

Entwickler, die große Codebasen oder Multi-Dokument-Workflows verwalten, stehen vor ständigen Herausforderungen: hohe Rechenkosten, instabile Langzeit-Kontextleistung und inkonsistentes Codeverständnis bei der Verwendung herkömmlicher Transformer-Modelle. Diese Einschränkungen begrenzen die Iterationseffizienz, schränken die Analyse auf Repository-Ebene ein und erhöhen die Betriebskosten. Die Einführung von DeepSeek V3.2 adressiert diese Schwachstellen durch die Integration von DeepSeek Sparse Attention (DSA), einem Mechanismus, der den Attention-Overhead reduziert, das Kontextverständnis beschleunigt und die Codegenerierung stabilisiert.
Dieser Artikel untersucht, wie DeepSeek V3.2 die Kosteneffizienz, die Langzeit-Kontextverarbeitung und die codefokussierten Fähigkeiten verbessert. Er bietet Betriebsanleitungen für die Bereitstellung von DeepSeek V3.2 über Novita AI und Claude Code.
Achtung! Novita AI startet seine „Build Month“-Kampagne und bietet Entwicklern einen exklusiven Anreiz von bis zu 20 % Rabatt auf alle Hauptprodukte!
Jetzt am Build Month teilnehmen!
Welche neuen Codierungsfunktionen bietet DeepSeek V3.2?
DSA ist ein revolutionärer Attention-Mechanismus, der grundlegend ändert, wie das Modell Informationen verarbeitet. Während traditionelle Transformatoren von jedem Token verlangen, auf alle anderen Token zu achten – was zu quadratischen Rechenkosten (O(n²)) führt – führt DSA einen feinkörnigen, inhaltsbewussten Auswahlmechanismus ein:
- Intelligente Filterung: Während des Trainings lernt das Modell, welche Token-Beziehungen für bestimmte Aufgaben wirklich wichtig sind
- Dynamische Verbindungen: Echtzeit-Auswahl notwendiger Attention-Verbindungen basierend auf dem Eingabeinhalt.
- Aufgabenoptimierung: Fokussiert auf unterschiedliche Strukturmuster bei der Verarbeitung von Code im Vergleich zu juristischen Dokumenten
Drei Kernverbesserungen durch DSA
„Direct Self-Adaptation“ wird als Hilfsmechanismus eingesetzt, um die Gesamtleistung des Modells zu verbessern, ohne die Kernarchitektur zu verändern. Durch diesen Ansatz erzielt das Modell eine erhebliche Kosteneffizienz, indem es eine wirtschaftlichere Inferenz ermöglicht und gleichzeitig eine mit v3.1 vergleichbare Codegenerierungs- und Analysequalität beibehält, wodurch häufige Tests und schnelle Iterationen unterstützt werden.
DSA stärkt auch die Nutzung langer Kontexte, indem es effektiv ein Kontextfenster von bis zu 128K Tokens nutzt, was die gleichzeitige Analyse mehrerer Dateien, das Verständnis dateiübergreifender Abhängigkeiten und die Verarbeitung komplexer technischer Dokumentation verbessert.
Darüber hinaus trägt DSA zu verbesserten codebezogenen Fähigkeiten bei, darunter schnellere Inferenzreaktionen, genaueres Codeverständnis und stabilere Codegenerierungsqualität, was insgesamt die Zuverlässigkeit und Effizienz des Modells in groß angelegten Softwareentwicklungsszenarien erhöht.
Skalierbares Reinforcement Learning Framework
Durch die Einführung eines robusten Reinforcement-Learning-Protokolls und die Skalierung der Post-Training-Berechnung erreicht DeepSeek-V3.2 eine mit GPT-5 vergleichbare Leistung. Bemerkenswert ist, dass die rechenintensive Variante DeepSeek-V3.2-Speciale durchgängig besser abschneidet als GPT-5 und Reasoning-Fähigkeiten auf dem Niveau von Gemini-3.0-Pro demonstriert.
