

Los desarrolladores que gestionan grandes bases de código o flujos de trabajo con múltiples documentos se enfrentan a desafíos persistentes que incluyen alto costo computacional, rendimiento inestable en contexto largo y comprensión inconsistente del código al usar modelos Transformer convencionales. Estas limitaciones restringen la eficiencia de la iteración, limitan el análisis a escala de repositorio y aumentan los gastos operativos. La introducción de DeepSeek V3.2 aborda estos puntos débiles mediante la integración de DeepSeek Sparse Attention (DSA), un mecanismo diseñado para reducir la sobrecarga de atención, acelerar el razonamiento contextual y estabilizar la generación de código.
Este artículo examina cómo DeepSeek V3.2 mejora la eficiencia de costos, el procesamiento de contexto largo y las capacidades centradas en el código. Presenta una guía operativa para implementar DeepSeek V3.2 a través de Novita AI y Claude Code.
¡Atención! Novita AI lanza su campaña “Build Month”, ofreciendo a los desarrolladores un incentivo exclusivo de hasta un 20% de descuento en todos los productos principales.
¿Cuáles son las nuevas funciones de codificación en DeepSeek V3.2?
DSA es un mecanismo de atención revolucionario que cambia fundamentalmente la forma en que el modelo procesa la información. Mientras que los Transformers tradicionales requieren que cada token atienda a todos los demás tokens —lo que resulta en un costo computacional cuadrático (O(n²))— DSA introduce un mecanismo de selección granular y consciente del contenido:
- Filtrado inteligente: Durante el entrenamiento, el modelo aprende a identificar qué relaciones entre tokens son realmente importantes para tareas específicas.
- Conexiones dinámicas: Selección en tiempo real de las conexiones de atención necesarias según el contenido de entrada.
- Optimización de tareas: Se enfoca en diferentes patrones estructurales al procesar código versus documentos legales.
Tres mejoras principales habilitadas por DSA
Se emplea la Auto-Adaptación Directa como mecanismo auxiliar para mejorar el rendimiento general del modelo sin alterar la arquitectura principal. Mediante este enfoque, el modelo logra una eficiencia de costos significativa al permitir una inferencia más económica mientras preserva la calidad de generación y análisis de código comparable a v3.1, lo que respalda pruebas frecuentes e iteraciones rápidas.
DSA también fortalece la utilización de contexto largo al aprovechar efectivamente una ventana de contexto de hasta 128K tokens, lo que mejora el análisis simultáneo de múltiples archivos, la comprensión de dependencias entre archivos y el procesamiento de documentación técnica compleja.
Además, DSA contribuye a mejorar las capacidades relacionadas con el código, incluyendo una respuesta de inferencia más rápida, una comprensión del código más precisa y una calidad de generación de código más estable; todo ello mejora la confiabilidad y eficiencia del modelo en escenarios de desarrollo de software a gran escala.
Marco de aprendizaje por refuerzo escalable
Al adoptar un protocolo robusto de aprendizaje por refuerzo y escalar la computación post-entrenamiento, DeepSeek-V3.2 alcanza un rendimiento comparable a GPT-5. En particular, la variante de alta computación, DeepSeek-V3.2-Speciale, supera consistentemente a GPT-5 y demuestra capacidades de razonamiento a la par de Gemini-3.0-Pro.
| Benchmark | Métrica | DeepSeek-V3.2-Speciale | DeepSeek-V3.2-Thinking | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Pass@1 (%) | 96.0 | 93.1 | 94.6 | 87.0 | 95.0 |
| HMMT 2025 | Pass@1 (%) | 99.2 | 90.2 | 88.3 | 79.2 | 97.5 |
| HLE | Pass@1 (%) | 30.6 | 25.1 | 26.3 | 13.7 | 37.7 |
| Codeforces | Rating | 2701 | 2386 | 2537 | 1480 | 2708 |
| SWE Verified | Resolved (%) | – | 73.1 | 74.9 | 77.2 | 76.2 |
| Terminal Bench 2.0 | Accuracy (%) | – | 46.4 | 35.2 | 42.8 | 54.2 |
| τ² Bench | Pass@1 (%) | – | 80.3 | 80.2 | 84.7 | 85.4 |
| Tool Decathlon | Pass@1 (%) | – | 35.2 | 29.0 | 38.6 | 36.4 |
¡Prueba Deepseek V3.2 con 20% de descuento!
