

Novita AI startet seine „Build Month“-Kampagne und bietet Entwicklern einen exklusiven Rabatt von bis zu 20 % auf alle Hauptprodukte!
Jetzt am Build Month teilnehmen!
Die Bereitstellung von ERNIE-4.5-VL-A3B in realen Szenarien stellt Entwickler vor ein klares Dilemma: Zwar liefert das Modell eine starke multimodale Reasoning-Leistung, seine hohen VRAM-Anforderungen und Infrastrukturkosten machen die lokale Bereitstellung jedoch komplex und teuer. Viele Teams haben Schwierigkeiten, Hardwareinvestitionen, Migrationsaufwand und operative Skalierbarkeit in Einklang zu bringen, insbesondere wenn sie auf Vollpräzisionsinferenz, lange Kontextfenster und Produktionsparallelität abzielen. Dieser Artikel geht auf diese Herausforderungen ein, indem er systematisch die Hardwareanforderungen von ERNIE-4.5-VL-A3B, tatsächliche lokale Bereitstellungskosten und eine kosteneffizientere Cloud-GPU-Alternative über Novita AI untersucht und gleichzeitig einen praktischen, schrittweisen Bereitstellungspfad bereitstellt, um Entwicklern zu helfen, schnell und zuverlässig loszulegen.
VRAM-Anforderungen von ERNIE-4.5-VL-A3B
Empfohlene Konfiguration
- GPU: 1 × NVIDIA A100 (80 GB) oder H100
- VRAM-Nutzung: ca. 70–75 GB
- Anwendungsfall: Vollpräzisionsinferenz (BF16), maximale Kontextlänge (128k) und High-Concurrency-Batching unter Produktionslast.
Minimale Konfiguration
- GPU: 2 × NVIDIA RTX 3090 oder RTX 4090 (jeweils 24 GB, NVLink bevorzugt) oder 1 × RTX 6000 Ada (48 GB)
- VRAM-Nutzung: Mehr als 48 GB erforderlich
- Quantisierung: WINT8 (nur Gewichts-INT8) wird explizit unterstützt, um den Speicherbedarf zu reduzieren.
Wie viel kostet die lokale Bereitstellung von ERNIE-4.5-VL-A3B?
Das Self-Hosting geht weit über die GPU hinaus: Server, Netzwerk, Kühlung und Energieinfrastruktur erhöhen die gesamten Anfangskosten erheblich.
Die Migrations-/Upgrade-Kosten bestehen größtenteils aus Engineering-Zeit und Integrationsarbeit; selbst wenn vorhandene Hardware teilweise wiederverwendet werden kann, sind die Migration des Software-Stacks, die Skalierungsorchestrierung und die Leistungsoptimierung nicht trivial und erfordern dedizierte Arbeitskraft.
