

Novita AI 正在推出「Build Month」活動,為開發者提供所有主力產品最高 20% 的專屬優惠!
在實際場景中部署 ERNIE-4.5-VL-A3B 對開發者來說是一個明確的兩難:雖然這款模型具備優異的多模態推理效能,但其高 VRAM 需求與基礎設施成本使得本地部署複雜且昂貴。許多團隊在平衡硬體投資、遷移成本與運維擴展性時面臨困難,尤其是當目標是實現全精度推理、長上下文窗口與生產級併發處理時。本文將系統性地探討 ERNIE-4.5-VL-A3B 的硬體需求、真實本地部署成本,以及透過 Novita AI 獲取更高性價比的雲端 GPU 替代方案,同時提供實用的逐步部署路徑,幫助開發者快速、可靠地開始使用。
ERNIE-4.5-VL-A3B VRAM 需求
推薦配置
- GPU: 1 × NVIDIA A100 (80 GB) 或 H100
- VRAM 使用量: 約 70–75 GB
- 適用場景: 全精度推理(BF16)、最大上下文長度(128k),以及生產負載下的高併發批次處理。
最低配置
- GPU: 2 × NVIDIA RTX 3090 或 RTX 4090(各 24 GB,優先使用 NVLink),或 1 × RTX 6000 Ada (48 GB)
