

Novita AI lance sa campagne « Build Month », offrant aux développeurs une réduction exclusive allant jusqu’à 20 % sur tous ses produits principaux !
Déployer ERNIE-4.5-VL-A3B dans des scénarios réels présente un dilemme clair pour les développeurs : si le modèle offre d’excellentes performances de raisonnement multimodal, ses exigences élevées en VRAM et ses coûts d’infrastructure rendent le déploiement local complexe et coûteux. De nombreuses équipes peinent à concilier investissement matériel, efforts de migration et scalabilité opérationnelle, notamment lorsqu’elles visent une inférence en précision complète, des fenêtres de contexte longues et une concurrence de niveau production. Cet article répond à ces défis en examinant systématiquement les exigences matérielles d’ERNIE-4.5-VL-A3B, les coûts réels d’un déploiement local et une alternative cloud GPU plus rentable via Novita AI, tout en proposant un chemin de déploiement pratique étape par étape pour aider les développeurs à démarrer rapidement et de manière fiable.
Exigences VRAM d’ERNIE-4.5-VL-A3B
Configuration recommandée
- GPU : 1 × NVIDIA A100 (80 Go) ou H100
- Utilisation VRAM : environ 70 à 75 Go
- Cas d’usage : inférence en précision complète (BF16), longueur de contexte maximale (128k) et traitement par lots à haute concurrence sous charge de production.
Configuration minimale
- GPU : 2 × NVIDIA RTX 3090 ou RTX 4090 (24 Go chacun, NVLink préférable), ou 1 × RTX 6000 Ada (48 Go)
- Utilisation VRAM : plus de 48 Go requis
- Quantification : WINT8 (INT8 pondéré uniquement) est explicitement pris en charge pour réduire l’empreinte mémoire.
Quel est le coût d’un déploiement local d’ERNIE-4.5-VL-A3B ?
L’auto-hébergement ne se limite pas au GPU : les serveurs, le réseau, le refroidissement et l’infrastructure électrique augmentent considérablement le coût initial total.
Le coût de migration/mise à niveau repose principalement sur le temps d’ingénierie et le travail d’intégration ; même si le matériel existant est partiellement réutilisable, la migration de la pile logicielle, l’orchestration de la scalabilité et l’optimisation des performances ne sont pas triviales et nécessitent une main-d’œuvre dédiée.
| Catégorie de coût | Configuration production (haut de gamme) | Configuration auto-hébergée minimale (quantifiée) | Migration/mise à niveau incrémentale |
|---|---|---|---|
| Matériel GPU | NVIDIA H100 80Go NVIDIA H100 NVL 29 700 – 42 700 $ |
NVIDIA A100‑80G NVIDIA A100 80G 30 000 – 42 000 $ |
Si vous remplacez des GPU grand public (par ex. 3090/4090), le coût incrémental correspond approximativement au prix plein des nouvelles cartes moins la valeur résiduelle des anciennes cartes ; comptez environ 25 000 – 40 000 $ par GPU comme delta de mise à niveau pour chaque GPU professionnel ajouté. |
| Système de support (serveur, alimentation, refroidissement, réseau) | 15 000 – 40 000 $ et plus (châssis entreprise, alimentation haute puissance, racks, 10/25/100 GbE) | 5 000 – 15 000 $ (serveur de station de travail, ponts NVLink) | Varie — dans les cas de mise à niveau en production, vous aurez très probablement besoin d’une nouvelle infrastructure serveur pour accueillir des H100/A100. La mise à niveau d’anciens châssis signifie généralement 10 000 – 30 000 $ pour la rénovation du serveur + câblage + NVLink. |
| Stockage et mémoire | 2 000 – 6 000 $ (NVMe + RAM ECC ) | 1 000 – 3 000 $ | Mineur si vous réutilisez le stockage existant, sinon 1 000 – 2 000 $ |
| Réseau | 2 000 – 8 000 $ | 500 – 2 000 $ | |
| Améliorations des installations et de l’alimentation | 5 000 – 15 000 $ (UPS, améliorations du refroidissement) | 1 000 – 5 000 $ | Dépend des travaux sur le site, souvent 3 000 – 10 000 $ |
| Ingénierie de migration / intégration | 15 000 – 50 000 $(100 à 300+ heures d’ingénierie) | 10 000 – 30 000 $(80 à 200+ heures) | Pour les équipes passant de GPU grand public à ces cartes professionnelles, l’intégration comprend la reconfiguration du serveur de modèles, la migration des pilotes et des environnements CUDA/NCCL, l’établissement de bases de performance et l’automatisation — généralement 15 000 – 40 000 $ de main-d’œuvre, selon le niveau de compétence interne. |
Une meilleure façon d’accéder à ERNIE-4.5-VL-A3B via un cloud GPU
La plateforme cloud GPU de Novita AI prend en charge plusieurs modes de facturation pour que les utilisateurs puissent adapter coût et stabilité en fonction des schémas de charge de travail :
Sur l’ensemble de l’horizon de 36 mois présenté, le cloud GPU reste nettement moins cher en coût cumulé, l’écart étant presque entièrement dû aux dépenses d’investissement (CapEx) évitées dans les premières étapes.
