

GLM 4.1V 9B Thinking é um modelo de IA inovador, pois consegue tanto ver imagens quanto explicar seu raciocínio passo a passo. Isso é chamado de raciocínio em cadeia de pensamento (CoT), e o GLM faz isso melhor do que qualquer outro modelo visão-linguagem de seu tamanho. Você verá como ele se compara a modelos maiores e como pode testá-lo você mesmo, mesmo que não tenha uma GPU cara.
Que mudanças o GLM 4.1V 9B Thinking trouxe para os modelos VLM?
Como o primeiro modelo VLM do mundo com raciocínio em cadeia de pensamento (CoT), o GLM não apenas impressionou com suas capacidades poderosas, mas também ganhou reconhecimento por alcançar desempenho comparável ao Qwen 2.5 72B, apesar de ser um modelo muito menor (9B). A seguir, vamos examinar mais de perto as especificações detalhadas e os resultados de benchmarks do GLM.
Atributo do GLM 4.1V 9B Thinking

Você pode iniciar um teste gratuito diretamente no Hugging Face!
Como o GLM 4.1V 9B Thinking alcança essas melhorias?
- Reforço com SFT:
As amostras de treinamento incluem anotações explícitas de Cadeia de Pensamento (CoT), para que o modelo aprenda a “pensar primeiro, depois responder.” Isso difere dos modelos tradicionais, que apenas fornecem uma resposta sem mostrar as etapas de raciocínio. - Reforço com RLCS:
A recompensa do modelo não se baseia apenas na correção — ela também avalia a qualidade do processo de raciocínio e das explicações, incentivando um pensamento interno mais coerente e completo. - Suporte Arquitetural:
Um codificador visual ViT alimenta um projetor MLP e, em seguida, o decodificador LLM, permitindo que o modelo gere perfeitamente caminhos de raciocínio explícitos a partir da entrada visual, em vez de mera recuperação ou correspondência de padrões. - Base Sólida de Raciocínio:
E outro fator-chave: o modelo base — GLM‑4‑9B 0414 — já possui habilidades robustas de raciocínio. Por exemplo:- Ele demonstra excelente raciocínio matemático e desempenho geral em tarefas, classificando-se no topo entre os modelos de código aberto em sua escala.
- Arquiteturalmente e em termos de treinamento, o GLM‑4‑9B se beneficia de pré-treinamento autoregressivo com preenchimento de lacunas e ajuste fino subsequente que fortalecem habilidades de raciocínio lógico e multi-etapas.
Você pode obter mais detalhes no artigo: GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning.
GLM 4.1V 9B Thinking vs Qwen 2.5 VL 72B
| Benchmark | GLM 4.1V 9B Thinking | Qwen 2.5 VL 72B | Vencedor |
|---|---|---|---|
| MMMU (imagem) | 68.0 | 70.2 | Qwen 2.5 VL |
| MMMU‑Pro | 57.1 | 51.1 | GLM |
| VideoMMMU | 61.0 | 60.2 | GLM |
| mvBench (vídeo) | 70.4 | 64.6 | GLM |
| AITZ_EM (agente) | 83.2 | 35.3* | GLM |
| Agente (OSWorld) | 14.9 | 8.8 | GLM |
| Agente (AndroidWorld) | 41.7 | 35.0 | GLM |
| Agente (WebVoyageSom) | 69.0 | 40.4 | GLM |
| Agente (Webquest‑SingleQA) | 72.1 | 60.5 | GLM |
| Agente (Webquest‑MultiQA) | 54.7 | 52.1 | GLM |
| Codificação (Design2Code) | 64.7 | 41.9 | GLM |
| Codificação (Flame‑VLM‑Code) | 72.5 | 46.3 | GLM |
| OCRBench | 84.2 | 85.1 | Qwen 2.5 VL |
| VideoMME (sem texto) | 68.2 | 73.3 | Qwen 2.5 VL |
| VideoMME (com texto) | 73.6 | 79.1 | Qwen 2.5 VL |
| MMVU | 59.4 | 62.9 | Qwen 2.5 VL |
Escolha GLM 4.1V 9B Thinking se sua prioridade for raciocínio multimodal, capacidades de agente, resolução de problemas STEM ou codificação.
Escolha Qwen 2.5 VL 72B se você estiver focado em compreensão de documentos/imagens/vídeos — especialmente OCR, extração estruturada e percepção visual.
Se quiser ver mais detalhes, consulte este artigo: GLM 4.1V 9B Thinking vs Qwen2.5 VL 72B: Qual se Encai a Qual Cenário?
Ele também fornece uma comparação com outros modelos líderes.