- VRAM 使用量: 需要超過 48 GB
- 量化: 明確支援 WINT8(僅權重 INT8)以降低記憶體佔用。
ERNIE-4.5-VL-A3B 本地部署成本是多少?
自建托管不僅僅是 GPU 成本:伺服器、網路、散熱與供電基礎設施會大幅增加前期總投入。
遷移/升級成本絕大多數來自工程時間與整合工作;即使現有硬體可部分重複使用,軟體堆疊遷移、擴展編排與效能調優也並非易事,需要專注的勞動力投入。
| 成本類別 | 生產級高階配置 | 最低自托管配置(量化後) | 增量遷移/升級成本 |
|---|---|---|---|
| GPU 硬體 | NVIDIA H100 80GB NVIDIA H100 NVL $29,700–$42,700 |
NVIDIA A100‑80G NVIDIA A100 80G $30,000–$42,000 |
若更換舊款消費級 GPU(如 3090/4090),增量成本約為新卡售價減去舊卡殘值;每張新增的專業 GPU 升級差價約為 $25,000–$40,000。 |
| 配套系統(伺服器、電源、散熱、網路) | $15,000–$40,000+(企業級機箱、高功率電源、機櫃、10/25/100GbE 網路) | $5,000–$15,000(工作站級伺服器、NVLink 橋接器) | 視情況而定——在生產級升級場景中,您很可能需要全新的伺服器基礎設施來容納 H100/A100。升級舊機箱通常需要 $10,000–$30,000 用於伺服器改裝、線材與 NVLink。 |
| 儲存與記憶體 | $2,000–$6,000(NVMe + ECC RAM) | $1,000–$3,000 | 若重用現有儲存則成本較低,否則需 $1,000–$2,000 |
| 網路 | $2,000–$8,000 | $500–$2,000 | |
| 場地與供電升級 | $5,000–$15,000(UPS、散熱優化) | $1,000–$5,000 | 取決於場地升級需求,通常為 $3,000–$10,000 |
| 遷移/整合工程 | $15,000–$50,000(100–300+ 小時工程工作量) | $10,000–$30,000(80–200+ 小時) | 對於從消費級 GPU 遷移至這些專業卡的團隊,整合工作包含模型伺服器重配置、驅動與 CUDA/NCCL 環境遷移、效能基線建立與自動化——通常需要 $15,000–$40,000 的人力成本,取決於團隊內部技能水平。 |