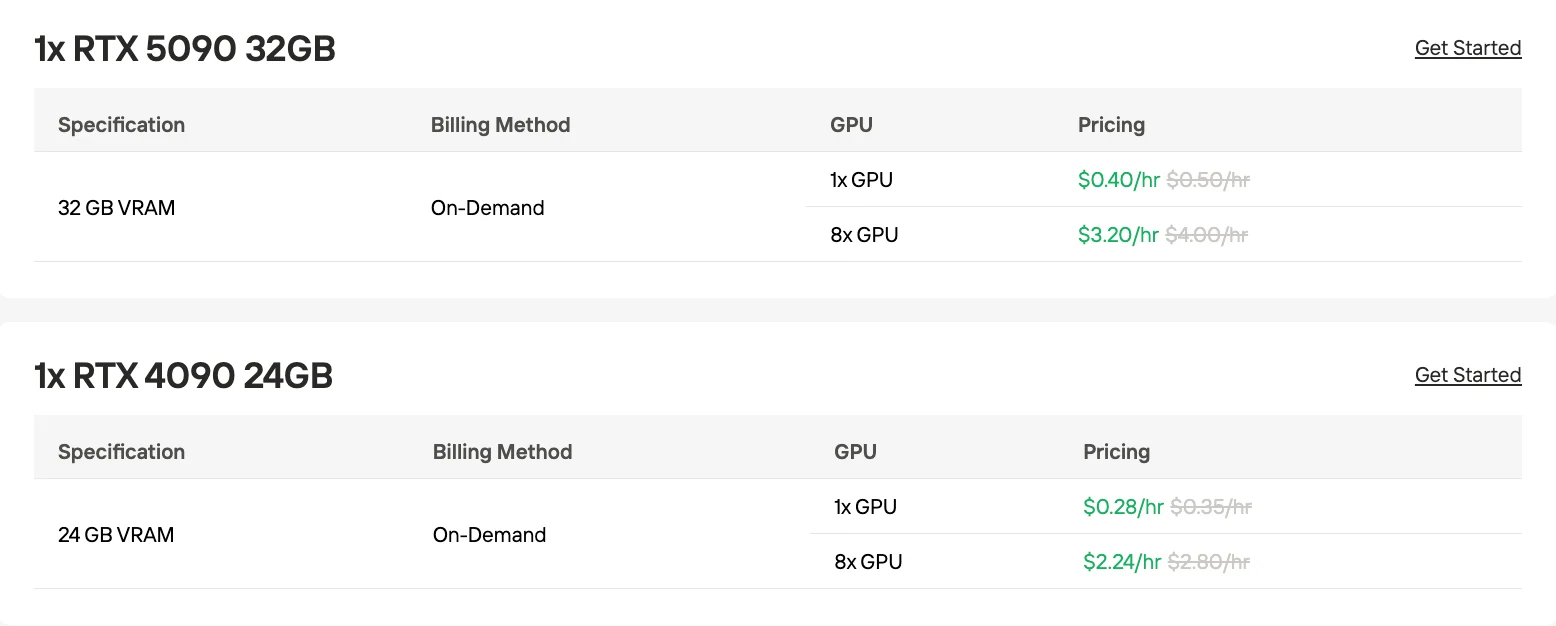
1. À la demande (pay-as-you-go)
C’est le modèle standard où vous payez la puissance de calcul GPU en fonction du temps d’exécution (par seconde/heure) sans contrat à long terme ni réservation. Il offre une flexibilité maximale et est idéal pour les charges de travail variables, les utilisations intermittentes et les expérimentations, puisque vous n’encourez des coûts que pendant le fonctionnement de l’instance. Le stockage et les ressources supplémentaires (par ex. disque, réseau) sont également facturés à l’usage.
Essayez un GPU rapide et pas cher dès maintenant !
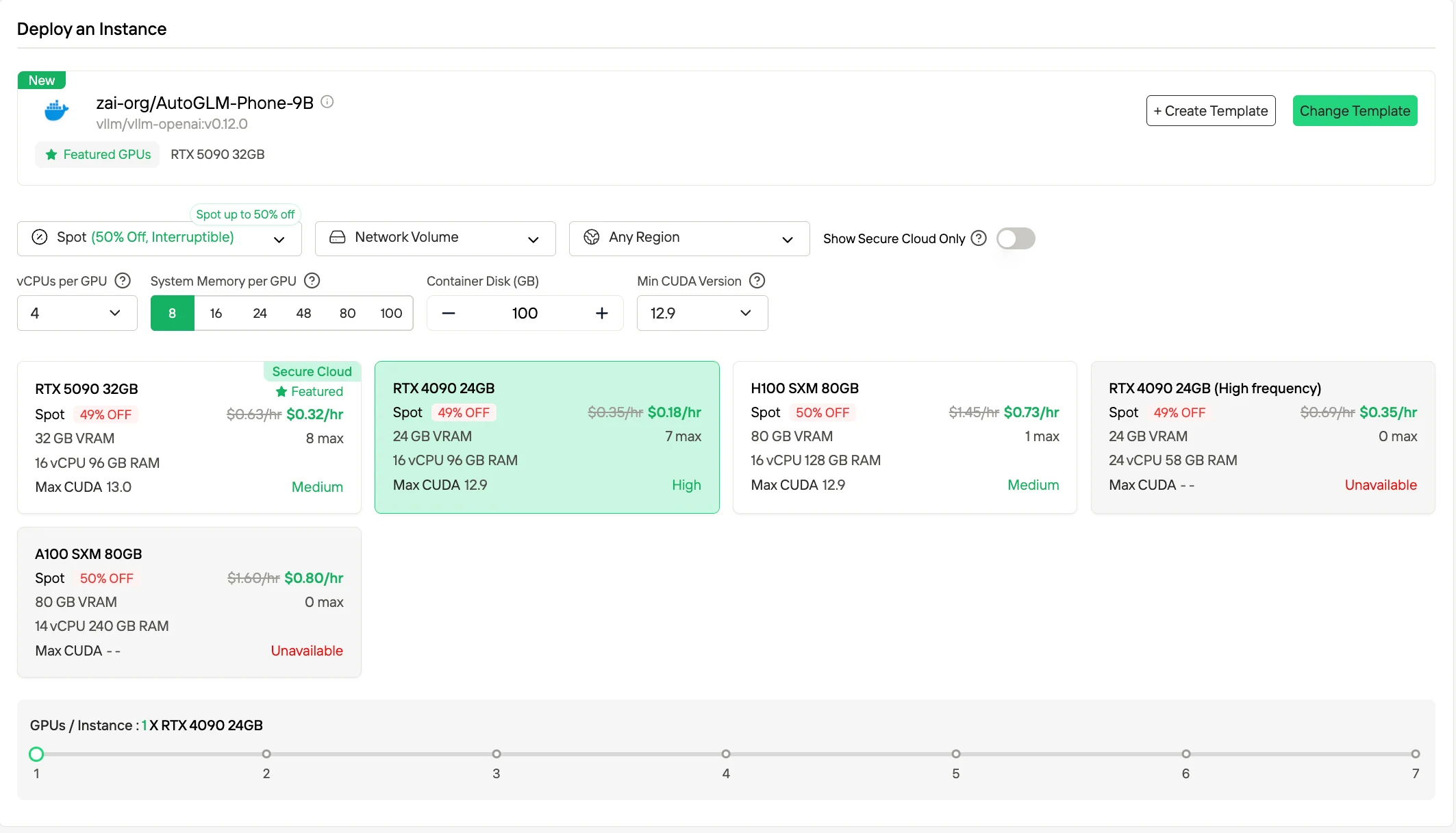
2. Instances Spot
La tarification Spot propose des tarifs horaires nettement plus bas (jusqu’à ~50 % de réduction) par rapport au modèle à la demande, en exploitant la capacité inutilisée. Ces instances peuvent être interrompues par la plateforme, mais Novita propose une fenêtre de protection garantie de 1 heure et des notifications d’interruption anticipées, rendant ce mode adapté aux charges de travail interruptibles ou aux tâches par lots pour lesquelles des interruptions occasionnelles sont acceptables.
