

革新的なBlackwellアーキテクチャを搭載したNVIDIA GeForce RTX 5090は、32GBのGDDR7メモリと21,760のCUDAコアにより、AIコンピューティングに新たな基準を打ち立てます。AIモデルがますます複雑になるにつれ、開発者や研究者にとって最先端のGPUインフラへのアクセスが不可欠になっています。
Novita AIは現在、RTX 5090 GPUを $0.50/時間 でオンデマンド提供しています。これはRunPodの$0.79/時間より37%安くなっています。この優れた価値により、初期ハードウェア投資なしで、世界で最も強力なコンシューマーGPUをAI推論、トレーニング、開発に利用できます。
RTX 5090を活用したパフォーマンス向上

出典: Nvidia
RTX 5090 GPUはNVIDIAの最新Blackwellアーキテクチャに基づいており、従来世代からの大幅な飛躍を表しています。NVIDIAは、RTX 5090が特定のシナリオでRTX 4090の最大2倍のパフォーマンスを発揮すると発表しており、要求の厳しいAI推論、機械学習トレーニング、深層学習研究に理想的な選択肢となっています。
RTX 5090以前は、大規模AIモデルを扱う開発者はパフォーマンスとコストの間で難しいトレードオフを迫られていました。高価なデータセンターGPU(H100など)を使うか、メモリを多く消費するワークロードに苦戦する低パフォーマンスのコンシューマーカードで妥協するかの選択でした。現在は、Novita AIでRTX 5090が利用可能になり、開発者はコンシューマーGPUの価格でデータセンターに近いパフォーマンスを手に入れることができます。
RTX 5090の32GB GDDR7メモリは、特にAIワークロードにおいて変革的です。従来は高価な40GB以上のカードやマルチGPU構成が必要だった多くの人気モデル(大規模トランスフォーマーモデルや複雑なニューラルネットワークアーキテクチャなど)が、1枚のRTX 5090で効率的に実行できるようになりました。
RTX 5090とRTX 4090のハードウェア仕様比較
RTX 5090の優位性は、前世代との直接比較で明らかになります。以下は、RTX 5090がRTX 4090を主要な仕様すべてで上回る包括的な内訳です。
| 仕様 | RTX 5090 | RTX 4090 | 改善点 |
|---|---|---|---|
| NVIDIAアーキテクチャ | Blackwell | Ada Lovelace | フル世代ジャンプ |
| AI TOPS | 3352 | 1321 | 2.5倍のAI性能 |
| Tensorコア | 第5世代 | 第4世代 | FP4量子化対応 |
| メモリ構成 | 32GB GDDR7 | 24GB GDDR6X | 33%多いVRAM |