存取 ERNIE-4.5-VL-A3B 雲端 GPU 的更優選擇
Novita AI 的雲端 GPU 平台支援多種計費模式,使用者可根據工作負載模式匹配成本與穩定性:
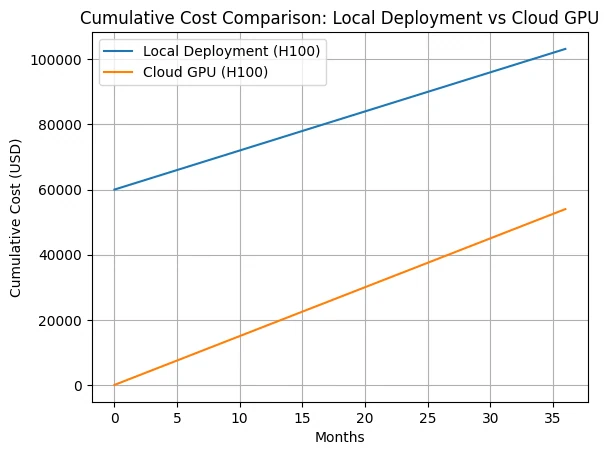
如圖所示的 36 個月週期內,雲端 GPU 的累計成本仍顯著更低,兩者差距幾乎完全來自前期避免的資本支出(CapEx)。
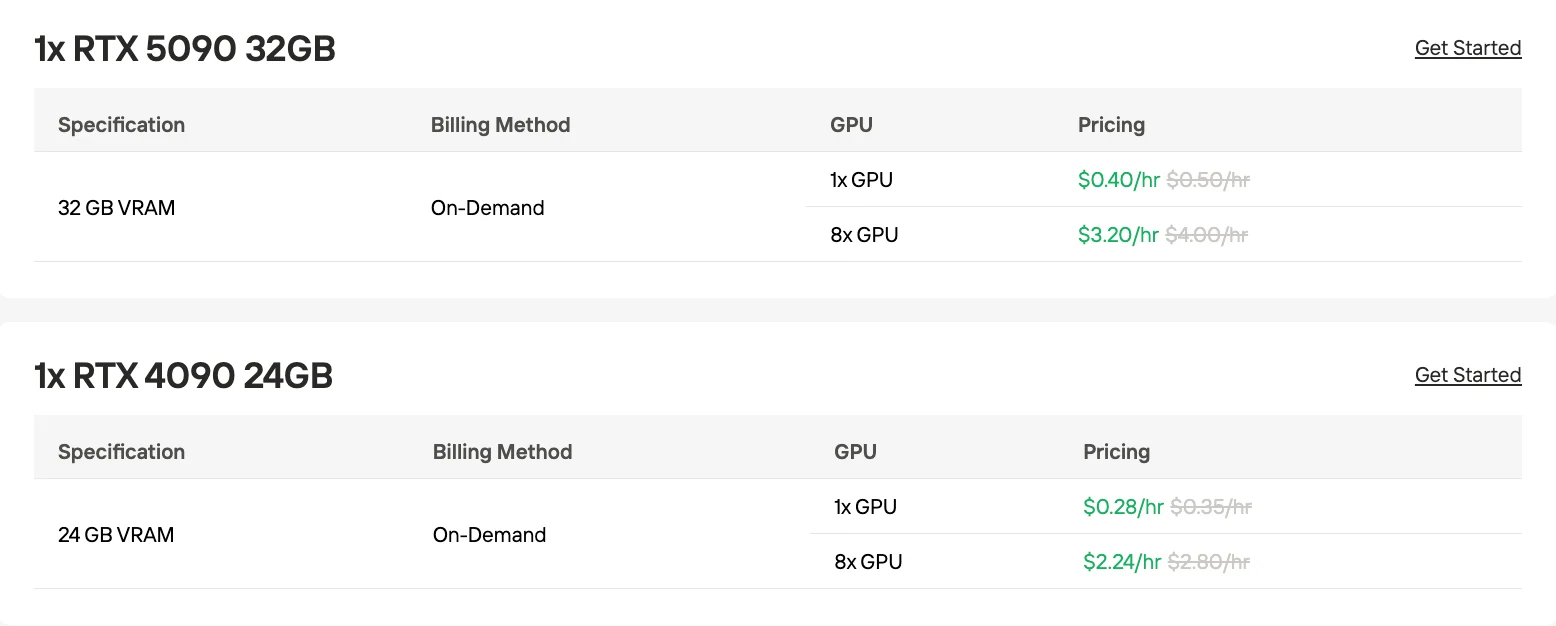
1. 隨需付費(Pay-as-you-go)
這是標準計費模式,您按運行時長(每秒/每小時)支付 GPU 運算費用,無需長期合約或預訂。它提供最大的靈活性,非常適合可變工作負載、間歇性使用與實驗場景,因為您僅需為實例運行期間的成本付費。儲存與其他資源(如磁碟、網路)也按使用量計費。
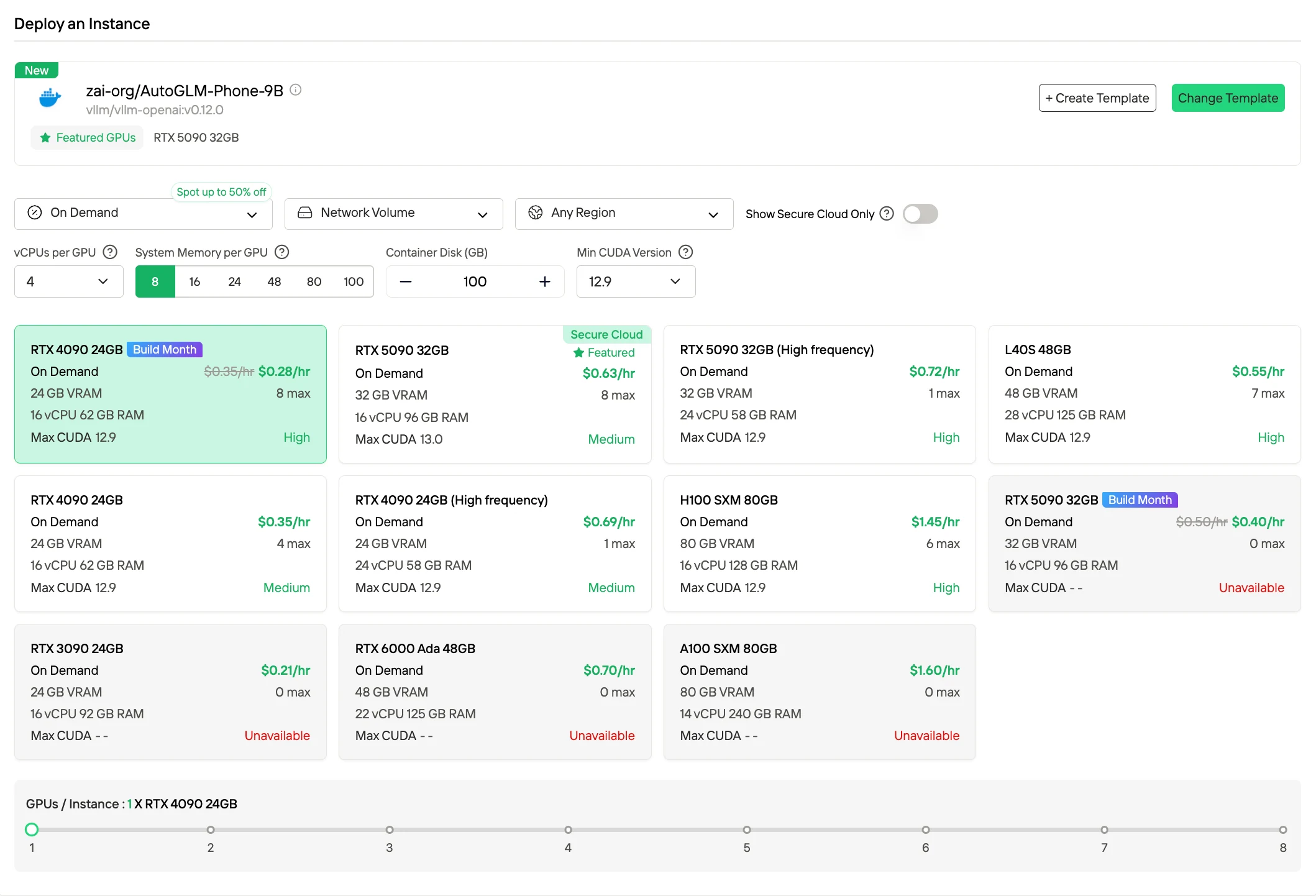
2. 搶占式實例
搶占式定價透過利用閒置容量,提供比隨需付費低得多的每小時費率(通常折扣高達約 50%)。這類實例可能被平台搶占,但 Novita 提供 1 小時的保護窗口與提前終止通知,非常適合可中斷的工作負載或批次作業,這類場景允許偶爾的運行中斷。
