

Qwen3-VL-235B-A22B se destaca como uno de los modelos más capaces de la serie Qwen, con 235 mil millones de parámetros y razonamiento multimodal avanzado. Sus avances en comprensión de texto, percepción visual y procesamiento de contextos largos lo hacen ideal para aplicaciones de vanguardia. Sin embargo, estas capacidades conllevan demandas extremas de VRAM, a menudo muy por encima de lo que las GPUs estándar pueden manejar.
Este artículo destaca las principales fortalezas del modelo, explica cuánta VRAM realmente requiere y explora formas prácticas de aprovechar todo el potencial de Qwen3-VL-235B-A22B mientras se minimizan los altos costos de implementación con GPU.
¿Qué es Qwen3-VL-235B-A22B?
El significado de “Qwen3-VL-235B-A22B”
- Qwen3: La tercera generación de los grandes modelos de lenguaje Qwen de Alibaba.
- VL: Significa Visión-Lenguaje, combinando un razonamiento visual más fuerte con capacidades de texto robustas.
- 235B: El modelo tiene un total de 235 mil millones de parámetros (“B” = billón en inglés).
- A22B: Activa 22 mil millones de parámetros por inferencia (típico en diseño MoE).
Qwen3-VL-235B-A22B: Conceptos básicos y benchmark
| Característica | Detalle |
| Tamaño del modelo | 235 mil millones de parámetros en total con 22 mil millones activados |
| Código abierto | Sí |