| メモリ帯域幅 | 1792 GB/秒 | 1008 GB/秒 | 78%高い帯域幅 |
| CUDAコア | 21,760 | 16,384 | 33%多いコア数 |
| ブーストクロック | 2.41 GHz | 2.52 GHz | 効率性重視に最適化 |
これらの仕様は、AIワークロードにおいて顕著なパフォーマンス上の利点をもたらします。
AI推論の場合: AI TOPSが2.5倍増加し、VRAMが33%増加したことで、大規模言語モデルを改善されたバッチサイズと高速な推論速度で実行できます。従来は複数のGPUにモデルを分割する必要があったモデルも、1枚のRTX 5090の32GBメモリに余裕で収まります。
AIトレーニングの場合: 拡張されたメモリ帯域幅(78%向上)により、トレーニング中の勾配計算とパラメータ更新が高速化され、追加のVRAMによりバッチサイズを大きくできるため、より安定したトレーニングと高速な収束が可能になります。
AI開発の場合: FP4量子化対応により、開発者は互換性のあるモデルで推論スループットを最大2倍に高めながら許容可能な精度を維持する、超効率的なモデルデプロイを試行できます。
先進的なAI機能の活用
RTX 5090は、AIワークロードを特に加速するために設計されたいくつかの画期的なテクノロジーを導入しています。
第5世代Tensorコア は、FP4、FP8、FP16、および従来のフォーマットを含む複数の精度フォーマットをネイティブサポートします。この柔軟性により、開発者は特定のユースケースに必要な精度を維持しながら、最大スループットのためにモデルを最適化できます。
強化されたメモリアーキテクチャ(GDDR7テクノロジー)は、大規模モデルの推論に不可欠な持続的な高帯域幅を提供します。メモリバウンドの操作がデプロイシナリオの主要なボトルネックになることが多いためです。
Blackwellアーキテクチャの最適化 には、専用のニューラル処理ユニットと改善されたスケジューリングが含まれており、トランスフォーマーベースのモデル、コンピュータビジョンネットワーク、生成AIアプリケーションを大幅に高速化できます。
本番AIワークロードにおけるRTX 5090
RTX 5090は優れた生のパフォーマンスを提供しますが、本番AI環境でその可能性を最大限に引き出すには、注意深い最適化と適切なデプロイインフラが必要です。
モデルパフォーマンスの最適化
RTX 5090のアーキテクチャは、現代のAIワークロードを加速するために特別に設計されています。その第5世代Tensorコアは、新しいFP4を含む複数の精度フォーマットをサポートしており、開発者は許容可能な精度を維持しながら最大スループットのためにモデルを最適化できます。
