de generación a nivel de API—especialmente útil cuando deseas combinar “pensamiento” a nivel de turno con un coste y latencia predecibles, en lugar de dimensionar el hardware según las necesidades de VRAM de GLM-4.7.
Conclusión: ¿Qué opción deberías elegir?
Elige una ruta de implementación según el control vs. esfuerzo operativo vs. escalabilidad:
| Opción | Pros | Contras |
| Local | Control total, sin coste por token | Límites de hardware + complejidad operativa |
| GPU Cloud | Hardware flexible, control casi local | Gestión de controladores/entorno + costes variables |
| API | Ruta más simple, escalado predecible | Menos control a bajo nivel |
Árbol de decisión
- Elige Local si debes ejecutar sin conexión/on-prem o necesitas control total sobre datos + infraestructura.
- Elige GPU Cloud si deseas benchmarking reproducible y control sin poseer GPUs.
- Elige API si buscas la ruta más simple a producción con mínima sobrecarga operativa.
GLM‑4.7 es extremadamente capaz, pero las implementaciones locales se encuentran con límites de VRAM cuando empujas contexto largo y alta concurrencia; para la mayoría de los equipos, la ruta más práctica es comenzar con expectativas claras de nivel, experimentar en Novita GPU Cloud, y luego quedarse allí o migrar a la API compatible con OpenAI de Novita para la ruta de menor operación hacia producción.
Preguntas Frecuentes
¿Qué es la VRAM en una computadora?
La VRAM es una memoria de alta velocidad conectada a tu GPU. Para la inferencia de IA, contiene los pesos del modelo, la caché KV y los búferes intermedios.
¿Cómo verifico mi VRAM?
Windows: Administrador de tareas → Rendimiento → GPU
macOS: Acerca de este Mac → Informe del sistema → Gráficos/Pantallas
Linux: nvidia-smi
¿Cuánta VRAM necesito para modelos de IA?
Para la mayoría de los usuarios, 8–12 GB de VRAM son suficientes para modelos pequeños y cargas ligeras, pero los modelos de frontera más grandes suelen necesitar 16–24 GB o más, especialmente si deseas una velocidad y longitud de contexto decentes.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, serverless, instancias de GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.