| Kostenkategorie | Produktionssetup (High-End) | Minimales Self-Hosted-Setup (Quantisiert) | Inkrementelle Migration/Upgrade |
|---|---|---|---|
| GPU-Hardware | NVIDIA H100 80GB NVIDIA H100 NVL $29.700–$42.700 |
NVIDIA A100‑80G NVIDIA A100 80G $30.000–$42.000 |
Beim Ersetzen älterer Consumer-GPUs (z. B. 3090/4090) liegen die inkrementellen Kosten roughly beim vollen Preis neuer Karten abzüglich des Restwerts alter Karten; rechnen Sie mit ~ $25.000–$40.000 pro GPU als Upgrade-Delta für jede hinzugefügte Profi-GPU. |
| Unterstützendes System (Server, Netzteil, Kühlung, Netzwerk) | $15.000–$40.000+ (Enterprise-Chassis, Hochleistungs-Netzteil, Racks, 10/25/100 GbE) | $5.000–$15.000 (Arbeitsplatzrechner-Server, NVLink-Bridges) | Variiert — bei Produktions-Upgrades benötigen Sie höchstwahrscheinlich neue Serverinfrastruktur, um H100/A100 unterzubringen. Das Upgrade älterer Chassis bedeutet in der Regel $10.000–$30.000 für Serverumbau + Verkabelung + NVLink. |
| Speicher & Arbeitsspeicher | $2.000–$6.000 (NVMe + ECC-RAM ) | $1.000–$3.000 | Gering, wenn vorhandener Speicher wiederverwendet wird, sonst $1.000–$2.000 |
| Netzwerk | $2.000–$8.000 | $500–$2.000 | |
| Standort- & Energie-Upgrades | $5.000–$15.000 (USV, Kühlungsverbesserungen) | $1.000–$5.000 | Abhängig von Standort-Upgrades, oft $3.000–$10.000 |
| Migration / Integrations-Engineering | $15.000–$50.000(100–300+ Stunden Engineering) | $10.000–$30.000(80–200+ Stunden) | Für Teams, die von Consumer-GPUs zu diesen Profi-Karten wechseln, umfasst die Integration Modellserver-Neukonfiguration, Treiber- und CUDA/NCCL-Umgebungsmigration, Leistungsbaseline und Automatisierung — in der Regel $15.000–$40.000 an Arbeitskosten, je nach internem Qualifikationsniveau. |
Ein besserer Weg, um auf ERNIE-4.5-VL-A3B Cloud-GPU zuzugreifen
Die Cloud-GPU-Plattform von Novita AI unterstützt mehrere Abrechnungsmodi, sodass Benutzer Kosten und Stabilität basierend auf Arbeitslastmustern anpassen können:
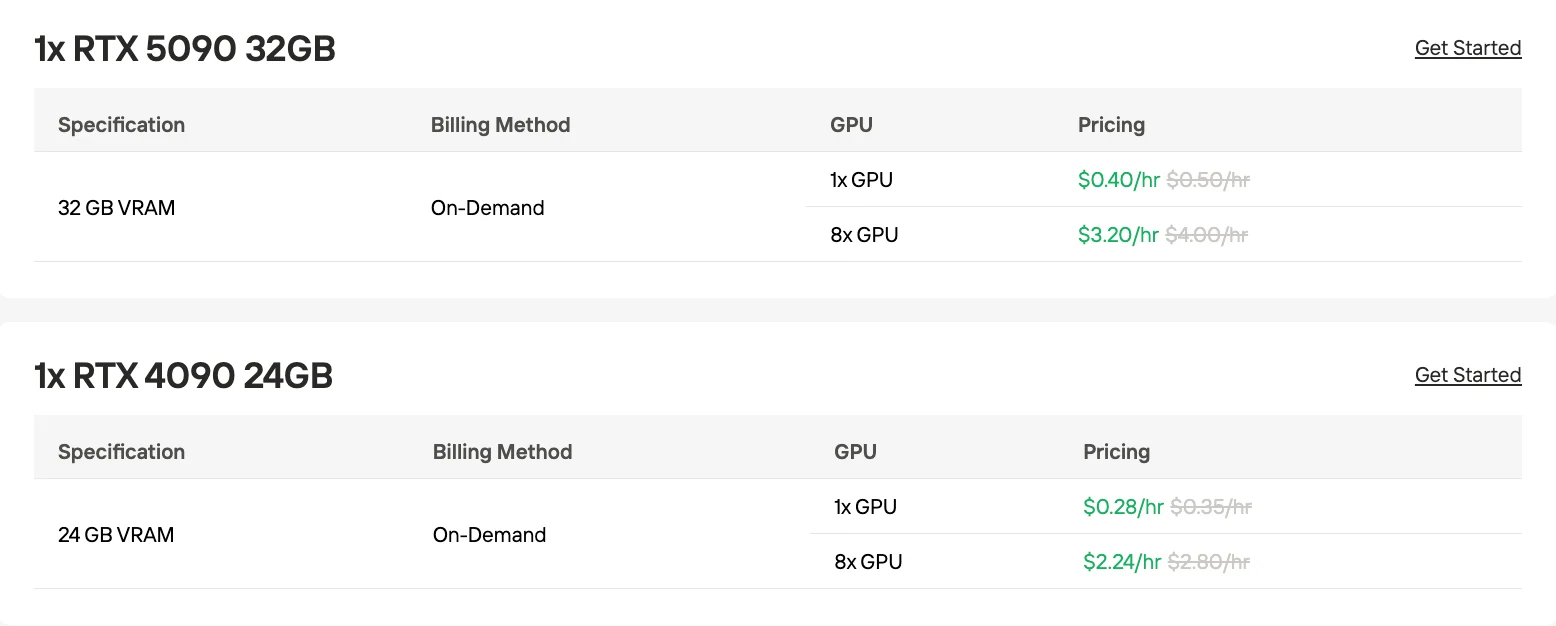
Über den gesamten dargestellten Zeitraum von 36 Monaten bleibt Cloud-GPU kumulativ deutlich günstiger, wobei die Lücke fast vollständig durch vermiedene CapEx in den frühen Phasen getrieben wird.
