

Les développeurs travaillant sur de grandes bases de code ou des flux multi-documents rencontrent des défis persistants : coût de calcul élevé, performance instable sur des contextes longs, et compréhension incohérente du code avec les modèles Transformer classiques. Ces contraintes limitent l’efficacité des itérations, restreignent l’analyse à l’échelle d’un dépôt et augmentent les dépenses opérationnelles. L’introduction de DeepSeek V3.2 répond à ces difficultés en intégrant DeepSeek Sparse Attention (DSA), un mécanisme conçu pour réduire la surcharge d’attention, accélérer le raisonnement contextuel et stabiliser la génération de code.
Cet article examine comment DeepSeek V3.2 améliore le rapport coût-efficacité, le traitement des longs contextes et les capacités axées sur le code. Il présente un guide opérationnel pour déployer DeepSeek V3.2 via Novita AI et Claude Code.
Votre attention, s’il vous plaît ! Novita AI lance sa campagne « Build Month », offrant aux développeurs une réduction exclusive pouvant aller jusqu’à 20 % sur tous les produits principaux !
Quelles sont les nouvelles fonctionnalités de codage dans DeepSeek V3.2 ?
DSA est un mécanisme d’attention révolutionnaire qui modifie fondamentalement la façon dont le modèle traite l’information. Alors que les Transformers traditionnels exigent que chaque jeton prête attention à tous les autres – ce qui entraîne un coût de calcul quadratique (O(n²)) – DSA introduit un mécanisme de sélection granulaire et sensible au contenu :
- Filtrage intelligent : Pendant l’entraînement, le modèle apprend à identifier quelles relations entre jetons sont réellement importantes pour des tâches spécifiques.
- Connexions dynamiques : Sélection en temps réel des connexions d’attention nécessaires en fonction du contenu d’entrée.
- Optimisation par tâche : Se concentre sur différents motifs structurels lors du traitement de code par rapport à des documents juridiques.
Trois améliorations clés apportées par DSA
L’auto-adaptation directe est utilisée comme mécanisme auxiliaire pour améliorer les performances globales du modèle sans modifier l’architecture principale. Grâce à cette approche, le modèle atteint une efficacité de coût significative en permettant une inférence plus économique tout en préservant une qualité de génération et d’analyse de code comparable à v3.1, soutenant ainsi les tests fréquents et l’itération rapide.
DSA renforce également l’utilisation des longs contextes en exploitant efficacement une fenêtre de contexte allant jusqu’à 128K tokens, ce qui améliore l’analyse simultanée de plusieurs fichiers, la compréhension des dépendances inter-fichiers et le traitement de documents techniques complexes.
De plus, DSA contribue à l’amélioration des capacités liées au code, notamment une réponse d’inférence plus rapide, une compréhension du code plus précise et une qualité de génération de code plus stable, ce qui améliore collectivement la fiabilité et l’efficacité du modèle dans les scénarios de développement logiciel à grande échelle.
Cadre d’apprentissage par renforcement évolutif
En adoptant un protocole d’apprentissage par renforcement robuste et en augmentant le calcul post-entraînement, DeepSeek-V3.2 atteint des performances comparables à GPT-5. Notamment, la variante à haut calcul, DeepSeek-V3.2-Speciale, surpasse régulièrement GPT-5 et démontre des capacités de raisonnement à la hauteur de Gemini-3.0-Pro.
| Benchmark | Métrique | DeepSeek-V3.2-Speciale | DeepSeek-V3.2-Thinking | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 96.0 | 93.1 | 94.6 | 87.0 | 95.0 |
| HMMT 2025 | Pass@1 (%) | 99.2 | 90.2 | 88.3 | 79.2 | 97.5 |
| HLE | Pass@1 (%) | 30.6 | 25.1 | 26.3 | 13.7 | 37.7 |
| Codeforces | Classement | 2701 | 2386 | 2537 | 1480 | 2708 |
| SWE Verified | Résolu (%) | – | 73.1 | 74.9 | 77.2 | 76.2 |
| Terminal Bench 2.0 | Précision (%) | – | 46.4 | 35.2 | 42.8 | 54.2 |
| τ² Bench | Pass@1 (%) | – | 80.3 | 80.2 | 84.7 | 85.4 |
| Tool Decathlon | Pass@1 (%) | – | 35.2 | 29.0 | 38.6 | 36.4 |
Essayez Deepseek V3.2 avec 20 % de réduction !
