

Qwen3-VL-235B-A22B stands as one of the most capable model in the Qwen series, with 235 billion parameters and advanced multimodal reasoning. Its breakthroughs in text understanding, visual perception, and long-context processing make it ideal for cutting-edge applications. However, these capabilities come with extreme VRAM demands, often far beyond what standard GPUs can handle.
This article highlights the model’s key strengths, explains how much VRAM the model really requires, and explores practical ways to tap the full potential of Qwen3-VL-235B-A22B while minimizing the high costs of GPU deployment.
What is Qwen3-VL-235B-A22B?
The Meaning of “Qwen3-VL-235B-A22B”
- Qwen3: The third generation of Alibaba’s Qwen large language models.
- VL: Stands for Vision-Language, combining stronger visual reasoning with robust text capabilities.
- 235B: The model has a total of 235 billion parameters (“B” = billion).
- A22B: Activates 22 billion parameters per inference (typical in MoE design).
Qwen3-VL-235B-A22B: Basics and Benchmark
| Feature | Detail |
| Model Size | 235B parameters in total with 22B activated |
| Open Source | Yes |
| Context Length | Native 256K context, expandable to 1M |
| Architecture | Available in both Dense and MoE |
| Variant | Instruct / Thinking |
| Language Support | 100+ languages and dialects, excels in English and Chinese |
| Multimodality | Integrates vision and language, from text to images, video, OCR, and spatial reasoning |
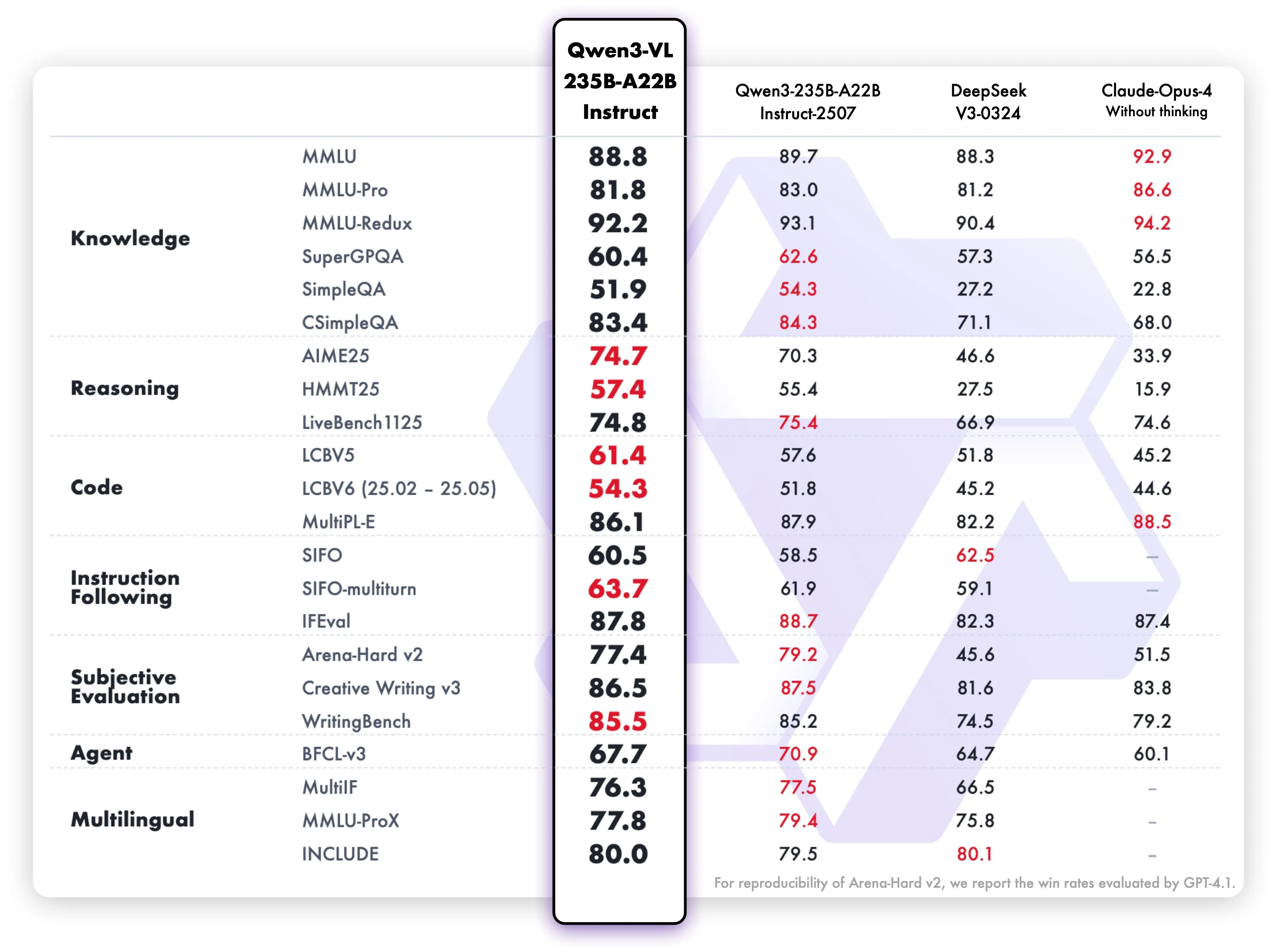
Qwen3-VL-235B-A22-Instruct Benchmark
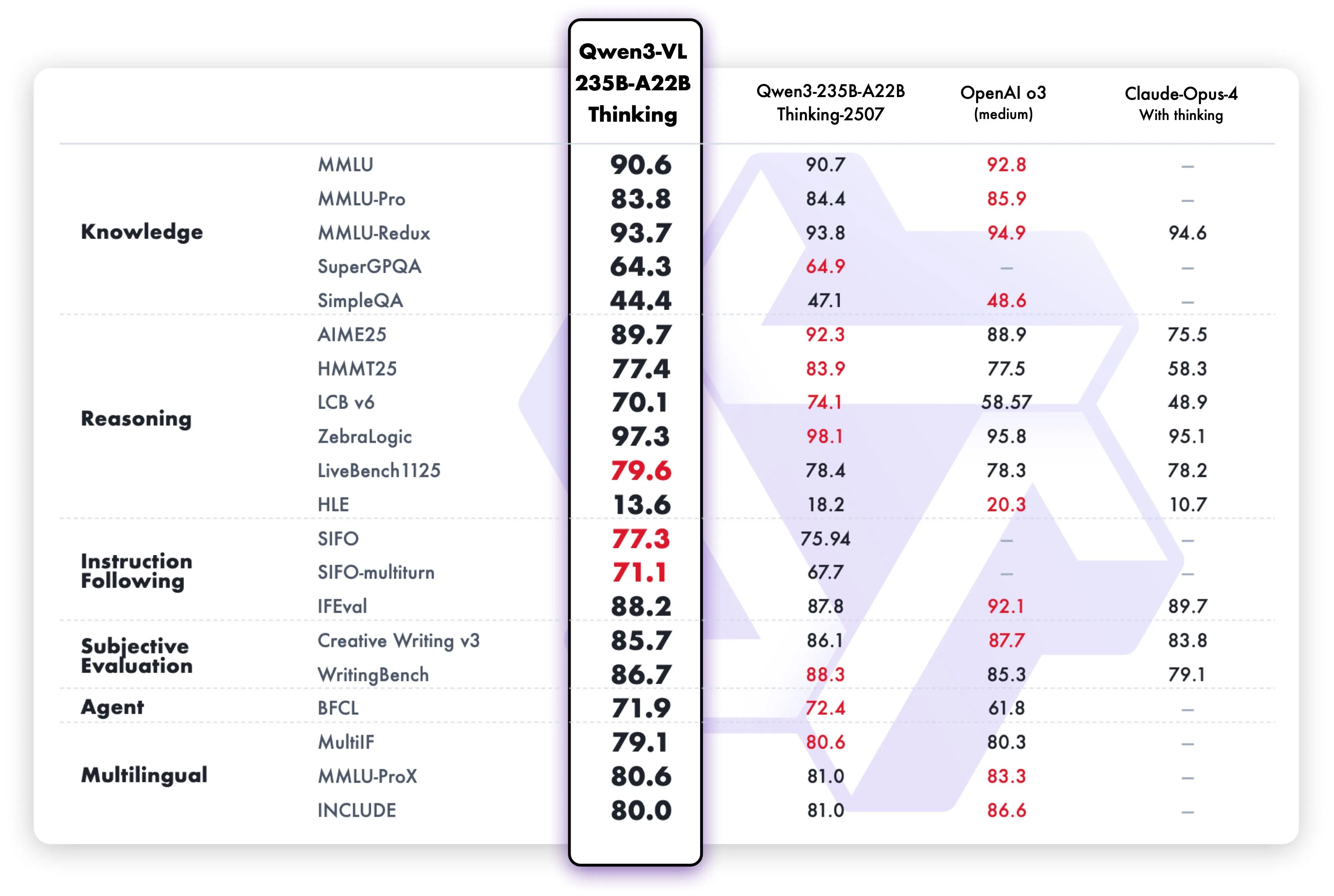
Qwen3-VL-235B-A22-Thinking Benchmark
Key Highlights of Qwen3-VL-235B-A22B
- Smarter Visual Agent: Can interact with PC or mobile interfaces—recognizing elements, triggering functions, and completing multi-step tasks.
