

NVIDIA 的 GeForce RTX 5090 采用革命性的 Blackwell 架构,配备 32GB GDDR7 内存和 21,760 个 CUDA 核心,为 AI 计算树立了新的标准。随着 AI 模型日益复杂,开发者和研究人员对尖端 GPU 基础设施的访问变得至关重要。
Novita AI 现提供 RTX 5090 GPU 按需使用,价格为 $0.50/小时 —— 比 RunPod 的 $0.79/小时便宜 37%。这一卓越性价比让全球最强大的消费级 GPU 触手可及,无需前期硬件投资即可用于 AI 推理、训练和开发。
使用 RTX 5090 带来的性能提升

图片来源:Nvidia
RTX 5090 GPU 基于 NVIDIA 最新的 Blackwell 架构,相较于前代产品实现了显著飞跃。NVIDIA 声称,RTX 5090 在某些场景下性能可达 RTX 4090 的 2 倍,使其成为高要求 AI 推理、机器学习训练和深度学习研究的理想选择。
在 RTX 5090 出现之前,处理大型 AI 模型的开发者不得不在性能与成本之间做出艰难取舍:要么使用昂贵的数据中心级 GPU(如 H100),要么退而求其次使用难以应对内存密集型工作负载的低性能消费级显卡。如今,通过 Novita AI 提供的 RTX 5090,开发者能够以消费级 GPU 的价格获得接近数据中心的性能。
RTX 5090 的 32GB GDDR7 内存对 AI 工作负载而言尤为具有变革性。许多以往需要昂贵 40GB+ 显卡或多 GPU 配置才能运行的流行模型(包括大型 Transformer 模型和复杂神经网络架构),现在都能在单块 RTX 5090 上高效运行。
RTX 5090 硬件规格对比:RTX 5090 vs RTX 4090
与上一代产品直接比较时,RTX 5090 的优势显而易见。以下详细对比了 RTX 5090 相较于 RTX 4090 在所有关键规格上的提升:
| 规格 | RTX 5090 | RTX 4090 | 提升幅度 |
|---|---|---|---|
| NVIDIA 架构 | Blackwell | Ada Lovelace | 完整一代跃升 |
| AI TOPS | 3352 | 1321 | 2.5 倍 AI 算力 |
| Tensor Core | 第 5 代 | 第 4 代 | 支持 FP4 量化 |
| 内存配置 | 32GB GDDR7 | 24GB GDDR6X | 33% 更多显存 |
| 内存带宽 | 1792 GB/s | 1008 GB/s | 78% 更高带宽 |
| CUDA 核心 | 21,760 | 16,384 | 33% 更多核心 |
| 加速频率 | 2.41 GHz | 2.52 GHz | 优化能效 |
这些规格转化为 AI 工作负载中显著的性能优势:
AI 推理方面:AI TOPS 提升 2.5 倍,加上 33% 的显存增加,使得更大的语言模型可以以更大的批处理量和更快的推理速度运行。以往需要跨多块 GPU 进行模型分片的模型,现在可以轻松容纳在单块 RTX 5090 的 32GB 内存中。
AI 训练方面:增强的内存带宽(提升 78%)加速了训练过程中的梯度计算和参数更新,而额外显存允许更大的批量大小,从而实现更稳定的训练和更快的收敛。
AI 开发方面:FP4 量化支持使开发者能够探索超高效的模型部署方式,在保持可接受精度的同时,将兼容模型的推理吞吐量提升一倍。
利用高级 AI 特性
RTX 5090 引入了多项专为加速 AI 工作负载而设计的突破性技术:
第 5 代 Tensor Core 原生支持多种精度格式,包括 FP4、FP8、FP16 及传统格式。这种灵活性使开发者能够针对最大吞吐量优化模型,同时满足特定用例的精度要求。
增强型内存架构 采用 GDDR7 技术,为大规模模型推理提供持续的高带宽 —— 内存密集型操作往往是部署场景中的主要瓶颈。
Blackwell 架构优化 包括专用神经处理单元和改进的任务调度,可显著加速基于 Transformer 的模型、计算机视觉网络和生成式 AI 应用。
RTX 5090 在生产级 AI 工作负载中的应用
虽然 RTX 5090 提供了卓越的原始性能,但要在生产级 AI 环境中充分发挥其潜力,仍需精心优化并配备合适的部署基础设施。
模型性能优化
RTX 5090 的架构专为加速现代 AI 工作负载而设计。其第 5 代 Tensor Core 支持多种精度格式,包括全新的 FP4,使开发者能够在保持可接受精度的同时,针对最大吞吐量优化模型。
对于推理工作负载,RTX 5090 的 32GB 内存容量消除了许多以往需要昂贵多 GPU 配置的瓶颈。那些曾经需要数据中心级硬件的大型语言模型、计算机视觉网络和生成式 AI 模型,如今可在单块 RTX 5090 上高效运行。
AI 模型部署场景
| 用例 | 支持的模型大小 | 关键优势 |
|---|---|---|
| 大型语言模型 | 最多 700 亿参数 | 自然语言处理、对话式 AI |
| 计算机视觉 | 高分辨率模型 | 目标检测、图像分割、医学影像 |
| 生成式 AI | 复杂架构 | 图像生成、文本合成、多模态应用 |
| 机器学习训练 | 大型数据集 | 神经网络训练、模型微调 |
企业部署考量
与需要自行管理 RTX 5090 高功耗和散热需求的桌面安装不同,在 Novita AI 上进行云端部署可省去这些基础设施难题。575W 功耗和高级散热要求均在数据中心层面处理,让开发者能够专注于优化 AI 模型而非硬件管理。
为何选择 Novita AI 使用 RTX 5090
Novita AI 是使用 RTX 5090 性能的卓越平台,为 AI 开发者、研究人员和企业提供无与伦比的价值与灵活性。
1. 显著价格优势与灵活定价模式
| 提供商 | RTX 5090 每小时价格 | 使用 Novita AI 节省 |