3. Plans d’abonnement / réservés
Novita propose également des options d’abonnement mensuelles et annuelles pour les instances GPU. Ces plans offrent des ressources dédiées avec une disponibilité prévisible et sont souvent accompagnés de tarifs réduits par rapport à la tarification à la demande. Ce mode est avantageux pour les utilisateurs ayant des besoins de calcul stables et à long terme qui souhaitent réduire le coût unitaire grâce à un engagement.
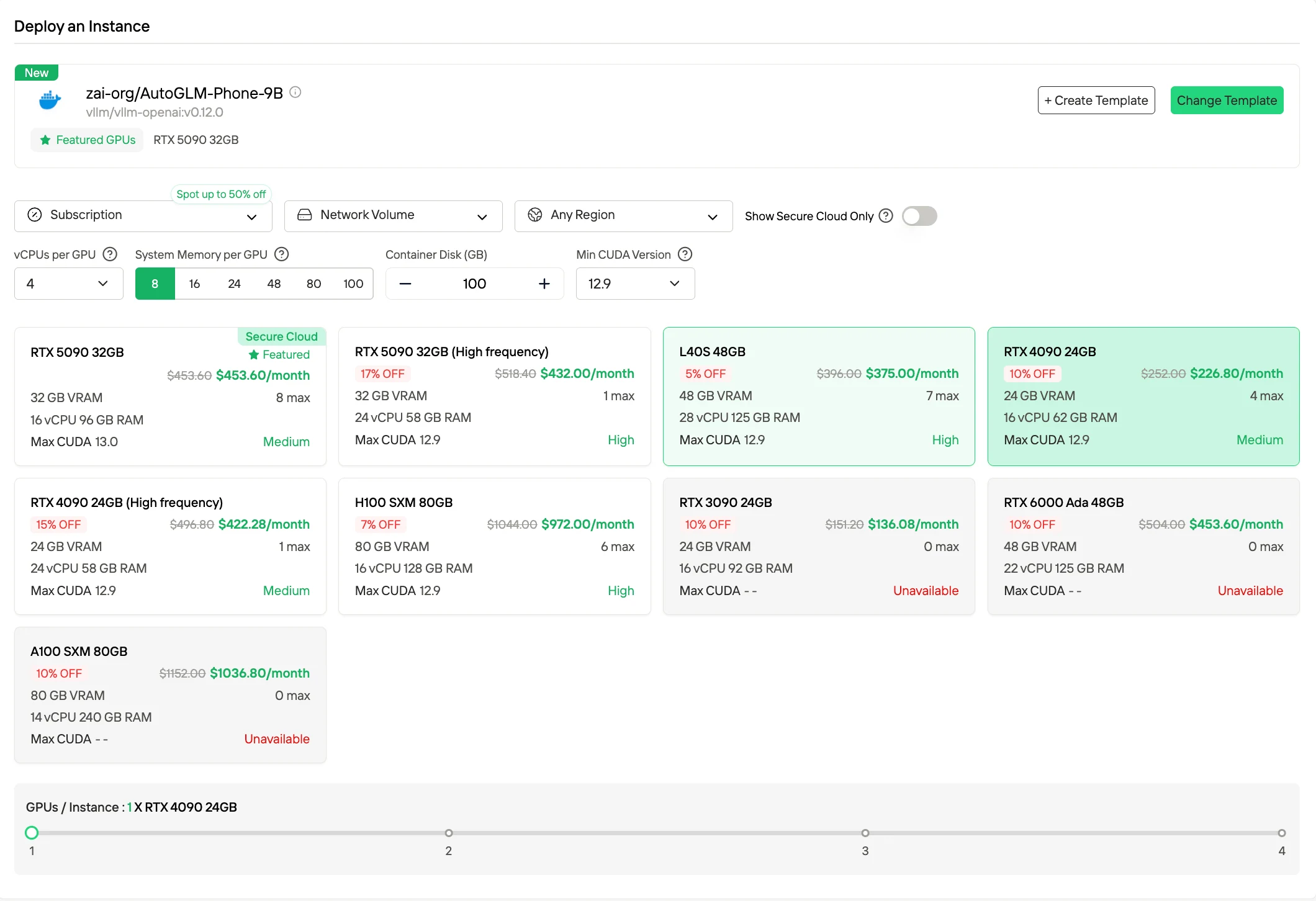
4. Facturation GPU serverless
En plus des modèles d’instances traditionnels, Novita prend en charge l’exécution GPU serverless, où les ressources s’adaptent automatiquement à la charge de travail et vous n’êtes facturé que pour les ressources de calcul consommées. Ce mode abstrait la gestion des instances et est optimisé pour les flux de travail présentant un trafic imprévisible ou très variable.
