

GLM 4.1V 9B Thinking 是一款突破性的 AI 模型,因为它既能“看见”图像,又能逐步解释其推理过程。这被称为思维链(CoT)推理,而 GLM 在这一方面比任何其他同等规模的视觉语言模型都做得更好。你将看到它与更大模型的对比情况,以及如何自己尝试使用它,即使没有昂贵的 GPU。
GLM 4.1V 9B Thinking 在 VLM 模型中带来了哪些变化?
作为全球首个具备思维链(CoT)推理能力的 VLM 模型,GLM 不仅以强大的能力令人印象深刻,更因其在 9B 模型的小尺寸下实现了与 Qwen 2.5 72B 相当的性能而获得认可。接下来,让我们详细了解一下 GLM 的技术规格和基准测试结果。
GLM 4.1V 9B Thinking 的特性

你可以直接在 Hugging Face 免费试用!
GLM 4.1V 9B Thinking 是如何实现这些改进的?
- SFT 强化:
训练样本中包含显式的 思维链(CoT) 注释,因此模型学会了 “先思考,再回答。” 这与仅输出答案而不展示推理步骤的传统模型不同。 - RLCS 强化:
模型的奖励不仅仅基于正确性——还会评估 推理过程和解释的质量,从而鼓励更连贯、更彻底的内在思考。 - 架构支持:
ViT 视觉编码器将输入送入 MLP 投影器,再进入 LLM 解码器,使模型能够 从视觉输入无缝生成显式推理路径,而非仅仅进行检索或模式匹配。 - 强大的推理基础:
另一个关键因素:基础模型 GLM‑4‑9B 0414 已经具备强大的推理能力。例如:- 它在数学推理和通用任务性能方面表现出色,在同一规模的开源模型中位居前列。
- 在架构和训练方面,GLM‑4‑9B 受益于自回归空白填充预训练以及后续微调,增强了逻辑和多步推理能力。
更多详情可查看论文:GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning。
GLM 4.1V 9B Thinking VS Qwen 2.5 VL 72B
| **基准 ** | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B | ** 胜者** |
|---|---|---|---|
| MMMU (图像) | 68.0 | 70.2 | Qwen 2.5 VL |
| MMMU‑Pro | 57.1 | 51.1 | GLM |
| VideoMMMU | 61.0 | 60.2 | GLM |
| mvBench (视频) | 70.4 | 64.6 | GLM |
| AITZ_EM (智能体) | 83.2 | 35.3* | GLM |
| 智能体 (OSWorld) | 14.9 | 8.8 | GLM |
| 智能体 (AndroidWorld) | 41.7 | 35.0 | GLM |
| 智能体 (WebVoyageSom) | 69.0 | 40.4 | GLM |
| 智能体 (Webquest‑SingleQA) | 72.1 | 60.5 | GLM |
| 智能体 (Webquest‑MultiQA) | 54.7 | 52.1 | GLM |
| 编程 (Design2Code) | 64.7 | 41.9 | GLM |
| 编程 (Flame‑VLM‑Code) | 72.5 | 46.3 | GLM |
| OCRBench | 84.2 | 85.1 | Qwen 2.5 VL |
| VideoMME (无文本) | 68.2 | 73.3 | Qwen 2.5 VL |
| VideoMME (有文本) | 73.6 | 79.1 | Qwen 2.5 VL |
| MMVU | 59.4 | 62.9 | Qwen 2.5 VL |
选择 GLM 4.1V 9B Thinking,如果你的重点是多模态推理、智能体能力、STEM 问题解决或编程。
选择 Qwen 2.5 VL 72B,如果你专注于文档/图像/视频理解——尤其是 OCR、结构化提取和视觉感知。
如果想了解更多细节,可以查看这篇文章:GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B:哪个适合什么场景?
该文章还提供了与其他领先模型的对比。
来自 THUDM
如何访问 GLM 4.1V 9B Thinking?
1. 本地访问
更令人印象深刻的是,GLM 4.1V 9B Thinking 仅有 90 亿参数,可以在 RTX 4090 甚至 3090 等 GPU 上运行。与参数多出数倍的其他模型相比,GLM 以更小的尺寸实现了出色的性能——这一成就无疑凸显了强化学习的力量。
来自 THUDM
安装指南
安装:
pip install git+https://github.com/huggingface/transformers.git
基本用法:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
如果购买 GPU 成本过高,你可以利用 Novita AI 高性价比且可靠的云 GPU——例如 RTX 4090 每小时仅需 $0.69,RTX 3090 每小时仅需 $0.21!
2. 直接 API 集成
步骤 1:登录并访问模型库
登录你的账户,点击 模型库 按钮。

步骤 2:选择模型
浏览可用选项,选择适合你需求的模型。
步骤 3:开始免费试用
开始免费试用,体验所选模型的功能。
步骤 4:获取 API 密钥
为了通过 API 进行身份验证,我们将为你提供一个新的 API 密钥。进入“设置”页面,你可以按照图中所示复制 API 密钥。