推論ワークロードの場合、RTX 5090の32GBメモリ容量により、従来は高価なマルチGPU構成を必要としていた多くのボトルネックが解消されます。大規模言語モデル、コンピュータビジョンネットワーク、生成AIモデルは、かつてデータセンターのハードウェアを必要としていましたが、1枚のRTX 5090で効率的に実行できます。
AIモデルデプロイシナリオ
| ユースケース | 対応モデルサイズ | 主な利点 |
|---|---|---|
| 大規模言語モデル | 最大70Bパラメータ | 自然言語処理、対話型AI |
| コンピュータビジョン | 高解像度モデル | 物体検出、画像セグメンテーション、医用画像 |
| 生成AI | 複雑なアーキテクチャ | 画像生成、テキスト合成、マルチモーダルアプリケーション |
| 機械学習トレーニング | 大規模データセット | ニューラルネットワークトレーニング、モデルファインチューニング |
エンタープライズデプロイの考慮事項
デスクトップ設置ではRTX 5090の大きな消費電力(575W)と冷却要件を管理する必要がありますが、Novita AIでのクラウドデプロイはこれらのインフラ課題を抽象化します。データセンターのレベルで電源と冷却が処理されるため、開発者はハードウェア管理ではなくAIモデルの最適化に集中できます。
Novita AIをRTX 5090アクセスに選ぶ理由
Novita AIは、比類のない価値と柔軟性を提供し、RTX 5090のパフォーマンスにアクセスするための最高のプラットフォームとして際立っています。
1. 大幅な価格アドバンテージと柔軟な料金モデル
| プロバイダー | RTX 5090 時間単価 | Novita AIでの節約額 |
|---|---|---|
| Novita AI | $0.50/時間 | - |
| RunPod | $0.79/時間 | 37%節約 |
柔軟な料金オプション:
- オンデマンド: 時間単位の支払いで契約不要。実験や変動するワークロードに最適です。
- サブスクリプション: 年間サブスクリプションで数百ドルを節約しながら、リソースの保証と優先アクセスを確保できます。
2. Novita AIで利用可能な高性能GPU
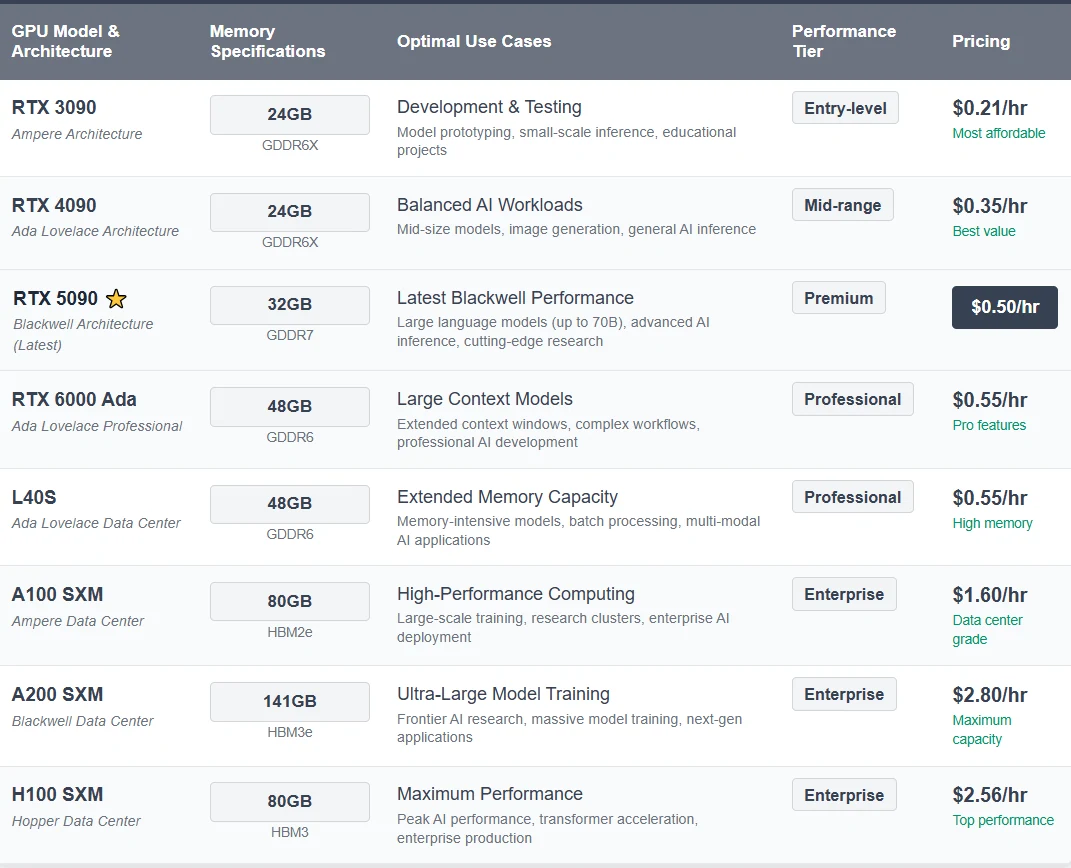
3. すぐに使えるテンプレートとカスタムの柔軟性
事前設定済みテンプレート は、人気モデル向けに最適化された構成(テスト済みのデプロイパラメータ、環境変数、コンテナ構成を含む)により、手動セットアップの複雑さを排除します。DeepSeek、Llamaなどの主要なAIフレームワークで即座に始められます。
カスタムテンプレートサポート は、上級ユーザーにデプロイ環境の完全な制御を提供します。パーソナライズされたデプロイスクリプト、カスタムソフトウェアスタック、調整された最適化設定で特別な構成を作成できます。