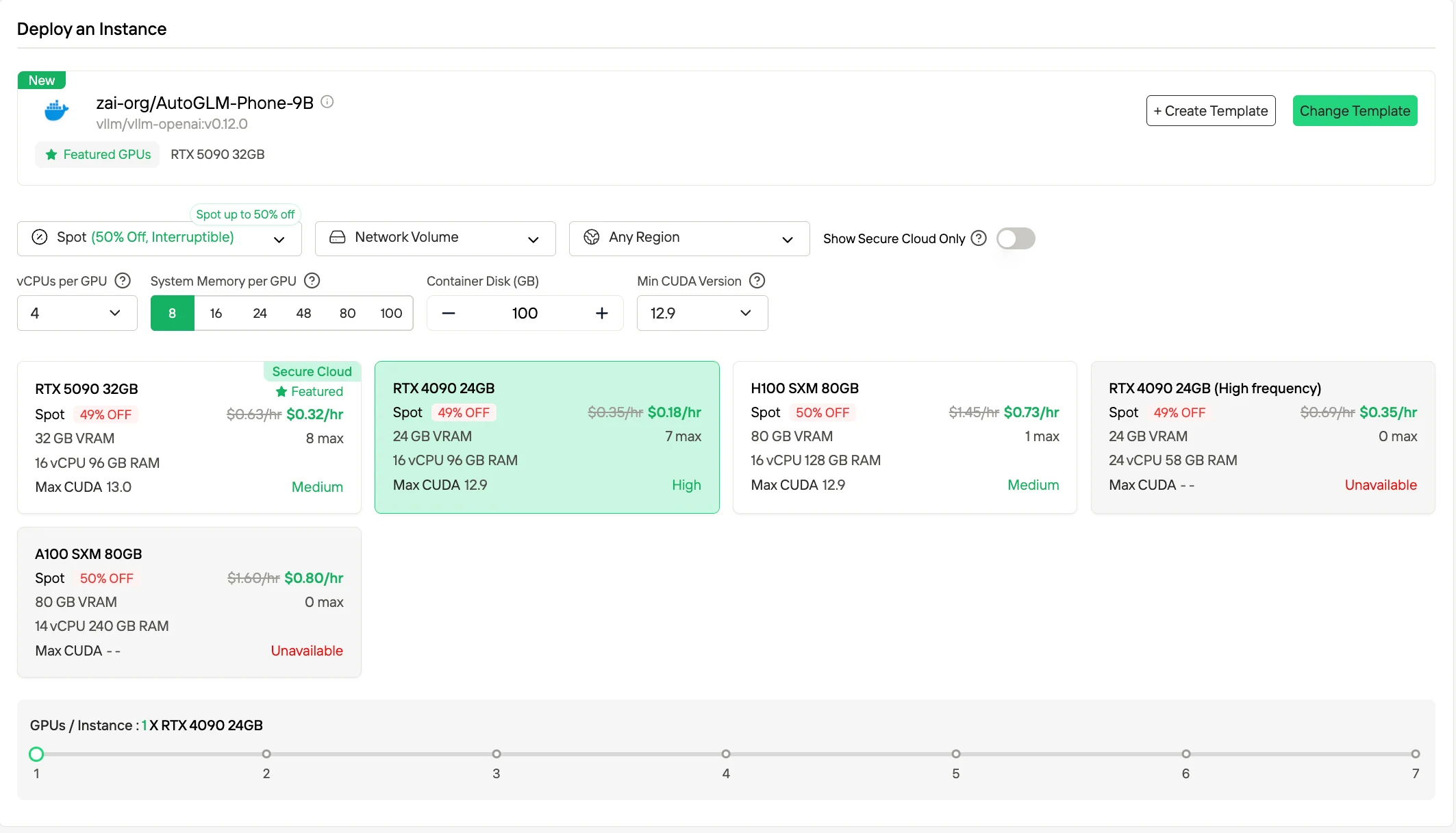
3. 訂閱/預留方案
Novita 也提供 GPU 實例的月付與年付訂閱選項。這些方案提供專屬資源與可預測的可用性,費率通常比隨需付費更低。此模式適合有穩定長期運算需求的用戶,可透過承諾使用降低單位成本。
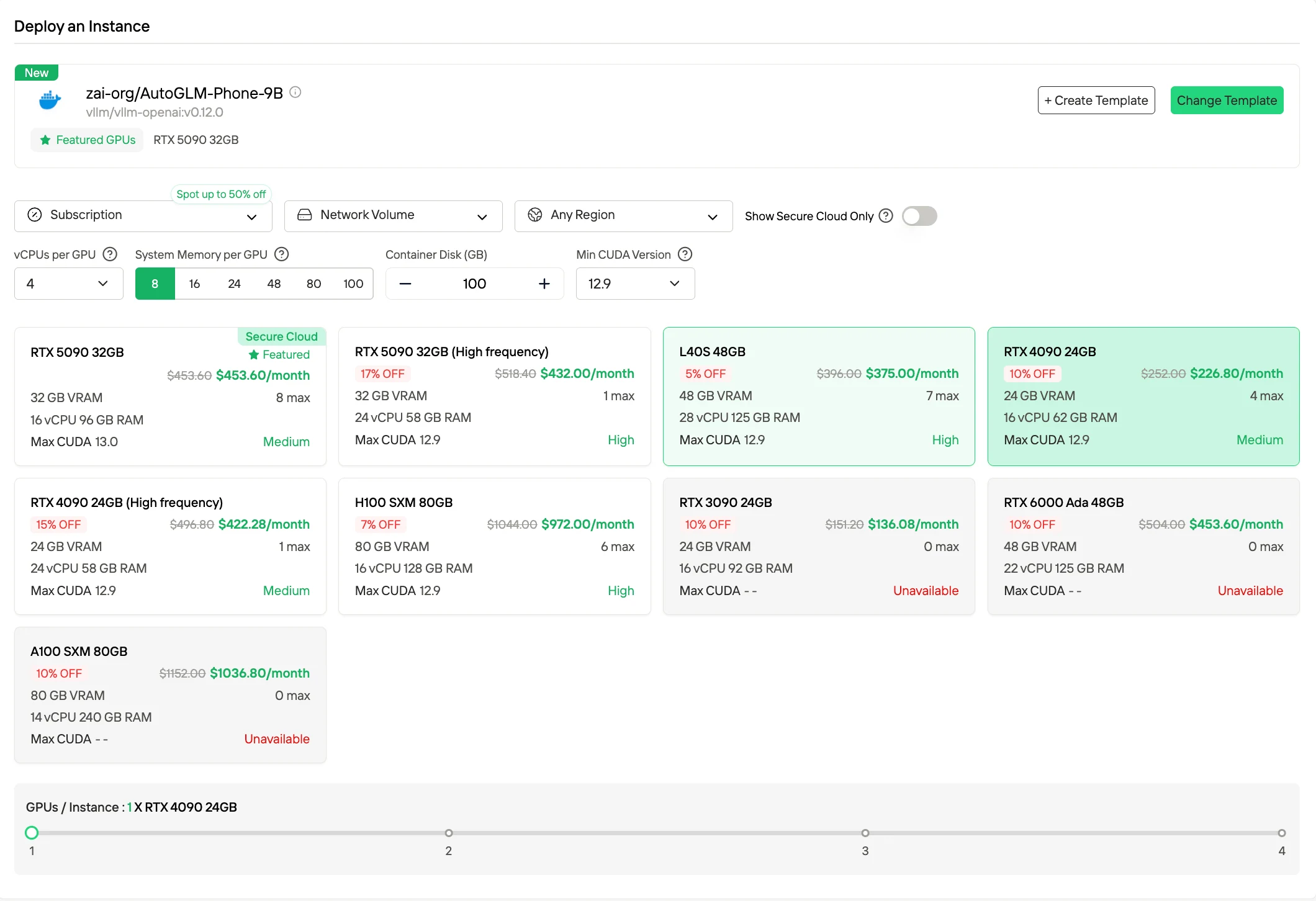
4. 無伺服器 GPU 計費
除了傳統實例模式外,Novita 還支援無伺服器 GPU 執行,資源會根據工作負載自動擴展,您僅需為實際消耗的運算資源付費。此模式抽象化了實例管理,針對不可預測或流量變化極大的工作流程進行了優化。
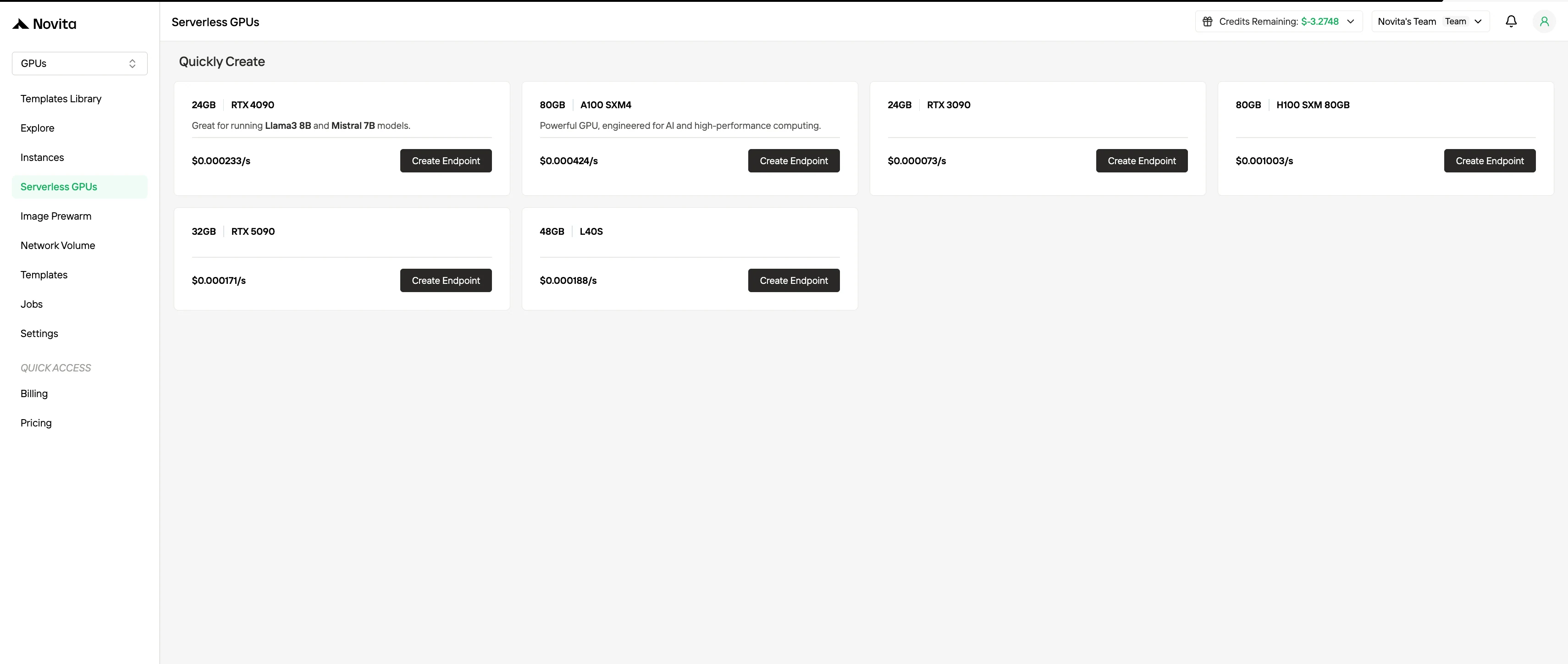
Novita AI 也提供模板功能,旨在大幅降低部署 GPU 型 AI 工作負載的運維與認知成本。相較於要求開發者從零開始手動組裝環境,模板系統提供預先配置、可直接用於生產的映像檔,捆綁了作業系統、CUDA 與 cuDNN 版本、深度學習框架、推理引擎,部分情況下甚至包含完整配置的模型服務堆疊。
