

O GLM-4.7 é um modelo grande de “pensamento” do tipo Mixture-of-Experts (MoE) desenvolvido para raciocínio, codificação, uso de ferramentas e workloads de contexto longo. Ele já está disponível na Novita AI com desempenho forte e preços competitivos.
Quando você tenta executar o GLM-4.7 localmente, o primeiro gargalo geralmente é a memória, não o poder de processamento bruto — especialmente a VRAM da GPU, além da RAM do sistema necessária para descarregamento em implantações práticas de MoE.
💡Destaques
- Se você quer o caminho mais rápido para produção: API de Modelos Novita
- Se você quer “controle no estilo local” sem comprar GPUs: Novita GPU Cloud
- Se você precisa executar offline/no local: escolha Local, mas espere depender de quantização + descarregamento
GLM-4.7: No que ele é bom
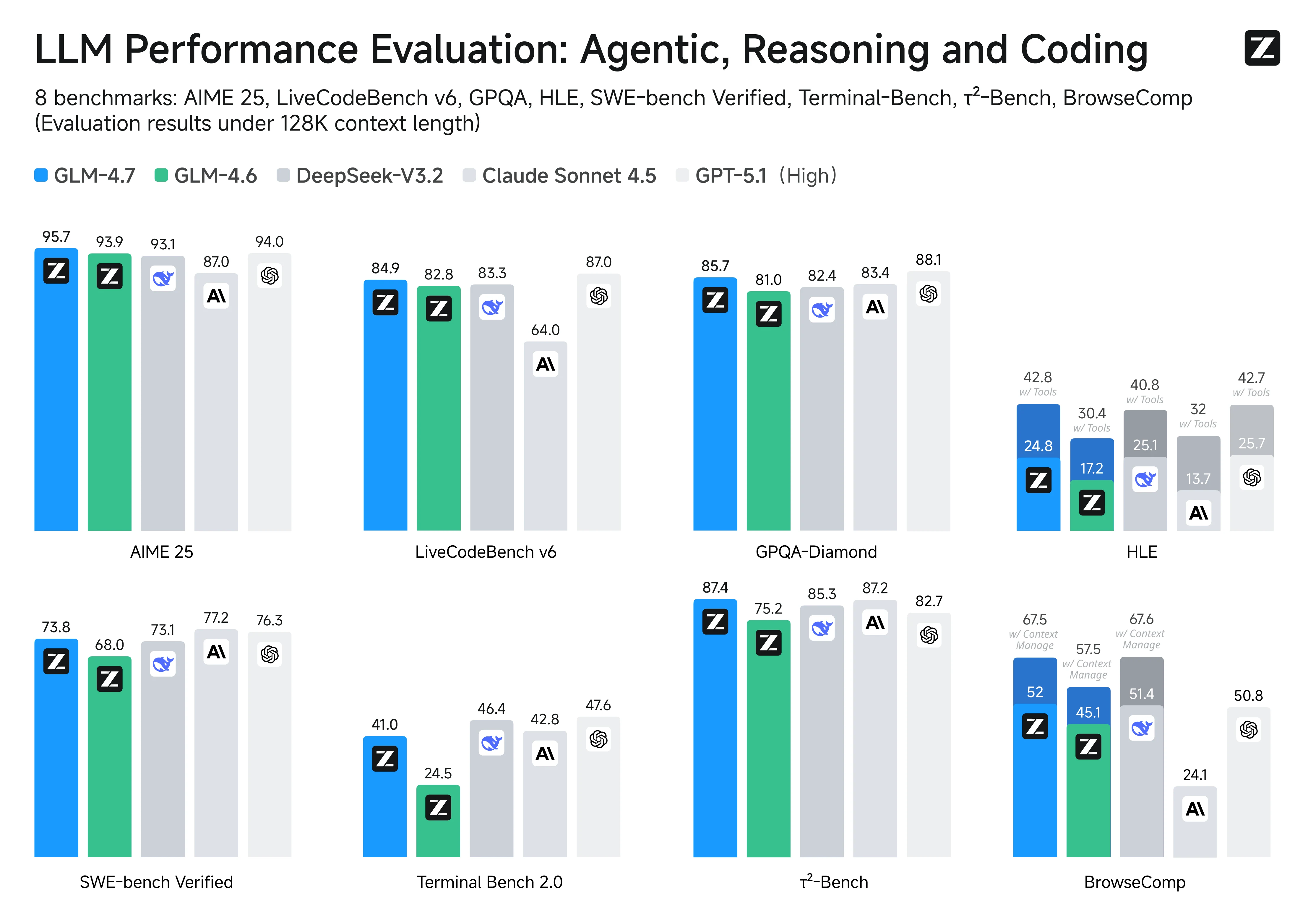
Nos principais benchmarks de codificação e agentes, o GLM-4.7 está posicionado como amplamente equivalente ao Claude Sonnet 4.5, e as pontuações mostram um quadro bastante claro de seus pontos fortes:
- Engenharia de software em nível de repositório: No SWE-bench Verified, o GLM-4.7 ocupa a 1ª posição entre os modelos de código aberto com 73,8% (+5,8% vs. GLM-4.6), sugerindo forte capacidade de ponta a ponta para diagnosticar problemas, editar entre arquivos e produzir patches que passam nos testes em repositórios reais.