| Longitud de contexto | Contexto nativo de 256K, expandible a 1M |
| Arquitectura | Disponible en versiones Dense y MoE |
| Variante | Instruct / Thinking |
| Soporte de idiomas | Más de 100 idiomas y dialectos, destaca en inglés y chino |
| Multimodalidad | Integra visión y lenguaje, desde texto a imágenes, video, OCR y razonamiento espacial |
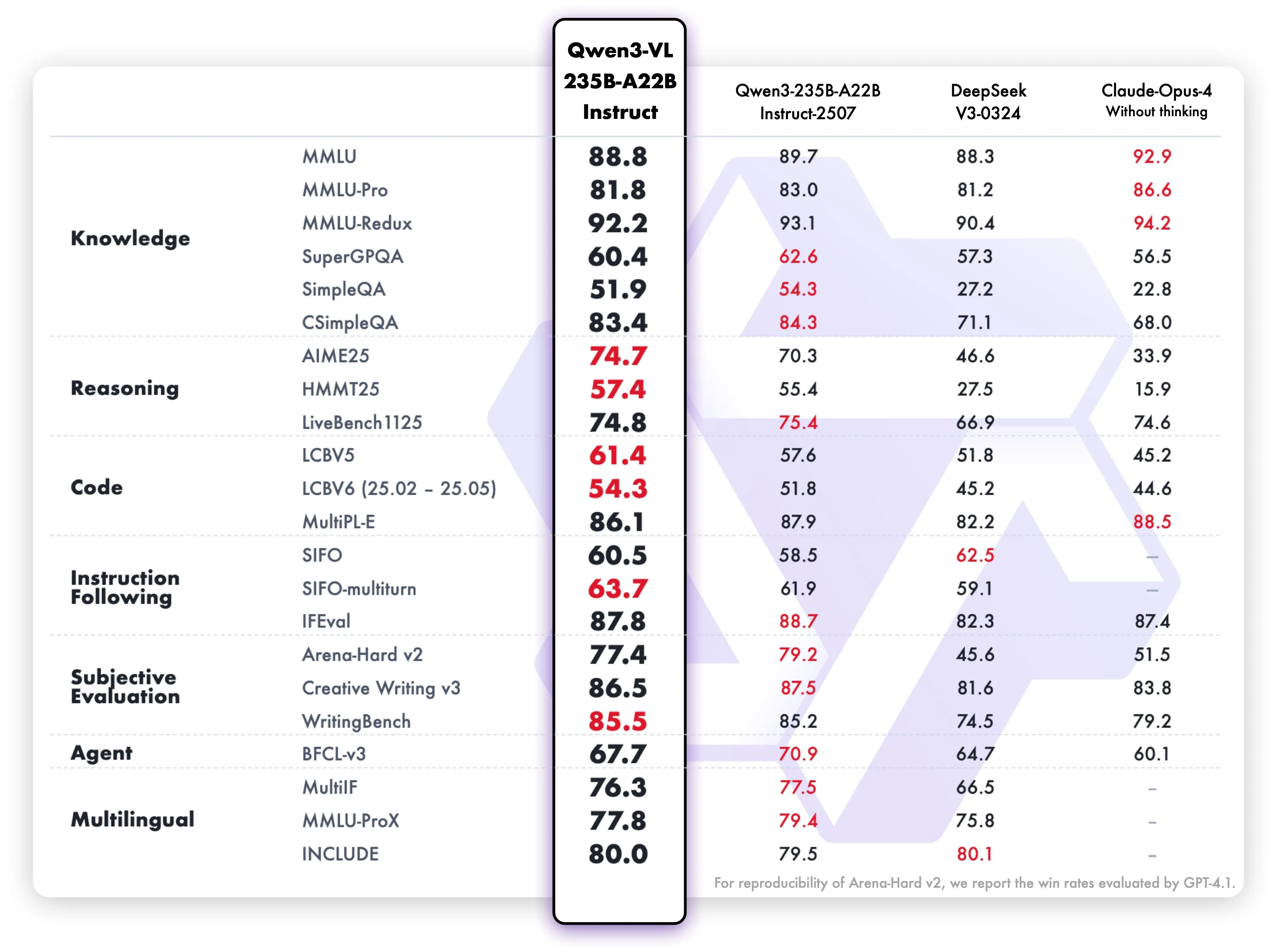
Benchmark de Qwen3-VL-235B-A22-Instruct
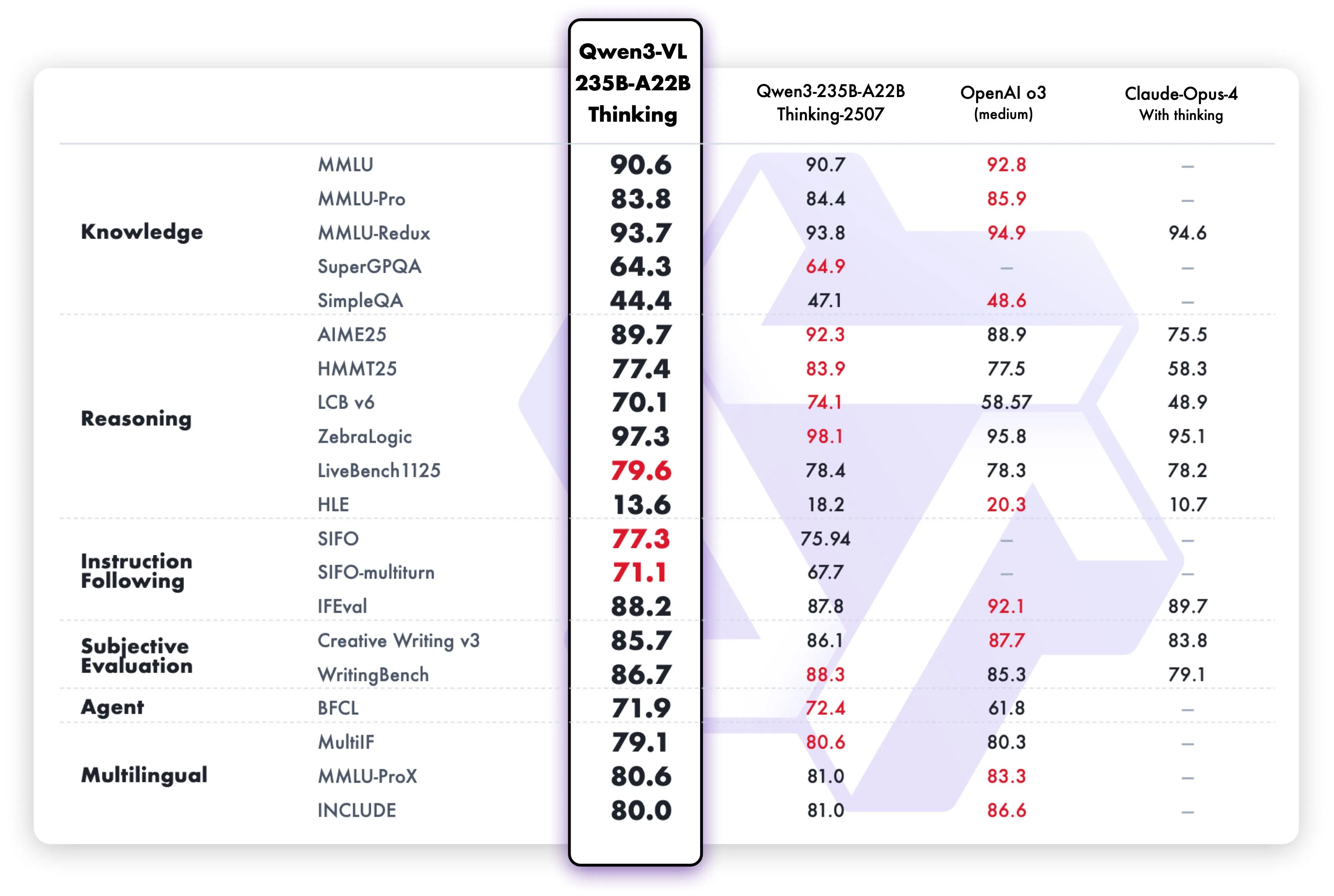
Benchmark de Qwen3-VL-235B-A22-Thinking
Aspectos destacados clave de Qwen3-VL-235B-A22B
- Agente visual más inteligente: Puede interactuar con interfaces de PC o móviles — reconociendo elementos, activando funciones y completando tareas de múltiples pasos.
- Código a partir de imágenes: Traduce diagramas, capturas de pantalla o videos a formatos de código utilizables como HTML, CSS y Draw.io.
- Conciencia espacial avanzada: Comprende posiciones de objetos, occlusiones y puntos de vista, permitiendo razonamiento 2D y 3D para robótica e IA incorporada.
- Manejo de contexto extendido: Procesa hasta 256K tokens de forma nativa, expandible a 1M — capaz de leer libros completos o videos de horas con recuperación precisa.
- Razonamiento multimodal más profundo: Sobresale en tareas STEM y matemáticas, proporcionando análisis causal y respuestas estructuradas basadas en evidencia.