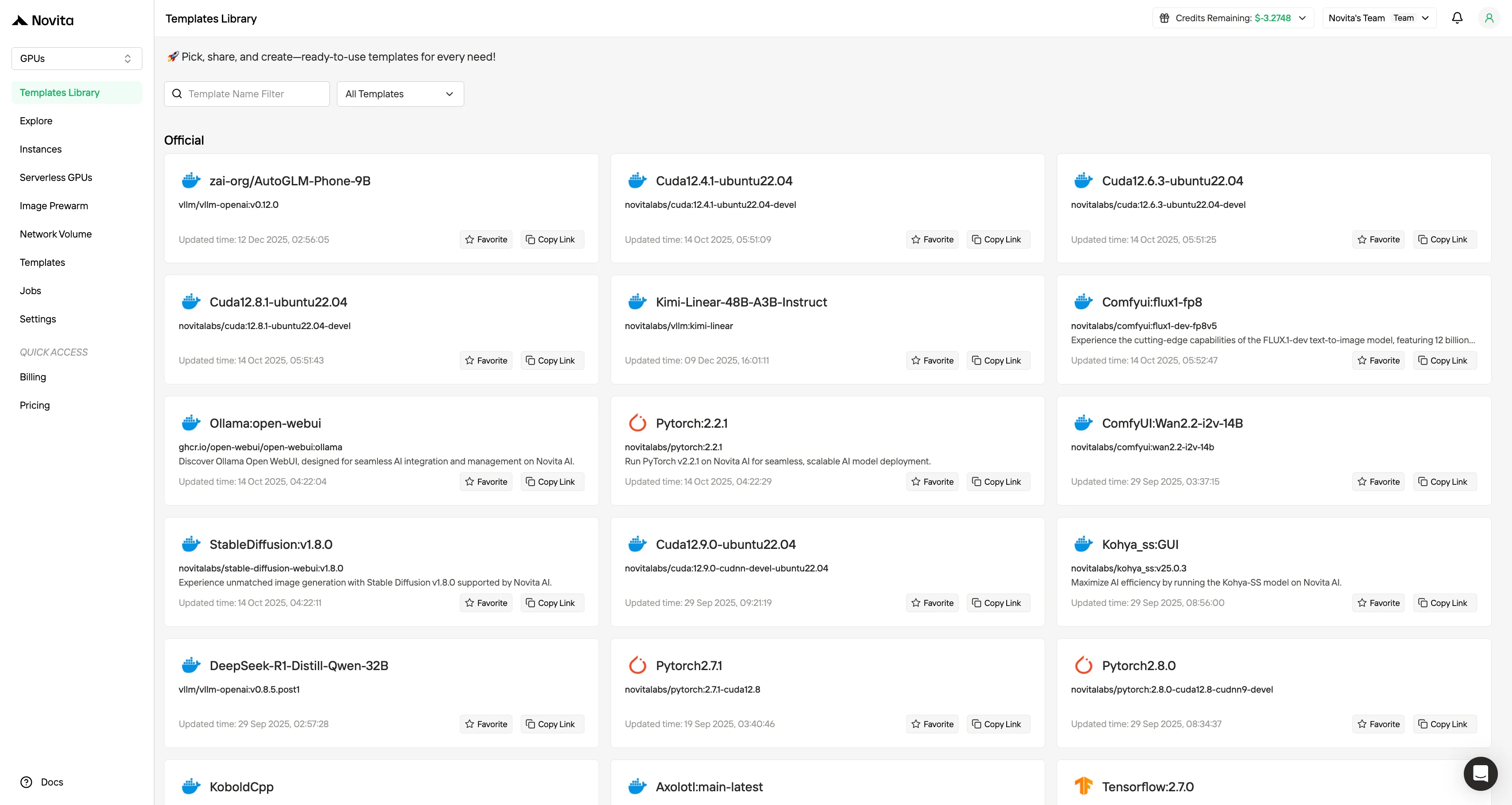
如何在 Novita AI 上部署 ERNIE-4.5-VL-A3B
步驟 1:註冊帳號 透過我們的官方網站建立 Novita AI 帳號。註冊完成後,前往左側邊欄的「Explore」區塊查看我們的 GPU 產品,開始您的 AI 開發之旅。

步驟 2:瀏覽模板與 GPU 伺服器 根據您的專案需求選擇對應的模板,如 PyTorch、TensorFlow 或 CUDA。接著選擇您偏好的 GPU 配置——可選方案包括強大的 L40S、RTX 4090 或 A100 SXM4,每款配備不同的 VRAM、RAM 與儲存規格。
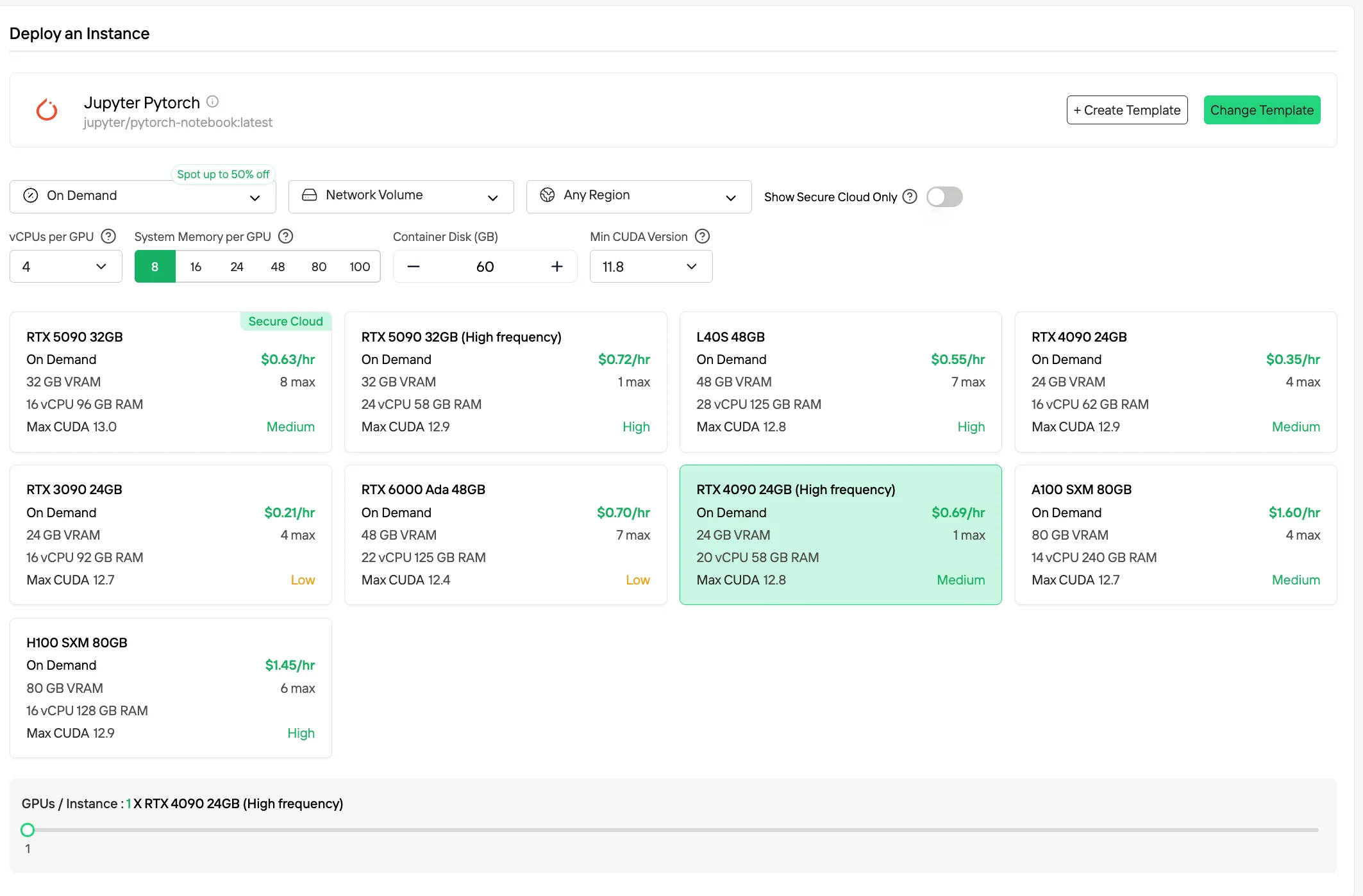
步驟 3:自訂部署並啟動實例 透過選擇您偏好的作業系統與配置選項自訂環境,確保您的 AI 工作負載與開發需求能獲得最佳效能。完成後,您的高效能 GPU 環境將在幾分鐘內就緒,可立即開始您的機器學習、渲染或運算專案。
步驟 4:監控部署進度 前往實例管理頁面進入控制台,此儀表板可讓您即時追蹤部署狀態。
步驟 5:查看映像檔拉取狀態 點擊對應的實例,監控容器映像檔的下載進度。此過程可能需要數分鐘,取決於網路狀況。
