

NVIDIAs GeForce RTX 5090, angetrieben von der revolutionären Blackwell-Architektur, setzt mit 32 GB GDDR7-Speicher und 21.760 CUDA-Kernen einen neuen Standard für KI-Computing. Da KI-Modelle immer komplexer werden, ist der Zugang zu modernster GPU-Infrastruktur für Entwickler und Forscher unerlässlich.
Novita AI bietet jetzt RTX 5090 GPUs auf Abruf für 0,50 $/Stunde – das sind 37 % weniger als bei RunPod mit 0,79 $/Stunde. Dieser außergewöhnliche Wert macht die leistungsstärkste Verbraucher-GPU der Welt für KI-Inferenz, Training und Entwicklung zugänglich, ohne dass eine Investition in Hardware im Voraus erforderlich ist.
Leistungssteigerungen durch den Einsatz von RTX 5090

Quelle: Nvidia
RTX 5090 GPUs basieren auf NVIDIAs neuester Blackwell-Architektur und stellen einen bedeutenden Sprung gegenüber früheren Generationen dar. NVIDIA gibt an, dass die RTX 5090 in bestimmten Szenarien die doppelte Leistung der RTX 4090 liefert, was sie zu einer idealen Wahl für anspruchsvolle KI-Inferenz, Training im maschinellen Lernen und Deep-Learning-Forschung macht.
Vor der RTX 5090 standen Entwickler, die mit großen KI-Modellen arbeiteten, vor schwierigen Kompromissen zwischen Leistung und Kosten. Sie konnten entweder teure Rechenzentrums-GPUs wie die H100 verwenden oder sich mit günstigeren Verbraucherkarten begnügen, die bei speicherintensiven Workloads an ihre Grenzen stießen. Mit den auf Novita AI verfügbaren RTX 5090 haben Entwickler nun Zugang zu Leistung in der Nähe von Rechenzentren zu Preisen von Verbraucher-GPUs.
Der 32 GB GDDR7-Speicher der RTX 5090 ist besonders transformativ für KI-Workloads. Viele beliebte Modelle, die zuvor teure Karten mit 40 GB+ oder Multi-GPU-Setups erforderten, laufen jetzt effizient auf einer einzigen RTX 5090, darunter große Transformatormodelle und komplexe neuronale Netzwerkarchitekturen.
Vergleich der Hardware-Spezifikationen: RTX 5090 vs. RTX 4090
Die Vorteile der RTX 5090 werden im direkten Vergleich mit ihrem Vorgänger deutlich. Hier eine umfassende Aufschlüsselung, wie die RTX 5090 die RTX 4090 in allen wichtigen Spezifikationen übertrifft:
| Spezifikation | RTX 5090 | RTX 4090 | Verbesserung |
|---|---|---|---|
| NVIDIA-Architektur | Blackwell | Ada Lovelace | Vollständiger Generationssprung |
| AI TOPS | 3352 | 1321 | 2,5× mehr KI-Leistung |
| Tensor Cores | 5. Generation | 4. Generation | FP4-Quantisierungsunterstützung |
| Speicherkonfiguration | 32 GB GDDR7 | 24 GB GDDR6X | 33 % mehr VRAM |
| Speicherbandbreite | 1792 GB/s | 1008 GB/s | 78 % höhere Bandbreite |
| CUDA-Kerne | 21.760 | 16.384 | 33 % mehr Kerne |
| Boost-Takt | 2,41 GHz | 2,52 GHz | Für Effizienz optimiert |
Diese Spezifikationen führen zu erheblichen Leistungsvorteilen für KI-Workloads:
Für KI-Inferenz: Die 2,5-fache Steigerung der AI TOPS in Kombination mit 33 % mehr VRAM bedeutet, dass größere Sprachmodelle mit verbesserten Batch-Größen und schnelleren Inferenzgeschwindigkeiten ausgeführt werden können. Modelle, die zuvor ein Sharding über mehrere GPUs erforderten, passen jetzt bequem in den 32 GB Speicher einer einzigen RTX 5090.
Für KI-Training: Die verbesserte Speicherbandbreite (78 % Steigerung) beschleunigt Gradientenberechnungen und Parameteraktualisierungen während des Trainings, während der zusätzliche VRAM größere Batch-Größen ermöglicht, was zu stabilerem Training und schnellerer Konvergenz führt.
