

Desenvolvedores que gerenciam grandes bases de código ou fluxos de trabalho com vários documentos enfrentam desafios persistentes que incluem alto custo computacional, desempenho instável em contexto longo e compreensão inconsistente de código ao usar modelos Transformer convencionais. Essas limitações restringem a eficiência da iteração, limitam a análise em escala de repositório e aumentam as despesas operacionais. A introdução do DeepSeek V3.2 resolve esses pontos problemáticos ao integrar o DeepSeek Sparse Attention (DSA), um mecanismo projetado para reduzir a sobrecarga de atenção, acelerar o raciocínio contextual e estabilizar a geração de código.
Este artigo examina como o DeepSeek V3.2 melhora a eficiência de custos, o processamento de contexto longo e as capacidades focadas em código. Ele apresenta orientações operacionais para implantar o DeepSeek V3.2 através da Novita AI e do Claude Code.
Sua Atenção, Por Favor! A Novita AI está lançando sua campanha “Build Month”, oferecendo aos desenvolvedores um incentivo exclusivo de até 20% de desconto em todos os principais produtos!
Quais são os Novos Recursos de Codificação no DeepSeek V3.2?
O DSA é um mecanismo de atenção revolucionário que muda fundamentalmente a forma como o modelo processa informações. Enquanto os Transformers tradicionais exigem que cada token atenda a todos os outros tokens — resultando em custo computacional quadrático (O(n²)) — o DSA introduz um mecanismo de seleção refinado e consciente do conteúdo:
- Filtragem Inteligente: Durante o treinamento, o modelo aprende a identificar quais relações entre tokens são realmente importantes para tarefas específicas
- Conexões Dinâmicas: Seleção em tempo real das conexões de atenção necessárias com base no conteúdo de entrada.
- Otimização de Tarefas: Foca em diferentes padrões estruturais ao processar código versus documentos jurídicos
Três Melhorias Principais Proporcionadas pelo DSA
A Auto-Adaptação Direta é empregada como um mecanismo auxiliar para melhorar o desempenho geral do modelo sem alterar a arquitetura central. Através dessa abordagem, o modelo alcança eficiência de custos significativa ao permitir inferência mais econômica, preservando a qualidade de geração e análise de código comparável ao v3.1, suportando assim testes frequentes e iteração rápida.
O DSA também fortalece a utilização de contexto longo ao aproveitar efetivamente uma janela de contexto de até 128K tokens, o que melhora a análise simultânea de múltiplos arquivos, a compreensão de dependências entre arquivos e o processamento de documentação técnica complexa.
Além disso, o DSA contribui para capacidades aprimoradas relacionadas a código, incluindo resposta de inferência mais rápida, compreensão de código mais precisa e qualidade de geração de código mais estável, aumentando coletivamente a confiabilidade e eficiência do modelo em cenários de desenvolvimento de software em larga escala.
Estrutura de Aprendizado por Reforço Escalável
Ao adotar um protocolo robusto de aprendizado por reforço e escalar a computação pós-treinamento, o DeepSeek-V3.2 alcança desempenho comparável ao GPT-5. Notavelmente, a variante de alta computação, DeepSeek-V3.2-Speciale, supera consistentemente o GPT-5 e demonstra capacidades de raciocínio no mesmo nível do Gemini-3.0-Pro.
| Benchmark | Métrica | DeepSeek-V3.2-Speciale | DeepSeek-V3.2-Thinking | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 96.0 | 93.1 | 94.6 | 87.0 | 95.0 |
| HMMT 2025 | Pass@1 (%) | 99.2 | 90.2 | 88.3 | 79.2 | 97.5 |
| HLE | Pass@1 (%) | 30.6 | 25.1 | 26.3 | 13.7 | 37.7 |
| Codeforces | Rating | 2701 | 2386 | 2537 | 1480 | 2708 |
| SWE Verified | Resolved (%) | – | 73.1 | 74.9 | 77.2 | 76.2 |
| Terminal Bench 2.0 | Accuracy (%) | – | 46.4 | 35.2 | 42.8 | 54.2 |
| τ² Bench | Pass@1 (%) | – | 80.3 | 80.2 | 84.7 | 85.4 |
| Tool Decathlon | Pass@1 (%) | – | 35.2 | 29.0 | 38.6 | 36.4 |
Experimente 20% de desconto no Deepseek V3.2!
DeepSeek V3.2: O que foi Feito para Colaborar Melhor com os Desenvolvedores?