4. グローバルデプロイネットワーク
Novita AIの世界規模のインフラは、複数の大陸にまたがる 18ゾーン をカバーし、包括的なグローバルカバレッジを提供します。
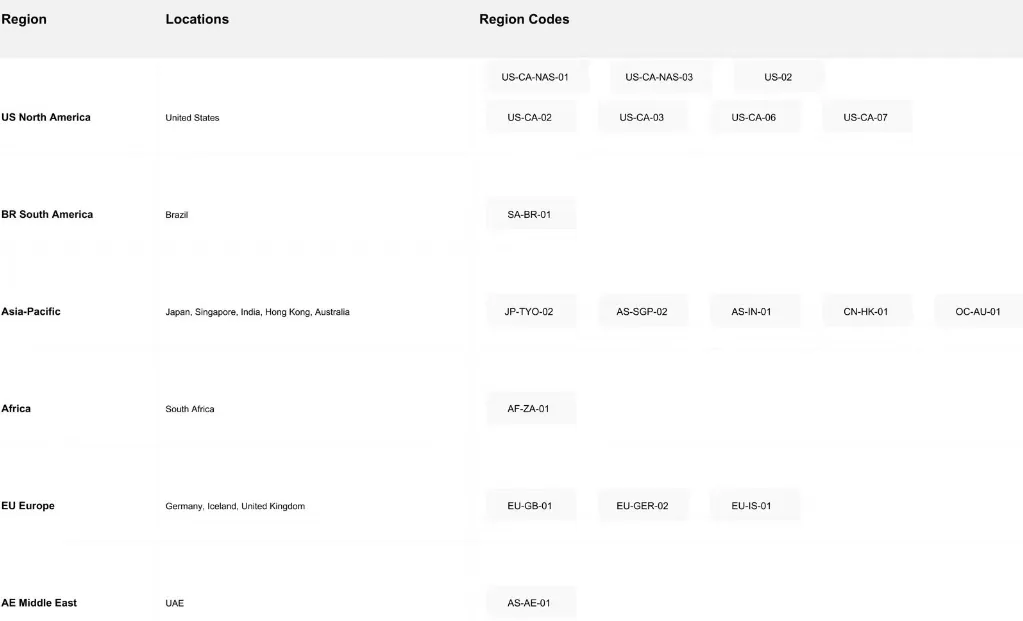
ネットワークの利点:
- 低レイテンシ: エンドユーザーに近い場所にデプロイして最適なパフォーマンスを実現
- 信頼性の高いアクセス: 複数のリージョンが冗長性と可用性を保証
- コンプライアンスサポート: リージョナルデプロイがデータ主権要件を満たすのに役立つ
- スケーラブルなインフラ: ワークロードをリージョン間で分散して最大のパフォーマンスを実現
グローバルなユーザーにサービスを提供する場合でも、リージョナルなデータ要件に準拠する必要がある場合でも、Novita AIの広範なネットワークは現代のAIアプリケーションに不可欠な地理的柔軟性を提供します。
Novita AIで今すぐRTX 5090 GPUを使い始める
Novita AIは、業界をリードする価格とパフォーマンスで RTX 5090 GPU への即時アクセスを提供します。最先端のハードウェア、柔軟な価格設定、グローバルインフラの組み合わせにより、Novita AIはRTX 5090のパフォーマンスを活用するための理想的なプラットフォームです。
Novita AIのクラウドGPUによる即時の利点
| 利点 | メリット |
|---|---|
| インフラ抽象化 | ハードウェア管理不要 – エンタープライズグレードのGPUインフラに即時アクセス |
| スケーラブルなパフォーマンス | 1つのGPUから始め、必要に応じてリージョン間で複数のインスタンスにスケール |
| エンタープライズグレードの信頼性 | 冗長電源、冷却、ネットワークを備えたデータセンターインフラ |
| コスト効率 | 時間単位の課金と競争力のある料金で、使用した分だけ支払い |
大規模言語モデルの推論、コンピュータビジョンアプリケーションの開発、生成AIモデルのトレーニング、機械学習研究の実施など、Novita AI上のRTX 5090は、使用量に応じてスケールする価格帯で必要なパフォーマンスを提供します。
RTX 5090インスタンス は、Novita AIで現在利用可能です。プラットフォームにアクセスして最初のインスタンスを起動し、GPUコンピューティングの未来を体験してください。
よくある質問
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるとともに、手頃で信頼性の高いGPUクラウドを構築・スケールのために提供するAIクラウドプラットフォームです。
おすすめの記事