Für KI-Entwicklung: Die FP4-Quantisierungsunterstützung ermöglicht es Entwicklern, mit hocheffizienten Modellbereitstellungen zu experimentieren, wodurch der Inferenzdurchsatz für kompatible Modelle potenziell verdoppelt werden kann, während eine akzeptable Genauigkeit erhalten bleibt.
Fortschrittliche KI-Funktionen nutzen
Die RTX 5090 führt mehrere bahnbrechende Technologien ein, die speziell zur Beschleunigung von KI-Workloads entwickelt wurden:
Tensor Cores der 5. Generation bieten native Unterstützung für mehrere Präzisionsformate, darunter FP4, FP8, FP16 und traditionelle Formate. Diese Flexibilität ermöglicht es Entwicklern, Modelle für maximalen Durchsatz zu optimieren und gleichzeitig die Präzisionsanforderungen ihrer spezifischen Anwendungsfälle zu erfüllen.
Verbesserte Speicherarchitektur mit GDDR7-Technologie liefert eine dauerhaft hohe Bandbreite, die für die Inferenz großer Modelle unerlässlich ist, bei der speichergebundene Operationen oft zum primären Engpass in Bereitstellungsszenarien werden.
Blackwell-Architekturoptimierungen umfassen dedizierte neuronale Verarbeitungseinheiten und verbesserte Planung, die transformatorbasierte Modelle, Computer-Vision-Netzwerke und generative KI-Anwendungen erheblich beschleunigen können.
RTX 5090 in produktiven KI-Workloads
Während die RTX 5090 eine außergewöhnliche Rohleistung liefert, erfordert die Maximierung ihres Potenzials in produktiven KI-Umgebungen eine sorgfältige Optimierung und die richtige Bereitstellungsinfrastruktur.
Modellleistungsoptimierung
Die Architektur der RTX 5090 ist speziell darauf ausgelegt, moderne KI-Workloads zu beschleunigen. Ihre Tensor Cores der 5. Generation unterstützen mehrere Präzisionsformate, einschließlich des neuen FP4, sodass Entwickler Modelle für maximalen Durchsatz optimieren können, während eine akzeptable Genauigkeit erhalten bleibt.
Für Inferenz-Workloads beseitigt der 32 GB große Speicher der RTX 5090 viele Engpässe, die zuvor teure Multi-GPU-Konfigurationen erforderten. Große Sprachmodelle, Computer-Vision-Netzwerke und generative KI-Modelle, die einst Rechenzentrums-Hardware benötigten, können jetzt effizient auf einer einzigen RTX 5090 ausgeführt werden.
KI-Modell-Bereitstellungsszenarien
| Anwendungsfall | Modellgrößenunterstützung | Wichtige Vorteile |
|---|---|---|
| Große Sprachmodelle | Bis zu 70B Parameter | Natürliche Sprachverarbeitung, konversationelle KI |
| Computer Vision | Hochauflösende Modelle | Objekterkennung, Bildsegmentierung, medizinische Bildgebung |
| Generative KI | Komplexe Architekturen | Bildgenerierung, Textsynthese, multimodale Anwendungen |
| Maschinelles Lernen Training | Große Datensätze | Neuronale Netzwerke trainieren, Modell-Feintuning |
Überlegungen zur Unternehmensbereitstellung
Im Gegensatz zu Desktop-Installationen, die den erheblichen Strombedarf und die Kühlungsanforderungen der RTX 5090 verwalten müssen, abstrahiert die Cloud-Bereitstellung auf Novita AI diese Infrastrukturherausforderungen. Die 575 W Leistungsaufnahme und die fortschrittlichen Kühlungsanforderungen werden auf Rechenzentrumsebene gehandhabt, sodass sich Entwickler auf die Optimierung ihrer KI-Modelle konzentrieren können, anstatt auf das Hardware-Management.
Warum Novita AI für den Zugriff auf RTX 5090 wählen?
Novita AI zeichnet sich als die führende Plattform für den Zugriff auf RTX 5090-Leistung aus und bietet unübertroffenen Wert und Flexibilität für KI-Entwickler, Forscher und Unternehmen.