|---|---|---|
| Novita AI | $0.50/小时 | - |
| RunPod | $0.79/小时 | 节省 37% |
灵活定价选项:
- 按需计费:按小时付费,无承诺,适合实验性及可变工作负载
- 订阅:年度订阅可节省数百美元,同时确保资源可用性及优先使用权
2. Novita AI 上提供的高性能 GPU
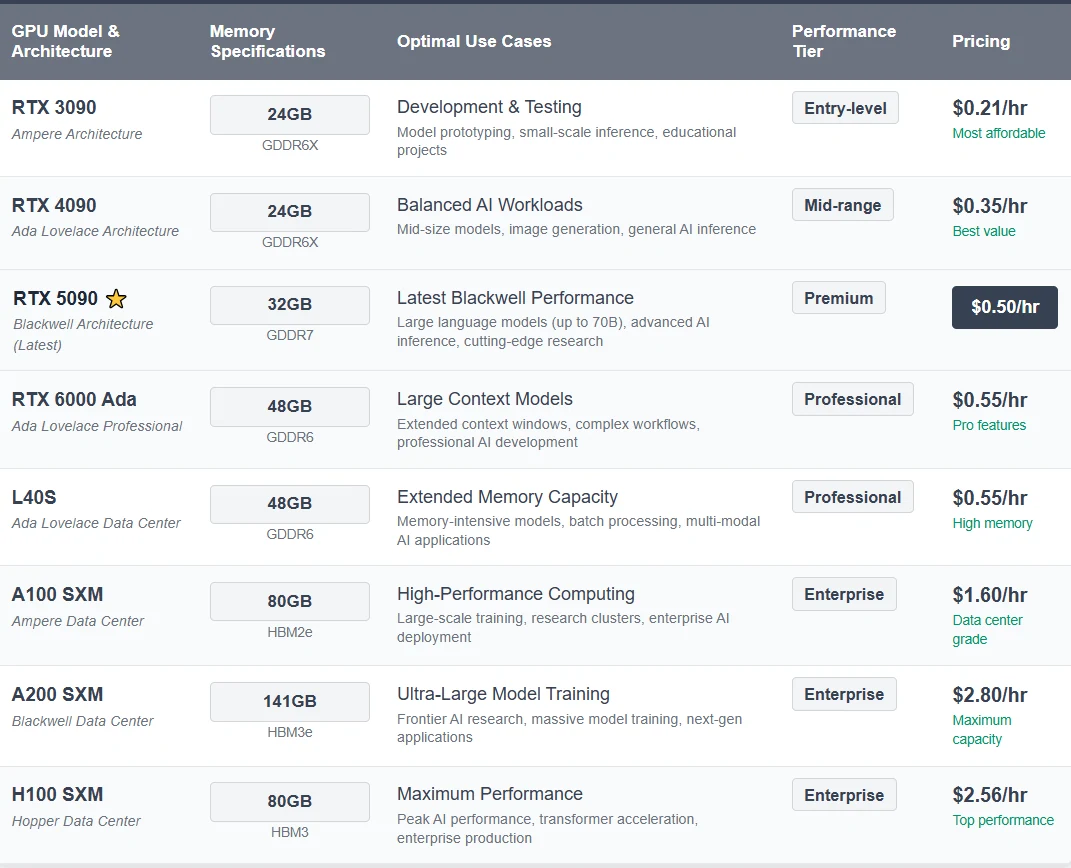
3. 即用模板与自定义灵活性
预配置模板 消除了手动设置的复杂性,为热门模型提供优化配置,包括经过测试的部署参数、环境变量和容器配置。可立即上手使用 DeepSeek、Llama 等领先 AI 框架的模型。
自定义模板支持 为高级用户提供对部署环境的完全控制。可创建包含个性化部署脚本、定制软件栈和针对性优化设置的专业配置。
4. 全球部署网络
Novita AI 的全球基础设施横跨 18 个区域,覆盖多个大洲,提供全面的全球覆盖:
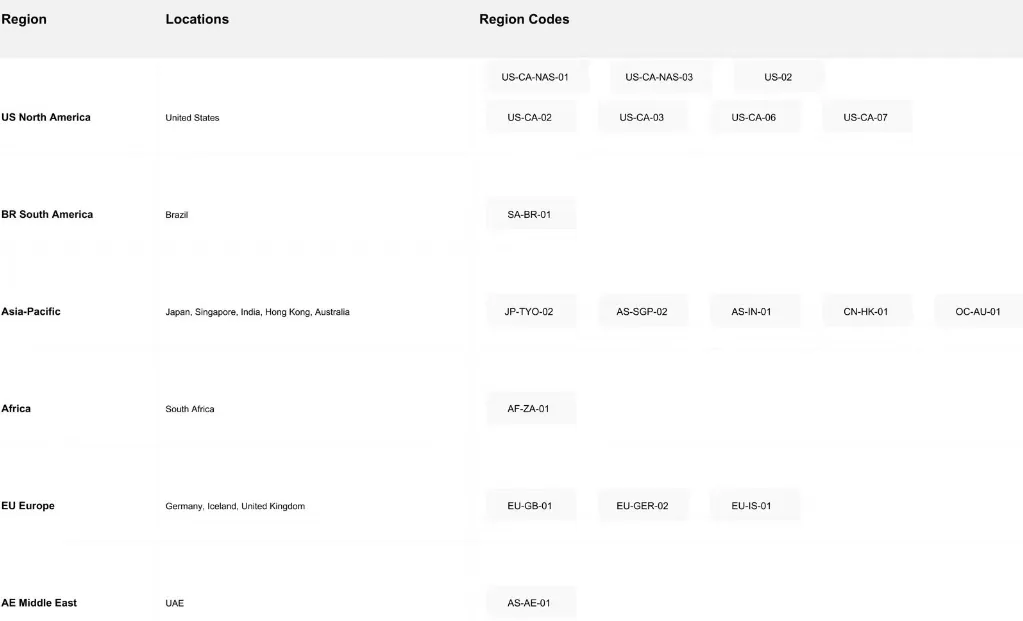
网络优势:
- 降低延迟:在更靠近最终用户的位置部署,获得最佳性能
- 可靠访问:多区域提供冗余和可用性保障
- 合规支持:区域部署有助于满足数据主权要求
- 可扩展基础设施:跨区域分配工作负载,实现最高性能
无论您是面向全球受众提供服务,还是需要满足区域数据合规要求,Novita AI 的广泛网络都能提供现代 AI 应用所需的地理灵活性。
立即在 Novita AI 上使用 RTX 5090 GPU
Novita AI 提供 RTX 5090 GPU 的即时访问,附带行业领先的价格和性能。尖端硬件、灵活定价和全球基础设施的结合,使 Novita AI 成为驾驭 RTX 5090 性能的理想平台。
Novita AI 云 GPU 的即时优势
| 优势 | 好处 |
|---|---|
| 基础设施抽象 | 无需硬件管理 —— 即时访问企业级 GPU 基础设施 |
| 可扩展性能 | 从一块 GPU 开始,按需扩展至跨区域多个实例 |
| 企业级可靠性 | 配备冗余电源、散热和网络的数据中心基础设施 |
| 成本效益 | 按小时计费,仅需为实际使用付费,费率具竞争力 |
无论您是运行大型语言模型的推理、开发计算机视觉应用、训练生成式 AI 模型,还是进行机器学习研究,Novita AI 上的 RTX 5090 都能提供您所需的性能,且价格随使用量灵活调整。
RTX 5090 实例 现已通过 Novita AI 提供。请访问我们的平台启动您的第一个实例,体验 GPU 计算的未来。
常见问题解答
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷途径,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
推荐阅读