| Benchmark | Metrik | DeepSeek-V3.2-Speciale | DeepSeek-V3.2-Thinking | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 96.0 | 93.1 | 94.6 | 87.0 | 95.0 |
| HMMT 2025 | Pass@1 (%) | 99.2 | 90.2 | 88.3 | 79.2 | 97.5 |
| HLE | Pass@1 (%) | 30.6 | 25.1 | 26.3 | 13.7 | 37.7 |
| Codeforces | Rating | 2701 | 2386 | 2537 | 1480 | 2708 |
| SWE Verified | Resolved (%) | – | 73.1 | 74.9 | 77.2 | 76.2 |
| Terminal Bench 2.0 | Accuracy (%) | – | 46.4 | 35.2 | 42.8 | 54.2 |
| τ² Bench | Pass@1 (%) | – | 80.3 | 80.2 | 84.7 | 85.4 |
| Tool Decathlon | Pass@1 (%) | – | 35.2 | 29.0 | 38.6 | 36.4 |
20 % Rabatt auf Deepseek V3.2 sichern!
DeepSeek V3.2: Was wurde getan, um besser mit Entwicklern zusammenzuarbeiten?
Um das Reasoning besser in Tool-Use-Szenarien zu integrieren, hat DeepSeek in der Post-Training-Phase von V3.2 eine Large-Scale Agentic Task Synthesis Pipeline eingeführt. Die Kernidee besteht darin, systematisch agentische Trainingsdaten in großem Maßstab zu generieren, anstatt sich auf handgefertigte Prompts oder begrenzte menschliche Demonstrationen zu verlassen.
Diese Pipeline erstellt programmatisch Aufgaben, die das Modell dazu zwingen, zu überlegen, zu entscheiden, Tools aufzurufen, Zwischenergebnisse zu beobachten und sein Verhalten entsprechend anzupassen. Indem das Modell einer Vielzahl von strukturierten Interaktionen ausgesetzt wird, ermöglicht DeepSeek skalierbares agentisches Post-Training und verbessert sowohl die Verhaltenskonformität als auch die Generalisierung in komplexen, mehrstufigen interaktiven Umgebungen wie Suche, Codierung und Tool-gestützten Workflows erheblich.
Die beiden wichtigsten Aktualisierungen sind:
Ein überarbeitetes Tool-Calling-Format, das in mehrstufigen Interaktionen expliziter und stabiler sein soll
Native Unterstützung für „Thinking with Tools“, bei der Reasoning und Tool-Nutzung strukturell integriert und nicht nur lose verschränkt sind
Um der Community das Verständnis und die Übernahme dieser neuen Vorlage zu erleichtern, stellt DeepSeek einen speziellen encoding-Ordner zur Verfügung. Dieser Ordner enthält Python-Skripte und Testfälle, die demonstrieren: wie OpenAI-kompatible Nachrichten in eine einzige Eingabezeichenfolge kodiert werden, die von DeepSeek-V3.2 erwartet wird, und wie die Textausgabe des Modells zurück in strukturierte Nachrichten geparst wird.
import transformers
# encoding/encoding_dsv32.py
from encoding_dsv32 import encode_messages, parse_message_from_completion_text
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2")
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
encode_config = dict(thinking_mode="thinking", drop_thinking=True, add_default_bos_token=True)
prompt = encode_messages(messages, **encode_config)
tokens = tokenizer.encode(prompt)
Es ist erwähnenswert, dass diese Version keine Jinja-basierte Chat-Vorlage enthält. Die bereitgestellte Python-Implementierung ist die maßgebliche Referenz. Darüber hinaus geht die Ausgabeparse-Funktion von wohlgeformten Modellausgaben aus und ist für Demonstrations- und Experimentierzwecke gedacht, nicht für den direkten Produktionseinsatz ohne zusätzliche Fehlerbehandlung.
20 % Rabatt auf Deepseek V3.2 sichern!
Warum wird die Entwickler-Rolle benötigt?
In realen Agent-Szenarien muss ein Modell oft drei verschiedene Arten von Informationen gleichzeitig verarbeiten:
- Die tatsächliche Absicht oder das Aufgabenziel des Benutzers
- Den eigenen Reasoning- und Entscheidungsprozess des Modells
- Suchstrategien, Tool-Einschränkungen und Ausführungsregeln, die vom System oder Entwickler bereitgestellt werden
In früheren Versionen wurden diese Signale typischerweise in Benutzer- oder System-Prompts gemischt. Im Laufe der Zeit führte dies zu zwei großen Problemen. Erstens konnte das Modell Schwierigkeiten haben, die Benutzerabsicht von verbindlichen Verhaltensbeschränkungen zu unterscheiden. Zweitens verschlechterte sich mit zunehmender Komplexität der Toolchains die Stabilität und Zuverlässigkeit des Tool-Aufrufs merklich.
