

管理大型程式碼庫或多文件工作流程的開發者,在使用傳統 Transformer 模型時會持續面臨挑戰,包括高運算成本、不穩定的長上下文效能,以及不一致的程式碼理解。這些限制降低了迭代效率,限制了倉儲級別的分析,並增加了營運支出。DeepSeek V3.2 的推出透過整合 DeepSeek 稀疏注意力(DSA) 解決了這些痛點,這是一種旨在降低注意力開銷、加速上下文推理,並穩定程式碼生成的機制。
本文探討 DeepSeek V3.2 如何提升成本效率、長上下文處理能力及程式碼相關功能。文章將提供透過 Novita AI 與 Claude Code 部署 DeepSeek V3.2 的操作指引。
請注意!Novita AI 正在推出「建構月」活動,為開發者提供所有主要產品最高 20% 的獨家優惠!
DeepSeek V3.2 新增了哪些程式碼相關功能?
DSA 是一種革命性的注意力機制,從根本上改變了模型處理資訊的方式。傳統 Transformer 要求每個 token 與所有其他 token 進行交互,導致二次方運算成本(O(n²)),而 DSA 則引入了細粒度、內容感知的選擇機制:
- 智慧過濾:在訓練過程中,模型學會識別哪些 token 關係對特定任務真正重要
- 動態連接:根據輸入內容即時選擇必要的注意力連接。
- 任務最佳化:處理程式碼與處理法律文件時,會聚焦於不同的結構模式。
DSA 帶來的三大核心改進
採用直接自適應作為輔助機制,在不改變核心架構的前提下提升整體模型效能。透過這種方法,模型實現了顯著的成本效率,支援更經濟的推論,同時維持與 v3.1 相當的程式碼生成與分析品質,從而支援頻繁測試與快速迭代。
DSA 也強化了長上下文利用率,有效運用高達 128K token 的上下文視窗,從而改進同時多文件分析、跨文件依賴理解,以及複雜技術文件的處理。
此外,DSA 有助於提升程式碼相關能力,包括更快的推論回應、更準確的程式碼理解,以及更穩定的程式碼生成品質,共同增強模型在大規模軟體開發場景中的可靠性與效率。
可擴展的強化學習框架
透過採用穩健的強化學習協議並擴展訓練後計算,DeepSeek-V3.2 達到了與 GPT-5 相當的效能。值得注意的是,高運算版本 DeepSeek-V3.2-Speciale 持續超越 GPT-5,並展現出與 Gemini-3.0-Pro 相當的推理能力。
| 基準測試 | 指標 | DeepSeek-V3.2-Speciale | DeepSeek-V3.2-Thinking | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 96.0 | 93.1 | 94.6 | 87.0 | 95.0 |
| HMMT 2025 | Pass@1 (%) | 99.2 | 90.2 | 88.3 | 79.2 | 97.5 |
| HLE | Pass@1 (%) | 30.6 | 25.1 | 26.3 | 13.7 | 37.7 |
| Codeforces | 評分 | 2701 | 2386 | 2537 | 1480 | 2708 |
| SWE Verified | 解決率 (%) | – | 73.1 | 74.9 | 77.2 | 76.2 |
| Terminal Bench 2.0 | 準確率 (%) | – | 46.4 | 35.2 | 42.8 | 54.2 |
| τ² Bench | Pass@1 (%) | – | 80.3 | 80.2 | 84.7 | 85.4 |
| Tool Decathlon | Pass@1 (%) | – | 35.2 | 29.0 | 38.6 | 36.4 |
DeepSeek V3.2:為了更好地與開發者協作做了哪些改進?