Para melhor integrar o raciocínio em cenários de uso de ferramentas, o DeepSeek introduziu um Pipeline de Síntese de Tarefas Agênticas em Grande Escala durante o estágio de pós-treinamento do V3.2. A ideia central é gerar sistematicamente dados de treinamento agênticos em escala, em vez de depender de prompts artesanais ou demonstrações humanas limitadas.
Este pipeline constrói programaticamente tarefas que exigem que o modelo raciocine, decida, chame ferramentas, observe resultados intermediários e ajuste seu comportamento de acordo. Ao expor o modelo a uma ampla variedade de interações estruturadas, o DeepSeek possibilita o pós-treinamento agêntico escalável, melhorando significativamente tanto a conformidade comportamental quanto a generalização em ambientes interativos complexos e de múltiplas etapas, como busca, codificação e fluxos de trabalho aumentados por ferramentas.
As duas atualizações mais importantes são:
Um formato revisado de chamada de ferramenta, projetado para ser mais explícito e mais estável em interações de múltiplas etapas
Suporte nativo para “pensar com ferramentas”, onde raciocínio e uso de ferramentas são estruturalmente integrados em vez de intercalados de forma flexível
Para ajudar a comunidade a entender e adotar este novo modelo, o DeepSeek fornece uma pasta dedicada encoding. Esta pasta inclui scripts Python e casos de teste que demonstram: como codificar mensagens compatíveis com OpenAI em uma única string de entrada esperada pelo DeepSeek-V3.2 e como analisar a saída de texto do modelo de volta para mensagens estruturadas.
import transformers
# encoding/encoding_dsv32.py
from encoding_dsv32 import encode_messages, parse_message_from_completion_text
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2")
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
encode_config = dict(thinking_mode="thinking", drop_thinking=True, add_default_bos_token=True)
prompt = encode_messages(messages, **encode_config)
tokens = tokenizer.encode(prompt)
Vale notar que este lançamento não inclui um modelo de chat baseado em Jinja. A implementação Python fornecida é a referência oficial. Além disso, a função de análise de saída pressupõe saídas do modelo bem formadas e é destinada para demonstração e experimentação, não para uso direto em produção sem tratamento adicional de erros.
Experimente 20% de desconto no Deepseek V3.2!
Por que o Papel de Desenvolvedor é Necessário
Em cenários agênticos reais, um modelo muitas vezes precisa lidar com três tipos distintos de informações simultaneamente:
- A intenção real do usuário ou objetivo da tarefa
- O próprio processo de raciocínio e tomada de decisão do modelo
- Estratégias de busca, restrições de ferramentas e regras de execução fornecidas pelo sistema ou desenvolvedor
Em versões anteriores, esses sinais eram tipicamente misturados em prompts de usuário ou sistema. Com o tempo, isso levou a dois grandes problemas. Primeiro, o modelo podia ter dificuldade em distinguir a intenção do usuário das restrições comportamentais obrigatórias. Segundo, à medida que as cadeias de ferramentas se tornavam mais complexas, a estabilidade e confiabilidade da invocação de ferramentas degradavam-se visivelmente.
O papel de desenvolvedor introduzido no DeepSeek-V3.2 serve essencialmente como um canal de controle dedicado para agentes de busca e agentes orientados a ferramentas. Ele é projetado para transportar instruções estritamente relacionadas ao comportamento do agente, como escopo de busca, ordem de uso de ferramentas ou restrições de política, sem participar da semântica conversacional comum. Esta separação explícita permite uma compreensão contextual mais clara e estabelece uma base estrutural para um treinamento agêntico mais escalável e robusto.
