

Qwen3-VL-235B-A22B 是 Qwen 系列中能力最强的模型之一,拥有 2350 亿参数和先进的多模态推理能力。它在文本理解、视觉感知和长上下文处理方面的突破,使其成为尖端应用的理想选择。然而,这些能力也带来了极高的 VRAM 需求,通常远超标准 GPU 的处理能力。
本文将重点介绍该模型的核心优势,详细说明其实际所需的 VRAM 大小,并探讨在最小化 GPU 部署高成本的同时,充分利用 Qwen3-VL-235B-A22B 全部潜力的实用方法。
什么是 Qwen3-VL-235B-A22B?
“Qwen3-VL-235B-A22B”的含义
- Qwen3: 阿里巴巴 Qwen 大语言模型的第三代。
- VL: 代表 Vision-Language(视觉语言),将更强大的视觉推理与稳健的文本能力相结合。
- 235B: 模型总参数为 2350 亿(“B” = billion)。
- A22B: 每次推理时激活 220 亿参数(MoE 架构的典型特征)。
Qwen3-VL-235B-A22B:基础信息与基准测试
| 特性 | 详情 |
| 模型规模 | 总参数 235B,激活参数 22B |
| 开源 | 是 |
| 上下文长度 | 原生 256K 上下文,可扩展至 1M |
| 架构 | 提供密集型和 MoE 两种版本 |
| 变体 | Instruct / Thinking |
| 语言支持 | 100 多种语言和方言,在英语和中文上表现突出 |
| 多模态 | 融合视觉与语言,涵盖文本、图像、视频、OCR 和空间推理 |
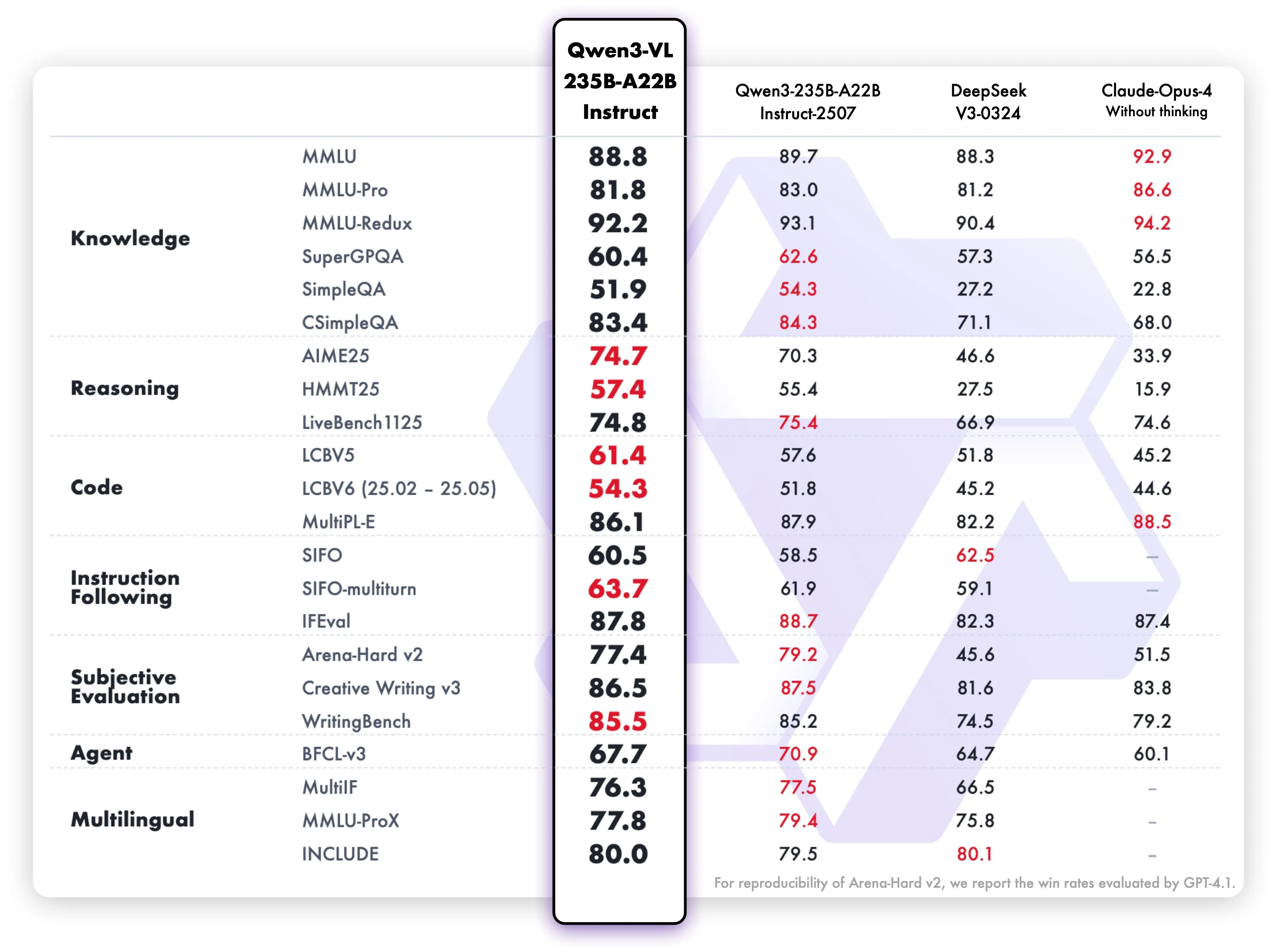
Qwen3-VL-235B-A22-Instruct 基准测试
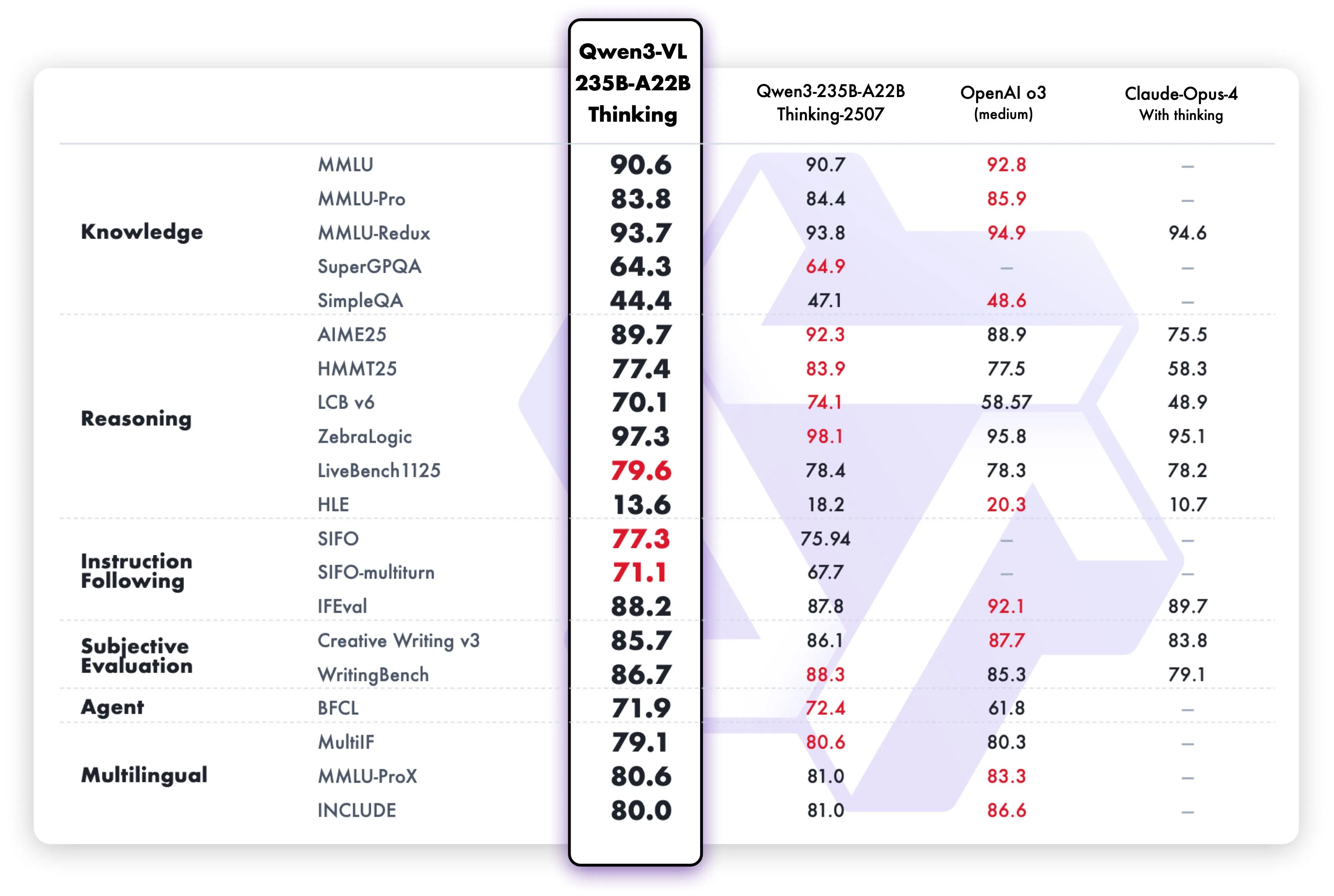
Qwen3-VL-235B-A22-Thinking 基准测试
Qwen3-VL-235B-A22B 的核心亮点