為了更好地將推理整合到工具使用場景中,DeepSeek 在 V3.2 的訓練後階段引入了一個 大規模代理任務合成管線。核心概念是系統性地大規模生成代理訓練資料,而非依賴於手工編寫的提示或有限的人類示範。
此管線以程式化方式建構任務,要求模型進行推理、決策、呼叫工具、觀察中間結果,並相應調整其行為。透過讓模型接觸各種結構化互動,DeepSeek 實現了可擴展的代理訓練後階段,顯著提升了在複雜、多步驟互動環境(如搜尋、編碼和工具增強工作流程)中的行為合規性和泛化能力。
兩個最重要的更新是:
一個 修訂後的工具呼叫格式,設計得更明確且在多步驟互動中更穩定
原生支援 「使用工具思考」,其中推理和工具使用在結構上整合,而非鬆散交錯
為了幫助社群理解和採用這個新模板,DeepSeek 提供了一個專用的 encoding 資料夾。該資料夾包含 Python 腳本和測試案例,展示:如何將 OpenAI 相容訊息編碼為 DeepSeek-V3.2 預期的單一輸入字串,以及如何將模型的文字輸出解析回結構化訊息。
import transformers
# encoding/encoding_dsv32.py
from encoding_dsv32 import encode_messages, parse_message_from_completion_text
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2")
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
encode_config = dict(thinking_mode="thinking", drop_thinking=True, add_default_bos_token=True)
prompt = encode_messages(messages, **encode_config)
tokens = tokenizer.encode(prompt)
值得注意的是,本次發布不包含基於 Jinja 的聊天模板。提供的 Python 實作是權威參考。此外,輸出解析函數假設模型輸出格式良好,僅供示範和實驗使用,未經額外錯誤處理不建議直接用於生產環境。
為什麼需要開發者角色
在真實的代理場景中,模型通常需要同時處理三種不同類型的資訊:
- 使用者的實際意圖或任務目標
- 模型自身的推理與決策過程
- 系統或開發者提供的搜尋策略、工具限制與執行規則
在早期版本中,這些訊號通常混合在使用者或系統提示中。隨著時間推移,這導致了兩個主要問題。首先,模型可能難以區分使用者意圖與強制行為限制。其次,隨著工具鏈變得更加複雜,工具呼叫的穩定性和可靠性明顯下降。
DeepSeek-V3.2 引入的 developer 角色本質上扮演了 搜尋代理和工具導向代理 的專用 控制通道。它旨在承載與代理行為嚴格相關的指令,例如搜尋範圍、工具使用順序或政策限制,而不參與一般對話語義。這種明確的分離實現了更清晰的上下文理解,並為更可擴展和更穩健的代理訓練奠定了結構基礎。
如何在 Claude Code 中存取 DeepSeek V3.2?
Novita AI 目前提供最具成本效益的全上下文 Deepseek V3.2 API。
*Novita AI 提供 **65K 上下文 ** 的 API,成本為 *$0.269/輸入 ** 和 $0.4/輸出,支援結構化輸出和函數呼叫,為充分發揮 Deepseek V3.2 的程式碼代理潛力提供了強力支援。
快取讀取:$0.1345 / M Token 表示快取命中時讀取快取 token 的成本。這些 token 先前已被計算並儲存,因此無需額外模型推理。在許多請求共享相同提示前綴、重複使用對話歷史、工具指令或固定規則文字的系統中,或者 RAG 檢索結果高度重複的情況下,可以實現高快取命中率,從而顯著降低整體推理成本。