- Geração de código de alta qualidade: No LiveCodeBench v6, ele atinge um SOTA de código aberto de 84,9, relatado como superior ao Claude Sonnet 4.5, indicando desempenho competitivo em problemas de codificação que enfatizam correção e qualidade de implementação.
- Robustez multilíngue: Uma pontuação de 66,7% no SWE-bench Multilingual (+12,9%) aponta para maior confiabilidade quando o contexto do repositório abrange várias linguagens de programação e artefatos de linguagem mista.
- Uso de ferramentas agentes na prática: O Terminal-Bench 2.0 com 41% (+16,5%) destaca ganhos significativos em fluxos de trabalho de várias etapas e orientados a ferramentas — exatamente o tipo de loop “planejar → executar → iterar” que você quer em agentes de codificação baseados em CLI.
Por que a VRAM é o verdadeiro gargalo
Embora os modelos MoE ativem apenas um subconjunto de especialistas por token, a inferência local ainda é limitada principalmente pela VRAM, pois a GPU precisa armazenar mais do que apenas “o arquivo do modelo”.
O que realmente consome VRAM?
- Pesos do modelo A quantização reduz o tamanho dos pesos, mas modelos MoE muito grandes ainda são pesados.
- Cache KV (memória de contexto) O cache KV cresce rapidamente com:
- comprimento do contexto (8K → 32K → 128K),
- concorrência (sessões paralelas multiplicam o cache),
- configurações de throughput (agrupamento de lotes geralmente precisa de mais espaço livre).
- Sobrecarga de tempo de execução Buffers de framework, alocações temporárias, fragmentação e espaços de trabalho de kernel — geralmente vários GB.
Por que “cabe” ainda pode causar OOM
Um modo de falha comum: os pesos mal cabem na VRAM, então você aumenta o comprimento do contexto ou executa uma segunda solicitação e o cache KV + sobrecarga ultrapassa o limite → erros de falta de memória (OOM) ou descarregamento pesado para CPU/RAM (o que pode reduzir muito a velocidade).
Uma regra de planejamento prática
Não vise 100% de uso da VRAM com os pesos.
- Mantenha os pesos ≈ 70–80% da VRAM para contextos moderados
- Reserve 20–30% de espaço livre para cache KV + sobrecarga
- Para contexto de 64K–128K ou múltiplas sessões concorrentes, reserve ainda mais espaço livre
Opção 1: Executar o GLM-4.7 Localmente
A implantação local vale a pena quando você precisa executar offline/no local ou precisa de controle total sobre toda a pilha. Na maioria das outras situações, é o caminho que exige mais esforço e mais manutenção.
Quanta memória o GLM-4.7 precisa? (variantes GGUF)
A tabela abaixo resume as variantes GGUF e as estimativas de memória de implantação mostradas pelo Hugging Face Inference Endpoints.
Importante
- Tamanho = tamanho do arquivo GGUF (apenas pesos; espaço de armazenamento)
- Requisitos de memória = estimativa de implantação do HF Endpoints (pesos + sobrecarga de tempo de execução). Os requisitos reais aumentam com o comprimento do contexto e a concorrência.
| Largura de bits | Quantização representativa | Tamanho | Req. de memória | GPU sugerida pelo HF | VRAM total |
|---|---|---|---|---|---|
| 1-bit | TQ1_0 | 84.5 GB | 86 GB | Nvidia L4 × 4 | 96 GB |
| 2-bit | Q2_K | 131 GB | 133 GB | Nvidia A100 × 2 | 160 GB |
| 3-bit | Q3_K_M | 171 GB | 173 GB | Nvidia L40S × 4 | 192 GB |
| 4-bit | Q4_K_M | 216 GB | 218 GB | Nvidia A100 × 4 | 320 GB |
| 5-bit | Q5_K_M | 254 GB | 256 GB | Nvidia A100 × 4 | 320 GB |
| 6-bit | Q6_K | 294 GB | 296 GB | Nvidia A100 × 4 | 320 GB |
| 8-bit | Q8_0 | 381 GB | 383 GB | Nvidia A100 × 8 | 640 GB |
| 16-bit | BF16 | 717 GB | 719 GB | Nvidia H200 × 8 | 1128 GB |
Knobs locais mínimos que importam
Se você for para o local, concentre-se em três alavancas:
- Quantização (maior alavanca de VRAM)
- Descarregamento (move algumas camadas para CPU/RAM)
- Comprimento do contexto (reduza o contexto primeiro se houver OOM)
Opção 2: Novita GPU Cloud
Se o local parecer muito trabalho de infraestrutura, a Novita GPU Cloud é um caminho intermediário limpo: você mantém um fluxo de trabalho “no estilo local” — seu tempo de execução, sua pilha de inferência, seus scripts de benchmark — sem comprar GPUs ou gerenciar drivers, falhas e capacidade.