DeepSeek V3.2: ¿Qué se ha hecho para colaborar mejor con los desarrolladores?
Para integrar mejor el razonamiento en escenarios de uso de herramientas, DeepSeek introdujo un pipeline de síntesis de tareas agentivas a gran escala durante la etapa post-entrenamiento de V3.2. La idea central es generar datos de entrenamiento agentivos de manera sistemática a gran escala, en lugar de depender de prompts artesanales o demostraciones humanas limitadas.
Este pipeline construye programáticamente tareas que requieren que el modelo razone, decida, llame a herramientas, observe resultados intermedios y ajuste su comportamiento en consecuencia. Al exponer el modelo a una amplia variedad de interacciones estructuradas, DeepSeek permite un entrenamiento agentivo escalable, mejorando significativamente tanto el cumplimiento conductual como la generalización en entornos interactivos complejos de múltiples pasos, como búsqueda, codificación y flujos de trabajo aumentados con herramientas.
Las dos actualizaciones más importantes son:
Un formato de llamada a herramientas revisado, diseñado para ser más explícito y más estable en interacciones de múltiples pasos.
Soporte nativo para “pensar con herramientas”, donde el razonamiento y el uso de herramientas se integran estructuralmente en lugar de intercalarse de manera suelta.
Para ayudar a la comunidad a comprender y adoptar esta nueva plantilla, DeepSeek proporciona una carpeta dedicada encoding. Esta carpeta incluye scripts de Python y casos de prueba que demuestran: cómo codificar mensajes compatibles con OpenAI en una sola cadena de entrada esperada por DeepSeek-V3.2 y cómo analizar la salida de texto del modelo de vuelta a mensajes estructurados.
import transformers
# encoding/encoding_dsv32.py
from encoding_dsv32 import encode_messages, parse_message_from_completion_text
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V3.2")
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
encode_config = dict(thinking_mode="thinking", drop_thinking=True, add_default_bos_token=True)
prompt = encode_messages(messages, **encode_config)
tokens = tokenizer.encode(prompt)
Vale la pena señalar que este lanzamiento no incluye una plantilla de chat basada en Jinja. La implementación en Python proporcionada es la referencia autorizada. Además, la función de análisis de salida asume salidas del modelo bien formadas y está destinada a fines de demostración y experimentación, no para uso directo en producción sin manejo adicional de errores.
¡Prueba Deepseek V3.2 con 20% de descuento!
¿Por qué es necesario el rol de developer?
En escenarios agentivos reales, un modelo a menudo necesita manejar tres tipos distintos de información simultáneamente:
- La intención real del usuario o el objetivo de la tarea.
- El propio proceso de razonamiento y toma de decisiones del modelo.
- Estrategias de búsqueda, restricciones de herramientas y reglas de ejecución proporcionadas por el sistema o el developer.
En versiones anteriores, estas señales solían mezclarse dentro de los prompts de usuario o sistema. Con el tiempo, esto llevó a dos problemas principales. Primero, el modelo podía tener dificultades para distinguir la intención del usuario de las restricciones de comportamiento obligatorias. Segundo, a medida que las cadenas de herramientas se volvían más complejas, la estabilidad y confiabilidad de la invocación de herramientas se degradaban notablemente.