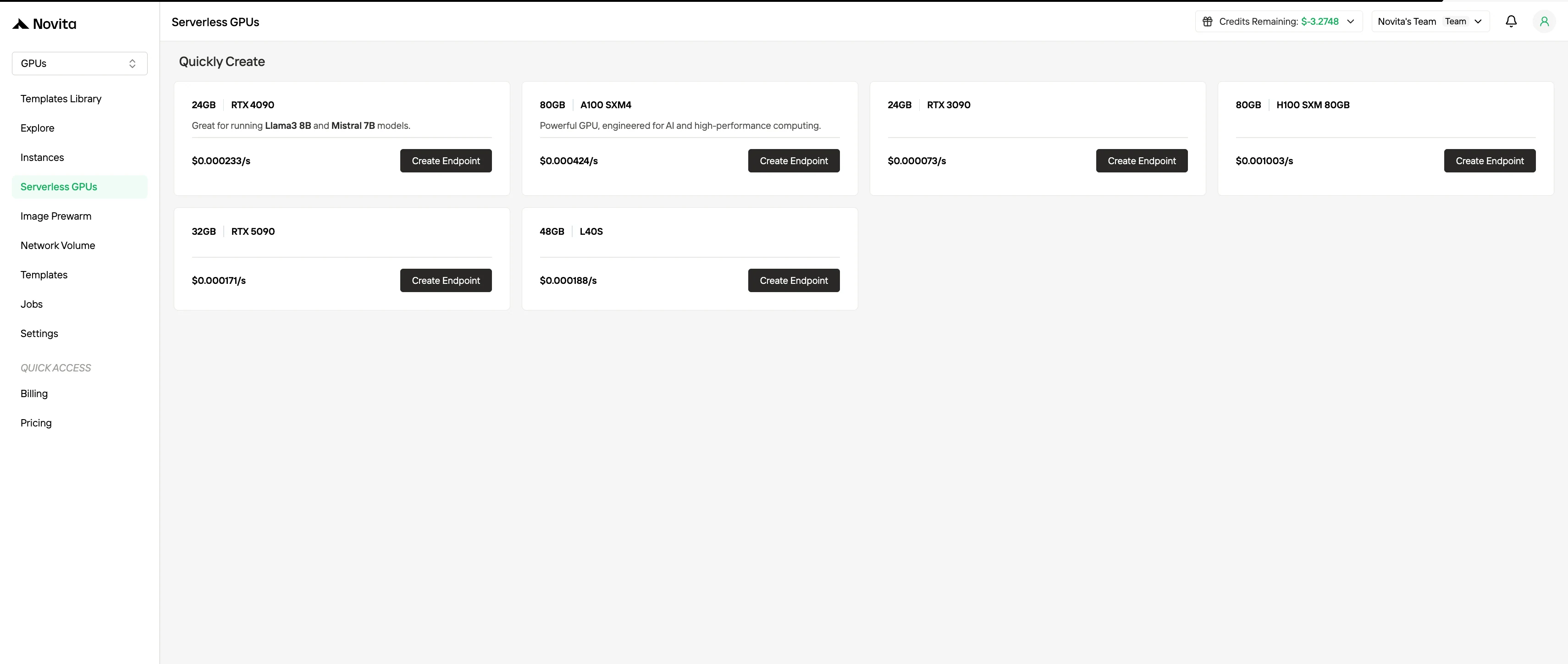
Novita AI propose également des modèles, conçus pour réduire considérablement la charge opérationnelle et cognitive associée au déploiement de charges de travail IA basées sur GPU. Au lieu de demander aux développeurs d’assembler manuellement des environnements from scratch, le système de modèles fournit des images préconfigurées, prêtes pour la production, qui regroupent le système d’exploitation, les versions de CUDA et cuDNN, les frameworks d’apprentissage profond, les moteurs d’inférence et, dans certains cas, même des piles de service de modèles entièrement préconfigurées.
Comment déployer ERNIE-4.5-VL-A3B sur Novita AI
Étape 1 : Créer un compte
Créez votre compte Novita AI via notre site web. Après l’inscription, rendez-vous dans la section « Explorer » dans la barre latérale gauche pour consulter nos offres GPU et commencer votre parcours de développement IA.