- OCR robusto y análisis de texto: Reconoce texto en 32 idiomas, incluso bajo desenfoque, inclinación o poca luz, y analiza mejor documentos largos.
- Reconocimiento visual amplio: Identifica una amplia gama de entidades — desde objetos reales y productos hasta anime, monumentos y especies biológicas.
- Fusión de lenguaje fuerte: Mantiene la comprensión de texto al nivel de modelos de lenguaje puros, mientras integra de manera fluida la percepción visual.
Qwen3-VL-235B-A22B VRAM y requisitos de hardware
Qwen3-VL-235B-A22B requiere un mínimo de 8 GPUs, cada una equipada con al menos 80 GB de memoria (como A100, H100 o H200). En ciertas configuraciones de hardware, el modelo puede no iniciar correctamente con la configuración predeterminada. Para garantizar un rendimiento estable, se recomiendan los siguientes enfoques según el tipo de hardware:
- GPUs H200 y B200: Ejecuta el modelo directamente sin configuración adicional, con soporte completo para longitudes de contexto largas y procesamiento simultáneo de imágenes y video.
- H100 con FP8: Usa FP8 para una eficiencia de memoria óptima. Pronto se lanzará una versión oficial FP8 del modelo, ofreciendo un rendimiento aún mejor.
- A100 y H100 con BF16: Reduce el parámetro
--max-model-leno limita la inferencia solo a imágenes para mantener la estabilidad y evitar la sobrecarga de memoria.