- 更智能的视觉代理:可与 PC 或移动界面交互——识别元素、触发功能并完成多步骤任务。
- 视觉生成代码:将图表、截图或视频转换为可用的代码格式,如 HTML、CSS 和 Draw.io。
- 高级空间感知:理解物体位置、遮挡和视角,实现机器人和具身 AI 所需的 2D 和 3D 推理。
- 扩展上下文处理:原生处理高达 256K 令牌,可扩展至 1M——能够阅读整本书籍或数小时长的视频,并保持精准的召回能力。
- 更深入的多模态推理:在 STEM 和数学任务中表现出色,提供因果分析和结构化的、基于证据的答案。
- 强大的 OCR 与文本解析:即使在模糊、倾斜或弱光条件下,也能识别 32 种语言的文字,并更好地解析长文档。
- 广泛的视觉识别:识别广泛的实体——从真实物体、产品到动漫、地标和生物物种。
- 强大的语言融合:在无缝整合视觉感知的同时,保持与纯大语言模型相当的文本理解能力。
Qwen3-VL-235B-A22B VRAM 和硬件要求
Qwen3-VL-235B-A22B 至少需要 8 张 GPU,每张配备至少 80 GB 内存(如 A100、H100 或 H200)。在某些硬件配置下,模型在默认设置下可能无法成功启动。为确保稳定性能,建议根据硬件类型采用以下方法:
- H200 和 B200 GPU:开箱即可直接运行模型,完全支持长上下文长度以及并发图像和视频处理。
- 采用 FP8 的 H100:使用 FP8 实现最佳内存效率。官方 FP8 版本模型即将发布,将提供更优性能。
- 采用 BF16 的 A100 和 H100:要么减小
--max-model-len参数,要么将推理限制为仅处理图像,以保持稳定性并避免内存过载。
对于希望直接控制并自由选择硬件的用户,Novita AI 提供按需的云 GPU 实例(包括 A100、H100、H200、B200 等)。这些实例允许您根据需要扩展资源,在不增加维护本地基础设施的费用或复杂性的情况下实现高性能部署。无论您是试验新模型、运行大规模训练还是部署高要求应用,Novita AI GPU 云的灵活性都能确保操作流畅、工作流高效。