El rol developer introducido en DeepSeek-V3.2 sirve esencialmente como un canal de control dedicado para agentes de búsqueda y agentes orientados a herramientas. Está diseñado para llevar instrucciones estrictamente relacionadas con el comportamiento del agente, como el alcance de la búsqueda, el orden de uso de herramientas o las restricciones de políticas, sin participar en la semántica conversacional ordinaria. Esta separación explícita permite una comprensión contextual más clara y establece una base estructural para un entrenamiento agentivo más escalable y robusto.
¿Cómo acceder a DeepSeek V3.2 en Claude Code?
Novita AI actualmente ofrece la API de Deepseek V3.2 con contexto completo más asequible.
Novita AI proporciona APIs con contexto de 65K, y costos de $0.269/input y $0.4/output, soportando salida estructurada y function calling, lo que brinda un fuerte respaldo para maximizar el potencial del agente de código de Deepseek V3.2.
Cache Read: $0.1345 / M Token indica el costo de leer tokens en caché cuando ocurre un acierto de caché. Estos tokens han sido previamente calculados y almacenados, por lo que no se requiere inferencia adicional del modelo. En sistemas donde muchas solicitudes comparten el mismo prefijo de prompt, reutilizan el historial de conversación, instrucciones de herramientas o textos de reglas fijas, o donde los resultados de recuperación RAG son muy repetitivos, se puede lograr una alta tasa de aciertos de caché, reduciendo significativamente el costo general de inferencia.
Primero: Obtener la clave API
Paso 1: Inicia sesión en tu cuenta y haz clic en el botón Model Library.

Paso 2: Elige tu modelo
Navega por las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
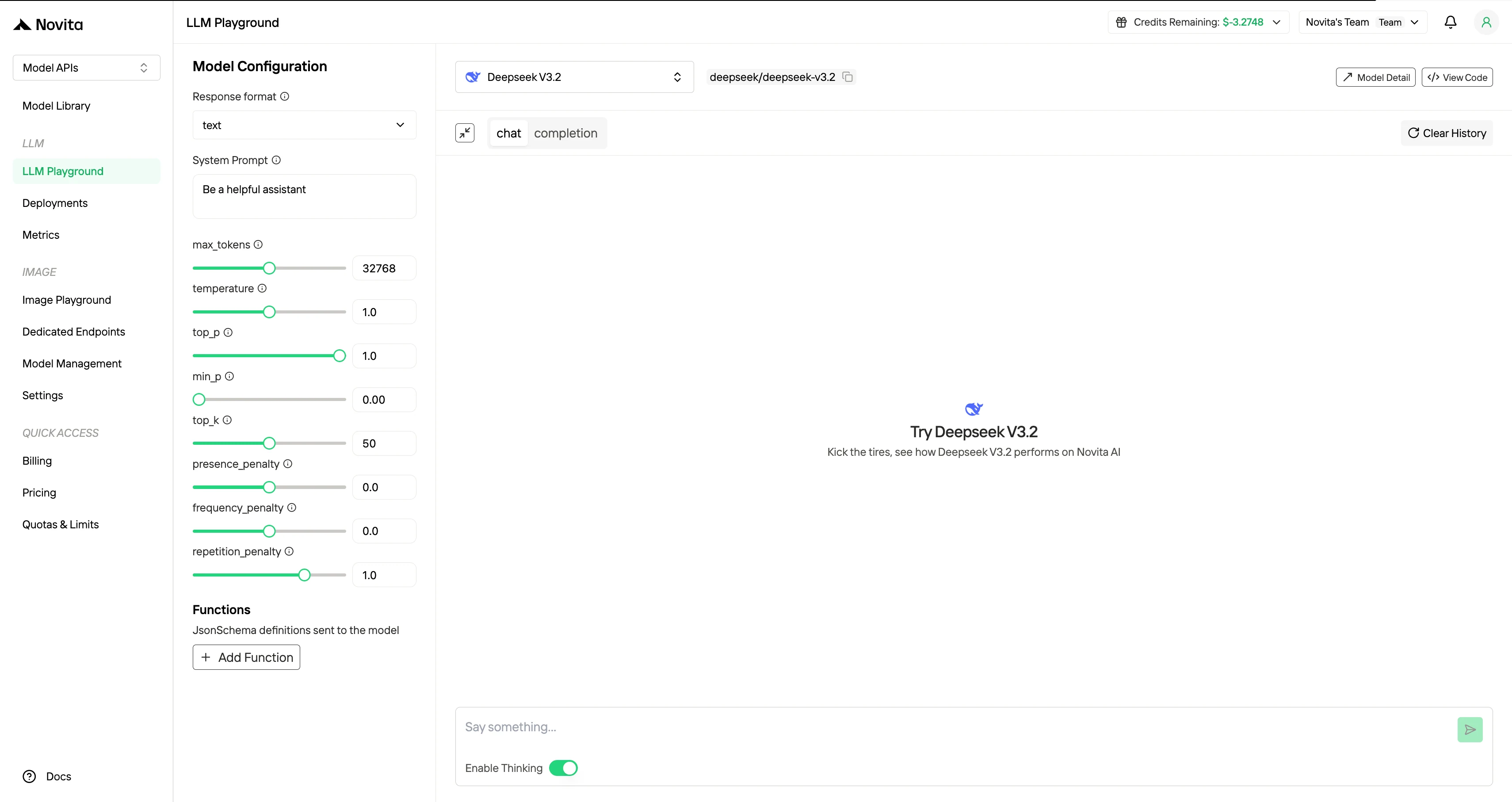
Paso 4: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Entra en la página “Settings” y copia la clave API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de chat completions para usuarios de Python.
from openai import OpenAI
client = OpenAI(
api_key="<Tu clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=65536,
temperature=0.7
)
print(response.choices[0].message.content)
Usar DeepSeek V3.2 con Claude Code
Paso 1: Instalar Claude Code