Para los usuarios que desean control directo y la libertad de elegir su hardware, Novita AI proporciona instancias de GPU en la nube bajo demanda (incluyendo A100, H100, H200, B200 y más). Estas instancias te permiten escalar recursos según sea necesario y lograr una implementación de alto rendimiento sin el gasto o la complejidad de mantener una infraestructura local. Ya sea que estés experimentando con nuevos modelos, ejecutando entrenamiento a gran escala o implementando aplicaciones exigentes, la flexibilidad de la nube de GPUs de Novita AI garantiza un funcionamiento sin problemas y flujos de trabajo eficientes.
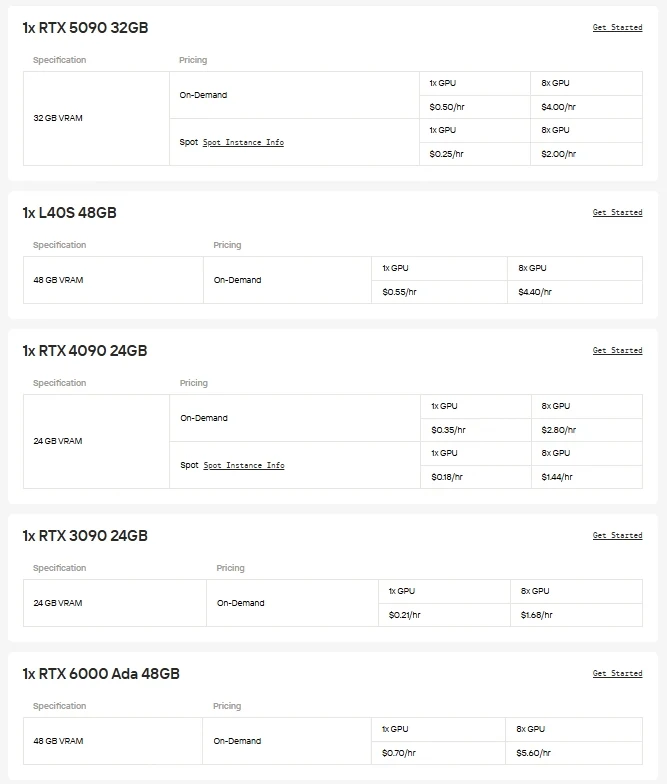
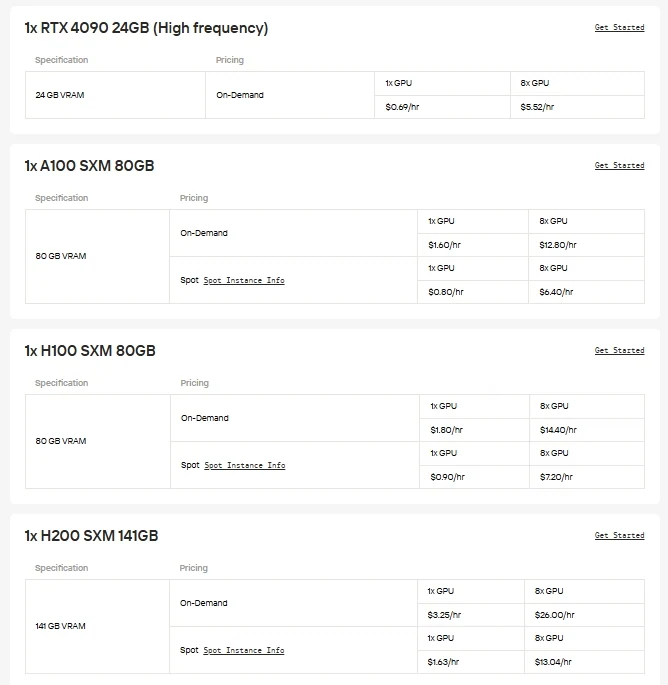
Otra opción para ahorrar costos: API
Novita AI proporciona APIs de Qwen3-VL-235B-A22B Instruct con una ventana de contexto de 131K, con un precio de $0.3/M tokens de entrada y $1.5/M tokens de salida, ofreciendo acceso rentable para razonamiento multimodal y tareas de seguimiento de instrucciones. Para escenarios más avanzados, también están disponibles las APIs de Qwen3-VL-235B-A22B Thinking, con la misma ventana de contexto de 131K pero con un precio de $0.3/M tokens de entrada y $3/M tokens de salida, ofreciendo un razonamiento más profundo y una consistencia multimodal más fuerte mediante implementación serverless.