Modos
- Instâncias de GPU — VMs de GPU para workloads de longa duração e reproduzíveis
- GPUs Serverless — endpoints por segundo ideais para uso com picos de demanda
- Bare Metal — isolamento máximo e o desempenho mais consistente
Por que a GPU Cloud funciona bem para o GLM-4.7 Implantações locais geralmente são limitadas pelo espaço livre de VRAM (pesos + cache KV + sobrecarga), especialmente com contexto longo ou concorrência. A GPU Cloud permite testar essas restrições em diferentes camadas de hardware reais (24GB / 48GB / 80GB+) — sem possuir o hardware.
Opção 3: API de Modelos Novita
Depois de ver como a VRAM, o comprimento do contexto e a concorrência se tornam restrições rapidamente — localmente ou na GPU Cloud — a rota com menos atritos geralmente é a API de Modelos Novita.
A Novita AI oferece acesso à API do GLM-4.7, eliminando a necessidade de hardware local caro enquanto fornece inferência pronta para produção em escala.
Passo 1: Faça login e acesse a Biblioteca de Modelos Faça login (ou cadastre-se) na sua conta Novita AI e navegue até a Biblioteca de Modelos.
Passo 2: Escolha o GLM-4.7 Navegue pelos modelos disponíveis e selecione o GLM-4.7 com base nos requisitos do seu workload.
Passo 3: Inicie seu teste gratuito Ative seu teste gratuito para explorar as características de raciocínio, contexto longo e custo-desempenho do GLM-4.7.
Passo 4: Obtenha sua chave de API Abra a página de Configurações para gerar e copiar sua chave de API para autenticação.
Passo 5: Instale e chame a API (Exemplo em Python) Abaixo um exemplo simples usando a API de Conclusões de Chat com Python:
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="zai-org/glm-4.7",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=131072,
temperature=0.7
)
print(response.choices[0].message.content)
Essa configuração permite controlar a profundidade de raciocínio, o uso de tokens e o comportamento de geração no nível da API — especialmente útil quando você quer combinar o “pensamento” em nível de turno com custo e latência previsíveis, em vez de dimensionar hardware com base nas necessidades de VRAM do GLM-4.7.
Conclusão: Qual opção você deve escolher?
Escolha um caminho de implantação com base em controle vs. esforço operacional vs. escalabilidade:
| Opção | Vantagens | Desvantagens |
| Local | Controle total, sem custo por token | Limites de hardware + complexidade operacional |
| GPU Cloud | Hardware flexível, controle quase local | Gerenciamento de driver/tempo de execução + custos variáveis |
| API | Caminho mais simples, escalabilidade previsível | Menos controle de baixo nível |
Árvore de decisão
- Escolha Local se você precisa executar offline/no local ou precisa de controle total sobre dados + infraestrutura.
- Escolha GPU Cloud se você quer benchmarks reproduzíveis e controle sem possuir GPUs.
- Escolha API se você quer o caminho mais simples para produção com sobrecarga operacional mínima.
O GLM‑4.7 é extremamente capaz, mas implantações locais esbarram em limites de VRAM assim que você usa contexto longo e alta concorrência; para a maioria das equipes, o caminho mais prático é começar com expectativas claras de camadas, experimentar na Novita GPU Cloud e depois ficar lá ou migrar para a API compatível com OpenAI da Novita para a rota de produção com menor sobrecarga operacional.
Perguntas Frequentes
O que é VRAM em um computador? A VRAM é uma memória de alta velocidade conectada à sua GPU. Para inferência de IA, ela armazena pesos de modelo, cache KV e buffers intermediários.
Como verifico minha VRAM?
Windows: Gerenciador de Tarefas → Desempenho → GPU
macOS: Sobre este Mac → Relatório do Sistema → Gráficos/Visores
Linux: nvidia-smi
Quanta VRAM eu preciso para modelos de IA? Para a maioria dos usuários, 8 a 12 GB de VRAM são suficientes para modelos pequenos e workloads leves, mas modelos maiores do tipo fronteira geralmente precisam de 16 a 24 GB ou mais, especialmente se você quer velocidade e comprimento de contexto decentes.
Novita AI é a plataforma de nuvem tudo-em-um que capacita suas ambições de IA. APIs integradas, serverless, Instância de GPU — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA uma realidade.