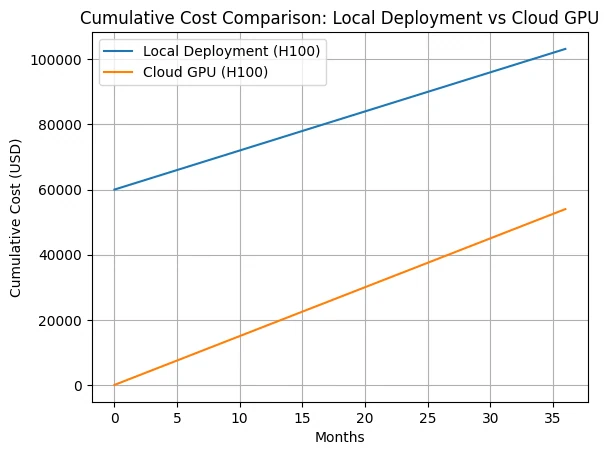
1. On-Demand (Pay-as-you-go)
Dies ist das Standardmodell, bei dem Sie für GPU-Compute nach Laufzeit (pro Sekunde/Stunde) ohne langfristige Verträge oder Reservierungen zahlen. Es bietet maximale Flexibilität und ist ideal für variable Arbeitslasten, intermittierende Nutzung und Experimente, da Sie nur Kosten verursachen, während die Instanz läuft. Speicher und zusätzliche Ressourcen (z. B. Festplatte, Netzwerk) werden ebenfalls nach Nutzung abgerechnet.
Testen Sie jetzt schnelle und günstige GPUs!
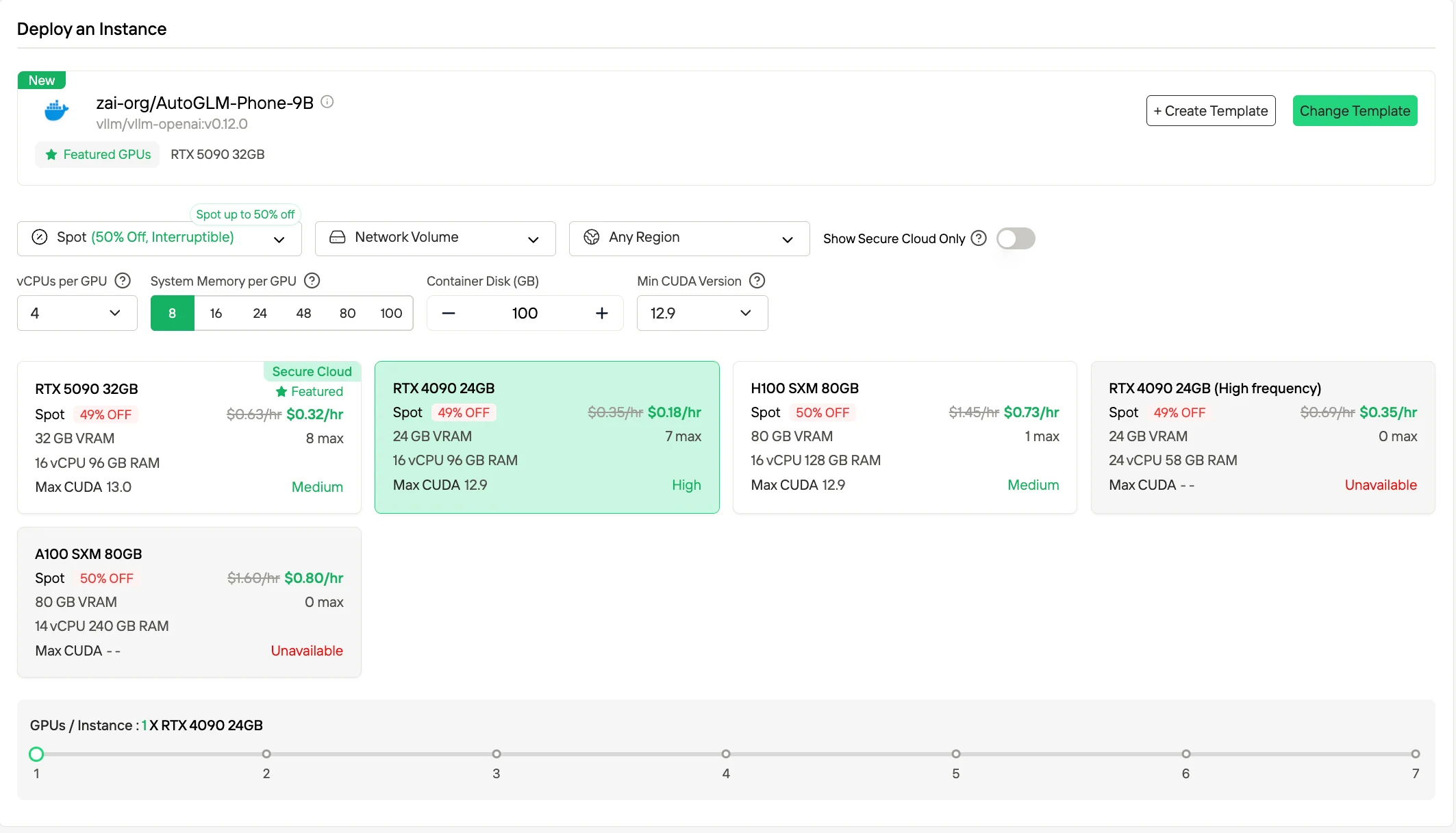
2. Spot Instances
Spot-Preise bieten deutlich niedrigere Stundensätze (oft bis zu ~50 % Rabatt) im Vergleich zu On-Demand, indem sie ungenutzte Kapazitäten nutzen. Diese Instanzen können von der Plattform vorzeitig beendet werden, aber Novita bietet ein 1-stündiges garantiertes Schutzfenster und vorherige Kündigungsbenachrichtigungen, wodurch dieser Modus für unterbrechbare Arbeitslasten oder Batch-Jobs geeignet ist, bei denen gelegentliche Unterbrechungen akzeptabel sind.
3. Subscription / Reserved Plans