| Aspecto | API | GPU local | GPU en la nube |
|---|---|---|---|
| Facilidad de configuración | Listo para usar al instante | Intensivo en hardware, complejo | Moderado, parcialmente gestionado |
| Mantenimiento | No requerido | Esfuerzo continuo pesado | Medio |
| Escalabilidad | Elástico y automático | Difícil de expandir | Simple |
| Privacidad | Procesamiento externo | Totalmente local, máxima privacidad | Procesamiento externo |
| Más adecuado para | Prototipado, cargas de trabajo pequeñas/medianas | Cargas de trabajo estables con alta privacidad | Entrenamiento variable/a gran escala, personalización |
Paso 1: Iniciar sesión y acceder a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Model Library.
¡Prueba la demostración de Qwen3-VL-235B-A22B GRATIS!
Paso 2: Iniciar tu prueba gratuita
Selecciona tu modelo y comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 3: Obtén tu clave API
Para autenticarte con la API, te proporcionaremos una nueva clave API. Ingresando a la página de “Configuración”, puedes copiar la clave API como se indica en la imagen.
Paso 4: Instalar la API (Ejemplo en Python)
Instala la API usando el administrador de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para Qwen3-VL-235B-A22B-Thinking.
from openai import OpenAI
client = OpenAI(
api_key="<Tu Clave API>",
base_url="https://api.novita.ai/openai"
)
response = client.chat.completions.create(
model="qwen/qwen3-vl-235b-a22b-thinking",
messages=[
{"role": "system", "content": "Eres un asistente útil."},
{"role": "user", "content": "Hola, ¿cómo estás?"}
],
max_tokens=32768,
temperature=0.7
)
print(response.choices[0].message.content)
Qwen3-VL-235B-A22B se posiciona como uno de los modelos de visión-lenguaje más potentes disponibles hoy en día, ofreciendo avances en razonamiento, comprensión visual, OCR y procesamiento de contextos largos. Sin embargo, su rendimiento inigualable también conlleva demandas elevadas de VRAM, lo que hace que la implementación local sea costosa y compleja. Para desarrolladores y empresas, esta compensación resalta una pregunta clave: cómo acceder a capacidades de vanguardia sin exceder el presupuesto de hardware.
Con opciones flexibles que van desde la integración de API para un acceso instantáneo y de bajo mantenimiento hasta implementaciones en GPU en la nube o locales para cargas de trabajo personalizadas, Novita AI ofrece caminos prácticos para aprovechar todo el potencial de Qwen3-VL-235B-A22B. Al elegir el enfoque adecuado para tus necesidades, puedes desbloquear IA multimodal de vanguardia mientras mantienes los costos de infraestructura bajo control.
Preguntas Frecuentes
¿Cuál es la diferencia entre las ediciones Instruct y Thinking de Qwen3-VL-235B-A22B?
Instruct está optimizado para seguir instrucciones y tareas cotidianas, mientras que Thinking enfatiza un razonamiento más profundo y una comprensión multimodal más compleja.
¿Qwen3-VL-235B-A22B admite video además de imágenes?
Sí, puede procesar tanto imágenes estáticas como entradas de video de largo alcance con alineación avanzada de marcas de tiempo.
¿Cómo puedo acceder a Qwen3-VL-235B-A22B sin grandes costos de hardware?
Puedes usar la integración de API a través de Novita AI, que proporciona acceso instantáneo sin infraestructura costosa.
Novita AI es la plataforma en la nube todo en uno que impulsa tus ambiciones de IA. APIs integradas, serverless, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y convierte tu visión de IA en realidad.