1. Erheblicher Preisvorteil und flexible Preismodelle
| Anbieter | RTX 5090 Stundensatz | Ersparnis mit Novita AI |
|---|---|---|
| Novita AI | 0,50 $/Stunde | - |
| RunPod | 0,79 $/Stunde | 37 % Ersparnis |
Flexible Preisoptionen:
- On-Demand: Bezahlung pro Stunde ohne Verpflichtungen – perfekt für Experimente und variable Workloads
- Abonnement: Jahresabonnements können Ihnen Hunderte von Dollar sparen und gleichzeitig garantierte Ressourcenverfügbarkeit und vorrangigen Zugriff gewährleisten
2. Hochleistungs-GPUs auf Novita AI verfügbar
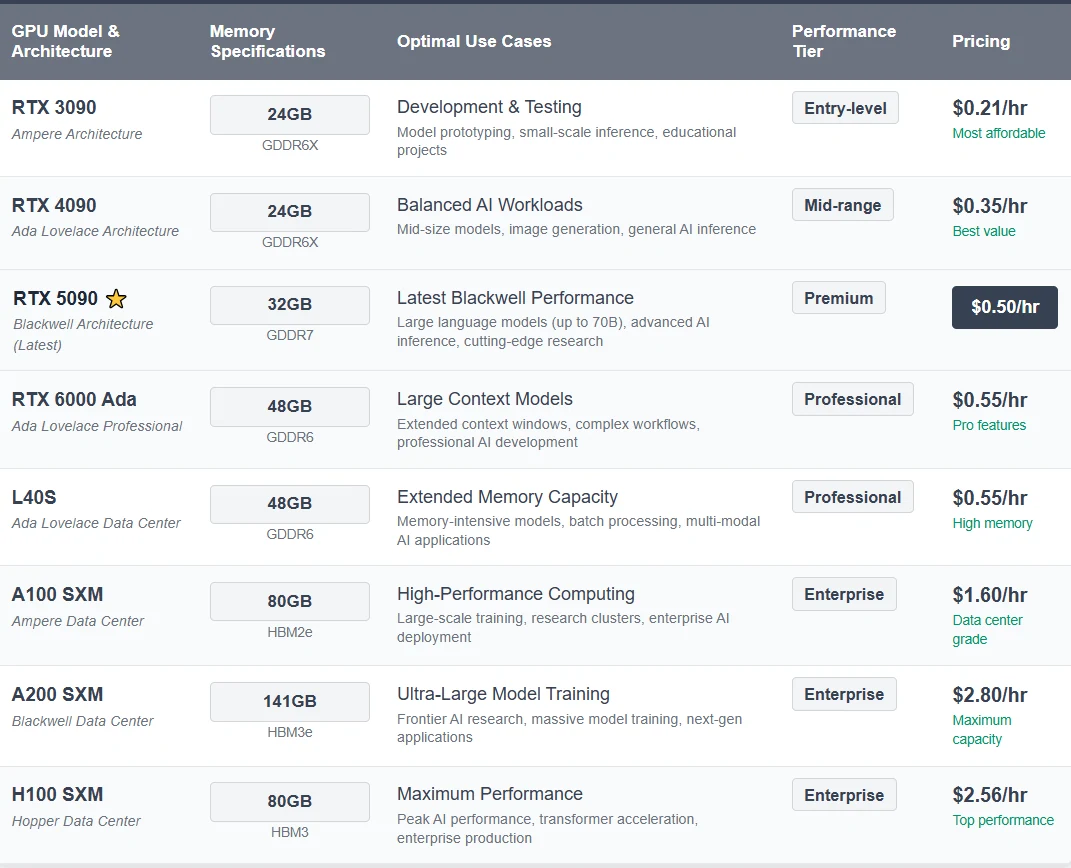
3. Fertig konfigurierte Vorlagen und individuelle Flexibilität
Vorkonfigurierte Vorlagen beseitigen die Komplexität der manuellen Einrichtung mit optimierten Konfigurationen für beliebte Modelle, einschließlich getesteter Bereitstellungsparameter, Umgebungsvariablen und Container-Konfigurationen. Starten Sie sofort mit Modellen wie DeepSeek, Llama und anderen führenden KI-Frameworks.
Unterstützung für benutzerdefinierte Vorlagen gibt fortgeschrittenen Benutzern die vollständige Kontrolle über ihre Bereitstellungsumgebung. Erstellen Sie spezielle Konfigurationen mit personalisierten Bereitstellungsskripten, individuellen Software-Stacks und maßgeschneiderten Optimierungseinstellungen.
