

A NVIDIA GeForce RTX 5090, alimentada pela revolucionária arquitetura Blackwell, estabelece um novo padrão para computação de IA com 32 GB de memória GDDR7 e 21.760 núcleos CUDA. À medida que os modelos de IA se tornam cada vez mais complexos, o acesso a uma infraestrutura de GPU de ponta tornou-se essencial para desenvolvedores e pesquisadores.
A Novita AI agora oferece GPUs RTX 5090 sob demanda por US$ 0,50/hora – 37% a menos que o RunPod a US$ 0,79/hora. Este valor excepcional torna a GPU consumidora mais potente do mundo acessível para inferência, treinamento e desenvolvimento de IA, sem a necessidade de investimento inicial em hardware.
Ganhos de desempenho com as RTX 5090

Fonte: Nvidia
As GPUs RTX 5090 são baseadas na mais recente arquitetura Blackwell da NVIDIA e representam um salto significativo em relação às gerações anteriores. A NVIDIA afirma que a RTX 5090 oferece até 2× o desempenho da RTX 4090 em determinados cenários, tornando-a uma escolha ideal para inferência de IA exigente, treinamento de aprendizado de máquina e pesquisa em aprendizado profundo.
Antes da RTX 5090, os desenvolvedores que trabalhavam com grandes modelos de IA enfrentavam difíceis trocas entre desempenho e custo. Eles podiam usar GPUs caras de data center, como a H100, ou se contentar com placas de consumo de menor desempenho que lutavam com cargas de trabalho com uso intensivo de memória. Agora, com as RTX 5090 disponíveis na Novita AI, os desenvolvedores têm acesso a um desempenho próximo ao de data center pelo preço de uma GPU consumidora.
Os 32 GB de memória GDDR7 da RTX 5090 são particularmente transformadores para cargas de trabalho de IA. Muitos modelos populares que anteriormente exigiam placas caras de 40 GB+ ou configurações multi-GPU agora podem ser executados eficientemente em uma única RTX 5090, incluindo grandes modelos de transformadores e arquiteturas complexas de redes neurais.
Comparando especificações de hardware: RTX 5090 vs RTX 4090
As vantagens da RTX 5090 tornam-se claras quando comparadas diretamente com sua antecessora. Aqui está uma análise abrangente de como a RTX 5090 supera a RTX 4090 em todas as especificações principais:
| Especificação | RTX 5090 | RTX 4090 | Melhoria |
|---|---|---|---|
| Arquitetura NVIDIA | Blackwell | Ada Lovelace | Salto de geração completo |
| AI TOPS | 3352 | 1321 | 2,5× mais potência de IA |
| Tensor Cores | 5ª Geração | 4ª Geração | Suporte a quantização FP4 |
| Configuração de Memória | 32 GB GDDR7 | 24 GB GDDR6X | 33% mais VRAM |
| Largura de Banda de Memória | 1792 GB/s | 1008 GB/s | 78% maior largura de banda |
| Núcleos CUDA | 21.760 | 16.384 | 33% mais núcleos |
| Clock de Boost | 2,41 GHz | 2,52 GHz | Otimizado para eficiência |
Essas especificações se traduzem em vantagens significativas de desempenho para cargas de trabalho de IA:
Para inferência de IA: O aumento de 2,5× em AI TOPS combinado com 33% mais VRAM significa que modelos de linguagem maiores podem ser executados com tamanhos de lote melhorados e velocidades de inferência mais rápidas. Modelos que anteriormente exigiam sharding em várias GPUs agora cabem confortavelmente nos 32 GB de uma única RTX 5090.
Para treinamento de IA: A largura de banda de memória aprimorada (melhoria de 78%) acelera os cálculos de gradiente e as atualizações de parâmetros durante o treinamento, enquanto o VRAM adicional permite tamanhos de lote maiores, levando a um treinamento mais estável e convergência mais rápida.