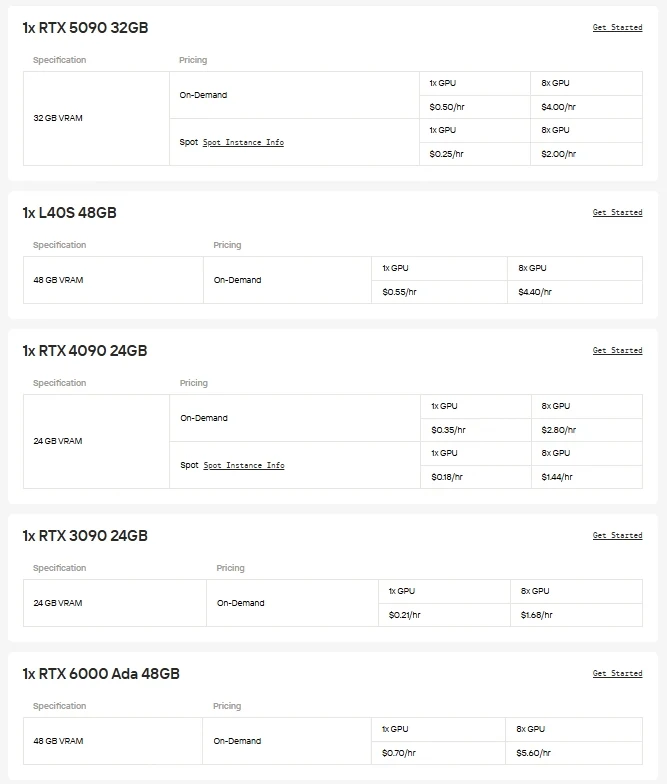
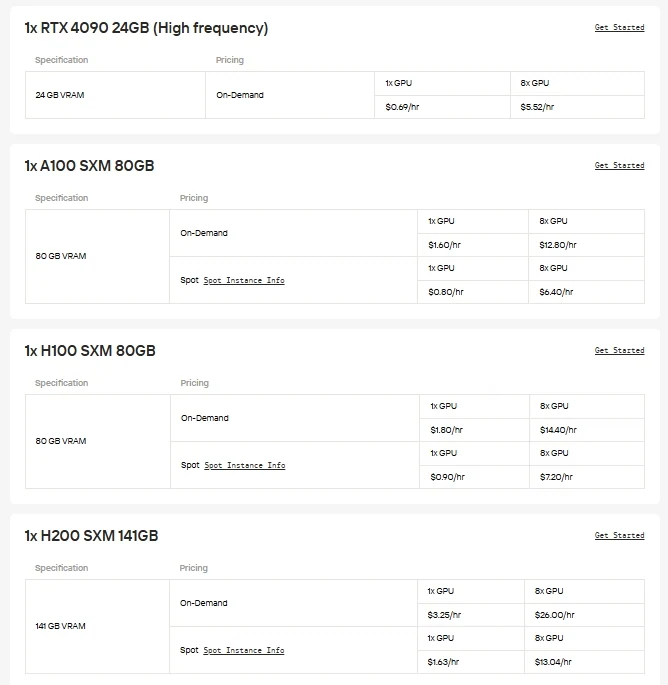
另一种节省成本的选择:API
Novita AI 提供 Qwen3-VL-235B-A22B Instruct API,上下文窗口为 131K,定价为 $0.3/M 输入令牌 和 $1.5/M 输出令牌,为多模态推理和指令跟随任务提供经济高效的接入。对于更高级的场景,还提供 Qwen3-VL-235B-A22B Thinking API,同样具有 131K 上下文窗口,但定价为 $0.3/M 输入令牌 和 $3/M 输出令牌,通过无服务器部署提供更深入的推理和更强的多模态一致性。
| 方面 | API | 本地 GPU | 云 GPU |
|---|---|---|---|
| 设置简便性 | 即时可用 | 硬件密集型,复杂 | 中等,部分托管 |
| 维护 | 不需要 | 持续投入较大 | 中等 |
| 可扩展性 | 弹性且自动 | 难以扩展 | 简单 |
| 隐私 | 外部处理 | 完全本地,最高隐私 | 外部处理 |
| 最适合 | 原型开发,中小规模工作负载 | 高隐私,稳定工作负载 | 可变/大规模训练,定制化 |
第 1 步:登录并访问模型库
登录您的账户,点击 Model Library(模型库)按钮。
第 2 步:开始免费试用
选择您的模型并开始免费试用,探索所选模型的能力。
第 3 步:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“Settings”(设置)页面,您可以按照图片所示复制 API 密钥。
第 4 步:安装 API(Python 示例)
使用您特定编程语言的包管理器安装 API。