第一步:取得 API 金鑰
步驟 1:登入您的帳戶,然後點選「模型庫」按鈕。

步驟 2:選擇您的模型
瀏覽可用選項,選擇適合您需求的模型。

步驟 3:開始免費試用
開始免費試用,探索所選模型的能力。
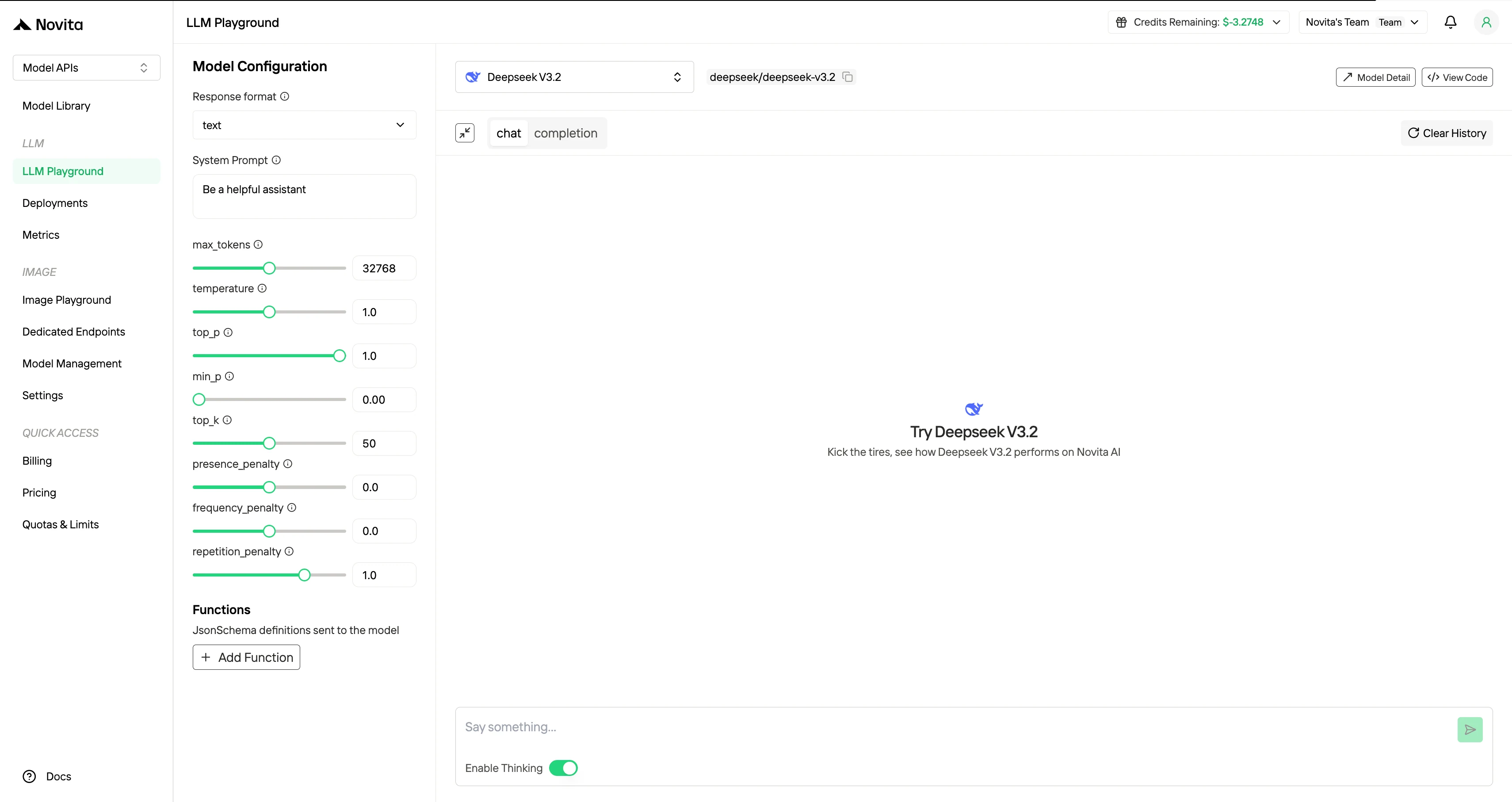
步驟 4:取得您的 API 金鑰
為了向 API 進行身份驗證,我們將為您提供一個新的 API 金鑰。進入「設定」頁面,您可以複製如圖所示的 API 金鑰。

步驟 5:安裝 API
使用適合您程式語言的套件管理器安裝 API。
安裝後,將必要的函式庫匯入您的開發環境。使用您的 API 金鑰初始化 API 以開始與 Novita AI LLM 互動。這是使用 Python 使用者使用聊天補全 API 的範例。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
與 Claude Code 一起使用 DeepSeek V3.2
步驟 1:安裝 Claude Code
在安裝 Claude Code 之前,請確保您的系統符合最低要求。您的本地環境必須安裝 Node.js 18 或更高版本。您可以在終端機中執行 node --version 來驗證您的 Node.js 版本。
Windows 使用者
開啟命令提示字元,執行以下命令:
npm install -g @anthropic-ai/claude-code
npx win-claude-code@latest
全域安裝確保 Claude Code 可從系統的任何目錄存取。npx win-claude-code@latest 命令會下載並執行最新的 Windows 特定版本。
Mac 和 Linux 使用者
開啟終端機,執行:
npm install -g @anthropic-ai/claude-code
Mac 使用者可以直接進行全域安裝,無需額外的平台特定命令。安裝過程會自動配置必要的依賴項和 PATH 變數。
步驟 2:設定環境變數
環境變數可設定 Claude Code 透過 Novita AI 的 API 端點使用 Deepseek v3.2。這些變數告訴 Claude Code 將請求發送到何處以及如何進行身份驗證。
Windows 使用者
開啟命令提示字元,設定以下環境變數:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Novita API Key>
set ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
set ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
將 <Novita API Key> 替換為您從 Novita AI 平台取得的實際 API 金鑰。這些變數在當前工作階段保持活動狀態,如果關閉命令提示字元則必須重新設定。
Mac 和 Linux 使用者
開啟終端機,匯出以下環境變數:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
export ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
export ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
步驟 3:啟動 Claude Code
安裝和配置完成後,您現在可以在專案目錄中啟動 Claude Code。使用 cd 命令導航到您的目標專案位置:
cd <your-project-directory>
claude .