Novita bietet auch monatliche und jährliche Abonnementoptionen für GPU-Instanzen. Diese Pläne bieten dedizierte Ressourcen mit vorhersehbarer Verfügbarkeit und haben oft niedrigere Preise im Vergleich zur On-Demand-Abrechnung. Dieser Modus kommt Benutzern mit stabilen, langfristigen Rechenbedürfnissen zugute, die die Stückkosten durch Verpflichtung senken möchten.
4. Serverless GPU Billing
Zusätzlich zu traditionellen Instanzmodellen unterstützt Novita serverlose GPU-Ausführung, bei der Ressourcen automatisch mit der Arbeitslast skaliert werden und Sie nur für die verbrauchten Rechenressourcen bezahlen. Dieser Modus abstrahiert die Instanzverwaltung und ist für Workflows mit unvorhersehbarem oder stark variablem Datenverkehr optimiert.
Novita AI bietet außerdem Vorlagen, die entwickelt wurden, um den operativen und kognitiven Aufwand im Zusammenhang mit der Bereitstellung von GPU-basierten KI-Arbeitslasten deutlich zu senken. Anstatt dass Entwickler Umgebungen von Grund auf manuell zusammenstellen müssen, bietet das Vorlagensystem vorkonfigurierte, produktionsbereite Images, die das Betriebssystem, CUDA- und cuDNN-Versionen, Deep-Learning-Frameworks, Inferenz-Engines und in einigen Fällen sogar vollständig verdrahtete Modellserving-Stacks bündeln.