DeepSeek V3.2 : Qu’a-t-il été fait pour mieux collaborer avec les développeurs ?
Pour mieux intégrer le raisonnement dans les scénarios d’utilisation d’outils, DeepSeek a introduit un Pipeline de synthèse de tâches agentiques à grande échelle lors de la phase de post-entraînement de V3.2. L’idée centrale est de générer systématiquement des données d’entraînement agentiques à grande échelle, plutôt que de s’appuyer sur des instructions artisanales ou des démonstrations humaines limitées.
Ce pipeline construit de manière procédurale des tâches qui obligent le modèle à raisonner, décider, appeler des outils, observer les résultats intermédiaires et ajuster son comportement en conséquence. En exposant le modèle à une grande variété d’interactions structurées, DeepSeek permet un post-entraînement agentique évolutif, améliorant considérablement à la fois la conformité comportementale et la généralisation dans des environnements interactifs complexes et multi-étapes, tels que la recherche, le codage et les workflows assistés par outils.
Les deux mises à jour les plus importantes sont :
Un format d’appel d’outils révisé, conçu pour être plus explicite et plus stable dans les interactions multi-étapes
Un support natif pour « raisonner avec des outils », où le raisonnement et l’utilisation d’outils sont structurellement intégrés plutôt que simplement entrelacés
Pour aider la communauté à comprendre et adopter ce nouveau modèle, DeepSeek fournit un dossier encoding dédié. Ce dossier contient des scripts Python et des cas de test qui montrent : comment encoder des messages compatibles OpenAI en une seule chaîne d’entrée attendue par DeepSeek-V3.2, et comment analyser la sortie texte du modèle pour revenir à des messages structurés.
import transformers
# encoding/encoding_dsv32.py
from encoding_dsv32 import encode_messages, parse_message_from_completion_text
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2")
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
encode_config = dict(thinking_mode="thinking", drop_thinking=True, add_default_bos_token=True)
prompt = encode_messages(messages, **encode_config)
tokens = tokenizer.encode(prompt)
Il est à noter que cette version n’inclut pas de modèle de chat basé sur Jinja. L’implémentation Python fournie est la référence faisant autorité. De plus, la fonction d’analyse de sortie suppose des sorties bien formées du modèle et est destinée à la démonstration et à l’expérimentation, pas à une utilisation directe en production sans gestion d’erreurs supplémentaire.
Essayez Deepseek V3.2 avec 20 % de réduction !
Pourquoi le rôle developer est-il nécessaire ?
Dans les scénarios agentiques réels, un modèle doit souvent gérer trois types d’informations distincts simultanément :
- L’intention réelle de l’utilisateur ou l’objectif de la tâche
- Le propre raisonnement et processus de décision du modèle
- Les stratégies de recherche, les contraintes des outils et les règles d’exécution fournies par le système ou le développeur
Dans les versions précédentes, ces signaux étaient généralement mélangés au sein des prompts utilisateur ou système. Avec le temps, cela a conduit à deux problèmes majeurs : d’une part, le modèle pouvait avoir du mal à distinguer l’intention de l’utilisateur des contraintes comportementales obligatoires ; d’autre part, à mesure que les chaînes d’outils devenaient plus complexes, la stabilité et la fiabilité de l’invocation d’outils se dégradaient notablement.