De THUDM
Como Acessar o GLM 4.1V 9B Thinking?
1. Acesso Local
Ainda mais impressionante, o GLM 4.1V 9B Thinking tem apenas 9 bilhões de parâmetros, permitindo que seja executado em GPUs como RTX 4090 ou até mesmo RTX 3090. Comparado a outros modelos com várias vezes mais parâmetros, o GLM alcança desempenho excepcional com um tamanho muito menor — uma conquista que, sem dúvida, destaca o poder do aprendizado por reforço.
De THUDM
Guia de Instalação
Instalação:
pip install git+https://github.com/huggingface/transformers.git
Uso básico:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
Se comprar uma GPU parecer muito caro, você pode aproveitar as GPUs em nuvem econômicas e confiáveis da Novita AI — como a RTX 4090 por apenas $0,69 por hora ou a RTX 3090 por apenas $0,21 por hora!
2. Integração Direta com API
Passo 1: Faça login e acesse a Biblioteca de Modelos
Faça login na sua conta e clique no botão Model Library.

Experimente o GLM 4.1V 9B agora!
Passo 2: Escolha seu modelo
Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.
Passo 3: Inicie seu teste gratuito
Inicie seu teste gratuito para explorar as capacidades do modelo selecionado.
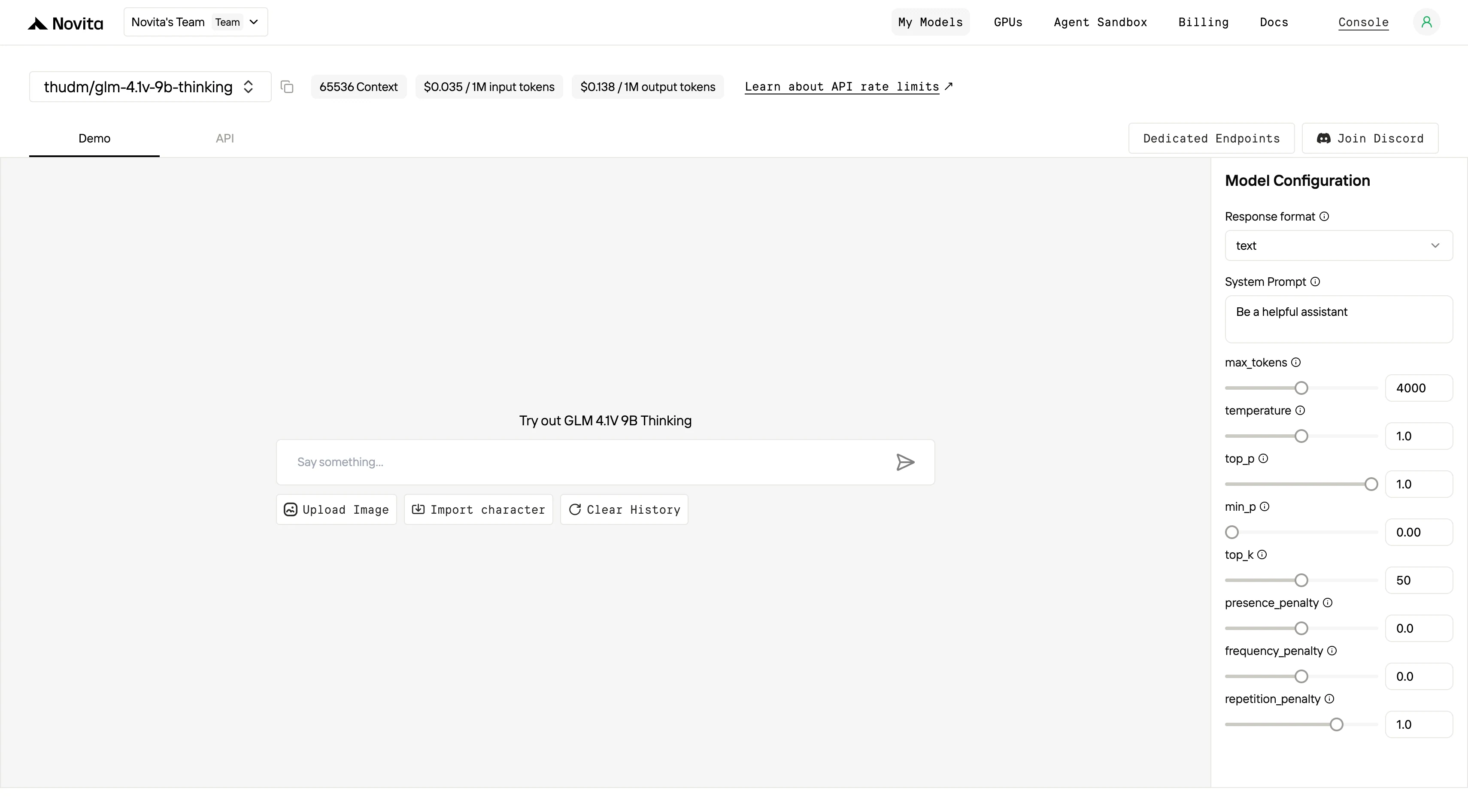
Passo 4: Obtenha sua chave de API
Para autenticar com a API, forneceremos uma nova chave de API. Ao entrar na página “Settings”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API
Instale a API usando o gerenciador de pacotes específico para sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias em seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o Novita AI LLM. Este é um exemplo de uso da API de chat completions para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="session_kgNdXtDPt2zYc95i-nDWPaW4Zl_e7nf4VDpukuIVBKpko1-LE8xCasG4YK7c-3c1xnPzGYRuocFk_DhkPUUQyQ==",
)
model = "thudm/glm-4.1v-9b-thinking"
stream = True # or False
max_tokens = 4000
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Construa uma Ferramenta Simples de Reconhecimento de Imagem usando MCP e GLM.