So stellen Sie ERNIE-4.5-VL-A3B auf Novita AI bereit
Schritt 1:Registrieren Sie ein Konto
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Explore“ in der linken Seitenleiste, um unsere GPU-Angebote anzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2:Vorlagen und GPU-Server erkunden
Wählen Sie Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration — Optionen umfassen die leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationen.
Schritt 3:Passen Sie Ihre Bereitstellung an und starten Sie eine Instanz
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Arbeitslasten und Entwicklungsanforderungen zu gewährleisten. Innerhalb weniger Minuten ist Ihre leistungsstarke GPU-Umgebung einsatzbereit, sodass Sie sofort mit Ihren Machine-Learning-, Rendering- oder Rechenprojekten beginnen können.
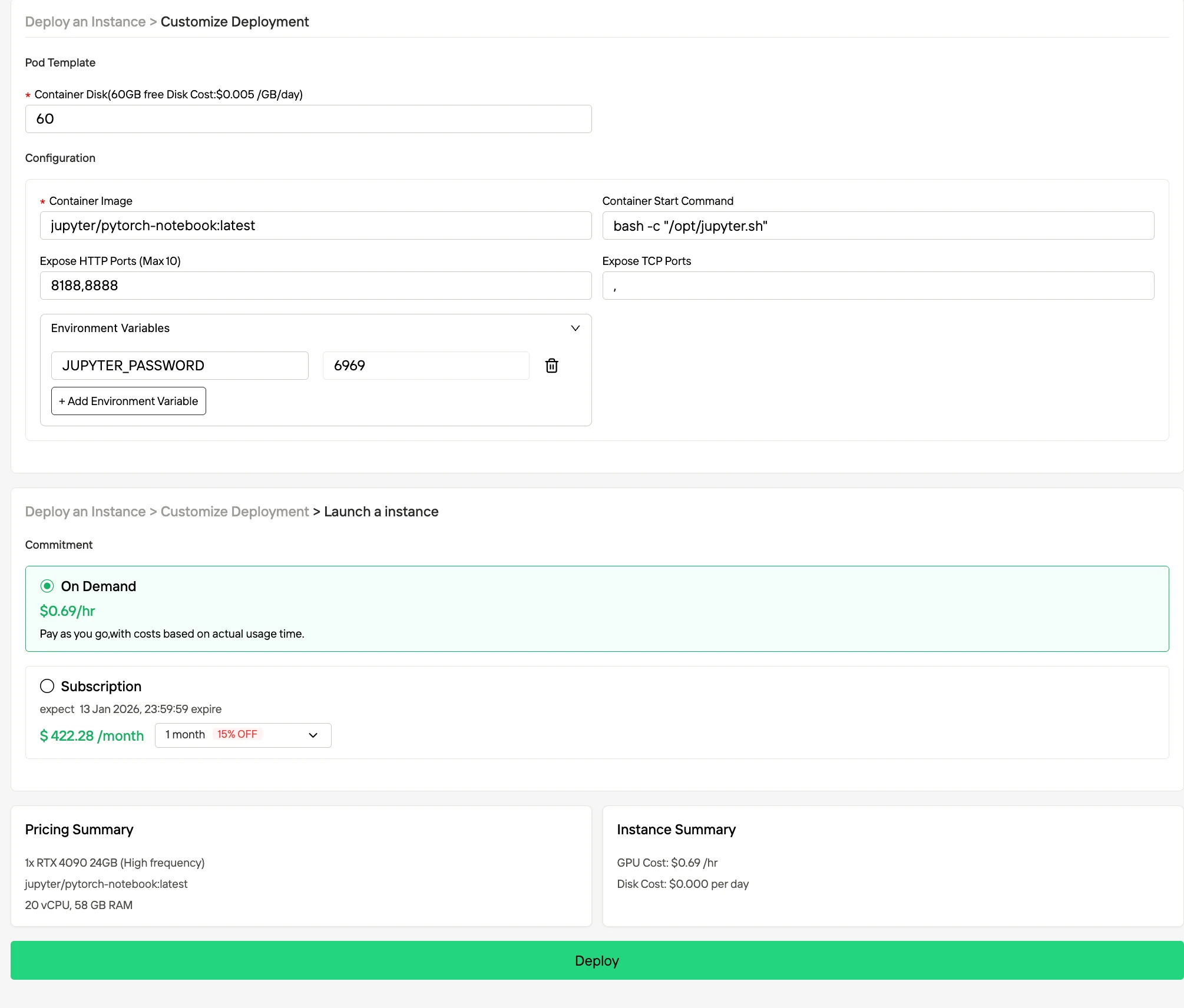
Schritt 4: Bereitstellungsfortschritt überwachen
Navigieren Sie zu Instanzverwaltung, um auf die Steuerungskonsole zuzugreifen. Dieses Dashboard ermöglicht es Ihnen, den Bereitstellungsstatus in Echtzeit zu verfolgen.