Die in DeepSeek-V3.2 eingeführte developer-Rolle dient im Wesentlichen als dedizierter Kontrollkanal für Suchagenten und Tool-orientierte Agenten. Sie ist dazu gedacht, Anweisungen zu transportieren, die streng mit dem Agentenverhalten zusammenhängen, wie z. B. Suchbereich, Tool-Nutzungsreihenfolge oder Richtlinienbeschränkungen, ohne an der gewöhnlichen Gesprächssemantik teilzunehmen. Diese explizite Trennung ermöglicht ein klareres Kontextverständnis und schafft eine strukturelle Grundlage für skalierbareres und robusteres agentisches Training.
Wie greife ich auf DeepSeek V3.2 in Claude Code zu?
Novita AI bietet derzeit die günstigste Deepseek V3.2 API mit vollem Kontext an.
Novita AI stellt APIs mit 65K Kontext bereit, die 0,269 $/Eingabe und 0,4 $/Ausgabe kosten, und unterstützt strukturierte Ausgabe und Funktionsaufrufe, was eine starke Unterstützung bietet, um das Code-Agent-Potenzial von Deepseek V3.2 zu maximieren.
Cache Read: 0,1345 $ / M Token gibt die Kosten für das Lesen von gecachten Tokens an, wenn ein Cache-Treffer auftritt. Diese Tokens wurden zuvor berechnet und gespeichert, sodass keine zusätzliche Modellinferenz erforderlich ist. In Systemen, in denen viele Anfragen dasselbe Prompt-Präfix teilen, Gesprächsverläufe, Tool-Anweisungen oder feste Regeltexte wiederverwendet werden oder RAG-Abrufergebnisse stark repetitiv sind, kann eine hohe Cache-Trefferquote erzielt werden, was die Gesamtinferenzkosten erheblich reduziert.
Der erste Schritt: API-Key holen
Schritt 1: Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell aus
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.
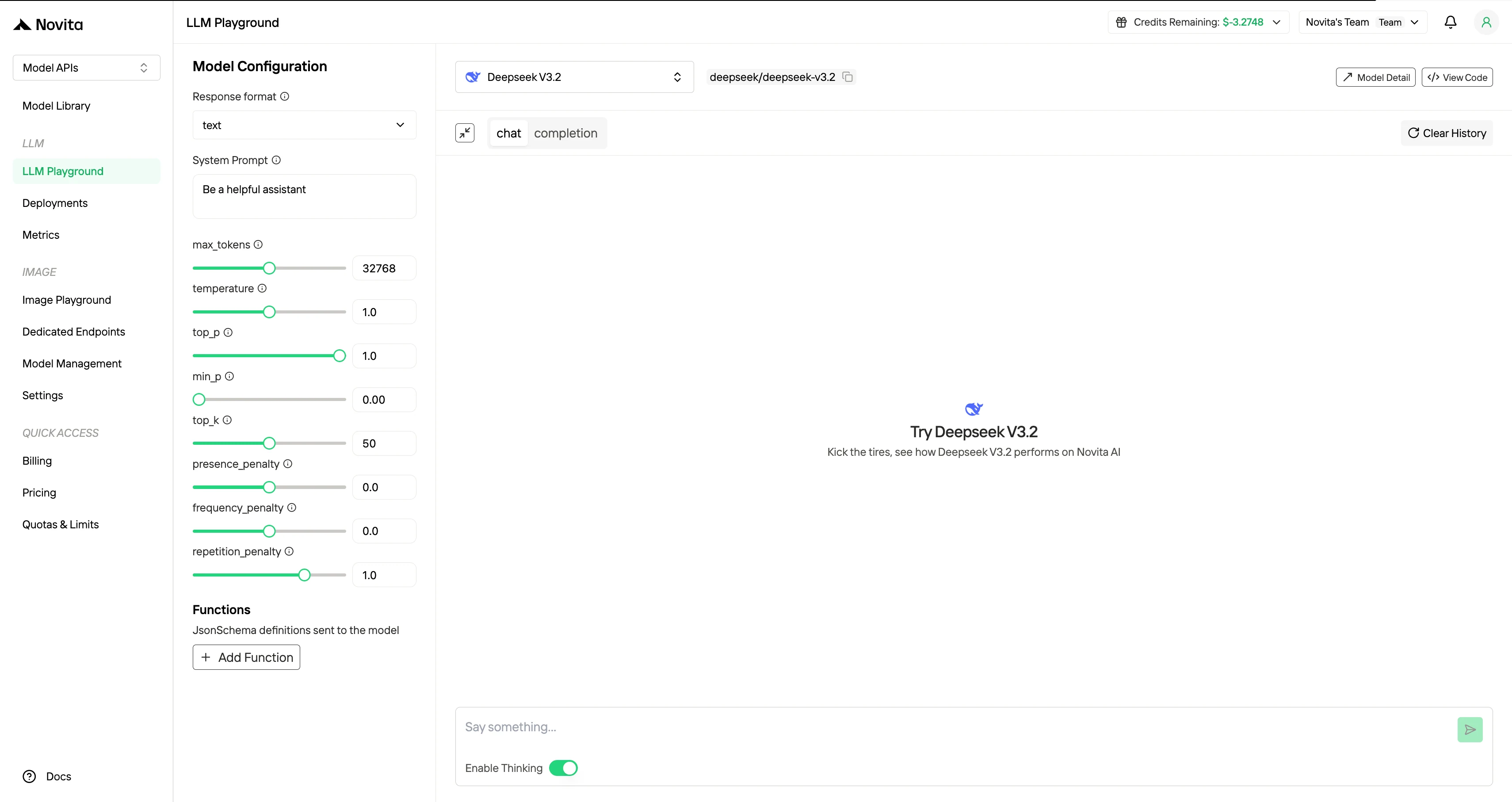
Schritt 4: Holen Sie Ihren API-Key
Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Key zur Verfügung. Rufen Sie die Seite „Einstellungen“ auf, um den API-Key wie im Bild gezeigt zu kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die notwendigen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Key, um mit Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
DeepSeek V3.2 mit Claude Code verwenden
Schritt 1: Claude Code installieren