- Code from Visuals: Translates diagrams, screenshots, or videos into usable code formats such as HTML, CSS, and Draw.io.
- Advanced Spatial Awareness: Understands object positions, occlusions, and viewpoints, enabling both 2D and 3D reasoning for robotics and embodied AI.
- Extended Context Handling: Processes up to 256K tokens natively, expandable to 1M—capable of reading entire books or hours-long videos with precise recall.
- Deeper Multimodal Reasoning: Excels in STEM and math tasks, providing causal analysis and structured, evidence-based answers.
- Robust OCR & Text Parsing: Recognizes text in 32 languages, even under blur, tilt, or low light, and better parses long documents.
- Broad Visual Recognition: Identifies a wide range of entities—from real-world objects and products to anime, landmarks, and biological species.
- Strong Language Fusion: Maintains text understanding on par with pure LLMs, while seamlessly integrating visual perception.
Qwen3-VL-235B-A22B VRAM & Hardware Requirements
Qwen3-VL-235B-A22B requires a minimum of 8 GPUs, each equipped with at least 80 GB of memory (such as A100, H100, or H200). On certain hardware configurations, the model may not launch successfully under default settings. To ensure stable performance, the following approaches are recommended based on hardware type:
- H200 & B200 GPUs: Run the model directly out of the box, with full support for long context lengths as well as concurrent image and video processing.
- H100 with FP8: Use FP8 for optimal memory efficiency. An official FP8 version of the model will be released soon, offering even better performance.
- A100 & H100 with BF16: Either reduce the
--max-model-lenparameter or limit inference to images only in order to maintain stability and avoid memory overload.
For users who want direct control and the freedom to choose their hardware, Novita AI provides on-demand Cloud GPU instances (including A100, H100, H200, B200, and more). These instances allow you to scale resources as needed and achieve high-performance deployment without the expense or complexity of maintaining local infrastructure. Whether you’re experimenting with new models, running large-scale training, or deploying demanding applications, the flexibility of Novita AI’s GPU cloud ensures smooth operation and efficient workflows.