Le rôle developer introduit dans DeepSeek-V3.2 sert essentiellement de canal de contrôle dédié pour les agents de recherche et les agents orientés outils. Il est conçu pour porter des instructions strictement liées au comportement agentique, comme le périmètre de recherche, l’ordre d’utilisation des outils ou les contraintes de politique, sans participer à la sémantique conversationnelle ordinaire. Cette séparation explicite permet une compréhension contextuelle plus claire et établit une base structurelle pour un entraînement agentique plus évolutif et robuste.
Comment accéder à DeepSeek V3.2 dans Claude Code ?
Novita AI propose actuellement l’API Deepseek V3.2 en contexte complet la plus abordable.
Novita AI fournit des API avec 65K de contexte, et des coûts de $0.269/entrée et $0.4/sortie, prenant en charge la sortie structurée et l’appel de fonction, ce qui offre un soutien solide pour maximiser le potentiel d’agent de code de Deepseek V3.2.
Cache Read : $0.1345 / M Token indique le coût de lecture des tokens en cache en cas de hit. Ces tokens ont été précédemment calculés et stockés, donc aucune inférence supplémentaire du modèle n’est nécessaire. Dans les systèmes où de nombreuses requêtes partagent le même préfixe de prompt, réutilisent l’historique de conversation, les instructions d’outils ou les textes de règles fixes, ou où les résultats de récupération RAG sont très répétitifs, un taux de hits élevé peut être atteint, réduisant considérablement le coût global d’inférence.
Première étape : Obtenir une clé API
Étape 1 : Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Démarrez votre essai gratuit pour explorer les capacités du modèle sélectionné.
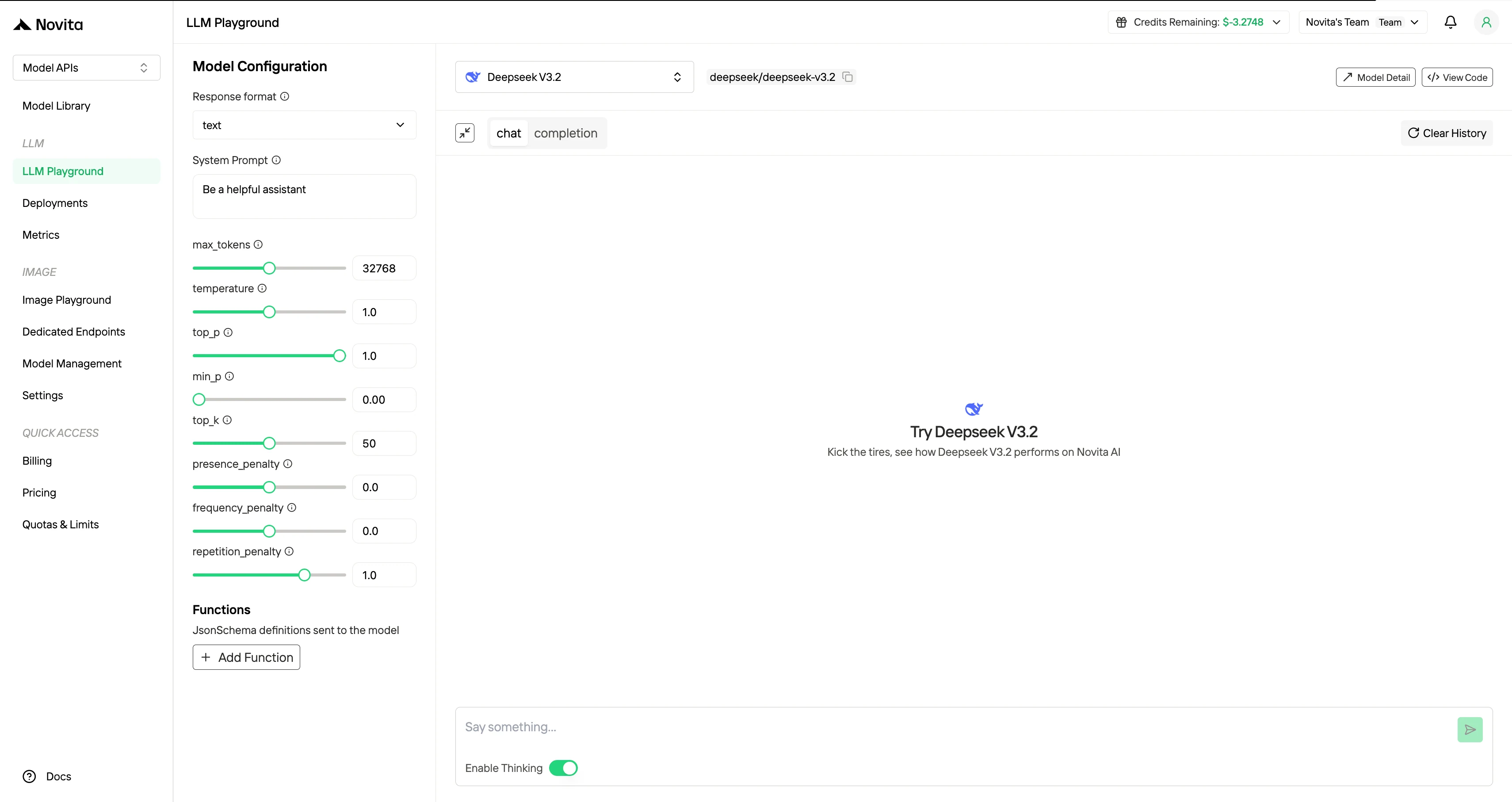
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page « Settings », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
api_key="<Votre clé API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "Vous êtes un assistant utile."},
{"role": "user", "content": "Bonjour, comment allez-vous ?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Utiliser DeepSeek V3.2 avec Claude Code
Étape 1 : Installer Claude Code