Stellen Sie vor der Installation von Claude Code sicher, dass Ihr System die Mindestanforderungen erfüllt. Node.js 18 oder höher muss in Ihrer lokalen Umgebung installiert sein. Sie können Ihre Node.js-Version überprüfen, indem Sie node --version in Ihrem Terminal ausführen.
Für Windows
Öffnen Sie die Eingabeaufforderung und führen Sie die folgenden Befehle aus:
npm install -g @anthropic-ai/claude-code
npx win-claude-code@latest
Die globale Installation stellt sicher, dass Claude Code von jedem Verzeichnis auf Ihrem System aus zugänglich ist. Der Befehl npx win-claude-code@latest lädt die neueste Windows-spezifische Version herunter und führt sie aus.
Für Mac und Linux
Öffnen Sie das Terminal und führen Sie Folgendes aus:
npm install -g @anthropic-ai/claude-code
Mac-Benutzer können direkt mit der globalen Installation fortfahren, ohne zusätzliche plattformspezifische Befehle. Der Installationsprozess konfiguriert automatisch die notwendigen Abhängigkeiten und PATH-Variablen.
Schritt 2: Umgebungsvariablen einrichten
Umgebungsvariablen konfigurieren Claude Code so, dass es Deepseek v3.2 über die API-Endpunkte von Novita AI verwendet. Diese Variablen teilen Claude Code mit, wohin Anfragen gesendet werden und wie die Authentifizierung erfolgt.
Für Windows
Öffnen Sie die Eingabeaufforderung und setzen Sie die folgenden Umgebungsvariablen:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Novita API Key>
set ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
set ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Ersetzen Sie <Novita API Key> durch Ihren tatsächlichen API-Key von der Novita AI Plattform. Diese Variablen bleiben für die aktuelle Sitzung aktiv und müssen zurückgesetzt werden, wenn Sie die Eingabeaufforderung schließen.
Für Mac und Linux
Öffnen Sie das Terminal und exportieren Sie die folgenden Umgebungsvariablen:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
export ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
export ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Schritt 3: Claude Code starten
Nach Abschluss der Installation und Konfiguration können Sie Claude Code in Ihrem Projektverzeichnis starten. Navigieren Sie mit dem Befehl cd zu Ihrem gewünschten Projektspeicherort:
cd <Ihr-Projektverzeichnis>
claude .