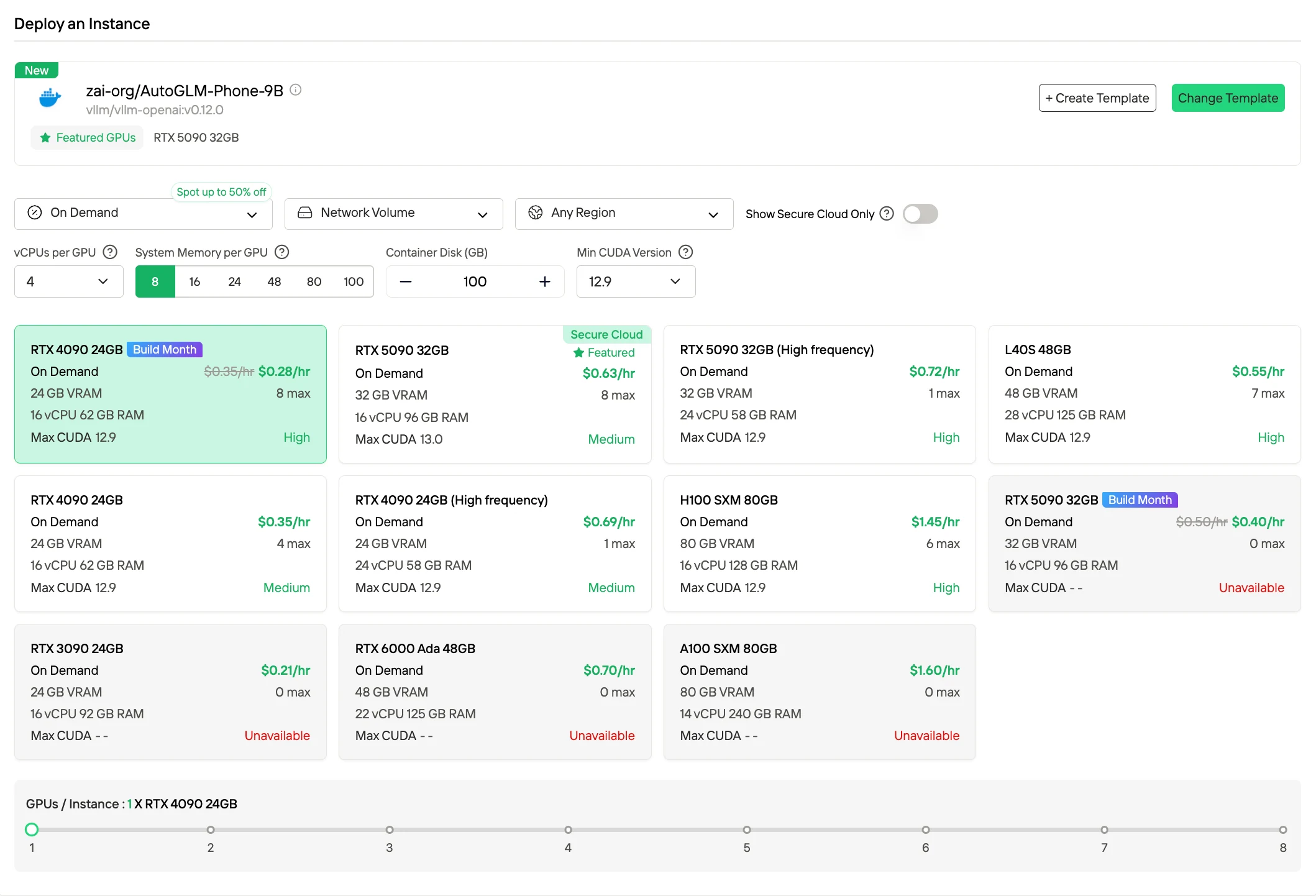
Étape 2 : Explorer les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA correspondant à vos besoins de projet. Sélectionnez ensuite votre configuration GPU préférée : les options incluent les puissants L40S, RTX 4090 ou A100 SXM4, chacun avec des spécifications différentes de VRAM, RAM et stockage.
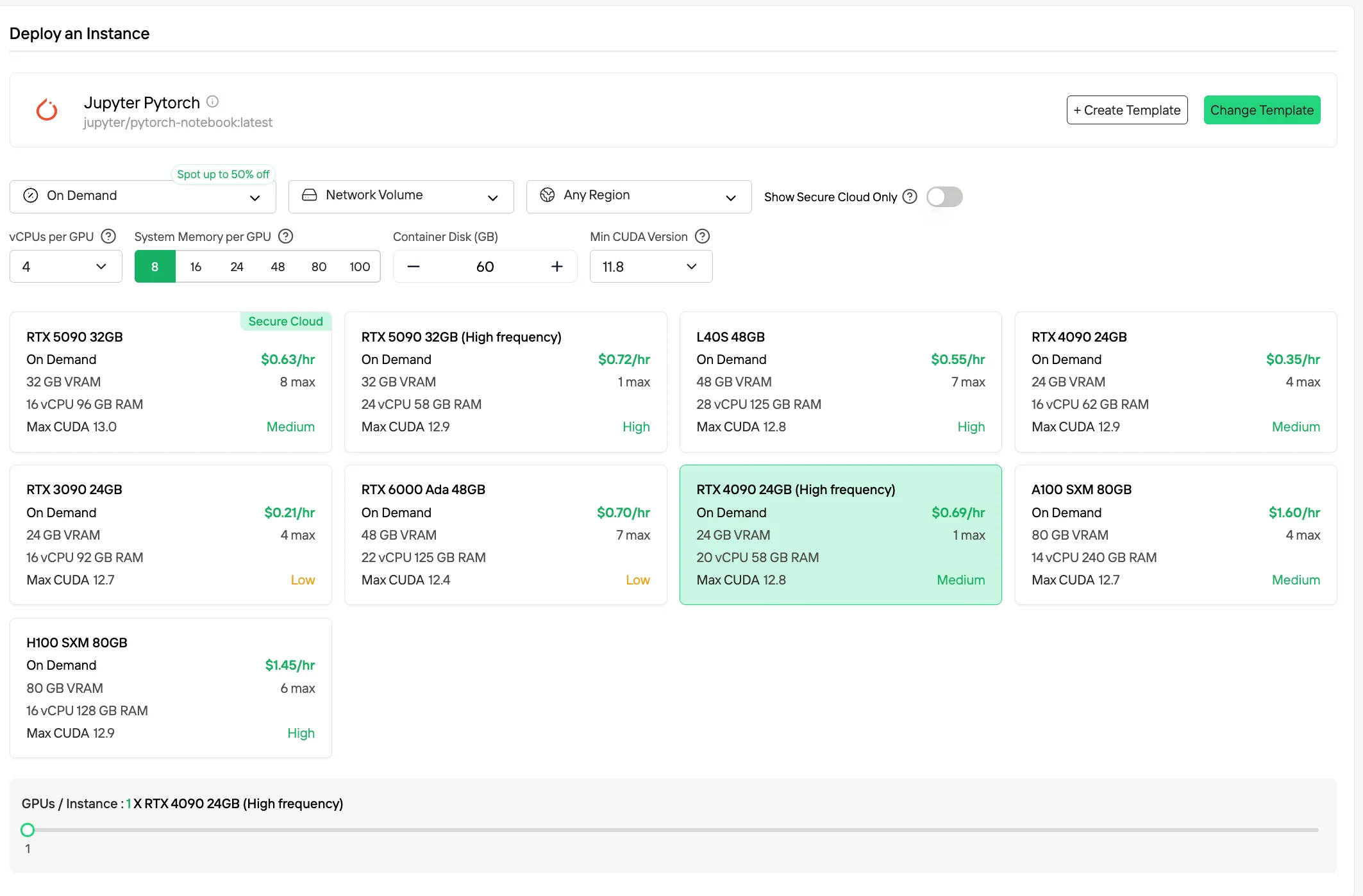
Étape 3 : Personnaliser votre déploiement et lancer une instance
Personnalisez votre environnement en sélectionnant votre système d’exploitation et vos options de configuration