Se você quiser aproveitar as capacidades do GLM — como construir uma ferramenta simples de reconhecimento de imagem para demonstrar sua integração de reconhecimento visual e raciocínio — pode usar a funcionalidade MCP suportada pela Novita AI. Abaixo está o código de exemplo:
import os
import sys
from mcp.server.fastmcp import FastMCP
import requests
import uvicorn
from starlette.applications import Starlette
from starlette.routing import Mount
base_url = "https://api.novita.ai/v3"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['NOVITA_API_KEY']}"
}
mcp = FastMCP("Novita_API")
@mcp.tool()
def list_models() -> str:
"""
List all available models from the Novita API.
"""
url = base_url + "/openai/models"
response = requests.request("GET", url, headers=headers)
data = response.json()["data"]
text = ""
for i, model in enumerate(data, start=1):
text += f"Model id: {model['id']}\
"
text += f"Model description: {model['description']}\
"
text += f"Model type: {model['model_type']}\
\
"
return text
@mcp.tool()
def get_model(model_id: str, message) -> str:
"""
Provide a model ID and a message to get a response from the Novita API.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"content": message,
"role": "user",
}
],
"max_tokens": 200,
"response_format": {
"type": "text",
},
}
response = requests.request("POST", url, json=payload, headers=headers)
content = response.json()["choices"][0]["message"]["content"]
return content
@mcp.tool()
def vision_chat(model_id: str, image_url: str, question: str) -> str:
"""
Use GLM-4.1V-9B-Thinking to answer a question about an image.
"""
url = base_url + "/openai/chat/completions"
payload = {
"model": model_id,
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_url,
}
},
{
"type": "text",
"text": question,
}
]
}
],
"max_tokens": 500
}
response = requests.post(url, json=payload, headers=headers)
return response.json()["choices"][0]["message"]["content"]
if __name__ == "__main__":
# Run using stdio transport
mcp.run(transport="stdio")
Se quiser obter os detalhes, confira este artigo: How to Build Your First MCP Server with Novita AI!
O GLM 4.1V 9B Thinking é fácil de usar, super inteligente e não precisa de hardware sofisticado. Você pode testar suas habilidades de reconhecimento de imagem e raciocínio com apenas algumas linhas de código, seja em sua própria máquina ou na nuvem. Se quiser ver até onde a IA multimodal chegou, experimente o GLM!
O que há de especial no GLM 4.1V 9B Thinking?
É o primeiro modelo que consegue “ver” e mostrar suas etapas de raciocínio, não apenas dar respostas.
Posso testar o GLM 4.1V 9B se não tiver uma GPU potente?
Sim! Você pode usar GPUs em nuvem acessíveis ou testá-lo gratuitamente no Novita AI Playground.
Como posso integrar o GLM 4.1V 9B Thinking em meus próprios projetos?
Você pode executá-lo localmente usando Python e Hugging Face, acessá-lo via API do Novita AI, ou até construir suas próprias ferramentas de reconhecimento de imagem usando MCP, conforme mostrado nos exemplos de código fornecidos.
Novita AI é a plataforma completa em nuvem que impulsiona suas ambições de IA. APIs integradas, serverless, GPU Instance — as ferramentas econômicas que você precisa. Elimine infraestrutura, comece gratuitamente e torne sua visão de IA realidade.