安装后,将必要的库导入到您的开发环境中。使用您的 API 密钥初始化客户端,开始与 Novita AI LLM 交互。以下是使用 chat completions API 调用 Qwen3-VL-235B-A22B-Thinking 的示例。
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Qwen3-VL-235B-A22B 是当今最强大的视觉语言模型之一,在推理、视觉理解、OCR 和长上下文处理方面实现了突破。然而,其无与伦比的性能也伴随着高昂的 VRAM 需求,使得本地部署既昂贵又复杂。对于开发者和企业来说,这种权衡凸显了一个关键问题:如何在不突破硬件预算的前提下获得最先进的能力。
Novita AI 提供从 API 集成(即时、低维护接入)到 云或本地 GPU 部署(适用于定制化工作负载)的灵活选项,为充分发挥 Qwen3-VL-235B-A22B 的潜力提供了实用途径。通过选择适合您需求的方法,您可以解锁尖端的多模态 AI,同时将基础设施成本控制在可控范围内。
常见问题解答
Qwen3-VL-235B-A22B 的 Instruct 和 Thinking 版本有什么区别?
Instruct 版本针对遵循指令和日常任务进行了优化,而 Thinking 版本则更强调深度推理和更复杂的多模态理解。
Qwen3-VL-235B-A22B 是否支持视频以及图像?
是的,它既能处理静态图像,也能处理长时间跨度的视频输入,并具有先进的时间戳对齐能力。
如何在不产生巨大硬件成本的情况下使用 Qwen3-VL-235B-A22B?
您可以通过 Novita AI 使用 API 集成,无需昂贵的基础设施即可获得即时接入。
Novita AI 是一个一体化云平台,助力您的 AI 雄心。集成 API、无服务器、GPU 实例——您需要的经济高效工具。消除基础设施负担,免费起步,让您的 AI 愿景成为现实。