préférés pour garantir des performances optimales pour vos charges de travail IA et vos besoins de développement spécifiques. Votre environnement GPU haute performance sera alors prêt en quelques minutes, vous permettant de commencer immédiatement vos projets d’apprentissage automatique, de rendu ou de calcul.
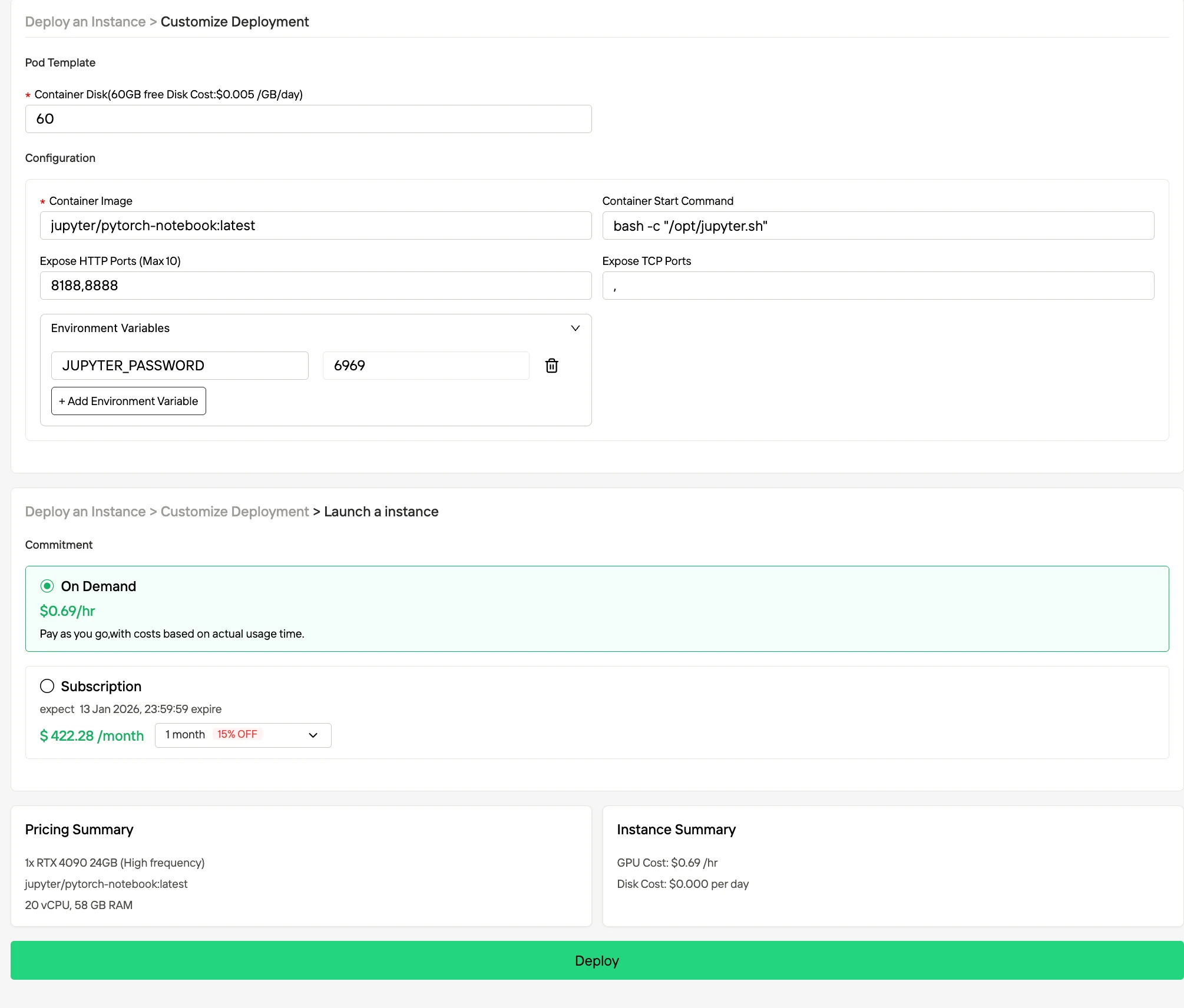
Étape 4 : Suivre la progression du déploiement
Rendez-vous dans la Gestion des instances pour accéder à la console de contrôle. Ce tableau de bord vous permet de suivre l’état du déploiement en temps réel.