Der Punkt (.) weist Claude Code an, im aktuellen Verzeichnis zu arbeiten. Nach dem Starten sehen Sie in einer interaktiven Sitzung die Eingabeaufforderung von Claude Code.
Dies zeigt an, dass das Tool bereit ist, Ihre Anweisungen entgegenzunehmen. Die Oberfläche bietet eine klare, intuitive Umgebung für natürliche Sprachprogrammierungsinteraktionen.
Schritt 4: Claude Code in VSCode oder Cursor verwenden
Claude Code integriert sich nahtlos in gängige Entwicklungsumgebungen. Es verbessert Ihren bestehenden Workflow, anstatt ihn zu ersetzen.
Sie können Claude Code direkt im Terminal in VSCode oder Cursor verwenden. Dies gibt Ihnen Zugriff auf Ihre vertrauten Entwicklungswerkzeuge bei gleichzeitiger Nutzung der KI-Unterstützung.
Darüber hinaus sind Claude Code-Plugins sowohl für VSCode als auch für Cursor verfügbar.
Wie man externe Modelle in Claude Code verwendet
Wenn Sie in Ihrem Entwicklungsworkflow dynamisch zwischen verschiedenen großen Sprachmodellen (z. B. Anthropics Claude, Zhipus GLM und Moonshots Kimi) wechseln möchten, gibt es Strategien, dies ohne umfangreiche Codeänderungen zu tun. Dieser Abschnitt erklärt, wie Sie Modelle mithilfe einheitlicher APIs und Konfigurationsumschaltungen schnell austauschen können.
Verwendung von Umgebungsvariablen (Claude Code-Ansatz):
Wenn Sie mit Tools wie Claude Code oder einem an eine bestimmte API gebundenen SDK arbeiten, können Sie Modelle einfach durch Anpassen Ihrer Umgebungskonfiguration wechseln. Novita AI bietet mehrere Modelloptionen, mit denen Sie experimentieren können, um die beste Lösung zu finden.
DeepSeek V3.2 führt DSA als gezieltes Architektur-Upgrade ein, das die Rechenkosten erheblich senkt, die Effektivität langer Kontexte erhöht und die codezentrierte Genauigkeit verbessert, während es gleichzeitig wettbewerbsfähige Reasoning-Leistungen beibehält. Das Modell ermöglicht skalierbare Analysen großer Repositories und komplexer technischer Dokumente und demonstriert eine günstige Balance zwischen Effizienz und Leistungsfähigkeit im Vergleich zu DeepSeek V3.1-Terminus und proprietären Alternativen. Diese Fortschritte etablieren DeepSeek V3.2 als kosteneffektive Lösung für nachhaltige Entwicklungsworkflows und KI-Anwendungen mit langem Kontext.
Häufig gestellte Fragen
Was ist der Hauptvorteil von DeepSeek Sparse Attention (DSA) in DeepSeek V3.2?
DeepSeek V3.2 verwendet DSA, um Attention-Verbindungen selektiv zu aktivieren, wodurch die quadratischen Attention-Kosten reduziert werden, während ein genaues Codeverständnis über lange Kontexte hinweg erhalten bleibt.
Wie unterscheidet sich DeepSeek V3.2 von DeepSeek V3.1-Terminus in praktischen Codierungs-Workflows?
DeepSeek V3.2 bietet niedrigere Betriebskosten, ein 128K-Kontextfenster und eine schnellere Inferenzstabilität im Vergleich zu DeepSeek V3.1-Terminus, was zu effizienteren Code-Analysen auf Repository-Ebene führt.
Verbessert DeepSeek V3.2 die Verarbeitung technischer Dokumente mit langem Kontext?
Ja. DeepSeek V3.2 unterstützt die gleichzeitige Analyse komplexer Dokumente und dateiübergreifender Beziehungen und übertrifft DeepSeek V3.1-Terminus in Reasoning-Aufgaben mit mehreren Dokumenten.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, Serverless, GPU-Instanzen – die kostengünstigen Tools, die Sie brauchen. Ohne Infrastruktur, kostenlos starten und Ihre KI-Vision verwirklichen.
Empfohlene Lektüre
So verwenden Sie Kimi K2.7 Code in Claude Code über Novita AI
So greifen Sie auf Qwen 3 Coder zu: Qwen Code; Claude Code; Trae
DeepSeek vs Qwen: Identifizieren, welches Ökosystem für die Produktion geeignet ist