Para desenvolvimento de IA: O suporte à quantização FP4 permite que os desenvolvedores experimentem implantações de modelos ultraeficientes, potencialmente dobrando o throughput de inferência para modelos compatíveis, mantendo níveis de precisão aceitáveis.
Aproveitando recursos avançados de IA
A RTX 5090 introduz várias tecnologias inovadoras projetadas especificamente para acelerar cargas de trabalho de IA:
Tensor Cores de 5ª Geração fornecem suporte nativo a múltiplos formatos de precisão, incluindo FP4, FP8, FP16 e formatos tradicionais. Essa flexibilidade permite que os desenvolvedores otimizem modelos para throughput máximo, mantendo os requisitos de precisão de seus casos de uso específicos.
Arquitetura de Memória Aprimorada com tecnologia GDDR7 oferece alta largura de banda sustentada, essencial para inferência de modelos grandes, onde operações limitadas pela memória frequentemente se tornam o principal gargalo em cenários de implantação.
Otimizações da Arquitetura Blackwell incluem unidades de processamento neural dedicadas e escalonamento aprimorado que podem acelerar significativamente modelos baseados em transformadores, redes de visão computacional e aplicações de IA generativa.
RTX 5090 em cargas de trabalho de IA em produção
Embora a RTX 5090 ofereça desempenho bruto excepcional, maximizar seu potencial em ambientes de IA de produção requer otimização cuidadosa e a infraestrutura de implantação certa.
Otimização de desempenho de modelos
A arquitetura da RTX 5090 é projetada especificamente para acelerar cargas de trabalho modernas de IA. Seus Tensor Cores de 5ª geração suportam múltiplos formatos de precisão, incluindo o novo FP4, permitindo que os desenvolvedores otimizem modelos para throughput máximo, mantendo níveis de precisão aceitáveis.
Para cargas de trabalho de inferência, os 32 GB de capacidade de memória da RTX 5090 eliminam muitos gargalos que anteriormente exigiam configurações multi-GPU caras. Modelos de linguagem grandes, redes de visão computacional e modelos de IA generativa que antes exigiam hardware de data center agora podem ser executados eficientemente em uma única RTX 5090.
Cenários de implantação de modelos de IA
| Caso de Uso | Suporte a Tamanho de Modelo | Principais Benefícios |
|---|---|---|
| Modelos de Linguagem Grandes | Até 70B parâmetros | Processamento de linguagem natural, IA conversacional |
| Visão Computacional | Modelos de alta resolução | Detecção de objetos, segmentação de imagens, imagem médica |
| IA Generativa | Arquiteturas complexas | Geração de imagens, síntese de texto, aplicações multimodais |
| Treinamento de Aprendizado de Máquina | Grandes conjuntos de dados | Treinamento de redes neurais, fine-tuning de modelos |
Considerações para implantação empresarial
Ao contrário de instalações desktop que precisam gerenciar os requisitos substanciais de energia e refrigeração da RTX 5090, a implantação em nuvem na Novita AI abstrai esses desafios de infraestrutura. O consumo de 575 W e os requisitos avançados de resfriamento são tratados no nível do data center, permitindo que os desenvolvedores se concentrem em otimizar seus modelos de IA em vez do gerenciamento de hardware.
Por que escolher a Novita AI para acesso à RTX 5090
A Novita AI se destaca como a plataforma principal para acessar o desempenho da RTX 5090, oferecendo valor e flexibilidade incomparáveis para desenvolvedores, pesquisadores e empresas de IA.