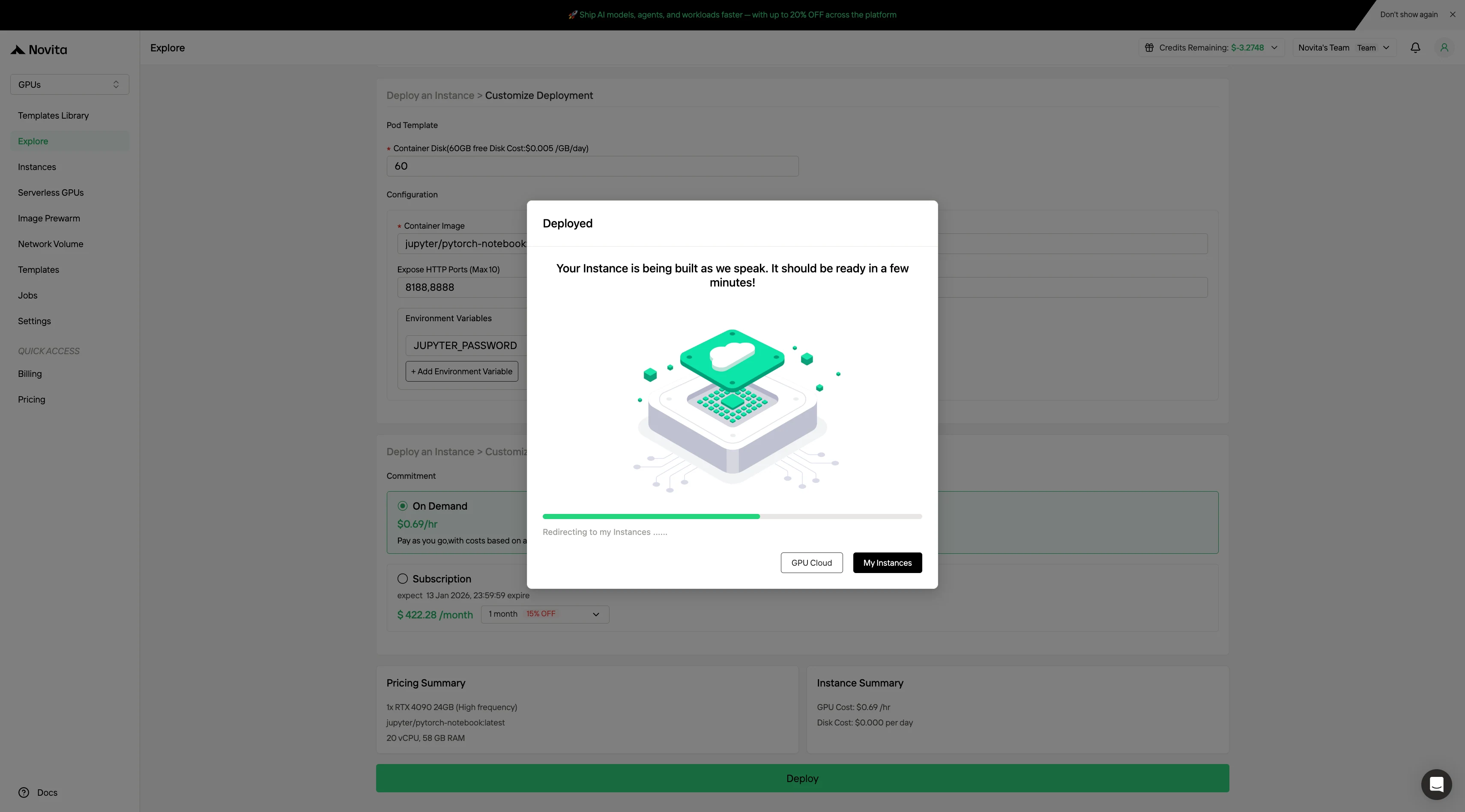
Essayez un GPU rapide et pas cher dès maintenant !
Étape 5 : Consulter l’état de téléchargement de l’image
Cliquez sur votre instance spécifique pour suivre la progression du téléchargement de l’image conteneur. Ce processus peut prendre plusieurs minutes selon les conditions du réseau.