Antes de instalar Claude Code, asegúrate de que tu sistema cumpla con los requisitos mínimos. Node.js 18 o superior debe estar instalado en tu entorno local. Puedes verificar tu versión de Node.js ejecutando node --version en tu terminal.
Para Windows
Abre el Símbolo del sistema y ejecuta los siguientes comandos:
npm install -g @anthropic-ai/claude-code
npx win-claude-code@latest
La instalación global asegura que Claude Code sea accesible desde cualquier directorio de tu sistema. El comando npx win-claude-code@latest descarga y ejecuta la última versión específica para Windows.
Para Mac y Linux
Abre la Terminal y ejecuta:
npm install -g @anthropic-ai/claude-code
Los usuarios de Mac pueden continuar directamente con la instalación global sin necesidad de comandos adicionales específicos de la plataforma. El proceso de instalación configura automáticamente las dependencias necesarias y las variables PATH.
Paso 2: Configurar variables de entorno
Las variables de entorno configuran Claude Code para usar Deepseek v3.2 a través de los endpoints de API de Novita AI. Estas variables le indican a Claude Code dónde enviar las solicitudes y cómo autenticarse.
Para Windows
Abre el Símbolo del sistema y establece las siguientes variables de entorno:
set ANTHROPIC_BASE_URL=https://api.novita.ai/anthropic
set ANTHROPIC_AUTH_TOKEN=<Clave API de Novita>
set ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
set ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Reemplaza <Clave API de Novita> con tu clave API real obtenida de la plataforma Novita AI. Estas variables permanecen activas para la sesión actual y deben restablecerse si cierras el Símbolo del sistema.
Para Mac y Linux
Abre la Terminal y exporta las siguientes variables de entorno:
export ANTHROPIC_BASE_URL="https://api.novita.ai/anthropic"
export ANTHROPIC_AUTH_TOKEN="<Clave API de Novita>"
export ANTHROPIC_MODEL="deepseek/deepseek-v3.2"
export ANTHROPIC_SMALL_FAST_MODEL="deepseek/deepseek-v3.2"
Paso 3: Iniciar Claude Code
Una vez completada la instalación y configuración, ya puedes iniciar Claude Code en el directorio de tu proyecto. Navega a la ubicación de tu proyecto deseada usando el comando cd:
cd <directorio-de-tu-proyecto>
claude .