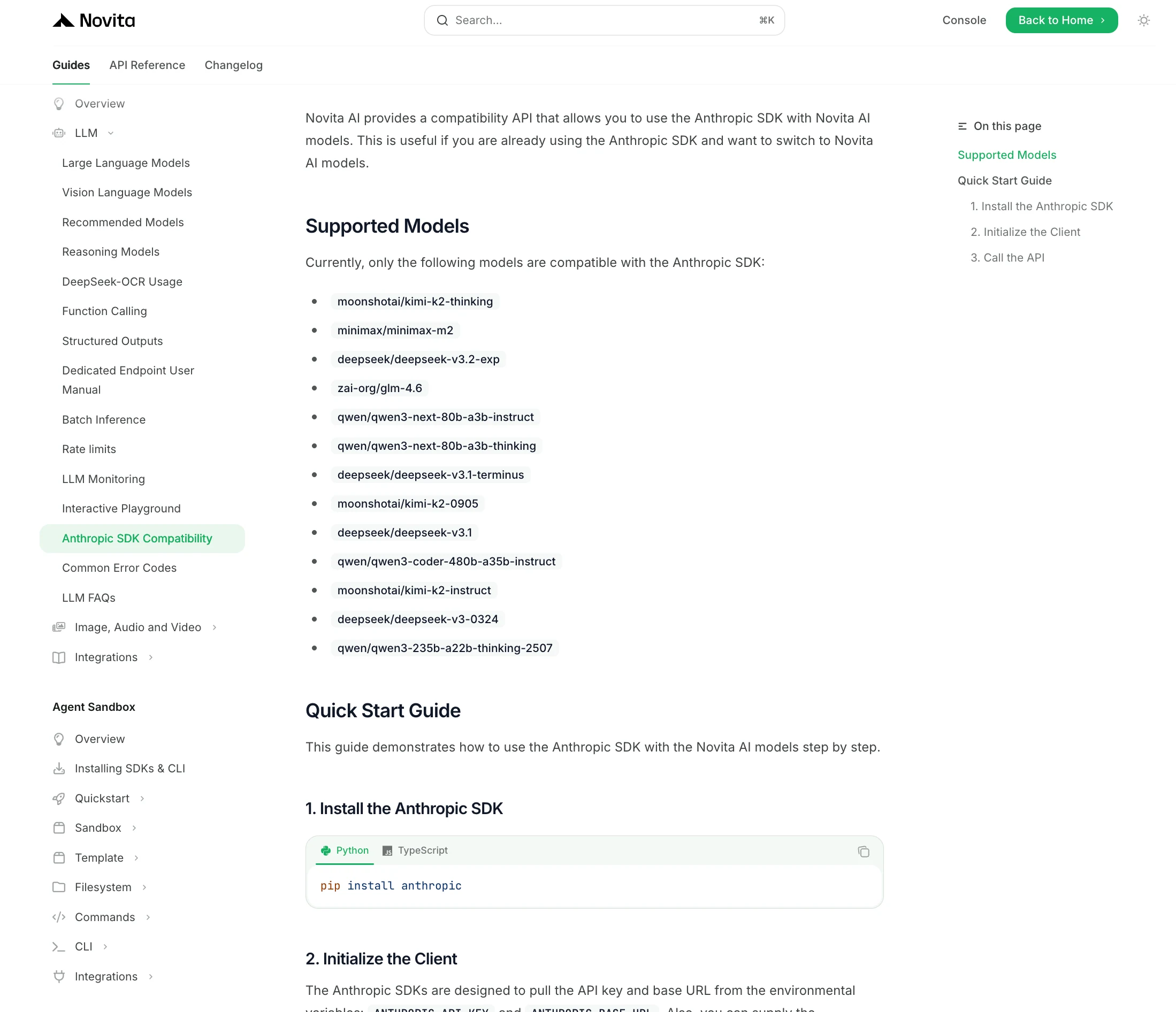
Como Acessar o DeepSeek V3.2 no Claude Code?
A Novita AI oferece atualmente a API Deepseek V3.2 de contexto completo mais acessível.
A Novita AI fornece APIs com 65K de contexto, e custos de $0,269/input e $0,4/output, suportando saída estruturada e chamada de função, o que oferece forte suporte para maximizar o potencial do agente de código do Deepseek V3.2.
Cache Read: $0,1345 / M Token” indica o custo para ler tokens em cache quando ocorre um cache hit. Esses tokens foram previamente computados e armazenados, portanto nenhuma inferência adicional do modelo é necessária. Em sistemas onde muitas requisições compartilham o mesmo prefixo de prompt, reutilizam histórico de conversas, instruções de ferramentas ou textos de regras fixas, ou onde os resultados de recuperação RAG são altamente repetitivos, uma alta taxa de cache hit pode ser alcançada, reduzindo significativamente o custo geral de inferência.
Primeiro: Obter a Chave da API
Passo 1: Faça login na sua conta e clique no botão Model Library.

Passo 2: Escolha Seu Modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito
Comece seu teste gratuito para explorar as capacidades do modelo selecionado.
