

Le GeForce RTX 5090 de NVIDIA, propulsé par l’architecture révolutionnaire Blackwell, établit une nouvelle norme pour le calcul IA avec 32 Go de mémoire GDDR7 et 21 760 cœurs CUDA. Alors que les modèles d’IA deviennent de plus en plus complexes, l’accès à une infrastructure GPU de pointe est devenu essentiel pour les développeurs et les chercheurs.
Novita AI propose désormais des GPU RTX 5090 à la demande à 0,50 $/heure – soit 37 % de moins que RunPod à 0,79 $/heure. Cette valeur exceptionnelle rend le GPU grand public le plus puissant du monde accessible pour l’inférence IA, l’entraînement et le développement, sans l’investissement matériel initial.
Gains de performance avec les RTX 5090

Source : Nvidia
Les GPU RTX 5090 sont basés sur la dernière architecture Blackwell de NVIDIA et représentent un bond en avant significatif par rapport aux générations précédentes. NVIDIA affirme que le RTX 5090 offre jusqu’à 2× les performances du RTX 4090 dans certains scénarios, ce qui en fait un choix idéal pour l’inférence IA exigeante, l’entraînement en apprentissage automatique et la recherche en apprentissage profond.
Avant le RTX 5090, les développeurs travaillant avec de grands modèles d’IA devaient faire face à des compromis difficiles entre performance et coût. Ils pouvaient utiliser des GPU de centre de données coûteux comme le H100, ou se contenter de cartes grand public aux performances inférieures qui peinaient avec les charges de travail gourmandes en mémoire. Maintenant, avec les RTX 5090 disponibles sur Novita AI, les développeurs ont accès à des performances proches de celles des centres de données au prix des GPU grand public.
La mémoire de 32 Go GDDR7 du RTX 5090 est particulièrement transformatrice pour les charges de travail IA. De nombreux modèles populaires qui nécessitaient auparavant des cartes coûteuses de 40 Go+ ou des configurations multi-GPU peuvent désormais fonctionner efficacement sur un seul RTX 5090, y compris les grands modèles de transformeurs et les architectures de réseaux neuronaux complexes.
Comparaison des spécifications matérielles : RTX 5090 vs RTX 4090
Les avantages du RTX 5090 deviennent évidents lorsqu’on le compare directement à son prédécesseur. Voici une analyse complète de la façon dont le RTX 5090 surpasse le RTX 4090 dans toutes les spécifications clés :
| Spécification | RTX 5090 | RTX 4090 | Amélioration |
|---|---|---|---|
| Architecture NVIDIA | Blackwell | Ada Lovelace | Saut de génération complet |
| AI TOPS | 3352 | 1321 | 2,5× plus de puissance IA |
| Tensor Cores | 5e génération | 4e génération | Prise en charge de la quantification FP4 |
| Configuration mémoire | 32 Go GDDR7 | 24 Go GDDR6X | 33 % de VRAM en plus |
| Bande passante mémoire | 1792 Go/s | 1008 Go/s | 78 % de bande passante en plus |
| Cœurs CUDA | 21 760 | 16 384 | 33 % de cœurs en plus |
| Fréquence boost | 2,41 GHz | 2,52 GHz | Optimisé pour l’efficacité |
Ces spécifications se traduisent par des avantages de performance significatifs pour les charges de travail IA :
Pour l’inférence IA : L’augmentation de 2,5× des AI TOPS combinée à 33 % de VRAM supplémentaire signifie que les grands modèles de langage peuvent fonctionner avec des tailles de lots améliorées et des vitesses d’inférence plus rapides. Les modèles qui nécessitaient auparavant un partitionnement sur plusieurs GPU peuvent désormais tenir confortablement dans la mémoire de 32 Go d’un seul RTX 5090.
Pour l’entraînement IA : La bande passante mémoire améliorée (78 % d’amélioration) accélère les calculs de gradient et les mises à jour des paramètres lors de l’entraînement, tandis que la VRAM supplémentaire permet des tailles de lots plus grandes, conduisant à un entraînement plus stable et à une convergence plus rapide.