步驟 6:驗證部署成功
實例啟動後,會開始拉取模型。點擊「Logs」→「Instance Logs」監控模型下載進度。在實例日誌中尋找
"Application startup complete."訊息,這表示部署流程已成功完成。點擊「Connect」,接著點擊 →「Connect to HTTP Service [Port 8000]」。由於這是 API 服務,您需要複製對應地址。
要對您的模型發送請求,請將***
[http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai](http://7a65a32b51e37482-8000.jp-tyo-1.gpu-instance.novita.ai&/#8221)*** 替換為您實際對外暴露的地址,複製以下程式碼即可存取您的私有模型!
ERNIE-4.5-VL-A3B 在自托管時需要大量的 GPU 記憶體與基礎設施投入,總成本遠超 GPU 本身,還包含伺服器、網路、供電與工程人力成本。相比之下,Novita AI 的雲端 GPU 平台透過靈活的計費模式、隨需擴展能力與開箱即用的模板,大幅降低了前期與長期成本。對大多數團隊而言,透過雲端 GPU 存取 ERNIE-4.5-VL-A3B 是更快速、更便宜、運維更簡單的生產級部署路徑,且無需犧牲效能或靈活性。
常見問題
ERNIE-4.5-VL-A3B 推薦使用什麼 GPU 配置? 推薦使用 1 張 NVIDIA A100(80 GB)或 H100 運行 ERNIE-4.5-VL-A3B,採用 BF16 精度以支援長上下文與高併發推理。
ERNIE-4.5-VL-A3B 最低需要什麼 GPU 配置? ERNIE-4.5-VL-A3B 需要配置 2 張 RTX 3090/4090(各 24 GB,優先使用 NVLink) 或 1 張 RTX 6000 Ada(48 GB),並搭配 WINT8 量化以降低記憶體使用量。
為什麼 ERNIE-4.5-VL-A3B 的本地部署成本如此高昂? ERNIE-4.5-VL-A3B 的本地部署不僅需要高階 GPU,還涉及伺服器、儲存、網路、散熱、供電升級,以及大量的遷移與優化工程工作。
Novita AI 是實現您 AI 抱負的一站式雲端平台。整合 API、無伺服器服務、GPU 實例——您需要的高性價比工具。免除基礎設施負擔,免費開始,讓您的 AI 願景成為現實。