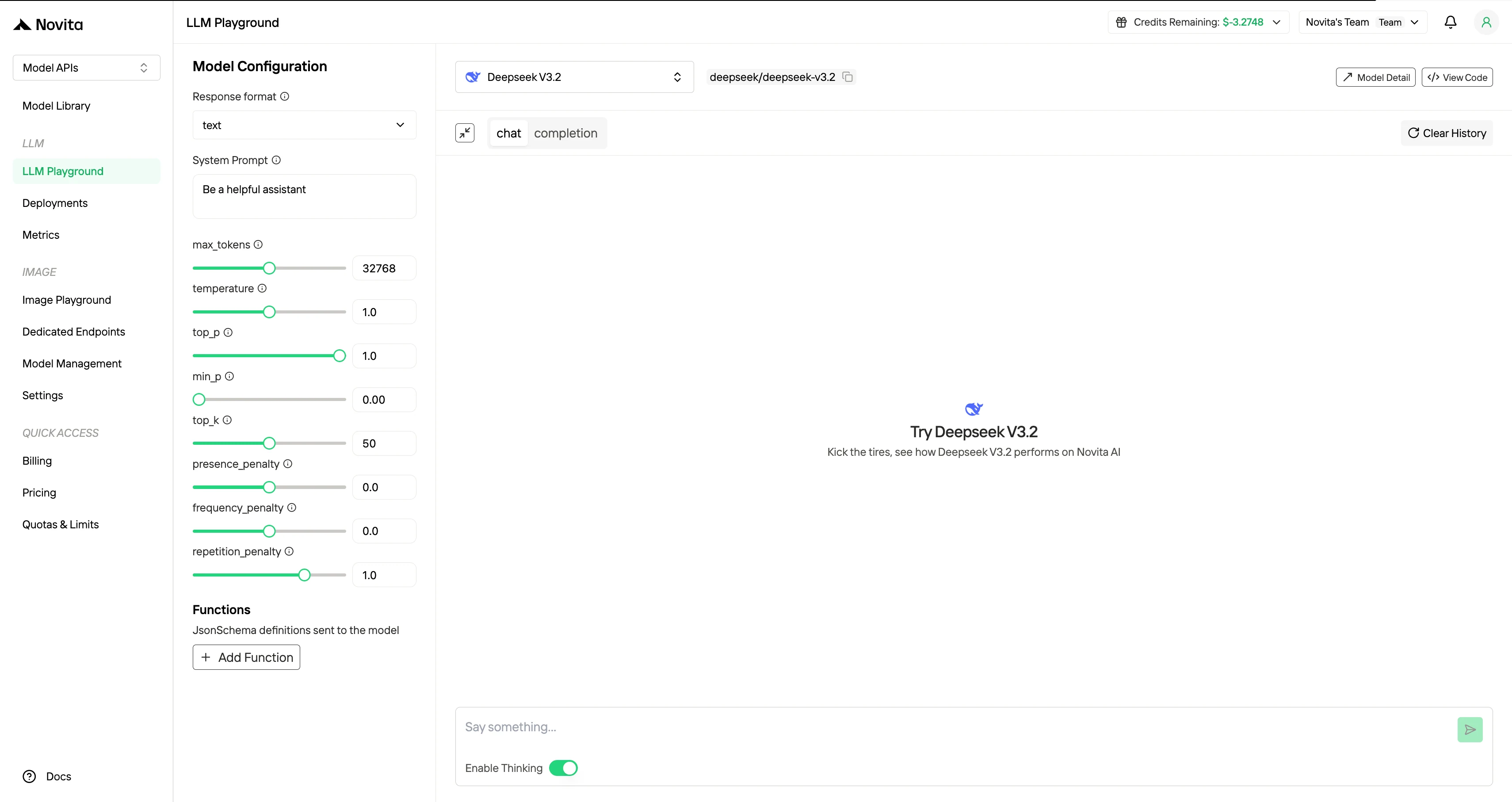
Passo 4: Obtenha Sua Chave de API
Para autenticar com a API, forneceremos a você uma nova chave de API. Entrando na página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários Python.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Use o DeepSeek V3.2 com o Claude Code
Passo 1: Instalando o Claude Code
Antes de instalar o Claude Code, certifique-se de que seu sistema atende aos requisitos mínimos. O Node.js 18 ou superior deve estar instalado em seu ambiente local. Você pode verificar sua versão do Node.js executando node --version no terminal.
Para Windows
Abra o Command Prompt e execute os seguintes comandos:
npm install -g @anthropic-ai/claude-code
npx win-claude-code@latest
A instalação global garante que o Claude Code esteja acessível a partir de qualquer diretório do seu sistema. O comando npx win-claude-code@latest baixa e executa a versão mais recente específica para Windows.
Para Mac e Linux
Abra o Terminal e execute:
npm install -g @anthropic-ai/claude-code
Usuários de Mac podem prosseguir diretamente com a instalação global sem exigir comandos adicionais específicos da plataforma. O processo de instalação configura automaticamente as dependências e variáveis PATH necessárias.
Passo 2: Configurando Variáveis de Ambiente
As variáveis de ambiente configuram o Claude Code para usar o Deepseek v3.2 através dos endpoints da API da Novita AI. Essas variáveis informam ao Claude Code para onde enviar as requisições e como autenticar.