Pour le développement IA : La prise en charge de la quantification FP4 permet aux développeurs d’expérimenter des déploiements de modèles ultra-efficaces, doublant potentiellement le débit d’inférence pour les modèles compatibles tout en maintenant des niveaux de précision acceptables.
Exploiter les fonctionnalités IA avancées
Le RTX 5090 introduit plusieurs technologies révolutionnaires spécialement conçues pour accélérer les charges de travail IA :
Les Tensor Cores de 5e génération offrent une prise en charge native de plusieurs formats de précision, notamment FP4, FP8, FP16 et les formats traditionnels. Cette flexibilité permet aux développeurs d’optimiser les modèles pour un débit maximal tout en respectant les exigences de précision de leurs cas d’utilisation spécifiques.
L’architecture mémoire améliorée avec la technologie GDDR7 offre une bande passante élevée soutenue, essentielle pour l’inférence de grands modèles, où les opérations liées à la mémoire deviennent souvent le principal goulot d’étranglement dans les scénarios de déploiement.
Les optimisations de l’architecture Blackwell incluent des unités de traitement neuronal dédiées et une planification améliorée qui peuvent accélérer considérablement les modèles basés sur les transformeurs, les réseaux de vision par ordinateur et les applications d’IA générative.
RTX 5090 dans les charges de travail IA de production
Bien que le RTX 5090 offre des performances brutes exceptionnelles, maximiser son potentiel dans les environnements IA de production nécessite une optimisation minutieuse et une infrastructure de déploiement adaptée.
Optimisation des performances des modèles
L’architecture du RTX 5090 est spécialement conçue pour accélérer les charges de travail IA modernes. Ses Tensor Cores de 5e génération prennent en charge plusieurs formats de précision, dont le nouveau FP4, permettant aux développeurs d’optimiser les modèles pour un débit maximal tout en maintenant des niveaux de précision acceptables.
Pour les charges de travail d’inférence, la capacité mémoire de 32 Go du RTX 5090 élimine de nombreux goulots d’étranglement qui nécessitaient auparavant des configurations multi-GPU coûteuses. Les grands modèles de langage, les réseaux de vision par ordinateur et les modèles d’IA générative qui exigeaient autrefois du matériel de centre de données peuvent désormais fonctionner efficacement sur un seul RTX 5090.
Scénarios de déploiement de modèles IA
| Cas d’utilisation | Taille de modèle prise en charge | Avantages clés |
|---|---|---|
| Grands modèles de langage | Jusqu’à 70 milliards de paramètres | Traitement du langage naturel, IA conversationnelle |
| Vision par ordinateur | Modèles haute résolution | Détection d’objets, segmentation d’image, imagerie médicale |
| IA générative | Architectures complexes | Génération d’images, synthèse de texte, applications multimodales |
| Entraînement en apprentissage automatique | Grands ensembles de données | Entraînement de réseaux neuronaux, réglage fin de modèles |
Considérations pour le déploiement en entreprise
Contrairement aux installations de bureau qui doivent gérer les besoins énergétiques importants et les exigences de refroidissement du RTX 5090, le déploiement cloud sur Novita AI abstrait ces défis d’infrastructure. La consommation électrique de 575 W et les exigences de refroidissement avancées sont gérées au niveau du centre de données, permettant aux développeurs de se concentrer sur l’optimisation de leurs modèles IA plutôt que sur la gestion du matériel.
Pourquoi choisir Novita AI pour l’accès au RTX 5090
Novita AI se distingue comme la plateforme de premier plan pour accéder aux performances du RTX 5090, offrant une valeur et une flexibilité inégalées pour les développeurs IA, les chercheurs et les entreprises.