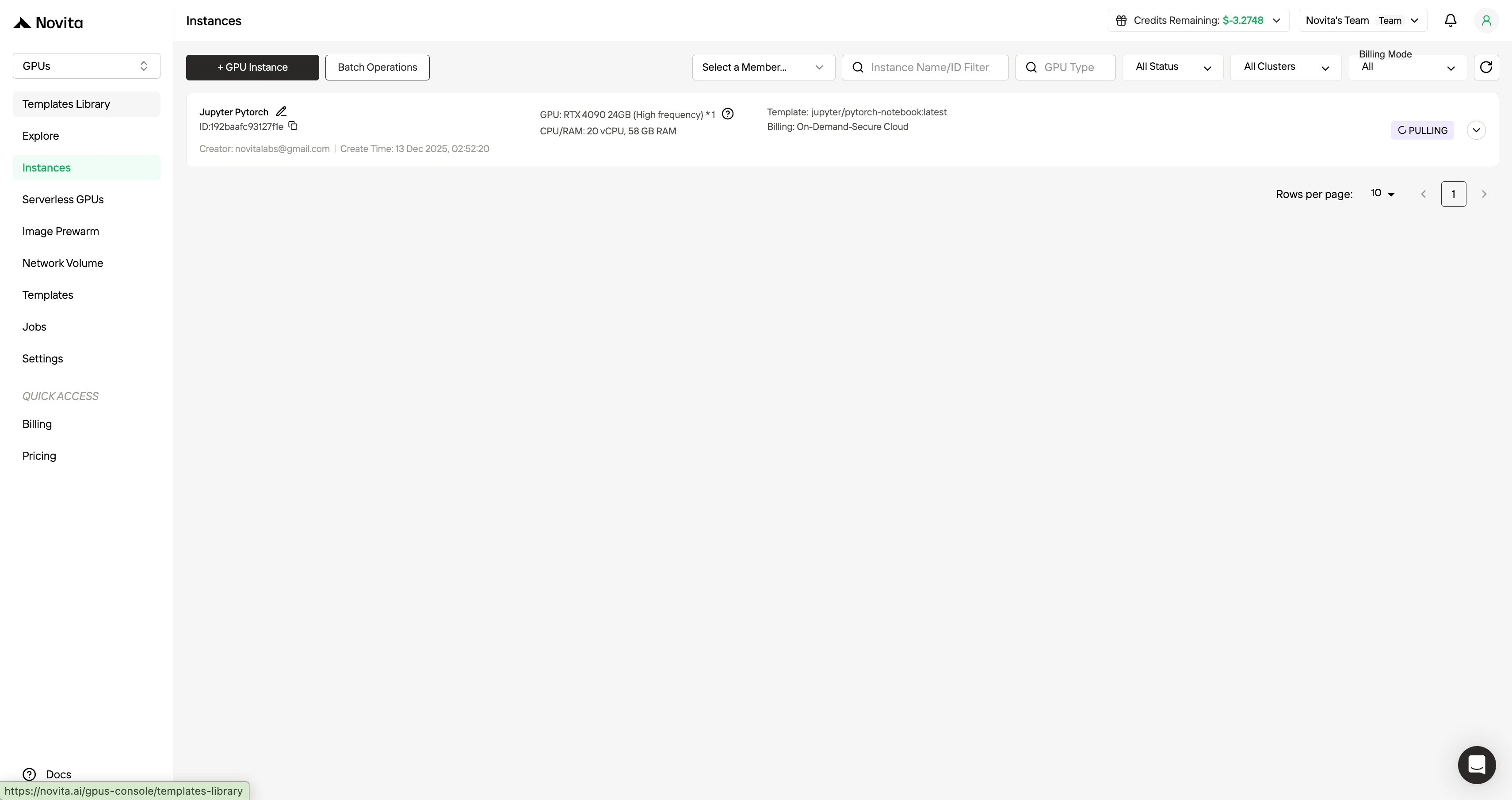
Étape 6 : Vérifier le déploiement réussi
Après le démarrage de l’instance, elle commencera à télécharger le modèle. Cliquez sur « Journaux » → « Journaux d’instance » pour suivre la progression du téléchargement du modèle. Recherchez le message
"Application startup complete."dans les journaux de l’instance. Cela indique que le processus de déploiement s’est terminé avec succès.Cliquez sur « Se connecter », puis sur → « Se connecter au service HTTP [Port 8000] ». Comme il s’agit d’un service API, vous devrez copier l’adresse.
Pour effectuer des requêtes sur votre modèle, veuillez remplacer « http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai » par votre adresse exposée réelle. Copiez le code suivant pour accéder à votre modèle privé !
ERNIE-4.5-VL-A3B nécessite une importante mémoire GPU et des investissements en infrastructure lorsqu’il est auto-hébergé, les coûts totaux s’étendant bien au-delà du GPU lui-même pour inclure les serveurs, le réseau, l’électricité et la main-d’œuvre d’ingénierie. À l’inverse, la plateforme cloud GPU de Novita AI réduit considérablement les coûts initiaux et à long terme grâce à des modèles de facturation flexibles, une scalabilité à la demande et des modèles prêts à l’emploi. Pour la plupart des équipes, accéder à ERNIE-4.5-VL-A3B via des GPU cloud offre un chemin plus rapide, moins cher et opérationnellement plus simple vers un déploiement de niveau production, sans sacrifier les performances ou la flexibilité.
Questions fréquemment posées
Quelle configuration GPU est recommandée pour ERNIE-4.5-VL-A3B ?
Il est recommandé d’exécuter ERNIE-4.5-VL-A3B sur 1× NVIDIA A100 (80 Go) ou H100, en utilisant la précision BF16 pour prendre en charge l’inférence à long contexte et à haute concurrence.
Quelle est la configuration GPU minimale requise pour ERNIE-4.5-VL-A3B ?
ERNIE-4.5-VL-A3B nécessite soit 2× RTX 3090/4090 (24 Go chacun, NVLink préférable), soit 1× RTX 6000 Ada (48 Go), avec quantification WINT8 pour réduire l’utilisation de la mémoire.
Pourquoi le déploiement local d’ERNIE-4.5-VL-A3B est-il coûteux ?
Le déploiement local d’ERNIE-4.5-VL-A3B implique non seulement des GPU haut de gamme, mais aussi des serveurs, du stockage, du réseau, du refroidissement, des améliorations électriques et un travail d’ingénierie important pour la migration et l’optimisation.
Novita AI est la plateforme cloud tout-en-un qui donne vie à vos ambitions IA. APIs intégrées, serverless, instances GPU — les outils rentables dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et concrétisez votre vision IA.