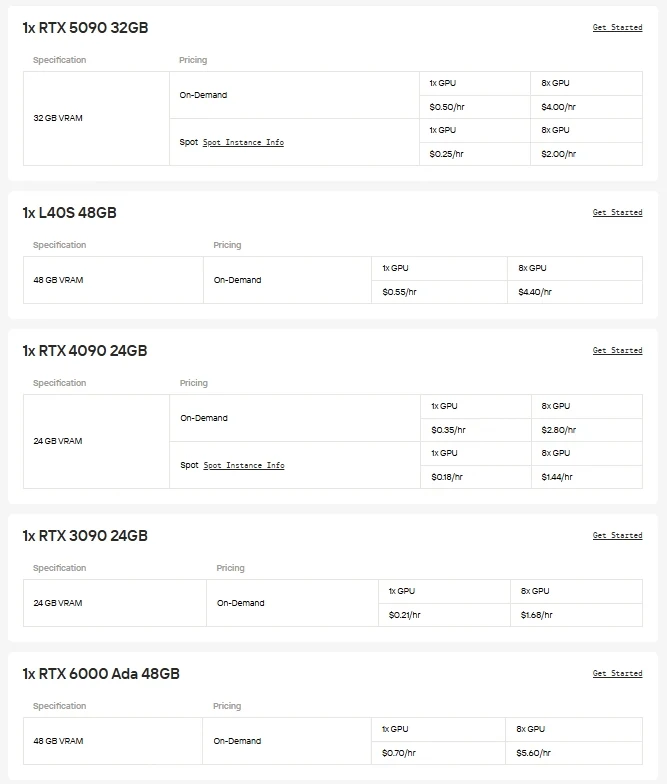
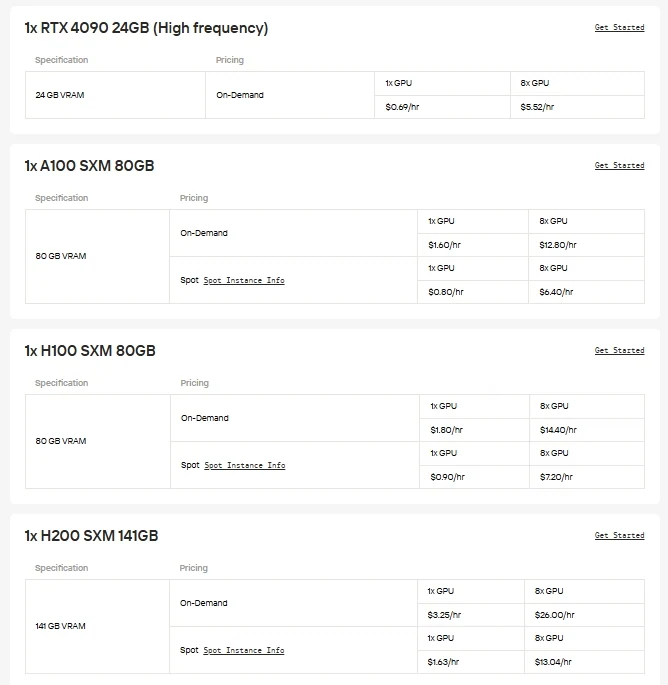
Another Cost-Saving Option: API
Novita AI provides Qwen3-VL-235B-A22B Instruct APIs with a 131K context window, priced at $0.3/M input tokens and $1.5/M output tokens, offering cost-efficient access for multimodal reasoning and instruction-following tasks. For more advanced scenarios, Qwen3-VL-235B-A22B Thinking APIs are also available, with the same 131K context window but priced at $0.3/M input tokens and $3/M output tokens, delivering deeper reasoning and stronger multimodal consistency through serverless deployment.
| Aspect | API | Local GPU | Cloud GPU |
|---|---|---|---|
| Ease of Setup | Ready to use instantly | Hardware-intensive, complex | Moderate, partly managed |
| Maintenance | Not-required | Heavy ongoing effort | Medium |
| Scalability | Elastic and automatic | Difficult to expand | Simple |
| Privacy | External processing | Fully local, max privacy | External processing |
| Best Suited For | Prototyping, small/medium workloads | High-privacy, stable workloads | Variable/large-scale training, customization |
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.
Try Qwen3-VL-235B-A22B Demo for FREE!
Step 2: Start Your Free Trial
Select your modal and begin your free trial to explore the capabilities of the selected model.