1. Avantage de prix significatif et modèles de tarification flexibles
| Fournisseur | Tarif horaire RTX 5090 | Économies avec Novita AI |
|---|---|---|
| Novita AI | 0,50 $/heure | - |
| RunPod | 0,79 $/heure | 37 % d’économies |
Options de tarification flexibles :
- À la demande : Paiement à l’heure sans engagement, idéal pour l’expérimentation et les charges de travail variables
- Abonnement : Les abonnements annuels peuvent vous faire économiser des centaines de dollars tout en garantissant une disponibilité des ressources et un accès prioritaire
2. GPU haute performance disponibles sur Novita AI
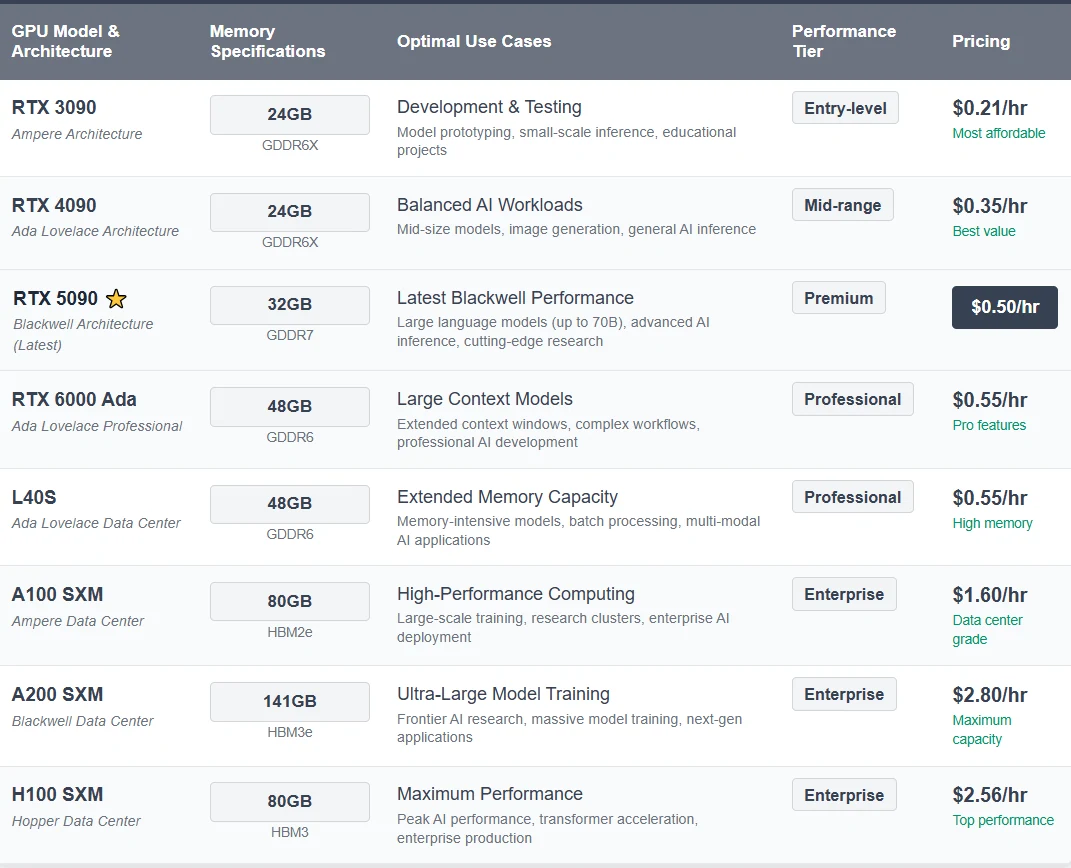
3. Modèles prêts à l’emploi et flexibilité personnalisée
Les modèles préconfigurés éliminent la complexité de la configuration manuelle avec des configurations optimisées pour les modèles populaires, y compris les paramètres de déploiement testés, les variables d’environnement et les configurations de conteneurs. Commencez instantanément avec des modèles comme DeepSeek, Llama et d’autres frameworks IA de premier plan.
Prise en charge des modèles personnalisés offre aux utilisateurs avancés un contrôle total sur leur environnement de déploiement. Créez des configurations spécialisées avec des scripts de déploiement personnalisés, des piles logicielles sur mesure et des paramètres d’optimisation adaptés.