Para Windows
Abra o Command Prompt e defina as seguintes variáveis de ambiente:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Novita API Key>
set ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
set ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Substitua <Novita API Key> pela sua chave de API real obtida na plataforma Novita AI. Essas variáveis permanecem ativas durante a sessão atual e devem ser redefinidas se você fechar o Command Prompt.
Para Mac e Linux
Abra o Terminal e exporte as seguintes variáveis de ambiente:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Novita API Key>"
export ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
export ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Passo 3: Iniciando o Claude Code
Com a instalação e configuração concluídas, você pode agora iniciar o Claude Code no diretório do seu projeto. Navegue até o local desejado do projeto usando o comando cd:
cd <seu-diretório-do-projeto>
claude .
O parâmetro ponto (.) instrui o Claude Code a operar no diretório atual. Após a inicialização, você verá o prompt do Claude Code aparecer em uma sessão interativa.
Isso indica que a ferramenta está pronta para receber suas instruções. A interface fornece um ambiente limpo e intuitivo para interações de programação em linguagem natural.
Passo 4: Usando o Claude Code no VSCode ou Cursor
O Claude Code integra-se perfeitamente com ambientes de desenvolvimento populares. Ele melhora seu fluxo de trabalho existente em vez de substituí-lo.
Você pode usar o Claude Code diretamente no terminal dentro do VSCode ou Cursor. Isso mantém o acesso às suas ferramentas de desenvolvimento habituais enquanto aproveita a assistência de IA.
Além disso, plugins do Claude Code estão disponíveis tanto para o VSCode quanto para o Cursor.
Como Usar Modelos Externos no Claude Code?
Se você deseja alternar dinamicamente entre diferentes modelos de linguagem de grande porte (por exemplo, o Claude da Anthropic, o GLM da Zhipu e o Kimi da Moonshot) em seu fluxo de trabalho de desenvolvimento, existem estratégias para fazer isso sem grandes alterações de código. Esta seção explica como trocar rapidamente de modelo usando APIs unificadas e alternâncias de configuração.
Usando Variáveis de Ambiente (abordagem do Claude Code):
Se você está trabalhando com ferramentas como o Claude Code ou um SDK vinculado a uma API específica, você pode alternar modelos simplesmente ajustando sua configuração de ambiente. A Novita AI oferece múltiplas opções de modelo que você pode experimentar para encontrar a mais adequada.
O DeepSeek V3.2 introduz o DSA como uma atualização arquitetural direcionada que reduz substancialmente o custo computacional, aumenta a eficácia em contexto longo e melhora a precisão centrada em código, mantendo desempenho de raciocínio competitivo. O modelo permite análise escalável de grandes repositórios e documentos técnicos complexos, demonstrando um equilíbrio favorável entre eficiência e capacidade em comparação com o DeepSeek V3.1-Terminus e alternativas proprietárias. Esses avanços estabelecem o DeepSeek V3.2 como uma solução econômica para fluxos de trabalho de desenvolvimento sustentados e aplicações de IA com contexto longo.
Perguntas Frequentes
Qual é a principal vantagem do DeepSeek Sparse Attention (DSA) dentro do DeepSeek V3.2?
O DeepSeek V3.2 usa o DSA para ativar seletivamente conexões de atenção, reduzindo o custo de atenção quadrático enquanto preserva a compreensão precisa de código em contextos longos.
Como o DeepSeek V3.2 difere do DeepSeek V3.1-Terminus em fluxos de trabalho práticos de codificação?
O DeepSeek V3.2 oferece menor custo operacional, uma janela de contexto de 128K e estabilidade de inferência mais rápida em comparação com o DeepSeek V3.1-Terminus, resultando em análise de código em escala de repositório mais eficiente.
O DeepSeek V3.2 melhora o processamento de documentos técnicos de contexto longo?
Sim. O DeepSeek V3.2 suporta análise simultânea de documentos complexos e relações entre arquivos, superando o DeepSeek V3.1-Terminus em tarefas de raciocínio com múltiplos documentos.
Novita AI é a plataforma de nuvem all-in-one que impulsiona suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Elimine a infraestrutura, comece gratuitamente e torne sua visão de IA realidade.
Leitura Recomendada
Como Usar o Kimi K2.7 Code no Claude Code via Novita AI
Como Acessar o Qwen 3 Coder: Qwen Code; Claude Code; Trae
DeepSeek vs Qwen: Identifique Qual Ecossistema Atende às Necessidades de Produção