1. Vantagem Significativa de Preço e Modelos de Precificação Flexíveis
| Provedor | Taxa Horária RTX 5090 | Economia com Novita AI |
|---|---|---|
| Novita AI | US$ 0,50/hora | - |
| RunPod | US$ 0,79/hora | Economia de 37% |
Opções de Precificação Flexíveis:
- Sob Demanda: Pague por hora sem compromissos, perfeito para experimentação e cargas de trabalho variáveis
- Assinatura: Assinaturas anuais podem economizar centenas de dólares, garantindo disponibilidade garantida de recursos e acesso prioritário
2. GPUs de Alto Desempenho Disponíveis na Novita AI
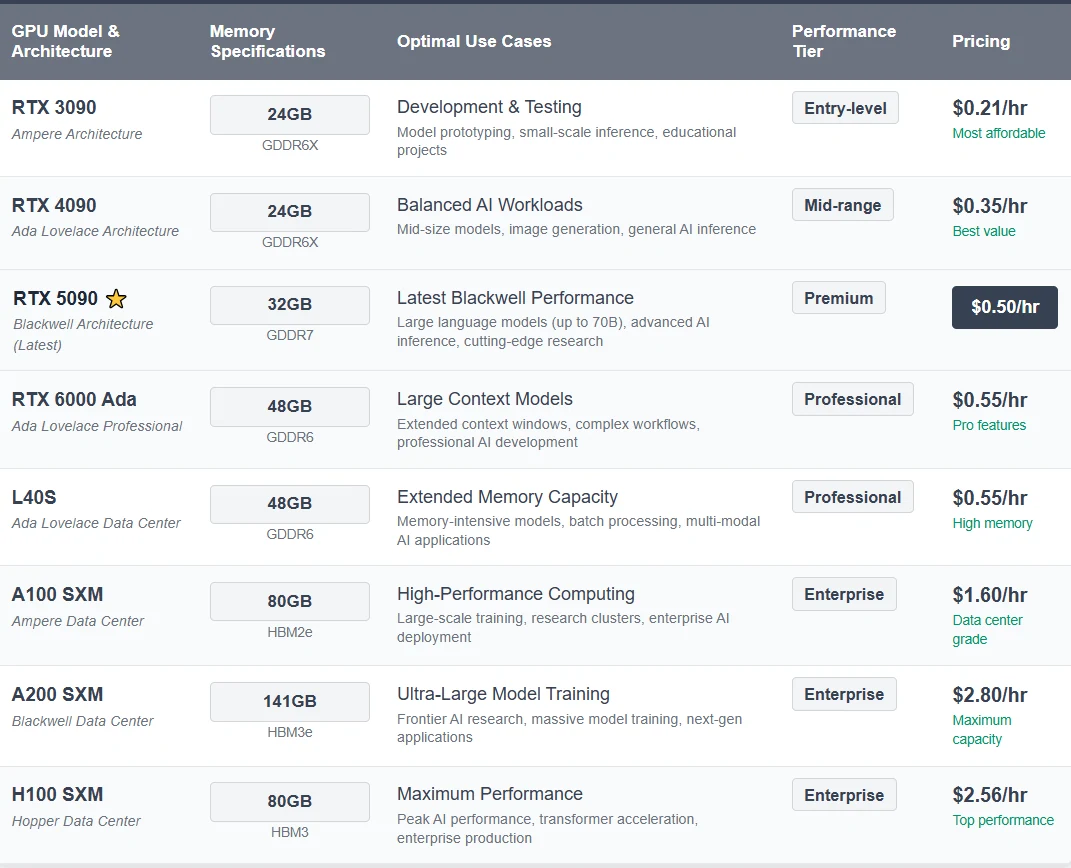
3. Modelos Prontos para Uso e Flexibilidade Personalizada
Modelos Pré-configurados eliminam a complexidade da configuração manual com otimizações para modelos populares, incluindo parâmetros de implantação testados, variáveis de ambiente e configurações de contêiner. Comece instantaneamente com modelos como DeepSeek, Llama e outros frameworks de IA líderes.
Suporte a Modelos Personalizados fornece a usuários avançados controle total sobre seu ambiente de implantação. Crie configurações especializadas com scripts de implantação personalizados, stacks de software customizados e configurações de otimização adaptadas.