Avant d’installer Claude Code, assurez-vous que votre système répond aux exigences minimales. Node.js 18 ou supérieur doit être installé dans votre environnement local. Vous pouvez vérifier votre version de Node.js en exécutant node --version dans votre terminal.
Pour Windows
Ouvrez l’invité de commandes et exécutez les commandes suivantes :
npm install -g @anthropic-ai/claude-code
npx win-claude-code@latest
L’installation globale garantit que Claude Code est accessible depuis n’importe quel répertoire de votre système. La commande npx win-claude-code@latest télécharge et exécute la dernière version spécifique à Windows.
Pour Mac et Linux
Ouvrez un terminal et exécutez :
npm install -g @anthropic-ai/claude-code
Les utilisateurs Mac peuvent procéder directement à l’installation globale sans nécessiter de commandes supplémentaires spécifiques à la plateforme. Le processus d’installation configure automatiquement les dépendances et les variables PATH nécessaires.
Étape 2 : Configurer les variables d’environnement
Les variables d’environnement configuent Claude Code pour utiliser Deepseek v3.2 via les points de terminaison API de Novita AI. Ces variables indiquent à Claude Code où envoyer les requêtes et comment s’authentifier.
Pour Windows
Ouvrez l’invité de commandes et définissez les variables d’environnement suivantes :
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Clé API Novita>
set ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
set ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Remplacez <Clé API Novita> par votre clé API réelle obtenue depuis la plateforme Novita AI. Ces variables restent actives pour la session en cours et doivent être redéfinies si vous fermez l’invité de commandes.
Pour Mac et Linux
Ouvrez un terminal et exportez les variables d’environnement suivantes :
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Clé API Novita>"
export ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
export ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Étape 3 : Démarrer Claude Code
Une fois l’installation et la configuration terminées, vous pouvez maintenant démarrer Claude Code dans le répertoire de votre projet. Naviguez jusqu’à l’emplacement souhaité de votre projet à l’aide de la commande cd :
cd <répertoire-de-votre-projet>
claude .