4. Réseau de déploiement mondial
L’infrastructure mondiale de Novita AI couvre 18 zones sur plusieurs continents, offrant une couverture globale complète :
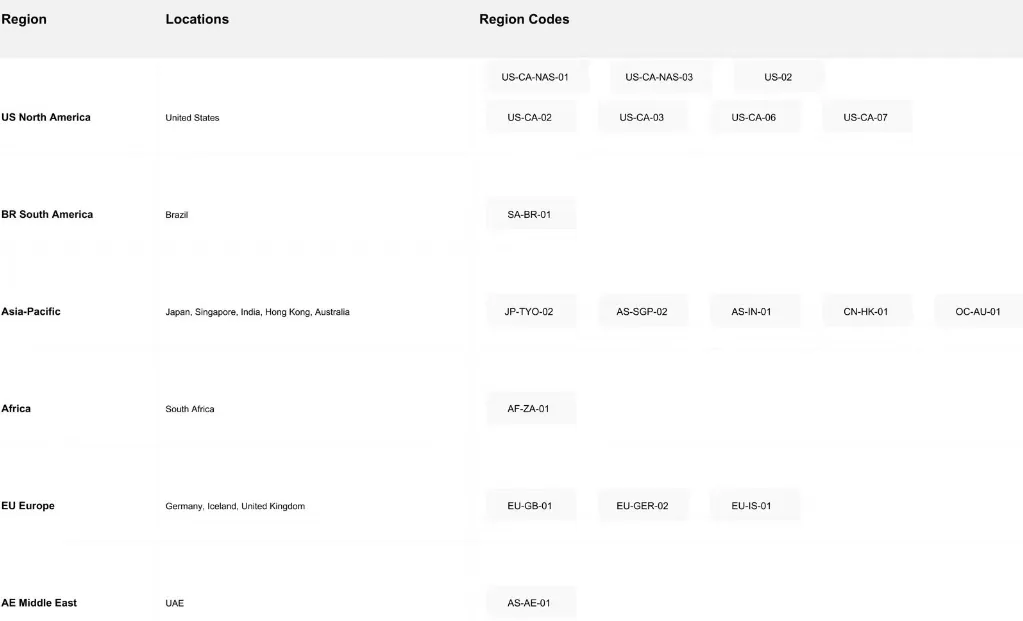
Avantages réseau :
- Latence réduite : Déployez plus près de vos utilisateurs finaux pour des performances optimales
- Accès fiable : Plusieurs régions offrent redondance et garanties de disponibilité
- Support de conformité : Les déploiements régionaux aident à respecter les exigences de souveraineté des données
- Infrastructure évolutive : Répartissez les charges de travail entre les régions pour des performances maximales
Que vous serviez des publics mondiaux ou que vous deviez vous conformer aux exigences régionales en matière de données, le vaste réseau de Novita AI offre la flexibilité géographique essentielle pour les applications IA modernes.
Commencez avec les GPU RTX 5090 dès aujourd’hui sur Novita AI
Novita AI fournit un accès instantané aux GPU RTX 5090 avec des prix et des performances de premier plan. La combinaison de matériel de pointe, de tarification flexible et d’infrastructure mondiale fait de Novita AI la plateforme idéale pour exploiter les performances du RTX 5090.
Avantages immédiats avec le GPU Cloud sur Novita AI
| Avantage | Bénéfice |
|---|---|
| Abstraction de l’infrastructure | Aucune gestion matérielle – accès instantané à une infrastructure GPU de niveau entreprise |
| Performances évolutives | Commencez avec un GPU, passez à plusieurs instances dans toutes les régions selon les besoins |
| Fiabilité de niveau entreprise | Infrastructure de centre de données avec alimentation, refroidissement et réseau redondants |
| Efficacité des coûts | Payez uniquement pour ce que vous utilisez avec une facturation horaire et des tarifs compétitifs |
Que vous exécutiez des inférences sur de grands modèles de langage, développiez des applications de vision par ordinateur, entraîniez des modèles d’IA générative ou meniez des recherches en apprentissage automatique, le RTX 5090 sur Novita AI offre les performances dont vous avez besoin à un prix qui évolue avec votre utilisation.
Les instances RTX 5090 sont disponibles dès maintenant sur Novita AI. Visitez notre plateforme pour lancer votre première instance et découvrir l’avenir du calcul GPU.
Questions fréquentes
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour la construction et le passage à l’échelle.
Lectures recommandées