4. Rede Global de Implantação
A infraestrutura mundial da Novita AI abrange 18 zonas em múltiplos continentes, fornecendo cobertura global abrangente:
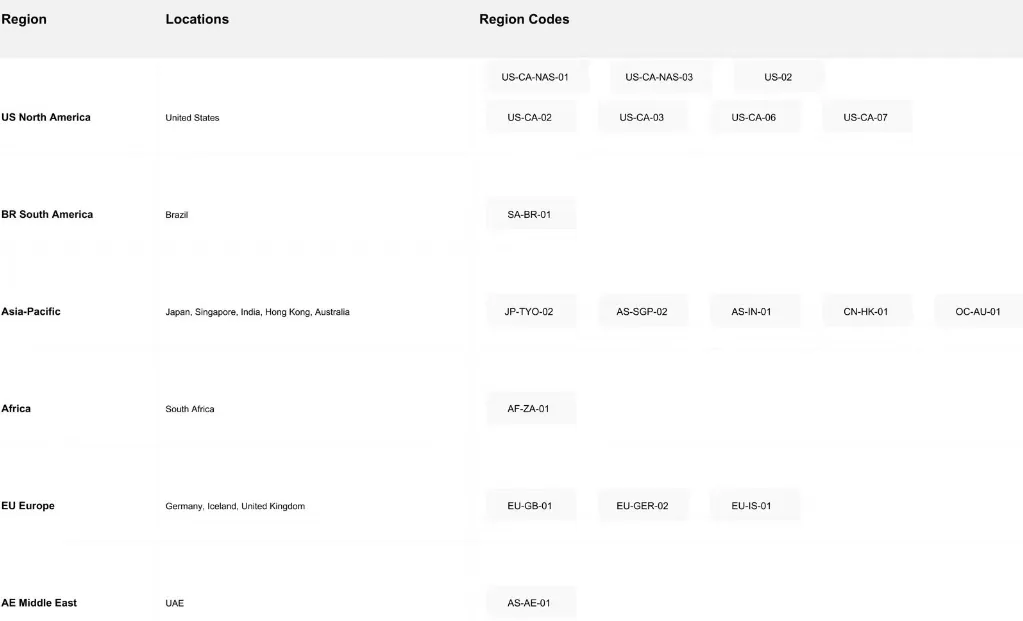
Vantagens da Rede:
- Latência Reduzida: Implante mais próximo de seus usuários finais para desempenho ideal
- Acesso Confiável: Múltiplas regiões fornecem redundância e garantias de disponibilidade
- Suporte a Conformidade: Implantações regionais ajudam a atender requisitos de soberania de dados
- Infraestrutura Escalável: Distribua cargas de trabalho entre regiões para desempenho máximo
Seja atendendo audiências globais ou precisando cumprir requisitos regionais de dados, a extensa rede da Novita AI fornece a flexibilidade geográfica essencial para aplicações modernas de IA.
Comece hoje com GPUs RTX 5090 na Novita AI
A Novita AI fornece acesso instantâneo a GPUs RTX 5090 com preços líderes do setor e desempenho. A combinação de hardware de ponta, preços flexíveis e infraestrutura global torna a Novita AI a plataforma ideal para aproveitar o desempenho da RTX 5090.
Vantagens imediatas com GPU em Nuvem na Novita AI
| Vantagem | Benefício |
|---|---|
| Abstração de Infraestrutura | Sem gerenciamento de hardware – acesso instantâneo a infraestrutura GPU de nível empresarial |
| Desempenho Escalável | Comece com uma GPU, escale para múltiplas instâncias entre regiões conforme necessário |
| Confiabilidade Empresarial | Infraestrutura de data center com energia, resfriamento e rede redundantes |
| Eficiência de Custos | Pague apenas pelo que usar com faturamento por hora e taxas competitivas |
Seja executando inferência em modelos de linguagem grandes, desenvolvendo aplicações de visão computacional, treinando modelos de IA generativa ou conduzindo pesquisa em aprendizado de máquina, a RTX 5090 na Novita AI oferece o desempenho que você precisa a um preço que escala com seu uso.
Instâncias RTX 5090 já estão disponíveis na Novita AI. Visite nossa plataforma para lançar sua primeira instância e experimentar o futuro da computação GPU.
Perguntas Frequentes
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU acessível e confiável para construir e escalar.
Leitura Recomendada