4. Globales Bereitstellungsnetzwerk
Novita AIs weltweite Infrastruktur erstreckt sich über 18 Zonen auf mehreren Kontinenten und bietet eine umfassende globale Abdeckung:
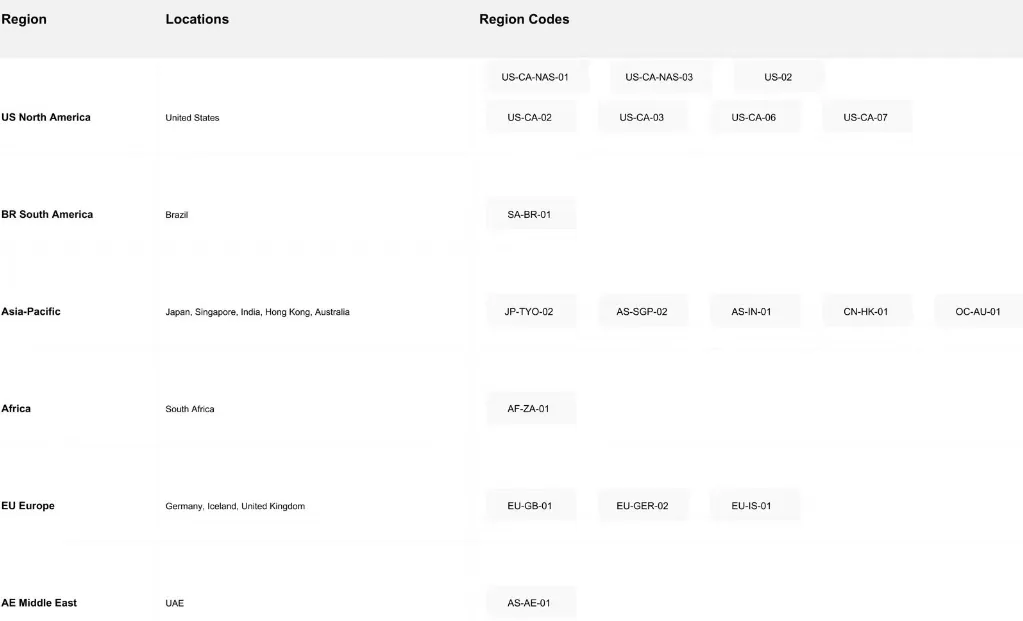
Netzwerkvorteile:
- Reduzierte Latenz: Näher an Ihren Endbenutzern bereitstellen für optimale Leistung
- Zuverlässiger Zugriff: Mehrere Regionen bieten Redundanz und Verfügbarkeitsgarantien
- Compliance-Unterstützung: Regionale Bereitstellungen helfen, Anforderungen an die Datensouveränität zu erfüllen
- Skalierbare Infrastruktur: Workloads auf Regionen verteilen für maximale Leistung
Egal, ob Sie ein globales Publikum bedienen oder regionale Datenanforderungen erfüllen müssen – Novita AIs umfangreiches Netzwerk bietet die geografische Flexibilität, die für moderne KI-Anwendungen unerlässlich ist.
Starten Sie noch heute mit RTX 5090 GPUs auf Novita AI
Novita AI bietet sofortigen Zugang zu RTX 5090 GPUs mit branchenführenden Preisen und Leistung. Die Kombination aus modernster Hardware, flexibler Preisgestaltung und globaler Infrastruktur macht Novita AI zur idealen Plattform, um die Leistung der RTX 5090 zu nutzen.
Sofortige Vorteile mit Cloud GPU auf Novita AI
| Vorteil | Nutzen |
|---|---|
| Infrastrukturabstraktion | Kein Hardware-Management – sofortiger Zugang zu GPU-Infrastruktur auf Unternehmensniveau |
| Skalierbare Leistung | Starten Sie mit einer GPU, skalieren Sie bei Bedarf auf mehrere Instanzen in verschiedenen Regionen |
| Zuverlässigkeit auf Unternehmensniveau | Rechenzentrumsinfrastruktur mit redundanter Stromversorgung, Kühlung und Vernetzung |
| Kosteneffizienz | Zahlen Sie nur, was Sie nutzen, mit stündlicher Abrechnung und wettbewerbsfähigen Preisen |
Ob Sie Inferenz auf großen Sprachmodellen durchführen, Computer-Vision-Anwendungen entwickeln, generative KI-Modelle trainieren oder maschinelles Lernen erforschen – die RTX 5090 auf Novita AI bietet die Leistung, die Sie benötigen, zu einem Preis, der mit Ihrer Nutzung skaliert.
RTX 5090 Instanzen sind jetzt auf Novita AI verfügbar. Besuchen Sie unsere Plattform, um Ihre erste Instanz zu starten und die Zukunft des GPU-Computings zu erleben.
Häufig gestellte Fragen
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig die erschwingliche und zuverlässige GPU-Cloud zum Aufbau und zur Skalierung bereitstellt.
Empfohlene Lektüre