El parámetro punto (.) le indica a Claude Code que opere en el directorio actual. Al iniciar, verás el prompt de Claude Code aparecer en una sesión interactiva.
Esto indica que la herramienta está lista para recibir tus instrucciones. La interfaz proporciona un entorno limpio e intuitivo para interacciones de programación en lenguaje natural.
Paso 4: Usar Claude Code en VSCode o Cursor
Claude Code se integra perfectamente con entornos de desarrollo populares. Mejora tu flujo de trabajo existente en lugar de reemplazarlo.
Puedes usar Claude Code directamente en la terminal dentro de VSCode o Cursor. Esto mantiene el acceso a tus herramientas de desarrollo familiares mientras aprovechas la asistencia de IA.
Adicionalmente, los complementos de Claude Code están disponibles tanto para VSCode como para Cursor.
¿Cómo usar modelos externos en Claude Code?
Si deseas cambiar dinámicamente entre diferentes modelos de lenguaje grandes (por ejemplo, Anthropic Claude, Zhipu GLM y Moonshot Kimi) en tu flujo de trabajo de desarrollo, existen estrategias para hacerlo sin cambios pesados en el código. Esta sección explica cómo intercambiar modelos rápidamente usando APIs unificadas y alternancias de configuración.
Usando variables de entorno (enfoque de Claude Code):
Si trabajas con herramientas como Claude Code o un SDK vinculado a una API específica, puedes cambiar de modelos simplemente ajustando tu configuración de entorno. Novita AI ofrece múltiples opciones de modelos que puedes experimentar para encontrar el más adecuado.
DeepSeek V3.2 introduce DSA como una mejora arquitectónica específica que reduce sustancialmente el costo computacional, aumenta la efectividad en contexto largo y mejora la precisión centrada en el código, manteniendo al mismo tiempo un rendimiento de razonamiento competitivo. El modelo permite el análisis escalable de grandes repositorios y documentos técnicos complejos, demostrando un equilibrio favorable entre eficiencia y capacidad en comparación con DeepSeek V3.1-Terminus y alternativas propietarias. Estos avances establecen a DeepSeek V3.2 como una solución rentable para flujos de trabajo de desarrollo sostenidos y aplicaciones de IA de contexto largo.
Preguntas frecuentes
¿Cuál es la ventaja principal de DeepSeek Sparse Attention (DSA) dentro de DeepSeek V3.2?
DeepSeek V3.2 utiliza DSA para activar selectivamente las conexiones de atención, reduciendo el costo de atención cuadrático mientras preserva una comprensión precisa del código a lo largo de contextos largos.
¿En qué se diferencia DeepSeek V3.2 de DeepSeek V3.1-Terminus en flujos de trabajo de codificación prácticos?
DeepSeek V3.2 proporciona un costo operativo más bajo, una ventana de contexto de 128K y una estabilidad de inferencia más rápida en comparación con DeepSeek V3.1-Terminus, lo que resulta en un análisis de código a escala de repositorio más eficiente.
¿DeepSeek V3.2 mejora el procesamiento de documentos técnicos de contexto largo?
Sí. DeepSeek V3.2 soporta el análisis simultáneo de documentos complejos y relaciones entre archivos, superando a DeepSeek V3.1-Terminus en tareas de razonamiento con múltiples documentos.
Novita AI es la plataforma integral en la nube que impulsa tus ambiciones de IA. APIs integradas, serverless, instancias GPU — las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.
Lecturas recomendadas
Cómo usar Kimi K2.7 Code en Claude Code a través de Novita AI
Cómo acceder a Qwen 3 Coder: Qwen Code; Claude Code; Trae
DeepSeek vs Qwen: Identifica qué ecosistema se adapta a las necesidades de producción