Le paramètre point (.) indique à Claude Code de travailler dans le répertoire courant. Au démarrage, vous verrez l’invite de Claude Code apparaître dans une session interactive.
Cela indique que l’outil est prêt à recevoir vos instructions. L’interface offre un environnement propre et intuitif pour les interactions de programmation en langage naturel.
Étape 4 : Utiliser Claude Code dans VSCode ou Cursor
Claude Code s’intègre parfaitement aux environnements de développement populaires. Il améliore votre flux de travail existant sans le remplacer.
Vous pouvez utiliser Claude Code directement dans le terminal de VSCode ou Cursor. Cela maintient l’accès à vos outils de développement habituels tout en bénéficiant de l’assistance IA.
De plus, des plugins Claude Code sont disponibles pour VSCode et Cursor.
Comment utiliser des modèles externes dans Claude Code ?
Si vous souhaitez basculer dynamiquement entre différents grands modèles de langage (par exemple ceux d’Anthropic, Zhipu, Moonshot) dans votre flux de développement, il existe des stratégies pour le faire sans modifications lourdes du code. Cette section explique comment échanger rapidement des modèles à l’aide d’API unifiées et de bascules de configuration.
Utilisation des variables d’environnement (approche Claude Code) :
Si vous travaillez avec des outils comme Claude Code ou un SDK lié à une API spécifique, vous pouvez changer de modèle simplement en ajustant votre configuration d’environnement. Novita AI propose plusieurs options de modèles que vous pouvez expérimenter pour trouver la meilleure solution.
Consultez d’autres modèles maintenant !
DeepSeek V3.2 introduit DSA comme une amélioration architecturale ciblée qui réduit considérablement le coût de calcul, augmente l’efficacité sur les longs contextes et améliore la précision centrée sur le code tout en maintenant des performances de raisonnement compétitives. Le modèle permet une analyse évolutive de grands dépôts et de documents techniques complexes, démontrant un bon équilibre entre efficacité et capacité par rapport à DeepSeek V3.1-Terminus et aux alternatives propriétaires. Ces avancées font de DeepSeek V3.2 une solution rentable pour les flux de développement soutenus et les applications IA à long contexte.
Questions fréquemment posées
Quel est le principal avantage de DeepSeek Sparse Attention (DSA) dans DeepSeek V3.2 ?
DeepSeek V3.2 utilise DSA pour activer sélectivement les connexions d’attention, réduisant le coût quadratique de l’attention tout en préservant une compréhension précise du code sur de longs contextes.
En quoi DeepSeek V3.2 diffère-t-il de DeepSeek V3.1-Terminus dans les workflows de codage pratiques ?
DeepSeek V3.2 offre un coût opérationnel plus bas, une fenêtre de contexte de 128K et une stabilité d’inférence plus rapide par rapport à DeepSeek V3.1-Terminus, ce qui se traduit par une analyse de code à l’échelle du dépôt plus efficace.
DeepSeek V3.2 améliore-t-il le traitement des documents techniques à long contexte ?
Oui. DeepSeek V3.2 prend en charge l’analyse simultanée de documents complexes et de relations inter-fichiers, surpassant DeepSeek V3.1-Terminus dans les tâches de raisonnement multi-documents.
Novita AI est la plateforme cloud tout-en-un qui alimente vos ambitions en IA. API intégrées, sans serveur, instance GPU — les outils rentables dont vous avez besoin. Supprimez l’infrastructure, commencez gratuitement et réalisez votre vision de l’IA.
Lectures recommandées
Comment utiliser Kimi K2.7 Code dans Claude Code via Novita AI
Comment accéder à Qwen 3 Coder : Qwen Code ; Claude Code ; Trae
DeepSeek vs Qwen : identifier quel écosystème répond aux besoins de production