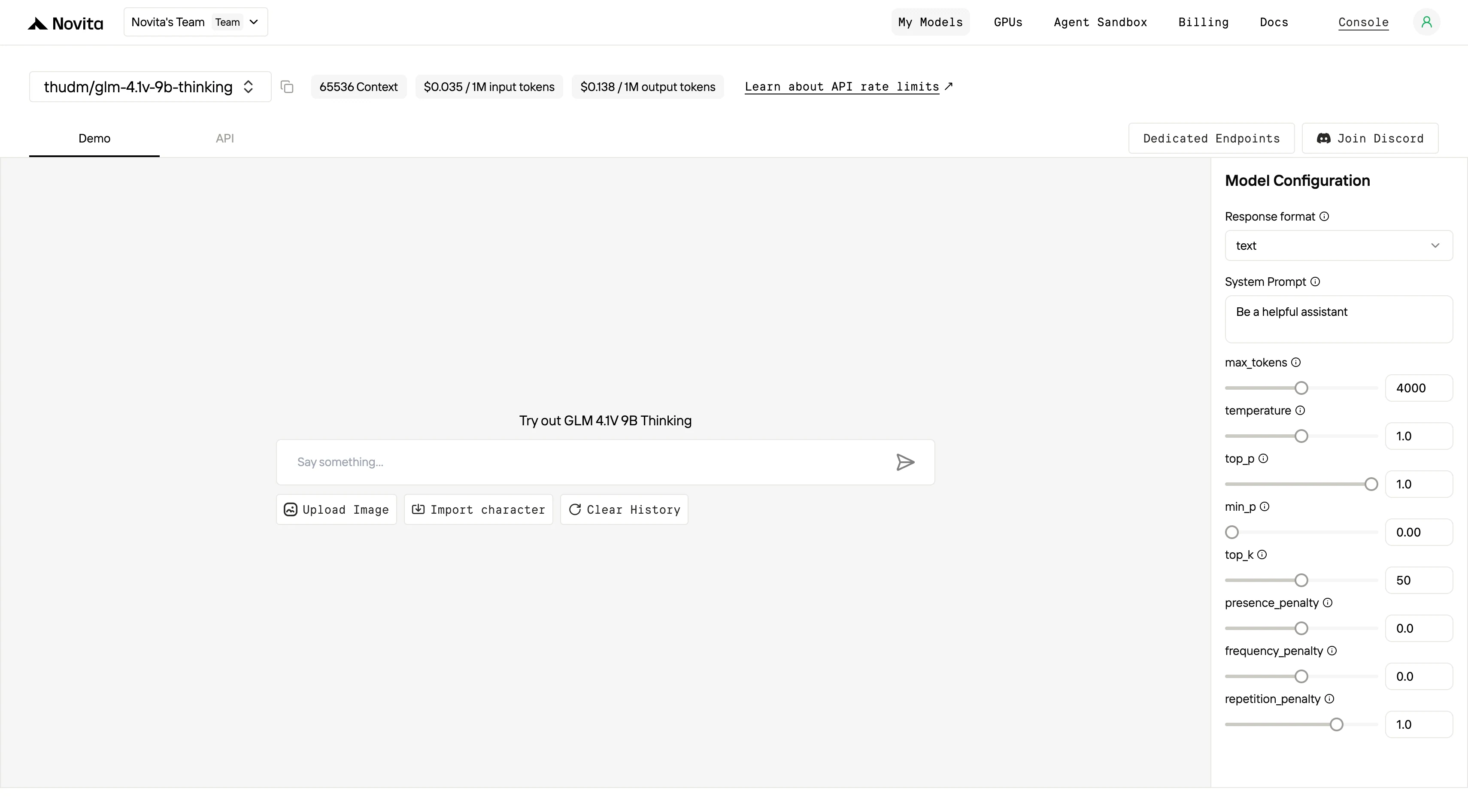
步骤 5:安装 API
使用你编程语言对应的包管理器安装 API。
安装后,将必要的库导入到你的开发环境中。使用你的 API 密钥初始化客户端,开始与 Novita AI LLM 交互。这是一个供 Python 用户使用的聊天补全 API 示例。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
使用 MCP 和 GLM 构建一个简单的图像识别工具
如果你想利用 GLM 的能力——例如构建一个简单的图像识别工具来展示其视觉识别与推理的集成——可以使用 Novita AI 支持的 MCP 功能。以下是示例代码:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
如果你想获取详细信息,可以查看这篇文章:如何使用 Novita AI 构建你的第一个 MCP 服务器!
GLM 4.1V 9B Thinking 易于使用、超级智能,并且不需要昂贵的硬件。只需几行代码,你就可以在自己的机器上或云端测试其图像识别和推理能力。如果你想看看多模态 AI 已经发展到了什么程度,不妨尝试一下 GLM!
GLM 4.1V 9B Thinking 有什么特别之处?
它是首个既能“看”又能展示推理步骤的模型,而不仅仅是给出答案。
如果我没有强大的 GPU,可以尝试 GLM 4.1V 9B 吗?
可以!你可以使用经济实惠的云 GPU,或者在 Novita AI 的 Playground 免费试用。
如何将 GLM 4.1V 9B Thinking 集成到自己的项目中?
你可以通过 Python 和 Hugging Face 在本地运行它,通过 Novita AI 的 API 访问它,甚至可以使用提供的代码示例中所示的 MCP 构建自己的图像识别工具。
Novita AI 是一个一体化云平台,助力实现你的 AI 雄心。集成 API、无服务器、GPU 实例——你需要的成本效益工具。消除基础设施,免费开始,让你的 AI 愿景成为现实。