點 (.) 參數指示 Claude Code 在目前目錄中操作。啟動後,您將在互動式工作階段中看到 Claude Code 提示。
這表示該工具已準備好接收您的指示。該介面為自然語言編程互動提供了一個乾淨、直觀的環境。
步驟 4:在 VSCode 或 Cursor 中使用 Claude Code
Claude Code 與流行的開發環境無縫整合。它增強了您現有的工作流程,而不是取代它。
您可以在 VSCode 或 Cursor 的終端機中直接使用 Claude Code。這可以在利用 AI 輔助的同時,保持對您熟悉的開發工具的存取。
此外,VSCode 和 Cursor 都有可用的 Claude Code 外掛程式。
如何在 Claude Code 中使用外部模型?
如果您想在開發工作流程中動態切換不同的大型語言模型(例如 Anthropic 的 Claude、智譜的 GLM 和月之暗面的 Kimi),有一些策略可以在不進行大量程式碼更改的情況下實現。本節說明如何使用統一的 API 和配置切換來快速交換模型。
使用環境變數(Claude Code 方法):
如果您正在使用 Claude Code 等工具或綁定到特定 API 的 SDK,您只需調整環境配置即可切換模型。Novita AI 提供了多種模型選項,您可以嘗試以找到最合適的模型。
DeepSeek V3.2 引入了 DSA 作為針對性的架構升級,大幅降低了運算成本,提升了長上下文效果,並提高了以程式碼為中心的準確性,同時保持了具有競爭力的推理效能。該模型支援對大型程式碼庫和複雜技術文件進行可擴展分析,與 DeepSeek V3.1-Terminus 和專有替代方案相比,在效率和能力之間展現出有利的平衡。這些進步使 DeepSeek V3.2 成為持續開發工作流程和長上下文 AI 應用程式的經濟高效解決方案。
常見問題
DeepSeek V3.2 中的 DeepSeek 稀疏注意力(DSA)的主要優勢是什麼?
DeepSeek V3.2 使用 DSA 選擇性地啟動注意力連接,降低二次方注意力成本,同時在長上下文中保持準確的程式碼理解。
DeepSeek V3.2 與 DeepSeek V3.1-Terminus 在實際編碼工作流程中有何不同?
與 DeepSeek V3.1-Terminus 相比,DeepSeek V3.2 提供了更低的營運成本、128K 上下文視窗和更快的推理穩定性,從而實現更高效的倉儲級別程式碼分析。
DeepSeek V3.2 是否改善了長上下文技術文件的處理?
是的。DeepSeek V3.2 支援同時分析複雜文件和跨文件關係,在多文件推理任務中表現優於 DeepSeek V3.1-Terminus。
Novita AI 是一個一站式雲端平台,支援您的 AI 抱負。整合 API、無伺服器、GPU 實例 — 您需要的經濟高效工具。消除基礎設施,免費開始,讓您的 AI 願景成為現實。
推薦閱讀
如何使用 Novita AI 在 Claude Code 中使用 Kimi K2.7 Code