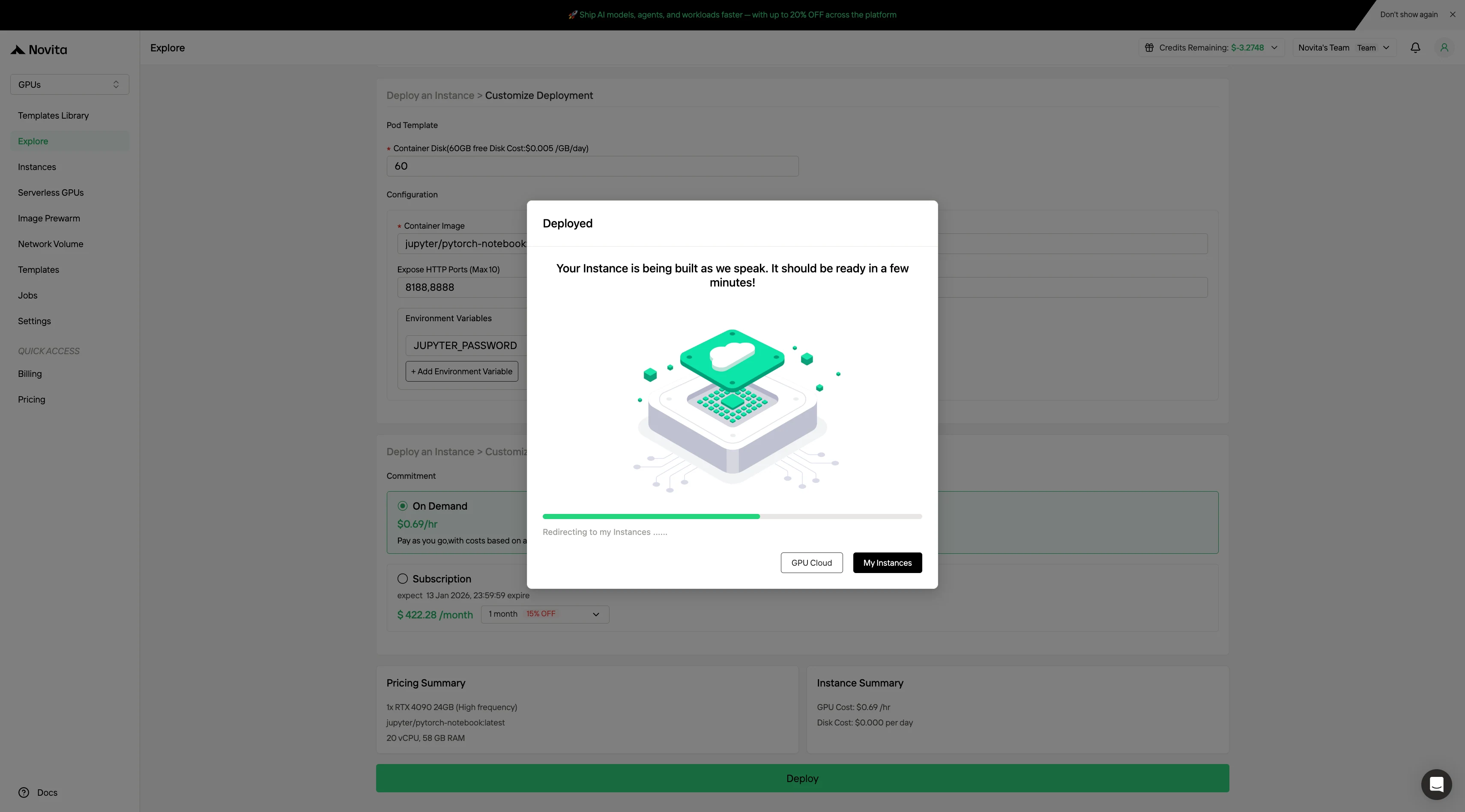
Testen Sie jetzt schnelle und günstige GPUs!