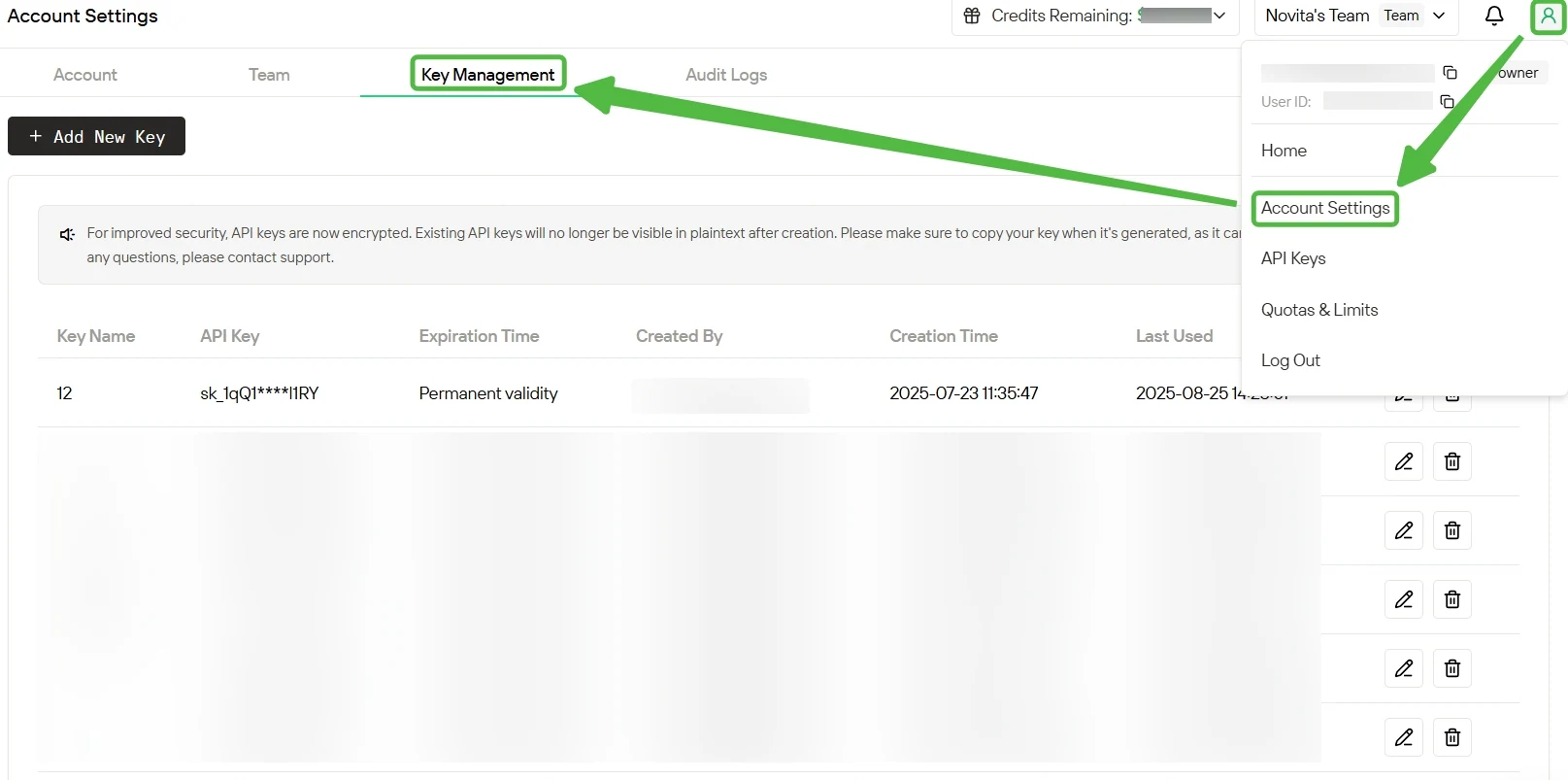
Step 3: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.
Step 4: Install the API (Python Example)
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for Qwen3-VL-235B-A22B-Thinking.
from openai import OpenAI
client = OpenAI(
api_key="<Your API Key>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)Qwen3-VL-235B-A22B stands as one of the most powerful vision-language models available today, delivering breakthroughs in reasoning, visual understanding, OCR, and long-context processing. Yet its unmatched performance also comes with steep VRAM demands, making local deployment costly and complex. For developers and enterprises, this trade-off highlights a key question: how to access state-of-the-art capabilities without breaking the hardware budget.
With flexible options ranging from API integration for instant, low-maintenance access to cloud or local GPU deployments for custom workloads, Novita AI provides practical pathways to tap the full potential of Qwen3-VL-235B-A22B. By choosing the right approach for your needs, you can unlock cutting-edge multimodal AI while keeping infrastructure costs under control.
Frequently Asked Questions
What’s the difference between Qwen3-VL-235B-A22B Instruct and Thinking editions?
Instruct is optimized for following prompts and everyday tasks, while Thinking emphasizes deeper reasoning and more complex multimodal understanding.
Does Qwen3-VL-235B-A22B support video as well as images?
Yes, it can process both static images and long-horizon video inputs with advanced timestamp alignment.
How can I access Qwen3-VL-235B-A22B without huge hardware costs?
You can use API integration via Novita AI, which provides instant access without expensive infrastructure.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.