Schritt 5: Status des Image-Pullings anzeigen
Klicken Sie auf Ihre spezifische Instanz, um den Downloadfortschritt des Container-Images zu überwachen. Dieser Vorgang kann je nach Netzwerkbedingungen mehrere Minuten dauern.
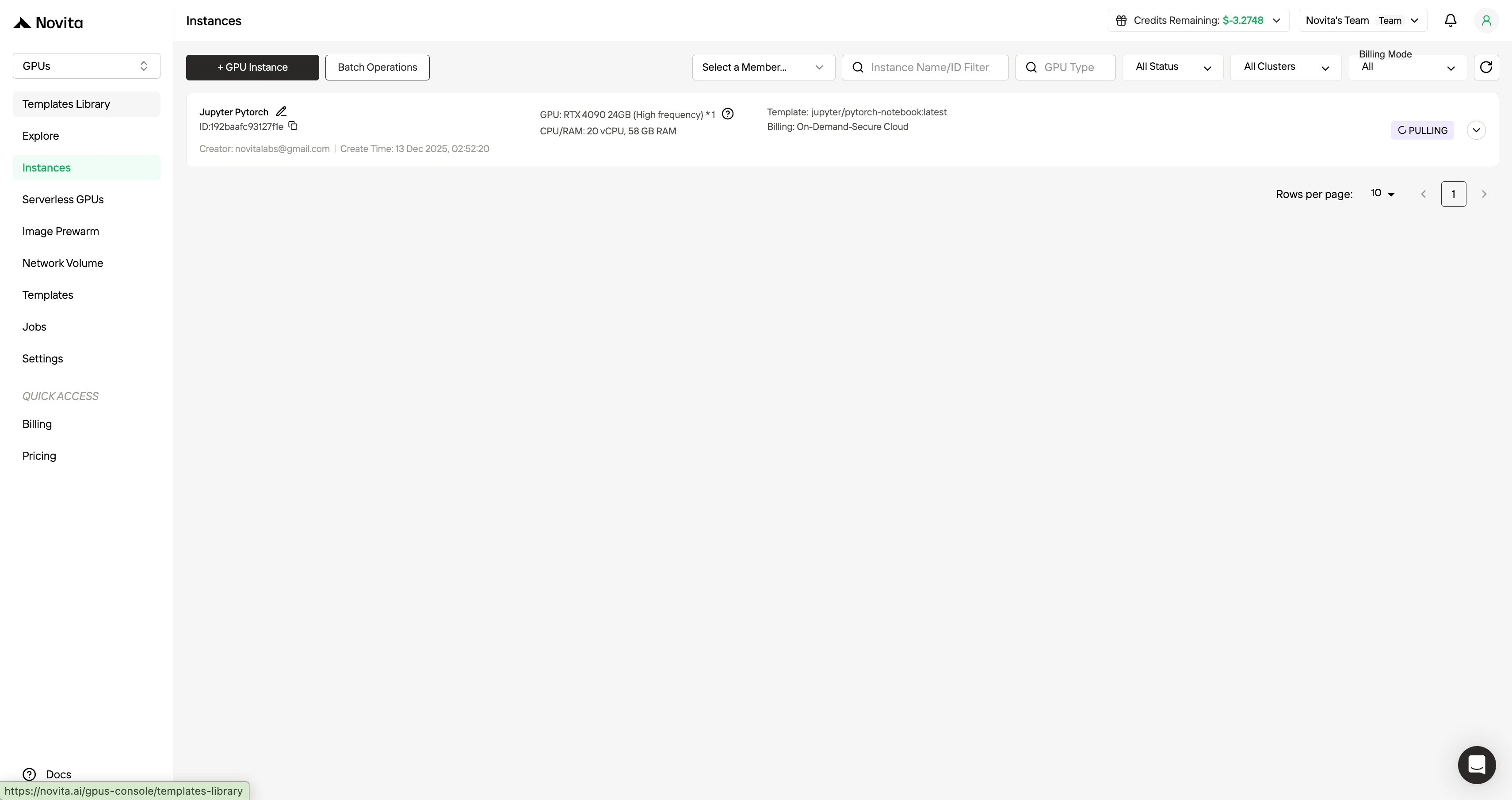
Schritt 6: Erfolgreiche Bereitstellung bestätigen
Nach dem Start der Instanz beginnt das Pullen des Modells. Klicken Sie auf „Logs“ → „Instanz-Logs“, um den Modelldownloadfortschritt zu überwachen. Suchen Sie nach der Meldung
"Application startup complete."in den Instanz-Logs. Dies zeigt an, dass der Bereitstellungsprozess erfolgreich abgeschlossen wurde.Klicken Sie auf „Connect“, dann auf → „Connect to HTTP Service [Port 8000]“. Da dies ein API-Dienst ist, müssen Sie die Adresse kopieren.
Um Anfragen an Ihr Modell zu stellen, ersetzen Sie bitte “http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai" durch Ihre tatsächliche exponierte Adresse. Kopieren Sie den folgenden Code, um auf Ihr privates Modell zuzugreifen!
ERNIE-4.5-VL-A3B erfordert bei Self-Hosting erhebliche GPU-Speicher- und Infrastrukturinvestitionen, wobei die Gesamtkosten weit über die GPU selbst hinausgehen und Server, Netzwerk, Energie und Engineering-Arbeitskraft umfassen. Im Gegensatz dazu senkt die Cloud-GPU-Plattform von Novita AI sowohl die Vorab- als auch die langfristigen Kosten durch flexible Abrechnungsmodelle, On-Demand-Skalierbarkeit und gebrauchsfertige Vorlagen. Für die meisten Teams bietet der Zugriff auf ERNIE-4.5-VL-A3B über Cloud-GPUs einen schnelleren, günstigeren und betrieblich einfacheren Weg zur produktionsreifen Bereitstellung, ohne Leistung oder Flexibilität zu opfern.
Häufig gestellte Fragen
Welche GPU-Konfiguration wird für ERNIE-4.5-VL-A3B empfohlen?
Für ERNIE-4.5-VL-A3B wird empfohlen, es auf 1× NVIDIA A100 (80 GB) oder H100 mit BF16-Präzision auszuführen, um Long-Context- und High-Concurrency-Inferenz zu unterstützen.
Welches ist die minimale erforderliche GPU-Konfiguration für ERNIE-4.5-VL-A3B?
ERNIE-4.5-VL-A3B erfordert entweder 2× RTX 3090/4090 (jeweils 24 GB, NVLink bevorzugt) oder 1× RTX 6000 Ada (48 GB), mit WINT8-Quantisierung zur Reduzierung des Speicherverbrauchs.
Warum ist die lokale Bereitstellung von ERNIE-4.5-VL-A3B teuer?
Die lokale Bereitstellung von ERNIE-4.5-VL-A3B umfasst nicht nur High-End-GPUs, sondern auch Server, Speicher, Netzwerk, Kühlung, Energie-Upgrades und umfangreiche Engineering-Arbeit für Migration und Optimierung.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen verwirklicht. Integrierte APIs, Serverless, GPU-Instanz — die kosteneffektiven Tools, die Sie brauchen. Eliminieren Sie Infrastruktur, starten Sie kostenlos und machen Sie Ihre KI-Vision zur Realität.



